CNN сети для датасета CIFAR-10
Введение
В качестве практики обучения свёрточных нейронных сетей, обучим различные архитектуры на датасете CIFAR-10. Этот датасет содержит 60k RGB-изображений 32x32 пикселей промаркированных десятью классами:
['airplane', 'automobile', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck']
Тренировочными считаются 50k изображений, а тестовыми - 10k. Ниже приведены примеры изображений из этого датасета:

ResNet
 Приведём целевые ошибки обучения на тестовой выборке, представленные в статье по архитектуре
ResNet (2015),
а также некоторые технические подробности обучения из этой же статьи:
Приведём целевые ошибки обучения на тестовой выборке, представленные в статье по архитектуре
ResNet (2015),
а также некоторые технические подробности обучения из этой же статьи:
- We use SGD with a mini-batch size of 256.
- The learning rate starts from 0.1 and is divided by 10 when the error plateaus, and the models are trained for up to 60 × 104 iterations.
- We use a weight decay of 0.0001 and a momentum of 0.9.
- We do not use dropout.
Сначала воспользуемся готовой архитектурой из torchvision, изменив (как и авторы ResNet) для CIFAR-10 первый слой:
model = models.resnet18(pretrained=False, num_classes=10)
model.conv1 = nn.Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), \
padding=(1, 1), bias=False)
model.maxpool = nn.Identity()
