ROC Stories
Введение
ROCStories - это простые истории из четырёх предложений. В тестовом наборе к каждой истории добавляются два предложения, одно из которых является осмысленным продолжением истории, тогда как второе таковым не является. Например:
Karen was assigned a roommate her first year of college.
Her roommate asked her to go to a nearby city for a concert.
Karen agreed happily. The show was absolutely exhilarating.
- Karen became good friends with her roommate. (right ending)
- Karen hated her roommate. (wrong ending )
Тренировочные данные содержат пять предложений (история и её верное продолжение).
Существует файл
100KStories.csv
(см. также файл 100KStories.zip)
c 98'167 историями, суммарно с 4'859'629 токенами
и 36'566 уникальными словоформами.
Для сравнения один том "Войны и мир" содержит около 150'000 токенов,
а wikipedia несколько миллиардов.
Загрузка историй
Так как датасет находится в csv-файле, воспользуемся библиотекой pandas. Истории будем сохранять в списке docs. Каждая тренировочная история является списком из 5 предложений. Первые две колонки csv файла являются служебными:
import re # регулярные выражения
import pandas as pd # csv-файлы
df = pd.read_csv('100KStories.zip', sep=',') # прочитать из zip-файла
docs = [] # список историй
for i in range( len(df) ):
sents = [] # список предложений
for j in range(5):
sents.append( preprocessing( df.iloc[i,2+j]) ) # добавляем предложение
docs.append(sents) # добавляем историю
Перед сохранением предложений делается небольшой препроцессинг: в функции preprocess выбрасываются специфические пробелы, кавычки, переводится всё в нижний регистр и знаки пунктуации отделяются от слов:
def preprocess(s):
s = s.translate( {ord(c): ' ' for c in "\u202f\u200b\xa0"} ) # разные пробелы в ' '
s = s.translate( {ord(c): ' ' for c in "\"«»"} ) # кавычки в ' '
s = re.sub( '\s+', ' ', s).strip() # много пробелов в один
s = s.lower() # в нижний регистр
res = []
for i, ch in enumerate(s): # отделяем пунктуацию
if ch in ".,:;!?…%" and s[i-1] != ' ': res.append(' '+ch)
else: res.append(ch)
return (' '+ "".join(res)+' ' ) # для поиска типа ' cat '
Словарь слов
Для составления словаря воспользуемся объектом Counter из стандартной библиотеки collections:from collections import Counter words = [w for d in docs for s in d for w in s.split()] cnt = Counter(words) # словарь tokens = len(wrds) # всего слов в текстеВ словаре wordID будем хранить номер слова (id) и число его появлений на миллион слов (pm), сохраняя только наиболее частые слова, встретившиеся не менее 12 раз:
V_DIM = sum( v >= 12 for v in cnt.values() ) # встретились не менее 12 раз
wordID = dict( cnt.most_common(V_DIM) ) # берем V_DIM самых частых слов
for i,w in enumerate(wordID):
wordID[w] = {"id": i, "pm": int(100000000*(cnt[w]/tokens))/100 }
В ROCStories получается 10'393 таких слов.
Ниже приведены первые 160 слов с указанием их частоты pm:
. 97442 with 5202 as 2666 some 1784 bought 1414 put 1117 thought 947 because 826 the 43773 that 4999 an 2562 found 1775 started 1411 family 1107 really 947 game 825 to 34919 up 4792 very 2541 tom 1725 house 1392 no 1089 like 939 buy 820 a 28664 's 4635 them 2435 into 1708 first 1373 just 1086 lot 911 class 814 was 24241 out 4540 not 2289 made 1705 down 1373 always 1079 happy 899 how 810 he 23352 him 4455 home 2273 school 1702 did 1313 looked 1077 has 894 find 806 she 19702 my 4454 from 2216 told 1608 night 1308 money 1044 while 893 great 802 and 19082 one 4322 after 2201 work 1600 finally 1275 said 1039 away 891 ran 797 her 14894 went 4261 we 2178 then 1594 came 1261 make 1036 before 891 john 794 , 14208 day 4183 get 2120 friend 1578 tried 1230 man 1020 gave 880 began 792 his 13346 when 3922 time 2110 car 1567 asked 1227 more 1017 much 874 parents 782 it 12458 but 3892 would 2085 me 1526 off 1201 going 1013 play 866 realized 779 i 10552 got 3884 is 2076 back 1521 never 1186 good 997 what 866 old 778 in 10470 decided 3665 go 1999 could 1514 store 1176 job 989 tim 866 food 771 of 9692 all 3389 took 1969 have 1504 this 1171 next 986 called 863 hard 749 for 8922 were 3307 there 1935 over 1463 mom 1171 needed 976 take 861 mother 744 had 8828 ! 3141 be 1919 their 1463 now 1143 couldn't 964 two 859 again 730 on 7407 so 3035 didn't 1918 saw 1444 dog 1134 every 960 do 855 other 725 they 6570 wanted 3016 friends 1900 by 1439 been 1120 too 957 left 834 last 715 at 5413 new 2776 about 1845 loved 1414 felt 1118 see 950 around 834 wasn't 712Список последних (редких слов) с pm=2.46:
sparked, olives, stance, 36, badminton,conclusion, pursuing, reddit, mattered, hitter, carole, blooms, charlene, headband, wander, mushy, otto, loretta, moses, mildly, hummus, woody, freyaПри 4.86 миллионах токенов pm=2.46 означает, что слово в корпусе встретилось 12 = 2.46*4.86 раз. Так, слово zeus (lily has two white mice , zeus and zeke .) с pm=2.46 встретилось в четырёх историях 12 раз.
Энтропия словаря историй равна 6.023.
По сравнению с более крупными корпусами текстов существует перекос на имена людей (истории о неких томах, лизах и т.п.).
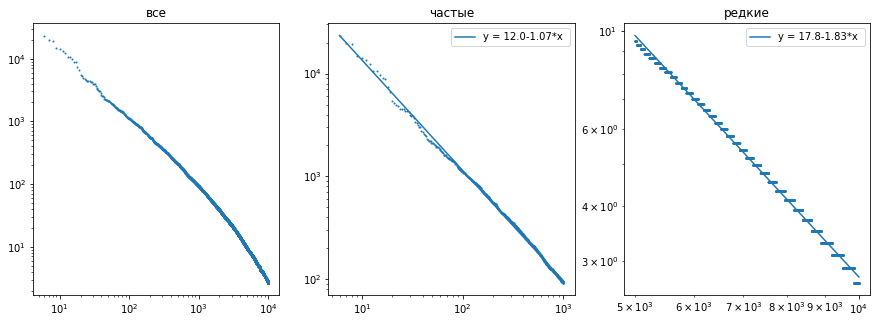
Частоты слов, как и положено, удовлетворяют закону Ципфа.
Для первых 1000 слов частота убывает как $i^{-1.07},$
где $i$ - номер
по порядку убывания частоты. Для более редких слов, частота убывает быстрее.
Ниже на графиках в логарифмическом масштабе (по обоим осям) нарисована зависимость $\mathrm{pm}(i)$: