ML: Чатбот RASA: Истории и правила
Введение
Истории в фреймворке RASA являются примерами диалогов, на которых обучается достаточно сложная нейронная сеть. Как и любое обучение - это магия. История состоит из списка пронумерованных "токенов", из фиксированного "словаря", состоящего из намерений (intent) человека и действий (action) бота. Например, если намерения greet и goodbye имеют номера 1 и 2, а отклики utter_greet и utter_goodbye имеют номера 3 и 4, то история
- story: привет и пока # data/stories.yml steps: - intent: greet # 🙎 привет - action: utter_greet # 💻 Привет, рад встречи - intent: goodbye # 🙎 до завтра - action: utter_goodbye # 💻 До скорой встречи!это последовательность 1,3,2,4. Задача нейронной сети RASA, научиться по входу 1,3,2 на выходе выдавать следующий номер (отклик) 4. При обучении используются истории, имеющие различную длину и RASA учится предсказывать любой отклик данной последовательности. В примере выше это также 1 -> 3. На самом деле ситуация чуть хитрее. Каждый шаг истории (выше 1, 2 и т.д.) дополнительно включает список имен сущностей, извлеченных из этого намерения (без их значений) и текущие значения всех слотов. Все эти составляющие, превращаются в вектор вещественных чисел. История представляет собой последовательность таких векторов, по которой нейронная сеть учится предсказывать следующую реакцию бота.
Так как нейронная сеть использует механизм внимания, то в длинных обучающих последовательностях могут быть "пойманы" достаточно нетривиальные закономерности диалога. Однако, как уже сказано выше, RASA - это большой магический чёрный ящик, поэтому результат может быть непредсказуемым. В любом случае, чем больше историй, тем, обычно, лучше и хорошо, если более вероятные продолжения встречаются чаще, чем менее вероятные. Напомним, что необходимо следить за ошибками обучения нейронной сети (последний прогресс-бар в обучении ядра). Если аккуратность (acc) заметно меньше 1, а ошибка (t_loss) больше 0.5, следует увеличить число эпох epochs в разделе TEDPolicy файла config.yml.
Ветвления
Для создания большого числа обучающих историй, в RASA существуют различные механизмы. Простейший - это блок логического ИЛИ (or), который позволяет в одной истории сразу описать несколько вариантов намерений человека:
stories: # data/stories.yml
- story: newsletter signup with OR
steps: # цепочка шагов истории:
- intent: signup_newsletter # 🙎 я хочу подпиcаться на рассылку новостей
- action: utter_ask_confirm_signup # 💻 Вы точно этого хотите?
- or: # далее одно из этих намерений:
- intent: affirm # 🙎 да, точно
- intent: thanks # 🙎 спасибо
- action: action_signup_newsletter # 💻 Я Вас подписываю
Такая история в результате превратиться в две похожие истории. В одной будет стоять intent: affirm,
а во второй - intent: thanks.
В разделе or к сожалению, можно размещать только намерение (intent).
Склейки
Часто повторяющиеся куски историй можно выделить в отдельные "мини-истории", "склеивая" их друг с другом при помощи свойства checkpoint, после которого идёт любое название (имя склейки):
stories: # data/stories.yml - story: beginning of conversation steps: - intent: goodbye - action: utter_goodbye - checkpoint: ask_feedback # эта история может быть продолжена - story: user provides feedback steps: - checkpoint: ask_feedback # например, вот этой историей - action: utter_ask_feedback - intent: inform - action: utter_thank_you
В данном случае RASA создаст одну длинную историю, "склеивая" эти два куска на точке checkpoint. Если добавить ещё несколько кусков с таким же checkpoint в начале или конце, то получатся истории со всеми возможными склейками. Следует помнить, что активное использование checkpoint может неконтролируемо порождать очень много историй и увеличивать время обучения. К тому же, подобные "переходы" между историями бывает сложно прослеживать, что приводит к логическим ошибкам.