При этом получается 11,173,962 параметров, что существенно больше, чем в статье (270k). Связано это с тем, что авторы тестировали ResNet на CIFAR-10 с числом фильтров 16 - 32 - 64, а не как в resnet18 (для ImageNet) с 64 - 128 - 256 - 512. Тем не менее, обучим сначала эту сеть. Для этого будем использовать аугментацию тренировочных данных, при помощи библиотеки Albumentations:
transform_trn = A.Compose([
A.HorizontalFlip(p=0.5),
A.ShiftScaleRotate(rotate_limit=10),
A.RandomResizedCrop(height=32, width=32, scale=(0.8, 1.), ratio=(0.9, 1.1)),
A.Normalize(),
ToTensorV2() ])
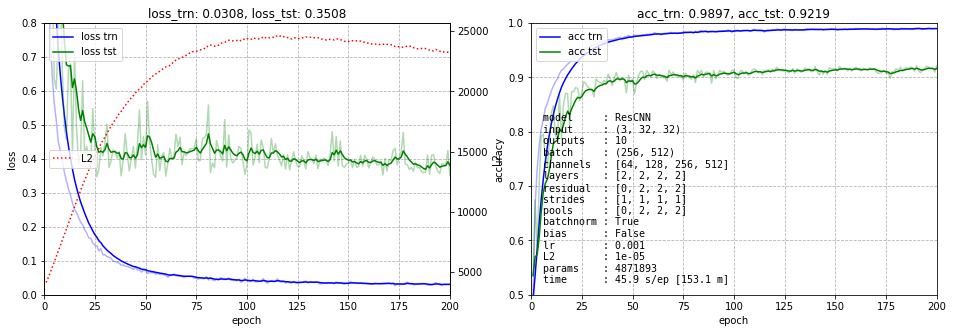
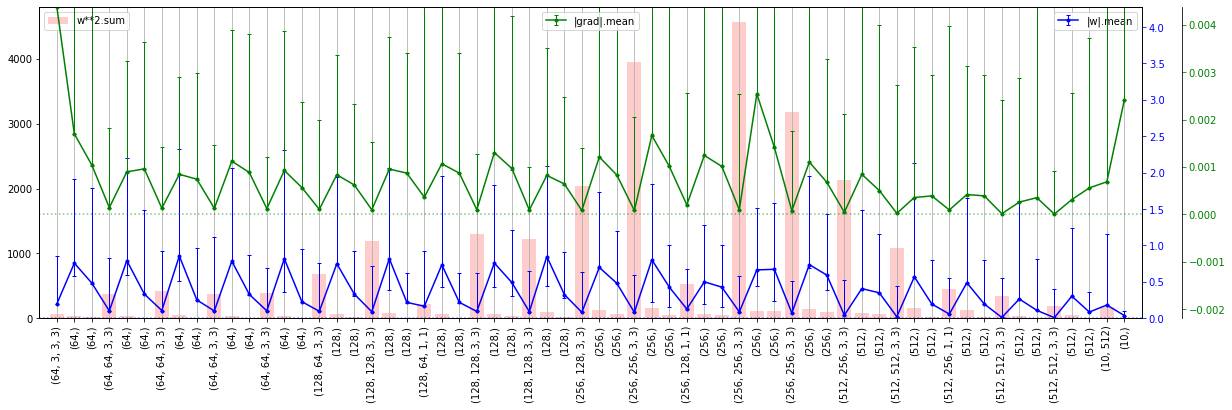
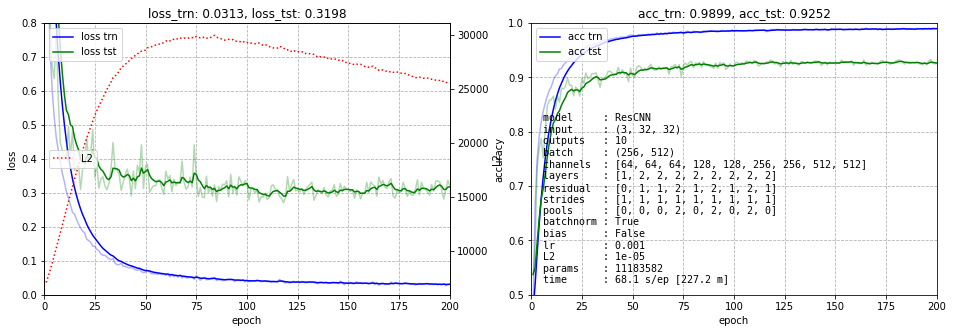
Результат представлен ниже. На левом графике нарисованы ошибки обучения тренировочных (синий) и тестовых (зелёных) данных. Пунктирная красная линия - это динамика суммы квадратов всех весов сети (для контроля L2 регуляризации). Голубая линия с точками - это среднее значение модулей градиентов по всем слоям в конце обучения (слева вход, справа выход сети). Эта линия показывает, что градиент при обратном распространении не затухает. Справа приведена точность на тренировочных данных (синий) и тестовых (зелёный).
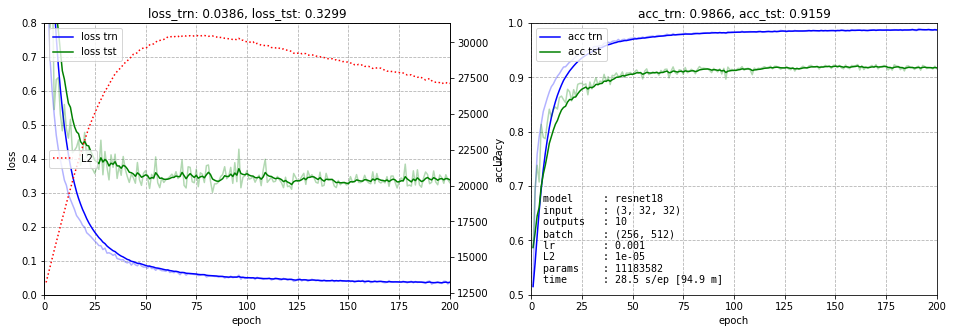
Мы не будем гнаться за долями процентов и обучение обычно останавливается на 200 эпохах. Где-то к 500-й эпохе можно получить ошибку порядка 7.7%.
