
С самого начала сотрудничество с лабораторией MIT-IBM Watson AI Lab сыграло решающую роль для таких преподавателей Массачусетского технологического института, как Джейкоб Андреас и Юн Ким, помогая им сформировать свои исследовательские группы и развивать инновационные проекты в области обработки естественного языка и создания крупномасштабных языковых моделей. Это сотрудничество обеспечило им ...
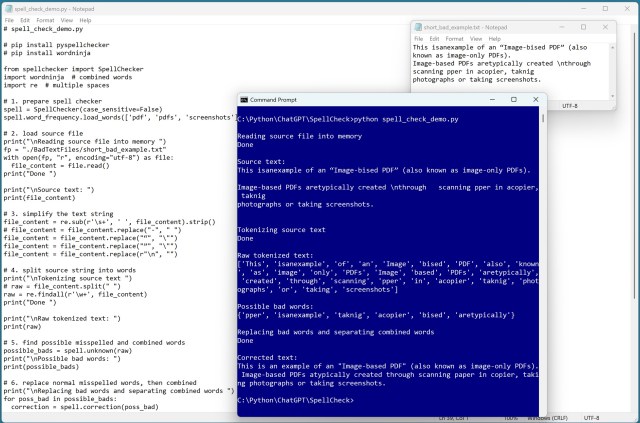
Проект по обработке естественного языка включал извлечение текста из необработанного PDF-файла с помощью PyMuPDF. Создал легкий инструмент для исправления орфографических ошибок, обеспечивающий точную обработку текста.
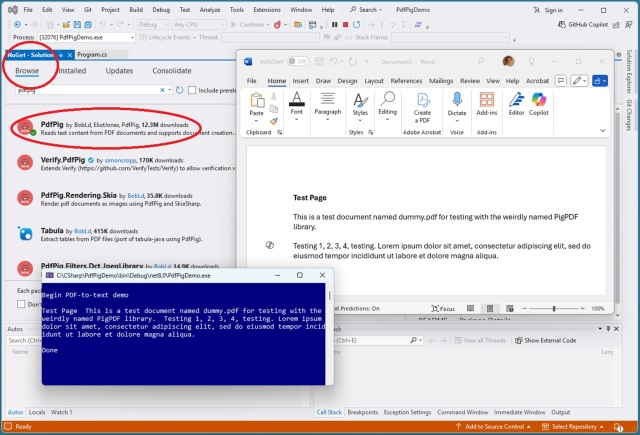
Извлечение текста из PDF-файлов может быть сложной задачей из-за их визуального характера. Ведущими библиотеками C# для этой задачи являются iText и PdfPig, а лучшим выбором для Python является PyMuPDF.

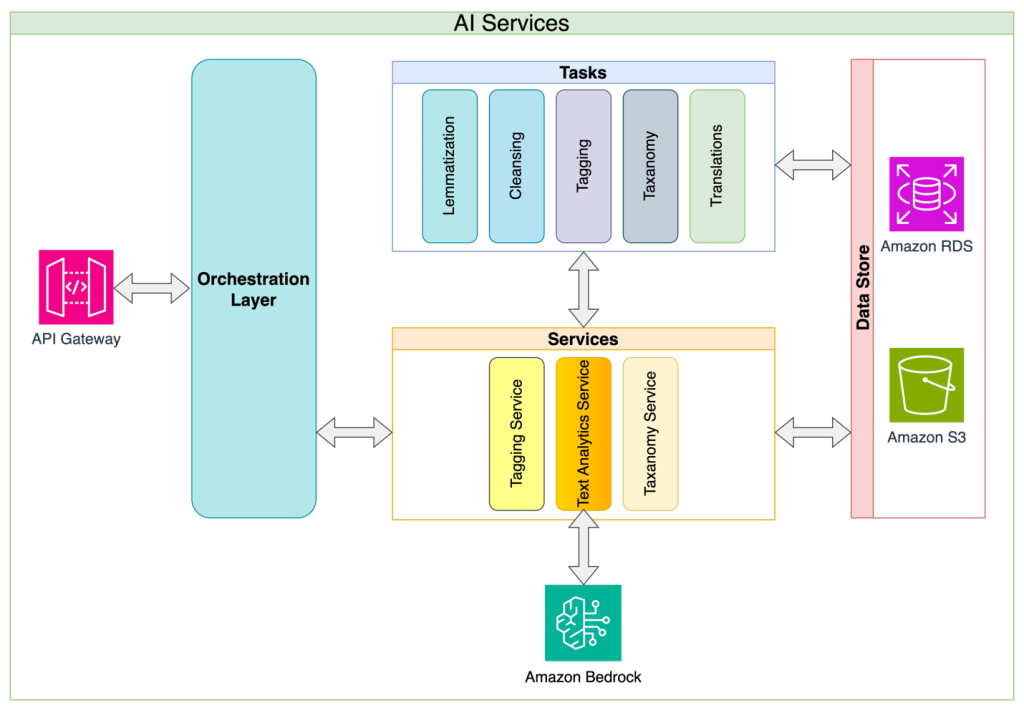
Amazon Bedrock Knowledge Bases упрощает взаимодействие естественного языка со структурированными источниками данных, обеспечивая точность запросов без узких мест SQL. Решение позволяет организациям быстро создавать «разговорные» интерфейсы данных, преобразуя возможности доступа к данным и процессы принятия решений.
Компания Qualtrics является первопроходцем в области управления опытом (XM) с использованием возможностей искусственного интеллекта, ML и NLP, повышающих связь с клиентами и их лояльность. Платформа Socrates компании Qualtrics, работающая на базе Amazon SageMaker, способствует инновациям в области управления опытом с помощью передовых технологий ML.

