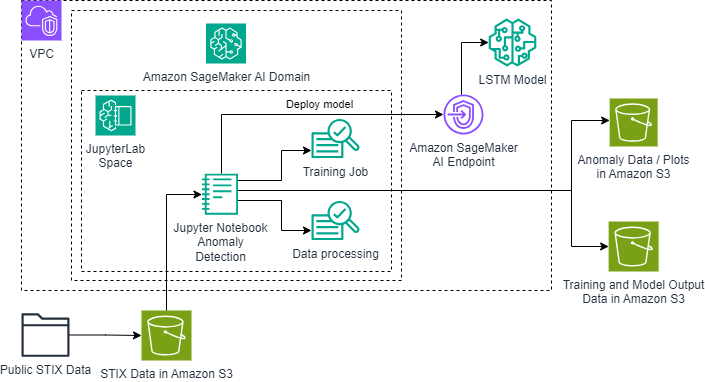
Современные методы машинного обучения помогают выявлять солнечные вспышки путем анализа рентгеновского излучения. Передовые модели глубокого обучения, такие как сети LSTM, позволяют надежно выявлять аномалии в многоканальных рентгеновских данных для комплексного мониторинга солнечной активности.
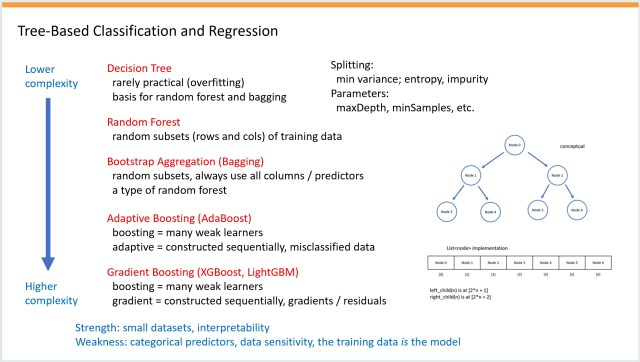
Резюме: Подробная презентация в формате PowerPoint о нейронных сетях, в которую были включены методы на основе деревьев. Также рассмотрены и оценены три сюжета научно-фантастических фильмов, связанных с памятью.
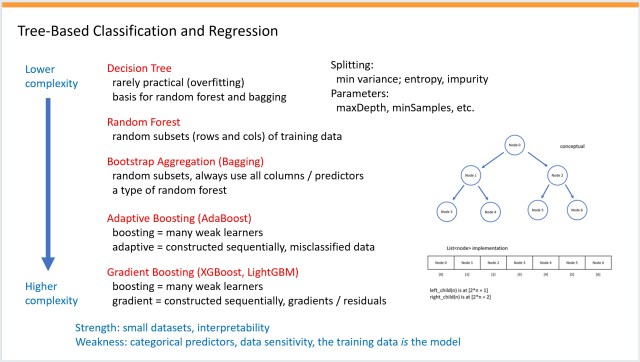
Подробная презентация PowerPoint о нейронных сетях, дополненная методами на основе деревьев, под названием «KitchenSink». Научно-фантастические фильмы на тему памяти, творчески оцененные автором.

Передовая нейросетевая архитектура CPTR объединяет кодер ViT и декодер Transformer для создания титров к изображениям, улучшая предыдущие модели. Модель CPTR использует ViT для кодирования изображений и Transformer для декодирования титров, что повышает производительность создания титров к изображениям.

Трансформеры революционизируют НЛП благодаря эффективным механизмам самовнушения. Интеграция трансформаторов в компьютерное зрение сталкивается с проблемами масштабируемости, но многообещающие прорывы уже не за горами.

Достижения в области искусственного интеллекта позволили объединить НЛП и компьютерное зрение, что привело к появлению моделей создания подписей к изображениям, подобных той, что представлена в фильме «Покажи и расскажи». Эта модель сочетает в себе CNN для обработки изображений и RNN для создания текста, используя GoogLeNet и LSTM.
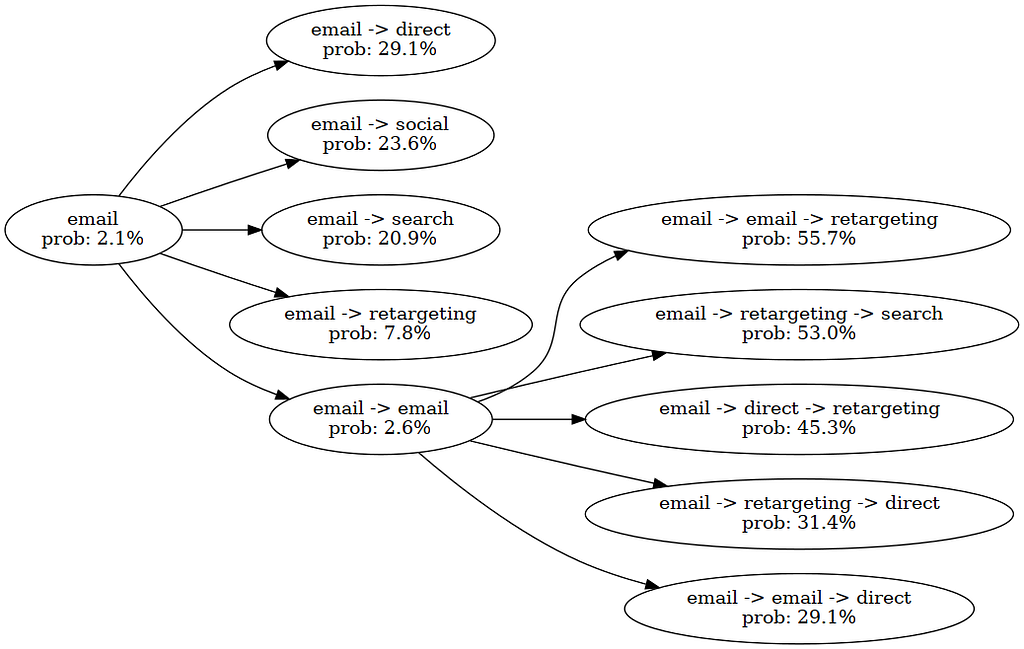
ML-модели могут разрабатывать оптимальные путешествия клиентов, сочетая глубокое обучение с методами оптимизации. Традиционные модели атрибуции не справляются с поставленной задачей из-за неагностичности атрибуции, слепоты контекста и статичных значений каналов.

LSTM, представленные в 1997 году, возвращаются с xLSTM как потенциальные конкуренты LLM в глубоком обучении. Способность запоминать и забывать информацию на временных интервалах отличает LSTM от RNN, что делает их ценным инструментом в языковом моделировании.