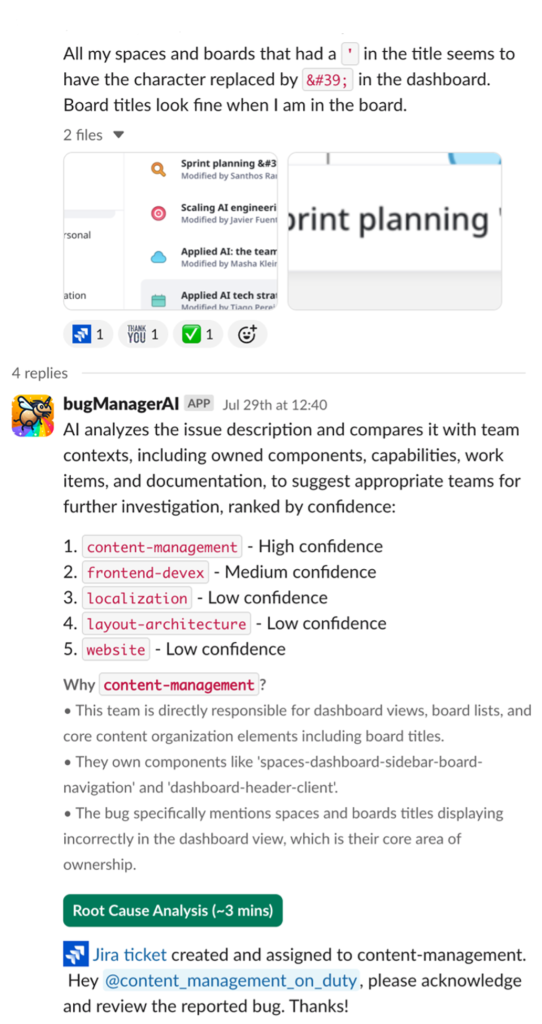
Компания Miro в партнерстве с AWS разрабатывает BugManager — решение на базе искусственного интеллекта для автоматической классификации ошибок, позволяющее сократить количество перенаправлений и время устранения неполадок. BugManager использует оптимизированные подсказки и технологию RAG (Retrieval Augmented Generation) для повышения точности классификации ошибок.

Кэролайн Улер обсуждает революцию в области биологии, связанную с обработкой данных, и потенциал машинного обучения для открытия новых возможностей понимания биологических систем. Такие достижения, как секвенирование ДНК и модели зрения, формируют новую эру в биологии, вдохновляя инновационные исследования в области машинного обучения.
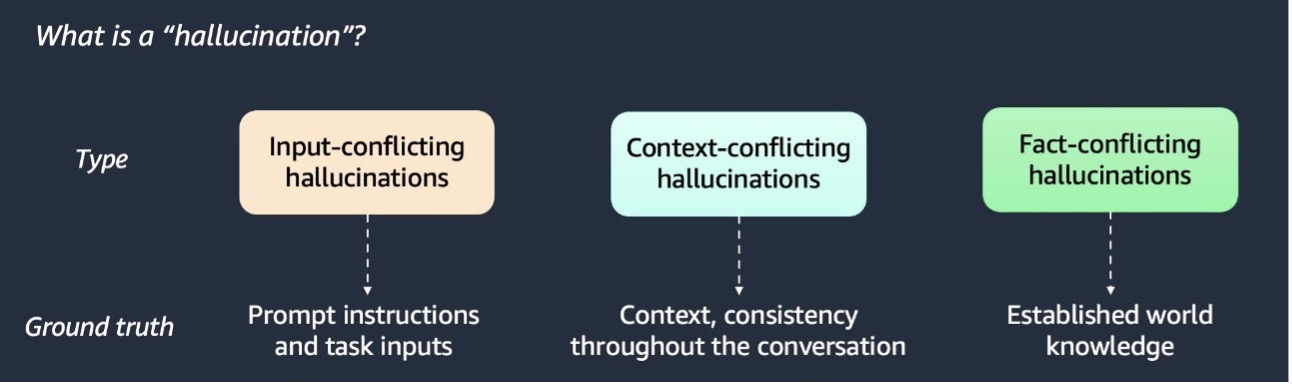
RAG улучшает ответы ИИ за счет использования дополнительных данных. Обнаружение и смягчение галлюцинаций ИИ имеет решающее значение для точности.