618-й AOC Командования воздушной мобильности улучшает планирование миссий с помощью чат-инструментов на базе искусственного интеллекта, разработанных в Лаборатории Линкольна. Обработка естественного языка обеспечивает быстрый анализ тенденций и интеллектуальные возможности поиска для принятия важнейших решений в ВВС США.
Yuewen Group расширяет глобальное влияние с помощью платформы WebNovel, адаптируя веб-романы в фильмы и анимацию. Оптимизация подсказок на Amazon Bedrock повышает производительность больших языковых моделей для интеллектуальной обработки текстов в Yuewen Group, преодолевая трудности в разработке подсказок и улучшая возможности в конкретных случаях использования.

LettuceDetect, легкий детектор галлюцинаций для конвейеров RAG, превосходит предыдущие модели, предлагая эффективность и доступность с открытым исходным кодом. Большие языковые модели сталкиваются с проблемами галлюцинаций, но LettuceDetect помогает обнаружить и устранить неточности, повышая надежность в критически важных областях.

Трансформеры революционизируют НЛП благодаря эффективным механизмам самовнушения. Интеграция трансформаторов в компьютерное зрение сталкивается с проблемами масштабируемости, но многообещающие прорывы уже не за горами.

Такие достижения науки о данных, как Transformer, ChatGPT и RAG, меняют технологию. Понимание эволюции НЛП является ключевым для начинающих специалистов по работе с данными.

Достижения в области искусственного интеллекта позволили объединить НЛП и компьютерное зрение, что привело к появлению моделей создания подписей к изображениям, подобных той, что представлена в фильме «Покажи и расскажи». Эта модель сочетает в себе CNN для обработки изображений и RNN для создания текста, используя GoogLeNet и LSTM.

Языковые модели отлично справляются с различными задачами, но испытывают трудности с интерпретацией и созданием ASCII-искусства. Токенизация мешает LLM понять общую картину, что приводит к комичным неудачам вроде смайлика, принятого за математическое уравнение.

Мультимодальные вкрапления объединяют текстовые и графические данные в единую модель, позволяя использовать кросс-модальные приложения, такие как создание подписей к изображениям и модерация контента. CLIP согласовывает представления текста и изображения для классификации изображений по 0-кадрам, демонстрируя возможности общих пространств вкраплений.
Модели Medical LLM от John Snow Labs на Amazon SageMaker Jumpstart оптимизируют задачи медицинского языка, превосходя GPT-4o в резюмировании и ответах на вопросы. Эти модели повышают эффективность и точность работы медицинских работников, поддерживая оптимальный уход за пациентами и результаты медицинского обслуживания.

Реферат: Разработчик делится опытом внедрения модели NLP для обработки документов на чешском языке с упором на идентификацию сущностей. Модель была обучена на 710 PDF-документах с использованием ручной маркировки и для повышения эффективности избегала подходов на основе ограничительных рамок.
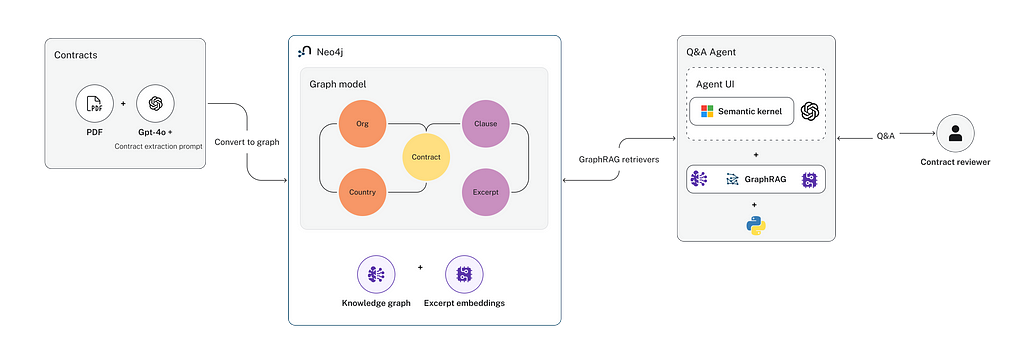
Реферат: Представляем новый подход GraphRAG для эффективного извлечения данных о коммерческих контрактах и создания агентов Q&A. Фокус на целевом извлечении информации и организации графа знаний повышает точность и производительность, что делает его пригодным для решения сложных юридических вопросов.

