ML: RASA NLU Конвейер
Введение
Этот документ продолжает описание движка RASA для построения чатботов. Подробно разбирается конвейер компонент для NLU-модуля. Правильное задание этих компонент и их параметров повышает качество классификации.
В файле config.yml, в разделе pipeline (конвейер) перечисляется последовательность выполнения различных компонент (классов), которые строят векторы признаков, классифицируют намерения (intent) и извлекают из них сущности (entity). Вывод каждого компонента может использоваться любым другим компонентом, который идет после него в конвейере. Все компоненты обучаются и обрабатываются в том порядке, в котором они перечислены в конвейере.

- Tokenizer - разбивает текст на отдельные слова (токены).
- Featurizers - формируют векторы признаков
- Intent Classifiers - классифицируют намерения
- Entity Extractors - извлекают из намерений сущности
Например, простейший конвейер может иметь вид (DIETClassifier объединяет в себе две последние задачи):
pipeline: # config.yml
- name: WhitespaceTokenizer # разбивает текст на токены
- name: CountVectorsFeaturizer # признаки в виде "мешка слов"
- name: CountVectorsFeaturizer # признаки в виде N-грамм
analyzer: char_wb # букв
min_ngram: 1 # от одной
max_ngram: 4 # до четырёх штук
- name: DIETClassifier # классификатор для намерений и сущностей
epochs: 100 # учится на 100 эпохах
constrain_similarities: true
Tokenizer
Tokenizers (токинизатор) - разбивает текст на слова (токены). Это стартовая задача NLU-конвейера, которая всегда идёт первой. По умолчанию это делает комонент WhitespaceTokenizer:
- name: WhitespaceTokenizer
case_sensitive: False # можно перевести в нижний регистр
WhitespaceTokenizer
убирает все знаки препинания (кроме точек и запятых в числах) и чистит текст от смайликов,
корректно обрабатывая url и e-mail (во второй строке токены разбиты вертикальной чертой):
text: "Да,это стоит 10,000.00$ :) info@google.com http://google.com (067)565-18-18?" tokens: |Да,это|стоит|10,000.00|info@google.com|http://google.com|(067)565-18-18|Видно, что он неверно токинезирует слитые знаком препинания слова "Да,это" и выбрасывает вопросительный знак, который может быть значимым для классификации намерения (человек задал вопрос). Если использовать вместо него токинизатор SpacyTokenizer результат будет другой:
tokens: |да|,|это|стоит|10,000.00|$|:)|info@google.com|http://google.com|(|067)565|-|18|-|18|?|
Он корректно разбивает токены, слитые знаком препинания, сохраняет пунктуацию, но неверно токенизирует телефонный номер. Дополнительно SpacyTokenizer генерирует леммы токенов (заменяет "likes" на "like" и т.п.), которые позже могут быть использованы в CountVectorsFeaturizer.
Как и для любой другой компоненты конвейера, при желании, можно написать собственный класс токинизатора.
Featurizers
Вектор признаков (features), получаемый из текста, затем поступает на вход нейронной сети, которая учится правильно относить текст к одному из намерений (intent). Признаки бывают двух видов:
- Sparse Features (разряженные признаки) - состоят из массива нулей и единиц, в котором, обычно, единиц существенно меньше. Единица означает присутствие некоторого признака, а ноль - его отсутствие. Такие признаки, например, создаются с помощью CountVectorsFeaturizer (мешок слов и n-грамм) и LexicalSyntacticFeaturizer (его признаки - это токен в начале текста, в конце текста и т.п.).
- Dense Features (плотные признаки) - это вектор (массив) с вещественными компонентами. Обычно - это технология embedding (word2ve). Чтобы работали плотные признаки, необходимо использовать SpaCyFeaturizers для соответствующего языка.
Все разряжённые и плотные признаки объединяются в единый вектор признаков, характеризующий данный токен:
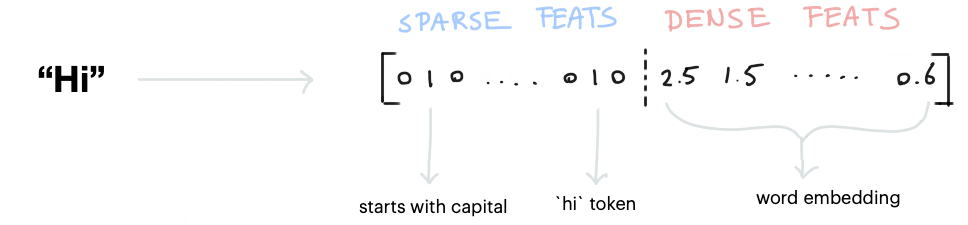
По-мимо совокупности векторов признаков для каждого токена, строится также вектор признаков всего предложения, который называется CLS:

RASA позволяет создавать свои компоненты для построения векторов признаков, которые могут "вносить свой вклад" в общий вектор признаков конвейера.
Intent Classifiers
После построения векторов признаков, RASA производит классификацию намерений. Универсальный классификатор DIETClassifier использует, как векторы токенов, так и CLS вектор всего предложения. При этом он одновременно классифицирует намерение и извлекает из него сущности:
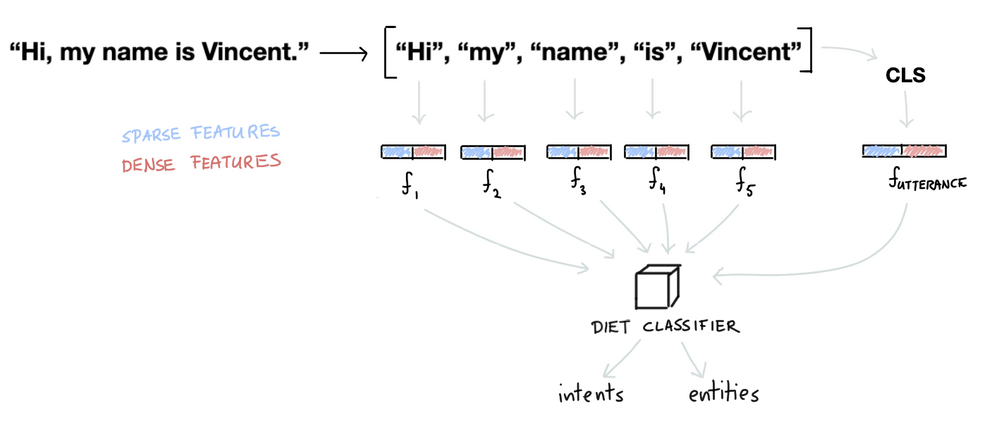
"Внутри" DIETClassifier находится достаточно сложная нейронная сеть, использующая архитектуру Transformer.
Entity Extractors
Некоторые, особенно шаблонные сущности, стоит извлекать не при помощи DIETClassifier, а специализированными компонентами типа RegexEntityExtractor. К таким сущностям относятся числа, телефонные номера, адреса элелектронной почты и т.п. Поэтому в конвейере, обычно, используется несколько компонент по извлечению сущностей:
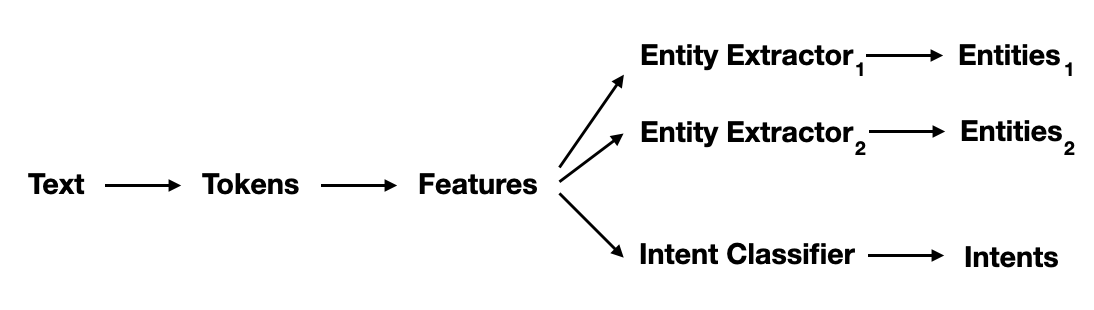
Каждый из них может извлекать различные части входного текста.
Конвейер в действии
Приведём пример последоваетельной работы различных компонент конвейера:

Полезная информация