BERTopic, python-библиотека для моделирования тем на основе трансформаторов, использует 6 основных модулей для ускоренной обработки финансовых новостей и выявления меняющихся со временем трендовых тем. Она включает в себя вкрапления, уменьшение размерности, кластеризацию, векторизаторы, c-TF-IDF и модели представления для выявления ключевых терминов в документах.
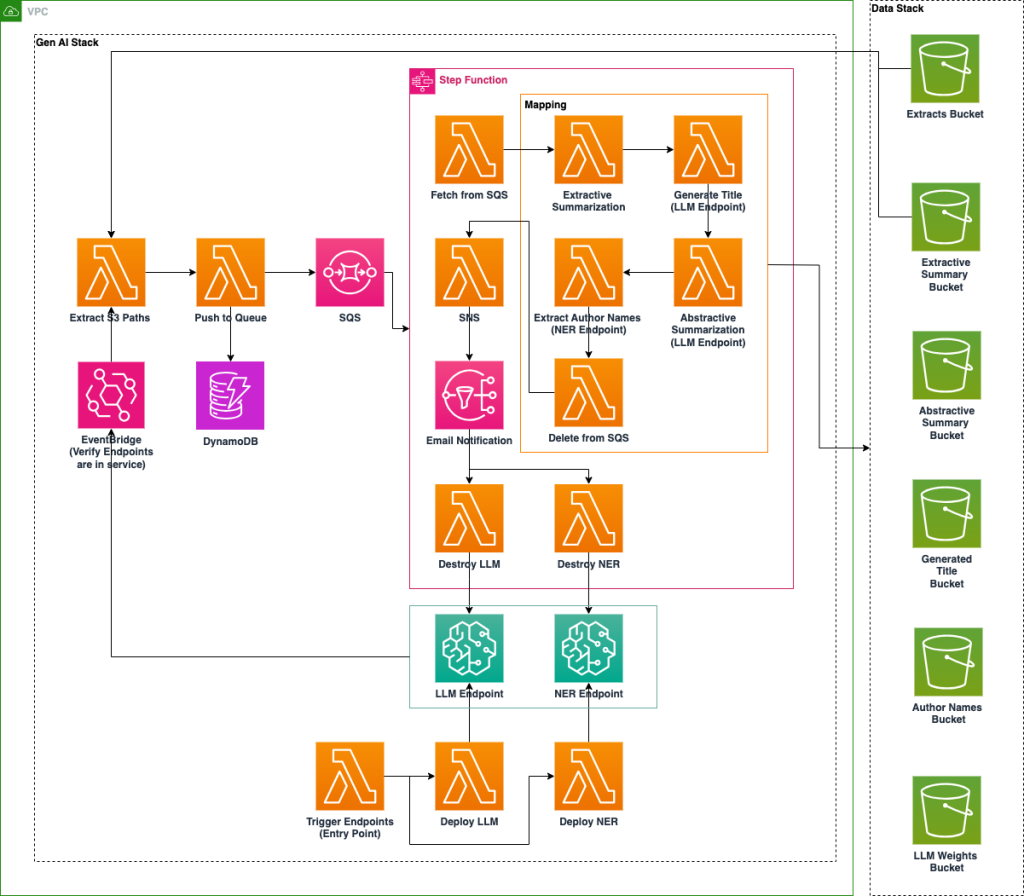
Национальная лаборатория США внедряет платформу искусственного интеллекта на базе Amazon SageMaker для повышения доступности архивных данных с помощью технологий NER и LLM. Оптимизированная по стоимости система автоматизирует обогащение метаданных, классификацию и обобщение документов для улучшения их организации и поиска.