Окончание с продолжением
Вместо склеек, в ряде случаев, эффективным оказывается другой механизм. Разобъём длинную историю на куски так, чтобы один кусок оканчивался некоторым действием, а другой этим же действием начинался. Пусть, например, после вопроса "Я могу Вам помочь?" может следовать два ответа ("да" и "нет"). Тогда такое ветвление можно оформить в виде трёх историй:
- story: 1 steps: ... - action: utter_can_i_help - story: 2 | - story: 3 steps: | steps: - action: utter_can_i_help | - action: utter_can_i_help - intent: yes | - intent: no - action: utter_2 | - action: utter_3 ... | ...По первой истории RASA учится предсказывать отклик utter_can_i_help, в вторая и третья обучают последовательностям: (utter_can_i_help, yes, utter_2) и (utter_can_i_help, no, utter_3). В каждом из таких кусков должно присутствовать хотя бы одно намерение (intent).
☝ Если при составлении истории активно используются ветвления и склейки, имеет смысл перейти от историй к кейсам, позволяющим записывать истории и их ветвления в более структурированном виде.
Состав шага истории
Каждая история состоит из шагов. Условно говоря, существуют шаги намерений (в которых кроме intent стоит служебное действие action_listen - слушаю человека) и шаги действий, состоящие из действия бота и последнего намерения человека. Если в истории подряд идут несколько action, в каждый такой шаг также добавляется вектор последнего намерения, который стоит выше.
Любой шаг истории содержит значения всех слотов. Это важная составляющая вектора признаков, характеризующего данный шаг. Если при описании обучающих историй значения слотов не прописывать, то это затрудняет правильное предсказание, так как в реальном диалоге слоты будут некоторым образом заполнены. Если такая комбинация в историях не была учтена, этот шаг окажется отличным от "эталонного" шага истории. Естественно, сеть на каждом шаге учитывает также намерение человека и действие бота, поэтому она может и справиться с "неправильным" вектором слотов. Но следует всё же облегчать ей жизнь.
Для описания значения слотов служит раздел истории slot_was_set. Перечисляя в нём значения слотов, мы указываем RASA, что в этом месте они скорее всего имеют эти значения, что важно для выбора следующего действия:
stories:
- story: story with a slot
steps:
- intent: celebrate_bot
- slot_was_set: # к данному моменту слоты имеют значения:
- NAME # текстовый NAME как-то заполнен != null
- AGE: 16 # вещественное AGE равно 16
- FEEDBACK: positive # категориальный FEEDBACK равен positive
- action: utter_yay # тогда далее должен идти отклик utter_yay
Подчеркнём, что в slot_was_set перечисляются не только те слоты,
которые поменяли своё значение на данном шаге, но и все слоты влияющие на диалог (имеющие свойство influence_conversation: true).
Впрочем, если в рамках данной истории слот был установлен и далее не меняется,
его не нужно повторять в slot_was_set.
При этом (с некоторой оговоркой, см. ниже) неопределённые слоты (null) перечислять не надо,
так как по умолчанию их вектор забивается нулями.
Если при обучении нейронная сеть видит только примеры с одним и тем же значением слота, то она перестаёт на него реагировать. Поэтому желательно приводить контр-примеры, в которых слот не определен или имеет различные значения.
Кроме значения слотов, шаг использует список извлечённых из намерения сущностей, которые также необходимо перечислять в свойстве entities данного намерения:
stories:
- story: story with entities
steps:
- intent: account_balance # из намерения account_balance
entities: # была извлечена сущность
- ACCOUNT_TYPE: credit # с именем ACCOUNT_TYPE и значением credit
- action: action_credit_account_balance # тогда будет вызван скрипт
Если такое извлечение не произошло, эта история не будет примером для обучения
с целью предсказания действия action_credit_account_balance
(которое оформляется в виде кода на Python).
Если имя слота и сущности совпадают, то после entities
перечислять значения этих слотов в slot_was_set не обязательно (они туда попадут автоматически).
Как слоты влияют на историю
При указании в slot_was_set или entities значений слотов очень важно учитывать их тип.
✒ Значение текстового слота (text) не играет роли и учитывается лишь тот факт, что в него что-то записали (или не записали). Поэтому в "векторе шага" текстовый слот равен [1.0] (задано значение) или [0.0] (не задано). Ниже первые три варианта дадут одинаковый результат (в отличии от последнего, где слот не определён):
- slot_was_set: | - slot_was_set: | - slot_was_set: | - slot_was_set: - NAME | - NAME: маша | - NAME: саша | - NAME: null
✒ Если нужна конкретизация значения, следует использовать категориальные слоты (categorical).
