ML: Рекуррентные сети на PyTorch
Введение
Encoder-Decoder
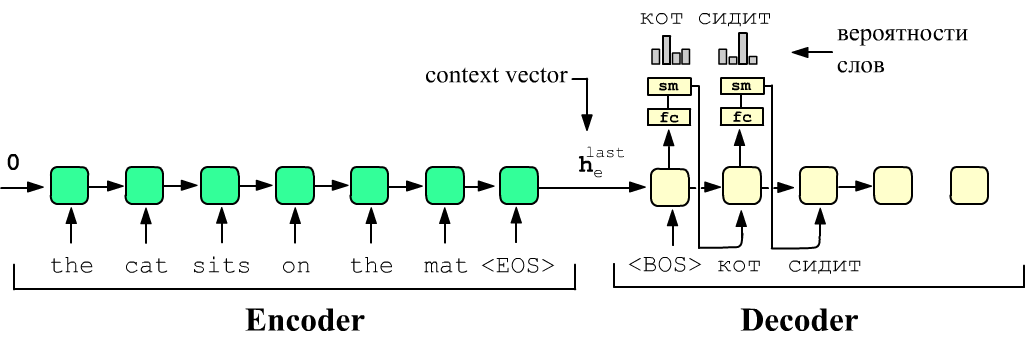
Пусть есть две различные рекуррентных сети. Первая называется Encoder, а вторая - Decoder. Энкодер на вход получает текст на одном языке (source), а декодер должен на выходе выдать текст на другом языке (target). Последняя ячейка RNN энкодера содержит на выходе вектор скрытого состояния $\mathbf{h}_e^{\text{last}}$ своей последней ячейки. Этот вектор "хранит" в себе информацию обо всём source-предложении (context vector). Его отправляют в качестве начального скрытого состояния, в первую ячейку RNN декодера.
Затем на вход первой ячейки декодера подаётся служебный токен <BOS> (begin of sentence). На выходе ячейки должно появиться слово-перевод "кот". Это означает, что выход каждой ячейки пропускается через линейный слой с числом нейронов равным числу слов в словаре. Затем softmax-функция, выдаёт вероятности слов из которых выбирается номер максимальной (argmax). Полученное слово "кот" передаётся на вход второй ячейки и т.д. пока не получится служебный токен <ЕOS> (end of sentence).
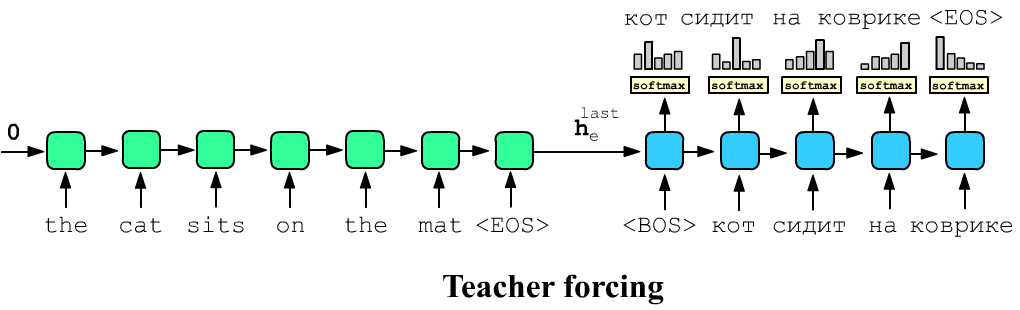
Более быстрый, но не такой качественный режим тренировки называется принудительное обучения (teacher forcing). В этом случае на все входы декодера сразу подают правильный target-перевод, а на выходе от него требуются выдать это предложение сдвинутое на одно слово влево. Обычно между режимами "честного" и "принудительного" обучения происходит случайное переключение.
Реализация Encoder-Decoder
Приведём реализацию архитектуры Encoder-Decoder на PyTorch. Пусть в словаре source-языка VOC_SIZE и размерность векторов эмбединга этих слов E = VEC_DIM. Тогда модуль энкодера имеет вид:
VEC_DIM = 100
class EncoderRNN(nn.Module):
def __init__(self, VOC_SIZE, E): # размеры словаря и эмбединга
super(EncoderRNN, self).__init__()
self.emb = nn.Embedding(VOC_SIZE, E, scale_grad_by_freq=True)
self.rnn = nn.GRU(E, E, bidirectional=True) # двунаправленная GRU
def forward(self, X):
""" X:(B,L) B - предложений с L словами в каждом. Ноль - отсутствие слова """
lens = torch.tensor([ len(x)-len(x[x==0]) for x in X ])
emb = self.emb( X.t() ) # (B,L) -> (L,B) -> (L,B,E)
Xp = pack_padded_sequence(emb, lens, enforce_sorted=False)
_, Hn = self.rnn(Xp) # (2,B,E)
Hn = torch.cat([Hn[0],Hn[1]], dim=1) # (B,2*E)
return Hn.view(1,-1, Hn.size(1)) # (1,B,2*E) только скрытое состояние
В энкодер будем засылать по одному предложению (batch_size=1) переменной длины L в виде вектора L целых чисел (long). На выходе энкодер возвращает пару Y - тензор (L,1,E) выходов всех ячеек и выход Hid последней ячейки.
class DecoderRNN(nn.Module):
def __init__(self, VOC_SIZE, E):
super(DecoderRNN, self).__init__()
self.emb = nn.Embedding(VOC_SIZE, E, scale_grad_by_freq=True)
self.rnn = nn.GRU(E, 2*E) # hidden из 2-направленной
self.out = nn.Linear(2*E, VOC_SIZE)
def forward(self, Hid, X = None, forcing = False): # Hid:(1,B,2*E), X:(B,L)
max_len = MAX_EN_LEN if X is None else len(X[0]) # максимальная длина предложения
W = torch.empty( Hid.size(1), dtype=torch.long ).fill_(BOS_INDEX)
Wrds = torch.zeros( Hid.size(1), max_len, dtype=torch.long ) # предсказ. слова
Prbs = torch.ones ( Hid.size(1), max_len, dtype=torch.float ) # вероятности
for i in range(max_len): #
W = self.emb( W.view(1,-1) ) # (1,B,E)
Y, Hid = self.rnn(W, Hid) # (1,B,2*E)
Y = self.out (Y[0]) # (B,VOC_SIZE)
Y = torch.softmax( Y, dim=1 ) # (B,VOC_SIZE)
_, W = Y.detach().topk(1, dim=1) # (B,1)
Wrds[:,i].copy_(W.squeeze()) # убираем 1 и сохраняем
if not X is None and i < X.size(1):
for b in range(X.size(0)): Prbs[b,i] = Y[b, X[b,i]]
if forcing:
W.copy_( X[:,i].view(-1,1) )
return Wrds, Prbs # (B,L), (B,L)
Суммарная модель:
class EncoderDecoderRNN(nn.Module):
def __init__(self, encoder, decoder):
super(EncoderDecoderRNN, self).__init__()
self.enc = encoder
self.dec = decoder
def forward(self, sourse, target, forcing=False): # (L1,) (L2,)
Hd = self.enc(sourse)
return self.dec(Hd, target, forcing)
gpu = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
cpu = torch.device("cpu")
encoder = EncoderRNN(len(voc_en), VEC_DIM)
decoder = DecoderRNN(len(voc_ru), VEC_DIM)
model = EncoderDecoderRNN(encoder, decoder) # экземпляр сети
model.to(gpu)