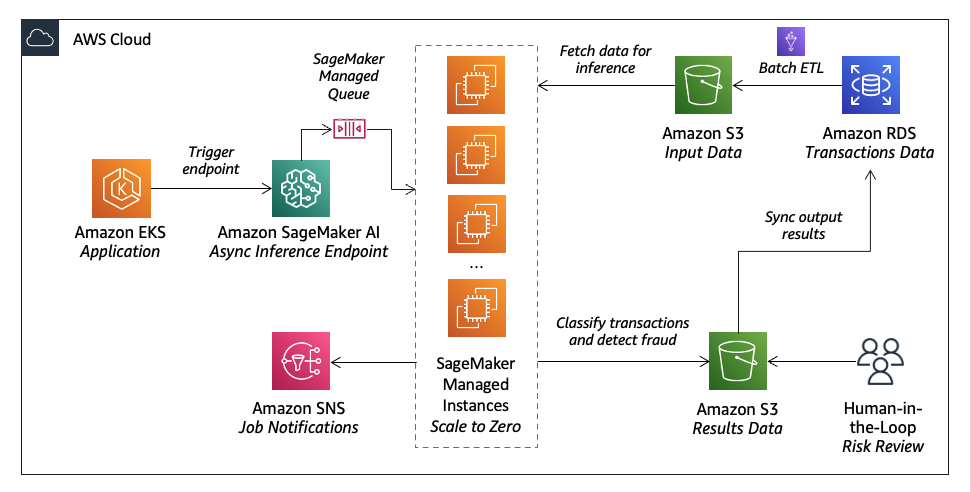
Lumi, австралийский финтех-кредитор, использует искусственный интеллект Amazon SageMaker для быстрого принятия решений о выдаче займов с точной оценкой кредитоспособности. Они сочетают машинное обучение с человеческим суждением для эффективного и точного управления рисками.

Мультимодальные вкрапления объединяют текстовые и графические данные в единую модель, позволяя использовать кросс-модальные приложения, такие как создание подписей к изображениям и модерация контента. CLIP согласовывает представления текста и изображения для классификации изображений по 0-кадрам, демонстрируя возможности общих пространств вкраплений.
Метаморфоза ML - процесс объединения различных моделей в цепочку - может значительно повысить качество модели по сравнению с традиционными методами обучения. Дистилляция знаний переносит знания из большой модели в меньшую, более эффективную, в результате чего получаются более быстрые и легкие модели с улучшенной производительностью.
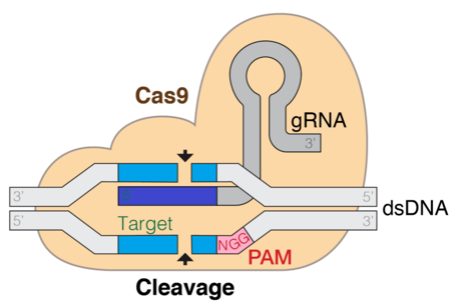
Технология CRISPR трансформирует редактирование генов, используя вычислительную биологию для прогнозирования эффективности гРНК с помощью больших языковых моделей, таких как DNABERT. Методы тонкой настройки, эффективные с точки зрения параметров, такие как LoRA, являются ключевыми в оптимизации LLM для задач молекулярной биологии.
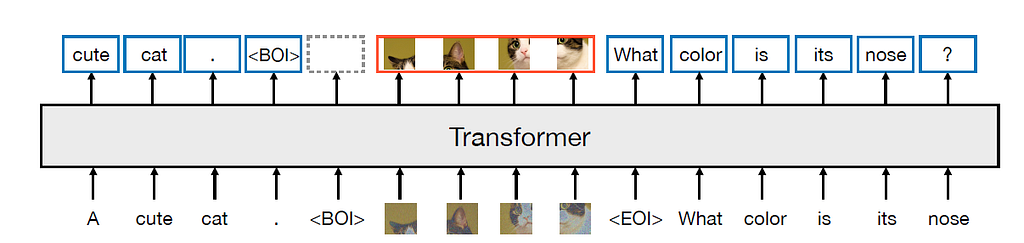
Meta и Waymo представили модель Transfusion, сочетающую трансформацию и диффузию для мультимодального прогнозирования. Модель Transfusion использует двунаправленное внимание трансформатора к лексемам изображения и задачи предварительного обучения для текста и изображения.