Для них различают три ситуации:
- задано конкретное (предопределённое) значение;
- в нём находится "мусор" (не совпадающий ни с одним из разрешённых значений);
- значение не установлено (null).
✒ Вещественный слот (float) в котором не установлено max_value ведёт себя как текстовый, т.е. его значение роли не играет и различаются случаи: "он есть" или "его нет" (null), а значение в векторе признаков всегда равно 1.0. При наличии max_value и min_value (если последнего нет, то это 0), происходит нормировка значения слота к диапазону [0...1]. Например, если установлено max_value: 1000 и значение равно 16, то вектор слота будет состоять из двух компонент [1.0, 0.016] (первая - установлен или нет). Если для числового слота в entities не указать значения, то оно интерпретируется как null. Когда указывается конкретное значение (AGE: 16), то именно это значение попадёт в вектор слотов. Если в реальном диалоге будет введено другое значение, то вектор слота шага будет отличаться от эталонного вектора шага истории.
Обратим внимание, что при большом max_value, близкие значения слота для сети оказываются мало различимыми. Поэтому тип float имеет смысл использовать только для узкого диапазона или при большом разбросе значений. Например, в истории интересной для молодёжи мы пишем 16, а для пожилых - 70. В реальном диалоге, при вводе 12 или 20 скорее всего будет срабатывать "молодёжное продолжение" истории, а при больших значениях - "пожилое продолжение".
Ещё несколько общих замечаний:
- Если значение слота любого типа указано на данном шаге (в entities или slot_was_set), то он дальше автоматически будет добавляться в векторы слотов всех шагов истории, пока не "получит" значение null. Eсли слот сбрасывается в null или меняет значение в кастомном экшене, то это надо явным образом указать (при тренировке RASA об этом ничего не знает).
- Независимо от значений слотов (даже если стоит null!) в разделе entities, их список попадает в вектор сущностей. Эти значения (включая null) будут влиять на формируемый далее список значений слотов (при установленном auto_fill: true). В частности, если у сущности стоит null, то в вектор слотов попадут нулевые компоненты. Но лучше не использовать null в разделе entities, сбрасывая слоты в null при помощи slot_was_set.
- Не стоит выставлять initial_value: ЗНАЧЕНИЕ_ПО_УМОЛЧАНИЮ для слотов, влияющих на историю (в разделе slots в файле domain.yml). В этом случае они добавляются в начала всех историй (которые, возможно, сработают не в начале диалога) и что хуже, также добавляются в правила. Последнее убивает работу chitchat (см. ниже), если слот на этом шаге имеет другое значение.
- Не стоит slot_was_set без необходимости ставить перед намерением intent, так как тогда он попадает в предыдущий шаг истории. В частности, это относится и к началу истории, где он превращается в шаг, содержащий только вектор слотов.
Правила
Правила содержат шаблоны коротких кусков диалога, которые всегда должны идти по одному и тому же пути. Обычно их используют, если для ответа на некоторые сообщения не требуется никакого контекста и ответ должен быть фиксированным. Правила могут включать только одно намерение пользователя (intent), после которого идёт одно или несколько ответов бота (action). Правилами не стоит злоупотреблять, так они являются "необучаемой" частью историй. Чтобы правила работали, в config.yml надо указать:
policies: # config.yml - name: RulePolicyЕсли раздел policies полностью пустой, то этого можно не делать, т.к. в этом случае будут включены политики по умолчанию, в которые RulePolicy входит.
Пусть необходимо, чтобы в начале диалога (и только в начале) срабатывало приветствие. Тогда у правила устанавливается свойство conversation_start:
rules: # data/rules.yml - rule: Правило 1> отвечаем на приветствие вначале диалога: conversation_start: true steps: - intent: greet # 🙎 привет - action: utter_greet # 💻 Рад встречи с тобой!Повторное приветствие greet внутри диалога это правило не активирует. Теперь приветствие можно не добавлять в примеры историй, так как оно заложено в "рефлективный ответ" в форме правила. Более того, если такого куска нет в историях, то после того, как RulePolicy предсказывает отклик utter_greet, нейронная сеть обученная на историях (TEDPolicy) будет делать прогнозы так, как если бы greet, utter_greet не произошли!