Воспроизведём для проверки эти же результаты на собственной версии ResNet с настраиваемыми параметрами и той же архитектурой, что и у ResNet18:
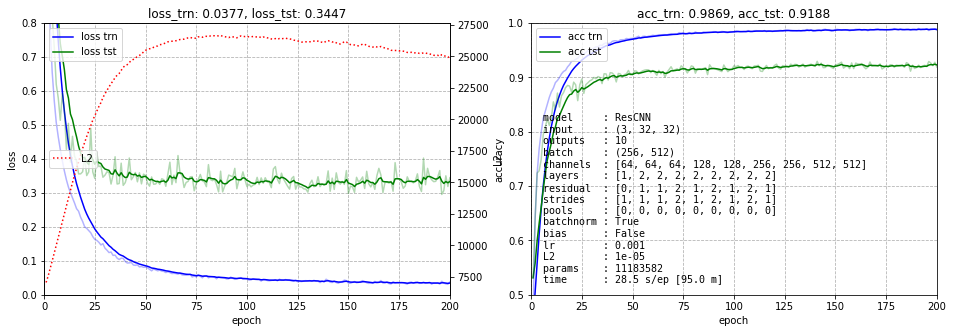
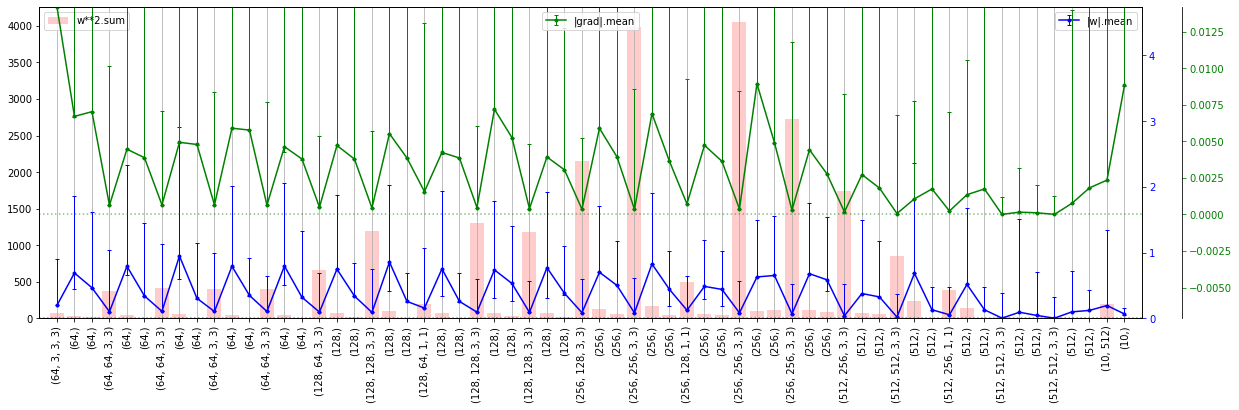
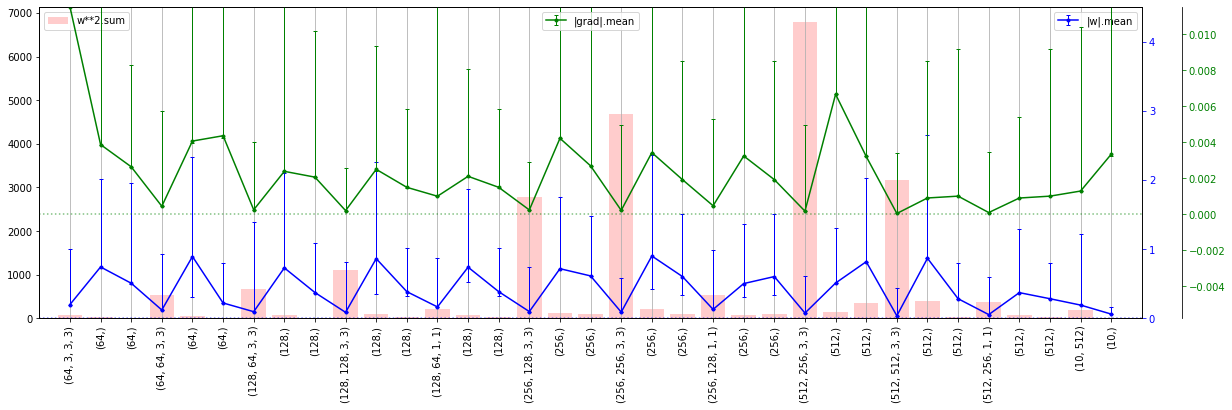
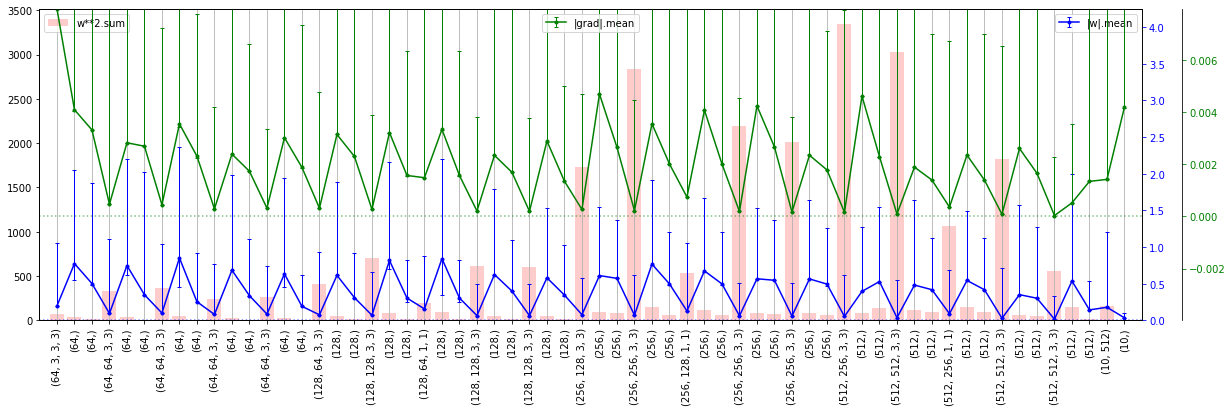
Далее будем изменять архитектуру, при помощи параметров, выведенных на правом графике:
- channels - число каналов в блоке (для всех слоёв блока они одинаковые);
- layers - число Conv2d слоёв в каждом блоке;
- residual - наличие "остаточных" петель (0 - нет, 1 - простое суммирование, 2 - вход перед суммированием пропускается через Conv2d c единичным ядром (веса вклада входа);