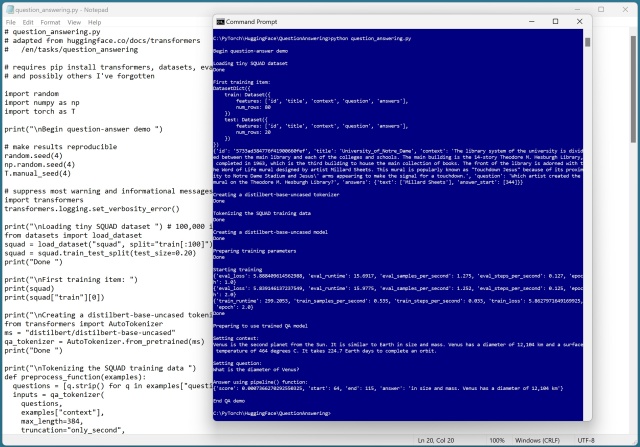
HuggingFace предлагает обширную библиотеку предварительно обученных моделей языка и изображений для решения задач естественного языка. Несмотря на некоторые ошибки, система QA демонстрирует простоту и эффективность использования функции pipeline().
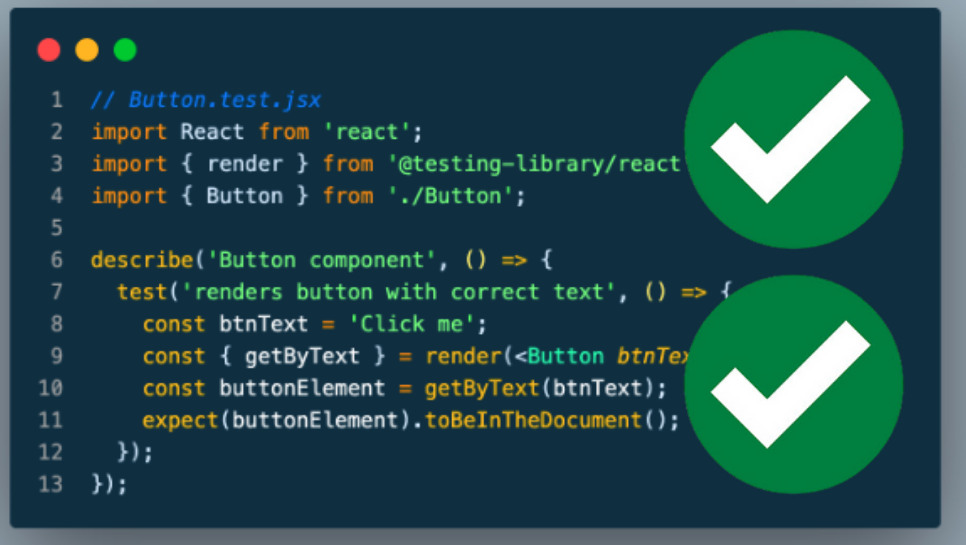
Узнайте, как тестировать проекты машинного обучения с помощью Pytest и Pytest-cov. Руководство посвящено BERT для классификации текстов с использованием библиотек промышленного стандарта.

Распознавание именных сущностей (NER) извлекает сущности из текста, традиционно требуя тонкой настройки. Новые большие языковые модели, такие как LLM Amazon Bedrock, позволяют выполнять NER с нулевым результатом, революционизируя извлечение сущностей.