Условия в правилах
В блоках condition правила можно перечислять условия срабатывания правила. Например, пусть необходимо чтобы правило сработало только, если, когда-либо ранее был задан слот PERSON и к текущему моменту он не сброшен в null. Тогда это надо указать в разделе slot_was_set:
rules:
- rule: Правило 2> Говорим 'До скорой встречи PERSON', если человек сообщил имя
condition:
- slot_was_set: # правило сработает, если
- PERSON # слот PERSON установлен в любое значение
steps:
- intent: goodbye # 🙎 пока
- action: utter_goodbye_PERSON # 💻 До скорой встречи Настя
- rule: Правило 3> Говорим 'До скорой встречи', если человек не сообщал имя
condition:
- slot_was_set: # правило сработает, если
- PERSON: null # слот PERSON не был установлен
steps:
- intent: goodbye # 🙎 пока
- action: utter_goodbye # 💻 До скорой встречи
Теперь прощание, как и приветствие, можно убрать из историй.
Впрочем, правило может и не сработать, если в диалоге окажутся не нулевые значения слотов,
которые не учтены в steps этих парвил.
По умолчанию, после завершения последнего шага правила, бот будет ждать следующего сообщения от пользователя. Чтобы это отменить, надо изменить свойство wait_for_user_input:
- rule: Rule which will not wait for user message once it was applied steps: - intent: greet - action: utter_greet wait_for_user_input: false # не ждём пользователяЭто указывает на то, что бот должен выполнить другое действие, прежде чем ждать дополнительных действий от пользователя.
Противоречия в правилах
Использование правил может приводить к сообщениям о противоречиях: "contradicting with rule(s)". Например, это произойдёт, если к правилам предыдущего раздела добавить ещё одно, в котором слот PERSON проверяется на конкретное значение "Настя":
- rule: Правило 4> Говорим 'Привет, рад встречи', если это Настя
condition:
- slot_was_set: # правило сработает, если
- PERSON: Настя # слот PERSON установлен в настя (неверно!)
steps:
- intent: goodbye # 🙎 пока
- action: utter_greet # 💻 Привет, рад встречи
Если PERSON текстовый слот то проверка на "Настя" на самом деле не делается, а лишь проверяется факт его заполненности, что эквивалентно правилу 2, но с другим окончанием.
Такая же проблема возникает, если есть история и правило которые оканчиваются по-разному:
stories: # data/stories.yml - story: привет и пока steps: - intent: greet - action: utter_goodbye rules: # data/rules.yml - rule: привет на привет steps: - intent: greet - action: utter_greet
Таким образом, правилами лучше оформлять короткие реакции на действия человека (например: "Сколько сейчас времени?" или "Пока"), которые в историях не встречаются.
Счастливые и несчастливые истории
Счастливая история описывает ситуацию, когда пользователь ведет себя так, как от него ожидается, т.е. делает то, что ему "положено". Например, при заказе пиццы выбирает её название, размер и количество, не отклоняясь на произвольные вопросы и не перепрыгивая назад фразами типа "а нет, всё же большую возьму". Все остальные истории несчастны (для разработчика бота). Однако их развитие также необходимо предусматривать, стараясь вернуть разговор в требуемое русло.
Уменьшать вероятность несчастливого диалога можно правильным проектированием вопросов, задаваемых ботом. Они не должны быть слишком общими, типа "Чем я могу Вам помочь?". Наоборот, необходимо подсказывать пользователю, что ему далее следует делать: "Вы можете выбрать пиццу или напитки".
RASA может ошибаться (как в NLU-модуле, так и ядре), поэтому, при низкой надёжности распознавания намерений или предсказания события необходимо предусмотреть переформулировку вопроса бота, её конкретизацию. Если этот процесс повторяется, необходимо "откатить" существенно назад и начать всё заново. Наиболее простой способ борьбы с несчастными историями, это разработка откликов на болтовню и FAQ-вопросы.