- strides - размер шага фильтра в первом слое блока (в остальных слоях он равен 1); если stride=2, то размер карты признаков уменьшается вдвое (альтернатива пулингу);
- pools - наличие слоя пулинга (размер его ядра) после соответствующего блока.
Заметим, что, как это часто бывает, узким местом является не обучение модели, а отправка батчей на GPU и аугментация. Например, при обучении, из 27s отправка на GPU: 14s, аугментация 9s, прямое распространение 1.1s, обратное распространение с подправкой весов 2.4s. При этом время засылки батчей в GPU заметно уменьшается для небольших моделей, когда в GPU много места.
Приведём графическое представление этой архитектуры. Сплошные линии для "остаточных" путей соответствуют простому суммированию выхода блока и его входа (residual=1), а пунктирные - с весами конволюции с ядром 1x1 (residual=2):
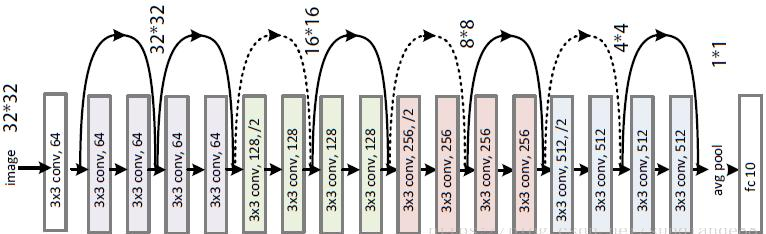
Экспериментируем с архитектурой ResNet
Отключим пакетную нормализацию, но добавим смещения в фильтры:
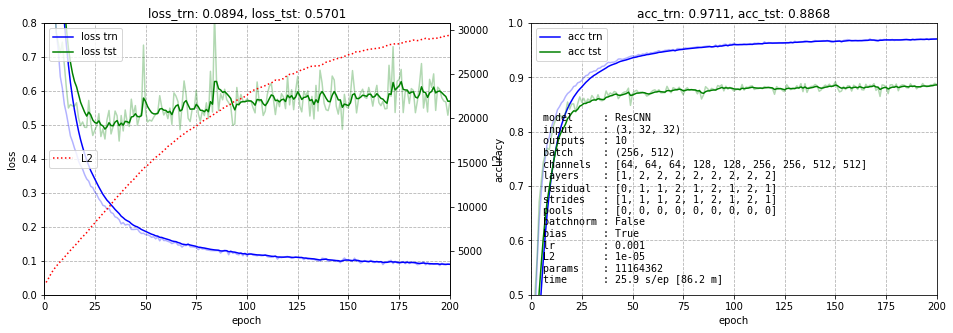
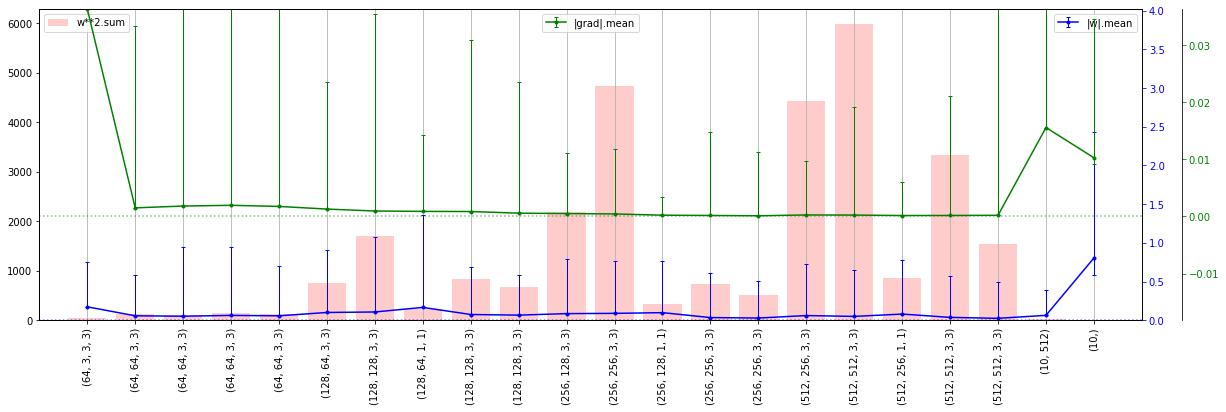
Вернём пакетную нормализацию, но отключим "остаточные" пути:
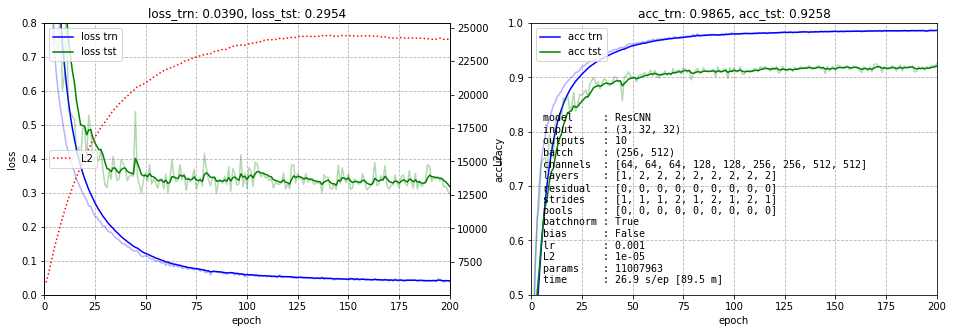
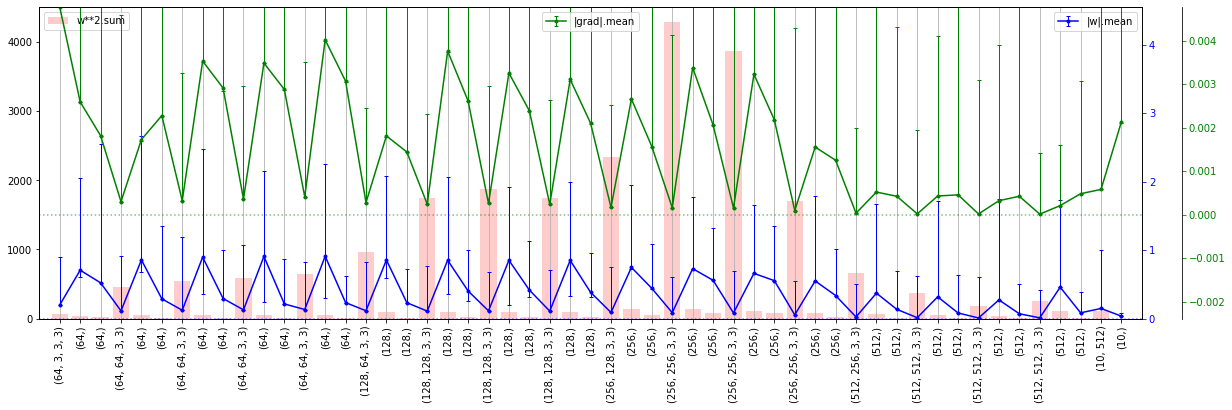
Вернём всё, но вместо stride=2 поставим в тех-же блоках (но на выходе!) pool=2 (как и должно быть, при этом несколько выросло число параметров). Учиться стал чуть лучше и на 300 эпох даже дошёл до точности 0.9326
Уменьшим глубину сети не меняя число признаков (каналов):