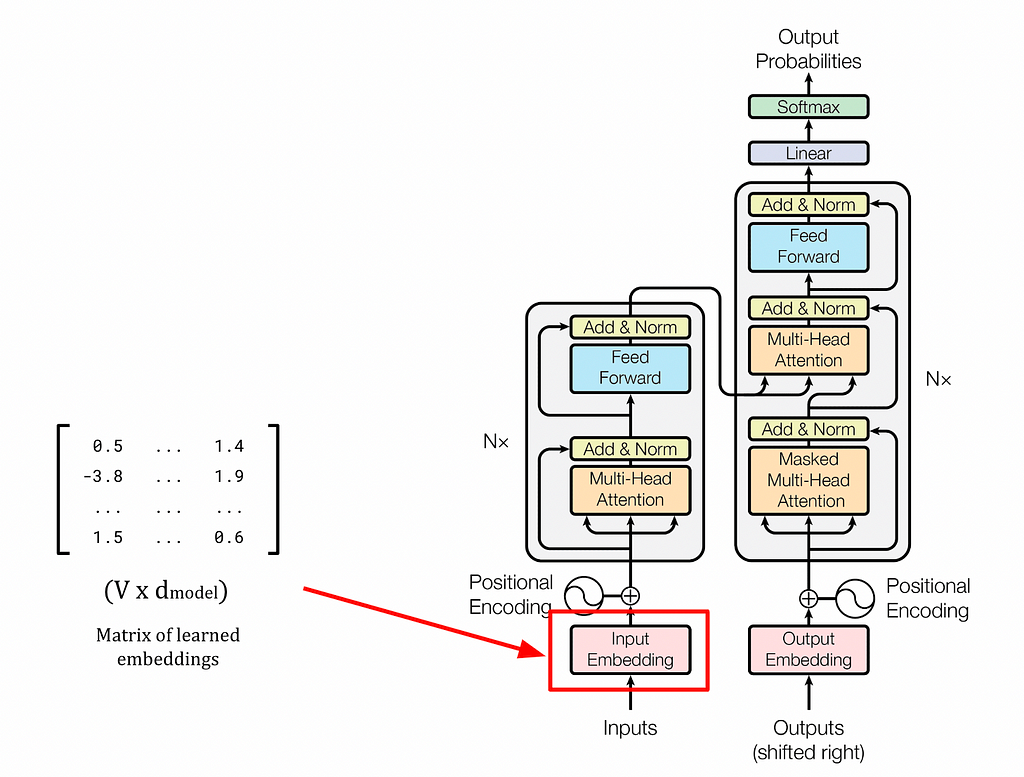
Крупные языковые модели, такие как GPT и BERT, опираются на архитектуру Transformer и механизм самовнимания для создания контекстуально насыщенных вкраплений, что произвело революцию в НЛП. Статические вкрапления, такие как word2vec, не справляются с захватом контекстуальной информации, что подчеркивает важность динамических вкраплений в языковых моделях.
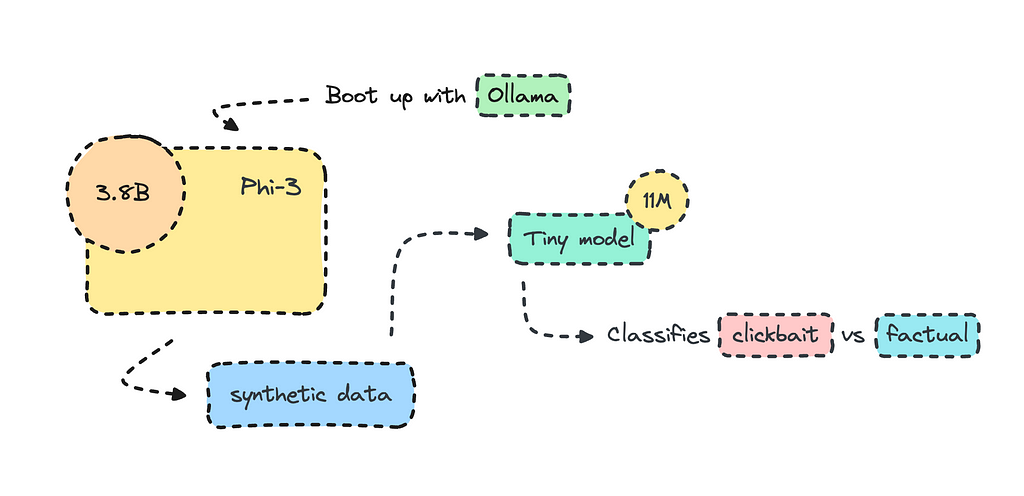
Phi-3 от Microsoft создает небольшие оптимизированные модели классификации текста, превосходящие более крупные модели, такие как GPT-3. Генерация синтетических данных с помощью Phi-3 через Ollama улучшает рабочие процессы ИИ для конкретных случаев использования, предлагая понимание классификации «кликабельного» и фактического контента.