Болтовня и FAQ
Часто человек задаёт стереотипные вопросы, например, с целью проверки пределов возможности бота: "ты бот?", тебе нравится работа? и т.п. В RASA такую болтовню называют chitchat. Кроме таких вопросов, могут быть короткие вопросы по теме, которые называют faq (часто задаваемые вопросы). На намерения chitchat или faq бот должен отвечать однообразно, независимо от того, что ранее происходило в диалоге, но при этом учитывать "тему" намерения. Для обработки этих ситуаций, в конвейере необходимо добавить ResponseSelector:
pipeline: # config.yml # ... - name: ResponseSelector epochs: 200 # сколько эпох на обучение retrieval_intent: chitchat # темы болтовни - name: ResponseSelector epochs: 200 retrieval_intent: faq # вопросы из FAQЗатем, в политиках config.yml включаем обработку правил (RulePolicy) и добавляем следующие два правила:
rules: # data/rules.yml
- rule: отклики на болтовню
steps:
- intent: chitchat # 🙎 что-то из намерений chitchat
- action: utter_chitchat # 💻 ответ на этот вопрос
- rule: отклики на FAQ-вопросы
steps:
- intent: faq # 🙎 что-то из намерений faq
- action: utter_faq # 💻 ответ на этот вопрос
В намерениях необходимо создать достаточное число примеров для
идентификации болтовни и FAQ. Имена таких намерений начинаются с chitchat,
затем идёт косая черта и уточнение темы болтовни, которая будет использоваться в откликах
(эти намерения стоит собрать в отдельном файле в папке data).
nlu: # data/nlu_chitchat.yml
- intent: chitchat/ask_name
examples: |
- Как тебя зовут?
- Могу ли я узнать твоё имя?
- intent: chitchat/ask_weather
examples: |
- Какая погода тебе нарвится?
- Тебе нравится когда жарко?
Темы болтовни называются суб-намерениями (sub-intents).
В списке намерений необходимо перечислить только, то что идёт перед чертой:
intents: # domain.yml - chitchat # все намерения chitchat/... - faq # все намерения faq/...а в файле domain.yml прописываются конкретные отклики на известные вопросы.
responses: # domain.yml utter_chitchat/ask_name: - text: "Меня зовут Смарт-бот" - text: "С утра меня звали Смарт-бот" utter_chitchat/ask_weather: - text: Мне всё равно какая погода.
Вне знаний бота
Ещё один способ борьбы с отклонением от счастливой истории, это создание намерения в котором перечисляются примеры с самыми различными вопросами и утверждениями, на которые делается общий ответ типа "Извините, но давайте вернёмся к нашей основной цели."
nlu: # data/nlu_out_of_scope.yml
- intent: out_of_scope
examples: |
- Зачем нужны девушки?
- Кто придумал компьютер?
- Нужно ли чистить зубы?
- Почему рыбы не летают?
- длыофвщшфрт
# ...
Как обычно, добавляем out_of_scope в раздел intents
файла domain.yml
и прописываем соответствующий ответ:
responses: # domain.yml utter_out_of_scope: - text: Извините, но нам лучше не отвлекаться от нашей цели.Обработку этого намерения также помещаем в правила:
rules: # data/rules.yml - rule: намерение находится вне рамок знаний бота steps: - intent: out_of_scope # 🙎 несу какую-то пургу - action: utter_out_of_scope # 💻 Нам лучше не отвлекаться от нашей цели. - action: utter_main_menu_again # 💻 Что Вы закажите, пиццу или напитки?
Неуверенность в намерениях
При распознавании намерений пользователя, NLU RASA вычисляет уровень достоверности (confidence) каждого намерения, выбирая максимальный. Это число находится в диапазоне от 0 до 1, где единица соответсвует абсолютной уверенности. Если намерение распознаётся с низкой достоверностью (nlu fallback), то лучше это обработать откликом utter_fallback типа "Я Вас не понял. Попробуйте повторить другими словами." Для этого добавляем его в раздел responses файла domain.yml, а в config.yml в конвейере прописываем:
pipeline: # config.yml # ... - name: FallbackClassifier # порог достоверности threshold: 0.7Классификатор FallbackClassifier обрабатывает входящие сообщения с низкой степенью уверенности. Намерение nlu_fallback будет вызвано, когда все другие предсказания намерений упадут ниже настроенного порога достоверности threshold. После этого будет вызван отклик utter_fallback, если определить это в правилах:
- rule: когда все намерения имеют достоверность ниже threshold (см. config.yml) steps: - intent: nlu_fallback - action: utter_fallback # 💻 Я Вас не понял. Сформулируйте по другому. - action: utter_main_menu_again # 💻 Сделайте свой следующий выбор
Неуверенность в диалоге
Ещё один источник неуверенности бота, это низкая достоверность предсказания следующего отклика (core fallback). Для обработки этой проблемы в политику RulePolicy необходимо добавить:
policies: # config.yml # .... - name: RulePolicy core_fallback_threshold: 0.4 core_fallback_action_name: action_default_fallback enable_fallback_prediction: trueЕсли достоверность предсказания продолжения истории ниже порога core_fallback_threshold, будет вызвано встроенное действие action_default_fallback, которое отправит ответ utter_default (его надо прописать в responses) и вернется к состоянию беседы до сообщения пользовател, вызвавшего откат. Поэтому это не повлияет на прогноз будущих действий.