BERT, разработанная Google AI Language, - это новаторская модель большого языка для обработки естественного языка. Ее архитектура и фокус на понимании естественного языка изменили ландшафт НЛП, вдохновив такие модели, как RoBERTa и DistilBERT.
Откройте для себя последние революционные исследования в области применения искусственного интеллекта в здравоохранении. Узнайте, как такие компании, как IBM и Google, революционизируют уход за пациентами с помощью инновационных технологий.

В 2021 году доходы фармацевтической промышленности США составили 550 миллиардов долларов, а прогнозируемые расходы на фармаконадзор к 2022 году - 384 миллиарда долларов. Для решения задач мониторинга нежелательных явлений разработано решение на основе машинного обучения с использованием Amazon SageMaker и модели BioBERT компании Hugging Face, обеспечивающее автоматическое обнаружение из различ...
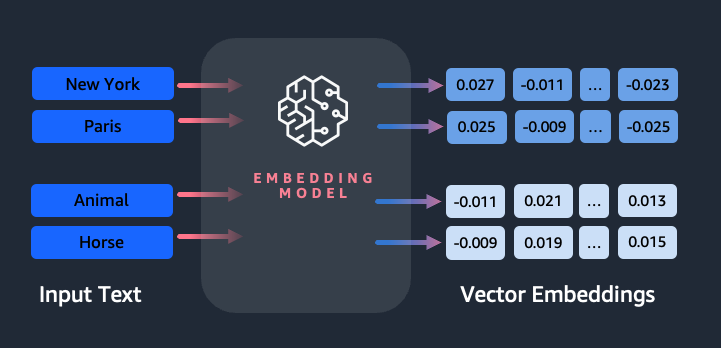
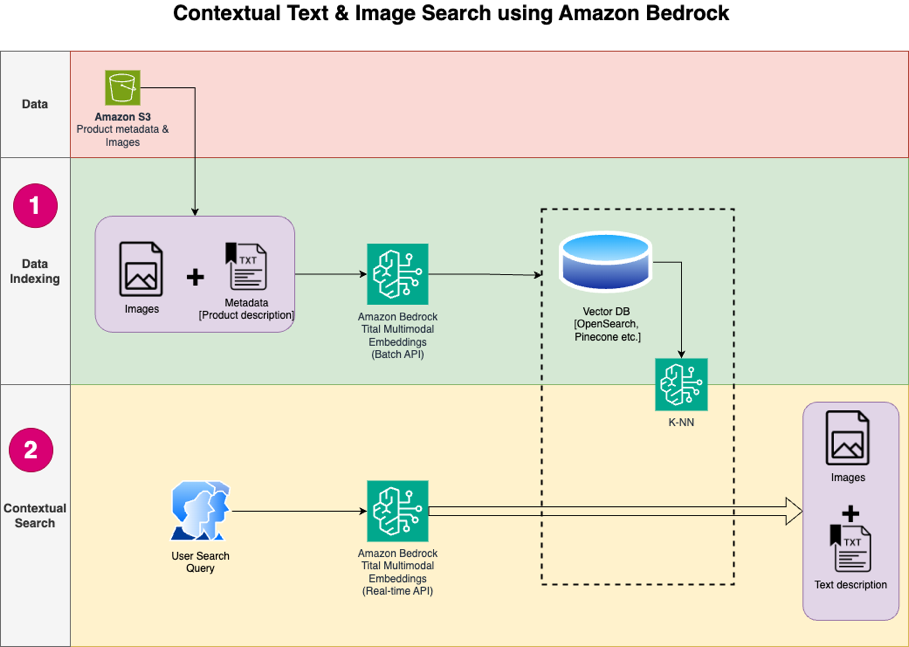
Amazon Titan Text Embeddings - это модель встраивания текста, которая преобразует текст на естественном языке в числовые представления для поиска, персонализации и кластеризации. В ней используются алгоритмы вкрапления слов и большие языковые модели для выявления семантических связей и улучшения последующих задач NLP.
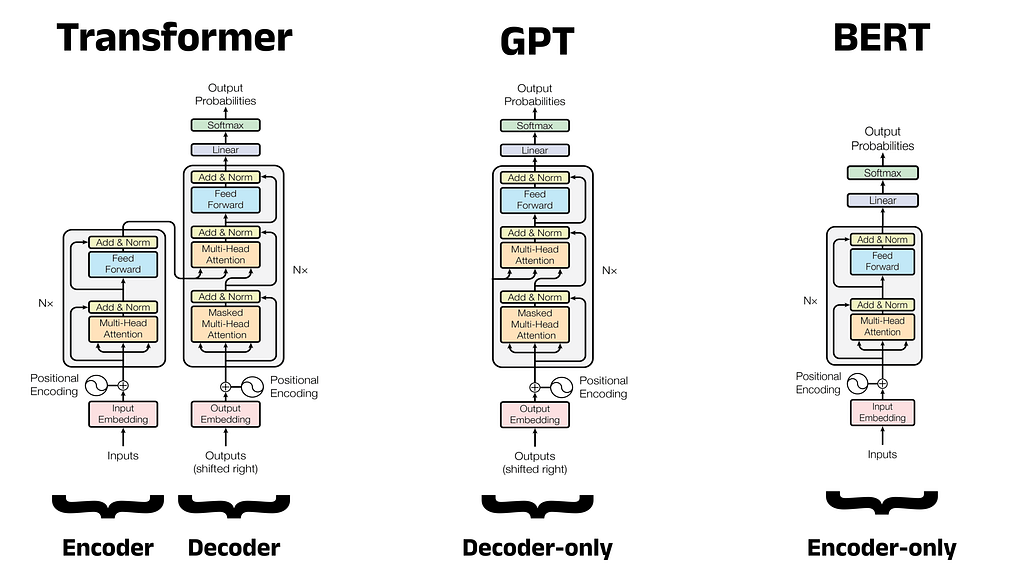
В 2017 году Google Brain представил Transformer - гибкую архитектуру, которая превзошла существующие подходы к глубокому обучению и теперь используется в таких моделях, как BERT и GPT. GPT, модель декодера, использует задачу языкового моделирования для генерации новых последовательностей и следует двухэтапной схеме предварительного обучения и тонкой настройки.
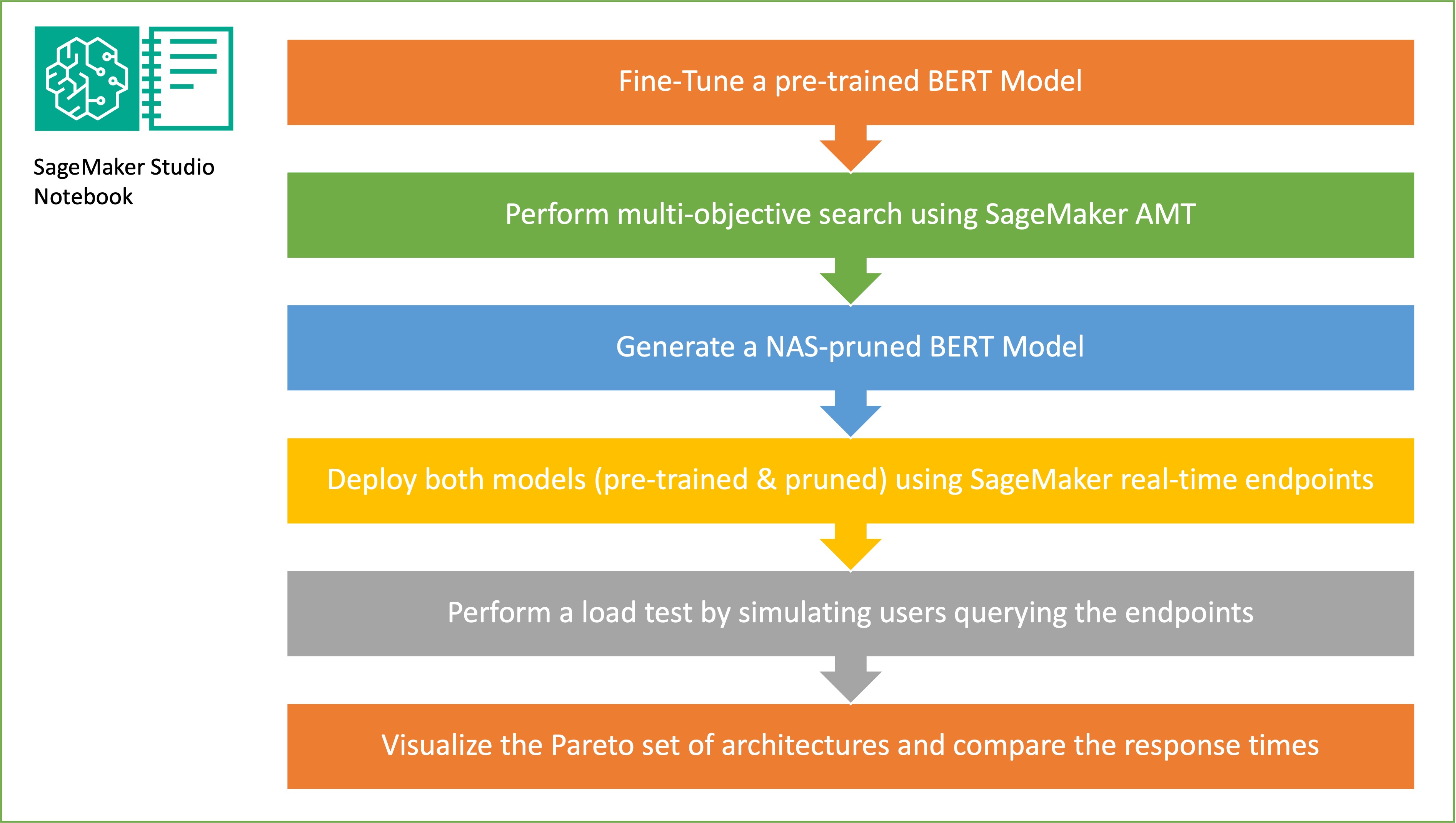
В этой статье демонстрируется, как поиск нейронной архитектуры может быть использован для сжатия точно настроенной модели BERT, что повышает производительность и