При желании, стандартное действие action_default_fallback можно переопределить, написав соответствующий скрипт на Python.
Двухэтапный аварийный режим
Two-Stage Fallback режим включается, когда сообщение человека классифицируется с низкой достоверностью. Тогда человека просят подтвердить своё намерение. Если он подтверждает, диалог продолжается. Если нет, то человека просят (utter_ask_rephrase) перефразировать свое сообщение. Если новое намерение классифицируется с высокой достоверностью, диалог продолжается так, как бы первого "плохого" намерения не было. Если новое намерение также классифицируется с низкой достоверностью, человека снова просят подтвердить это намерение. Если подтверждает, то диалог продолжается, а если нет, то включается action_default_fallback, которое посылает utter_default и диалог продолжается, так как если бы обоих нраспознанных намерений не было.
Как и при неуверенности в намерениях, в config.yml добавляем FallbackClassifier и создаём пару подходящих откликов:
responses: # domain.yml utter_ask_rephrase: - text: I'm sorry, I didn't quite understand that. Could you rephrase? utter_default: - text: I'm sorry, I can't help you.Затем добавляем следующее правило (включив в политиках RulePolicy):
rules: - rule: Implementation of the Two-Stage-Fallback steps: - intent: nlu_fallback - action: action_two_stage_fallback - active_loop: action_two_stage_fallback
Переброска на человека
Human Handoff - см. документацию.TEDPolicy
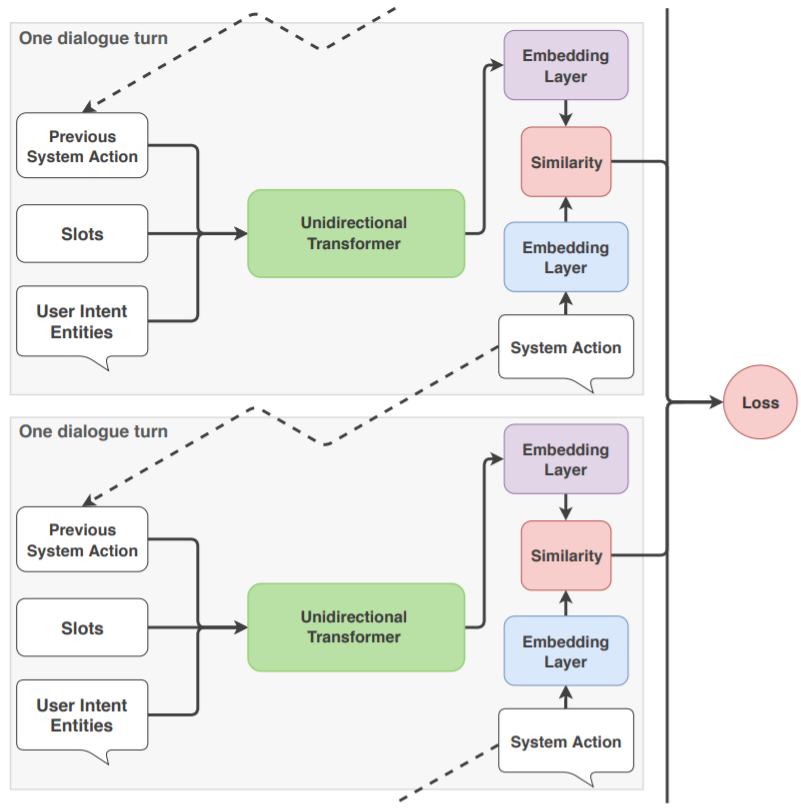 Нейронная сеть, предсказывающая продолжение
диалога называется TED (Transformer Embedding Dialogue).
Нейронная сеть, предсказывающая продолжение
диалога называется TED (Transformer Embedding Dialogue).
Более подробную информацию о её архитектуре можно найти в статье
arXiv:1910.00486.
Вкратце ситуация выглядит следующим образом. Каждое событие (шаг)
в диалоге (action и intent)
сопровождается списком слотов и извлечённых сущностей.
При этом:
Поэтому TED, обучаясь, учитывает только те слоты, которые указаны в разделе slot_was_set. В процессе же предсказания, учитывается значения всех слотов (уже заданных).
Если понятно, что питоновский скрипт поменял какие то слоты, то лучше это указать в историях (соответствующее предупреждение при запуске выдаёт и RASA). В общем, чем больше мы предоставляем информации при обучении, тем лучше. Настройка обучения TED делается в файле config.yml:
policies: # config.yml - name: TEDPolicy epochs: 200 # сколько эпох обучения max_history: 8 # по какому числу событий в диалоге прогнозСвойство max_history - это число шагов истории, которое учитывается для прогноза. Чем меньше max_history, тем может оказаться проще научить RASA. Однако, ограничивать max_history, необходимо так, чтобы у модели было достаточно предыдущих диалоговых поворотов для создания правильного прогноза. Можно также менять параметры нейронной сети: number_of_transformer_layers, transformer_size и т.п., описание которых можно найти в документации. Общий совет: пока всё работает, лучше параметры TEDPolicy не менять (кроме числа эпох обучения epochs и глубины истории max_history ).
MemoizationPolicy
Хорошо обученная нейронная сеть с правильной архитектурой должна, по возможности, не только "запоминать" обучающие примеры, но и уметь на их основе делать адекватные предсказания в незнакомых ситуациях. Впрочем, даже самая замечательная сеть может и не запомнить все обучающие данные. Поэтому в RASA есть механизм, позволяющий хранить истории вне нейронной сети. Для этого в config.yml необходимо задать:
policies: # config.yml
- name: MemoizationPolicy
max_history: 3 # длина запоминаемой последовательности
В этом случае RASA запомнит все куски историй длины 3 (по умолчанию max_history: 5).
Если такая последовательность в текущем диалоге возникла, то RASA
с единичной уверенностью (confidence) предскажет следующий отклик.
Если же такой последовательности найдено в примерах не будет,
то запускается нейронная сеть TEDPolicy.
При этом на каждом шаге должны совпадать не только action, intent,
но и список извлечённых сущностей и значения всех слотов.
Пусть история в файле stories.yml состоит из шести шагов (i1,a1,i2,a2,i3,a3), где iX - это намерение, а aX - действие и max_history: 3. Тогда в память попадёт шесть кусков (после двоеточия стоит предсказание действия и AL = action_listen - системное действие ожидания сообщения):
(i1: a1) (i1,a1: aL) (i1,a1,i2: a2) (a1,i2,a2: aL) (i2,a2,i3: a3) (a2,i3,a3: aL)
"Укороченные куски" (выше первые два) будут задействованы только в начале диалога.
В его середине всегда отсчитывается назад max_history шагов и если они
в памяти есть, то сработает MemoizationPolicy.
Пусть для примера выше с одной историей, диалог состоит из двух её повторов:
i1,a1,i2,a2,i3,a3, i1,a1,i2,a2,i3,a3.
В начале, после каждого намерения будет срабатывать MemoizationPolicy
для предсказания следующего действия (три раза).
Однако, в начале повторения истории (второе i1),
политика памяти для a1 не сработает (будет TEDPolicy), т.к. в памяти нет последовательности
(i3,a3,i1).
Затем (после i2) опять заработает MemoizationPolicy для a2,
так как соответствующий кусок (i1,a1,i2) длины max_history: 3 в памяти есть.