сокращает время вывода. Применение структурной обрезки позволяет уменьшить размер и сложность модели, что приводит к ускорению времени отклика и повышению эффективности использования ресурсов.
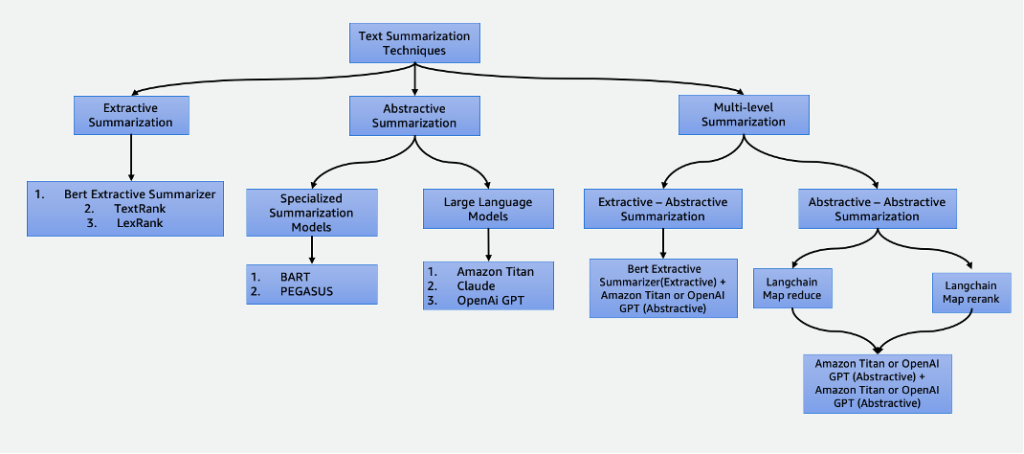
Обобщение данных играет важную роль в нашем мире, основанном на данных, позволяя экономить время и улучшать процесс принятия решений. Оно находит различные применения, включая агрегирование новостей, обобщение юридических документов и финансовый анализ. С развитием НЛП и ИИ такие техники, как экстрактивное и абстрактное обобщение, становятся все более доступными и эффективными.