Таким образом, стоит стремиться к короткой памяти (малому max_history), но так, чтобы не потерять важных для принятия решения "сюжетных поворотов". Следует учитывать, что короткие истории с шагами менее max_history, в середине диалога не будут приводить у срабатыванию MemoizationPolicy. В примере выше, если задать max_history: 7 (больше чем шагов в истории), политика памяти будет срабатывать только на первых трёх намерениях (в начале диалога), а затем перестанет работать (нет ни одного куска памяти из 7 шагов).
Параметр max_history в нейронной сети TED. также не следует выбирать большим, чем нужно для правильного предсказания. Иначе длинная и "ненужная" история усложнит обучение и уменьшит надёжность предсказания.
Политика AugmentedMemoizationPolicy работает аналогично MemoizationPolicy. Дополнительно она пытается выбросить слоты, которые не влияют на заполненный кусок. Если эти слоты устанавливаются в других историях или скриптах, такое "облегчение" жизни может её и усложнить.
Таким образом, при выборе следующего отклика, сначала анализируется срабатывание правила (RulePolicy), затем наличие запомненных историй (MemoizationPolicy), а уже после этого запускается нейронная сеть (TEDPolicy):
6 - RulePolicy (высший приоритет у правил) 3 - MemoizationPolicy или AugmentedMemoizationPolicy (потом идёт память) 1 - TEDPolicy (самый низкий приоритет у нейронной сети)В любом случае необходимо экспериментировать и писать много счастливых и не очень историй.
Анализ шагов
Для понимания состава шагов, поступающих на вход TEDPolicy, полезно
их анализировать в запомненных историях MemoizationPolicy.
Они находятся в архиве модели и для их распаковки служит скрипт !memory.py.
Пусть в MemoizationPolicy стоит max_history:7 и есть единственная история из восьми шагов:
- story: привет, хочу две колы
steps:
- intent: greet # 🙎 привет
- action: utter_what_is_your_name # 💻 Привет, как тебя зовут?
- intent: my_name+my_age # 🙎 Маша, 16 лет
entities:
- NAME # слот NAME type:text
- AGE: 16 # слот AGE type:float, max_value:1000.0
- action: utter_glad_to_meet_you_name # 💻 Рад знакомству, Маша. Как жизнь?
- intent: my_life # 🙎 хорошо
entities: [ ADJ: хорошо ] # слот AGE=(хорошо,плохо) type:categorical
- action: utter_what_do_you_want # 💻 Что ты хочешь?
- intent: want_item # 🙎 хочу колу
entities: [ITEM] # слот ITEM type:text
- slot_was_set: [ AGE: null ] # сбрасываем для эксперимента слот
- action: utter_good_choice # 💻 Отличный выбор, Маша!
Запуск !memory.py выдаст восемь сохранённых кусков. Самая короткая память состоит из одного шага, предсказывающего отклик utter_what_is_your_name в начале истории:
- memo_1: - action: action_listen - intent: greet - predict: utter_what_is_your_nameНамерения всегда сопровождаются действием action_listen, а шаги действий бота повторяют последнее намерение (ниже и то и другое опущено). Одна из двух самых длинных кусков памяти из семи шагов (max_history:7 ) содержит всю историю (шаги отделены пустыми строками):
- memo_8:
- intent: greet
- action: utter_what_is_your_name
- intent: my_namemy_age
entities:['AGE', 'NAME']
- slots: {'AGE': [1.0, 0.016], 'NAME': [1.0]}
- action: utter_glad_to_meet_you_name
- slots: {'AGE': [1.0, 0.016], 'NAME': [1.0]}
- intent: my_life
entities:['ADJ']
- slots: {'ADJ': [1.0, 0.0, 0.0], 'AGE': [1.0, 0.016], 'NAME': [1.0]}
- action: utter_what_do_you_want
- slots: {'ADJ': [1.0, 0.0, 0.0], 'AGE': [1.0, 0.016], 'NAME': [1.0]}
- intent: want_item
entities:['ITEM']
- slots: {'ADJ': [1.0, 0.0, 0.0], 'ITEM': [1.0], 'NAME': [1.0]}
- predict: utter_good_choice
Обратим внимание, что явно установленный в этой истории категориальный слот ADJ автоматически повторяется в последнем шаге, а текстовый слот NUMBER там отсутствует, так как для него указано null. Если мы в slot_was_set на каком-то шаге укажем NAME:null, то начиная с этого шага в векторах слотов его больше не будет.