Говорят, что большие языковые модели (LLM) обладают «эмерджентными свойствами», но определение варьируется. Исследователи НЛП спорят о том, являются ли эти свойства обучаемыми или врожденными, что влияет на исследования и общественное восприятие.

Google Colab, интегрированный с инструментами генеративного искусственного интеллекта, упрощает кодирование на Python. Изучайте Python легко, без установки, благодаря доступным функциям Google Colab.

Токенизация имеет решающее значение в НЛП, чтобы соединить человеческий язык и машинное понимание, позволяя компьютерам эффективно обрабатывать текст. Крупные языковые модели, такие как ChatGPT и Claude, используют токенизацию для преобразования текста в числовые представления для получения осмысленных результатов.
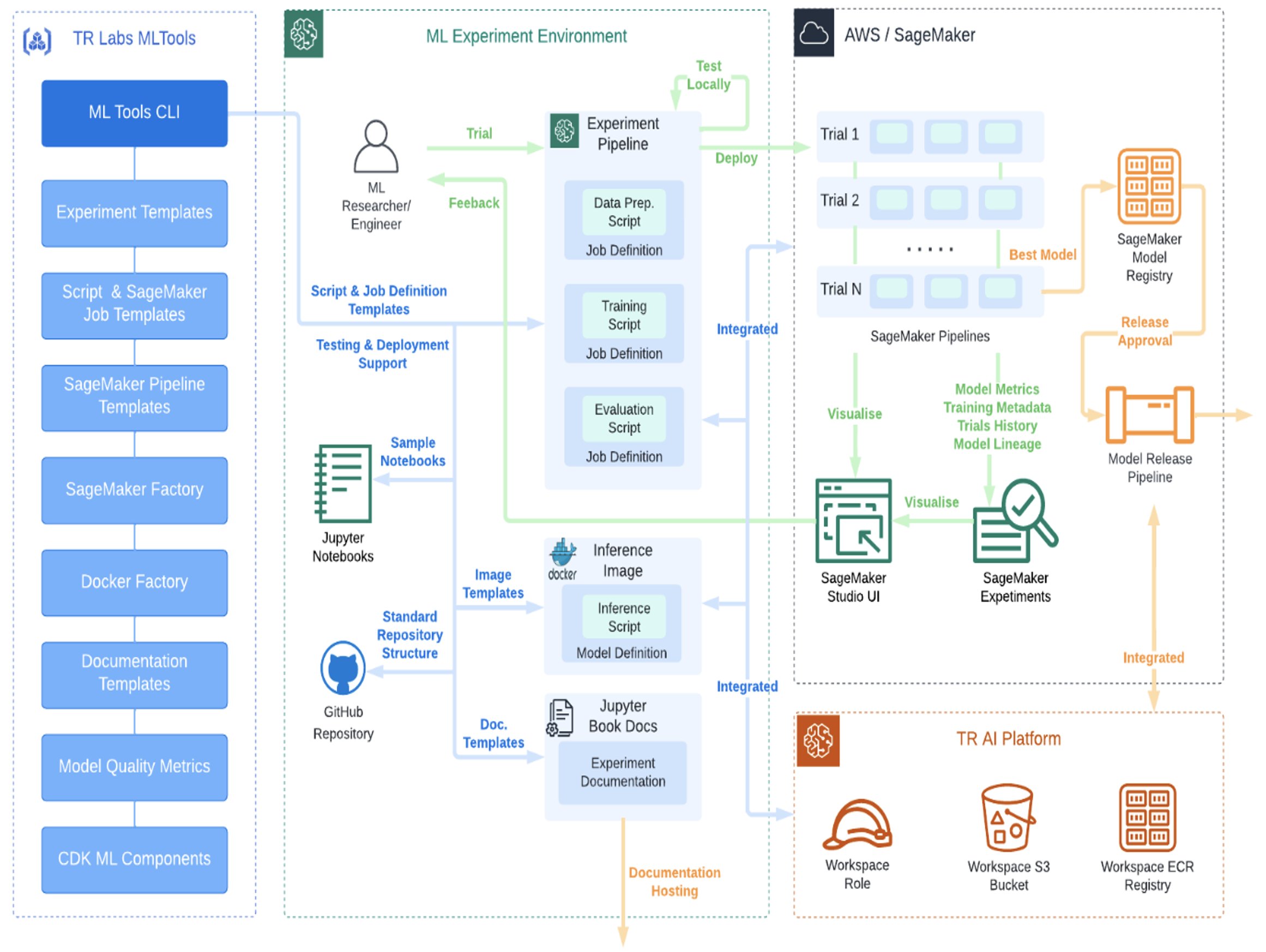
Thomson Reuters Labs разработала эффективный процесс MLOps с помощью AWS SageMaker, ускоряя инновации в области искусственного интеллекта. Цель TR Labs - стандартизировать MLOps для создания более умных и экономичных инструментов машинного обучения.
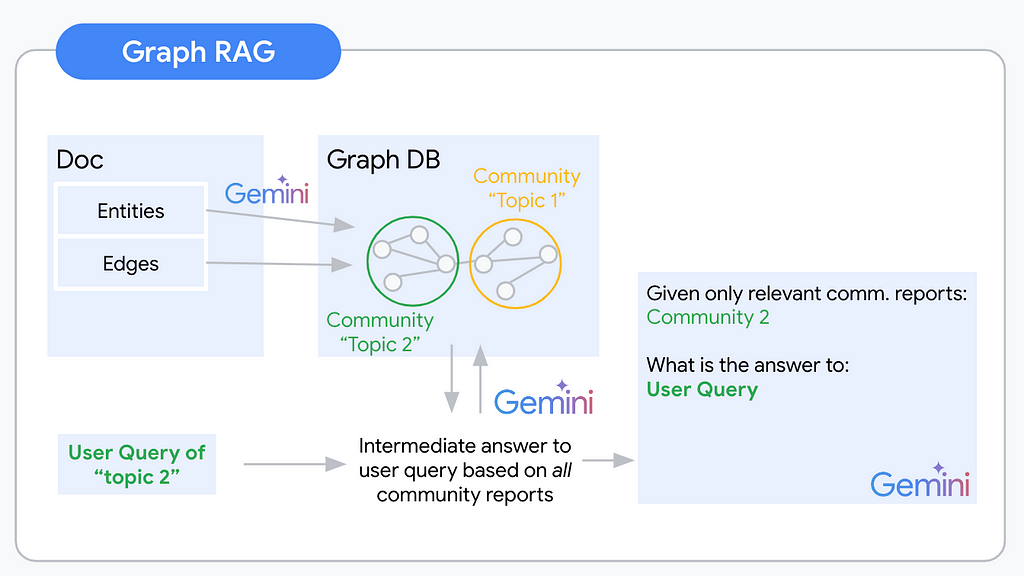
RAG расширяет возможности приложений ИИ, объединяя LLM с данными, специфичными для конкретной области. Встраивание в текст имеет ограничения при ответе на сложные, абстрактные вопросы по всем документам.
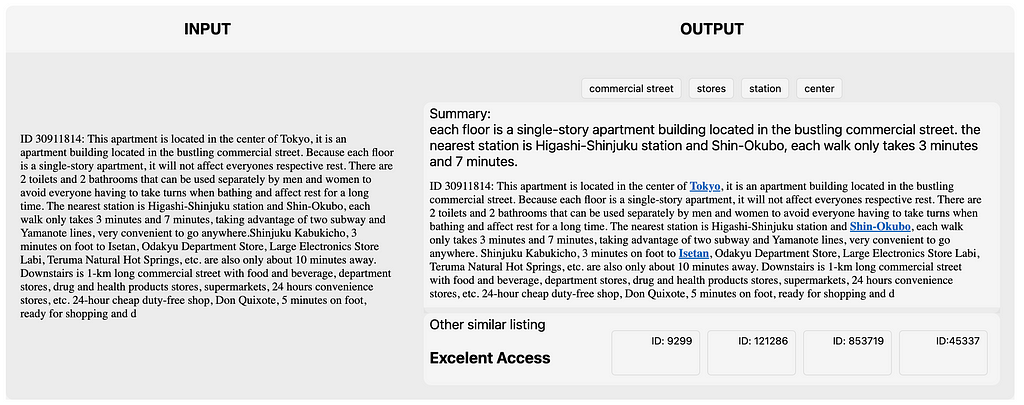
Методы NLP улучшают объявления о сдаче жилья на Airbnb в Токио, извлекая ключевые слова и улучшая пользовательский опыт. Во второй части мы рассмотрим тематическое моделирование и предсказание текста для аренды недвижимости.
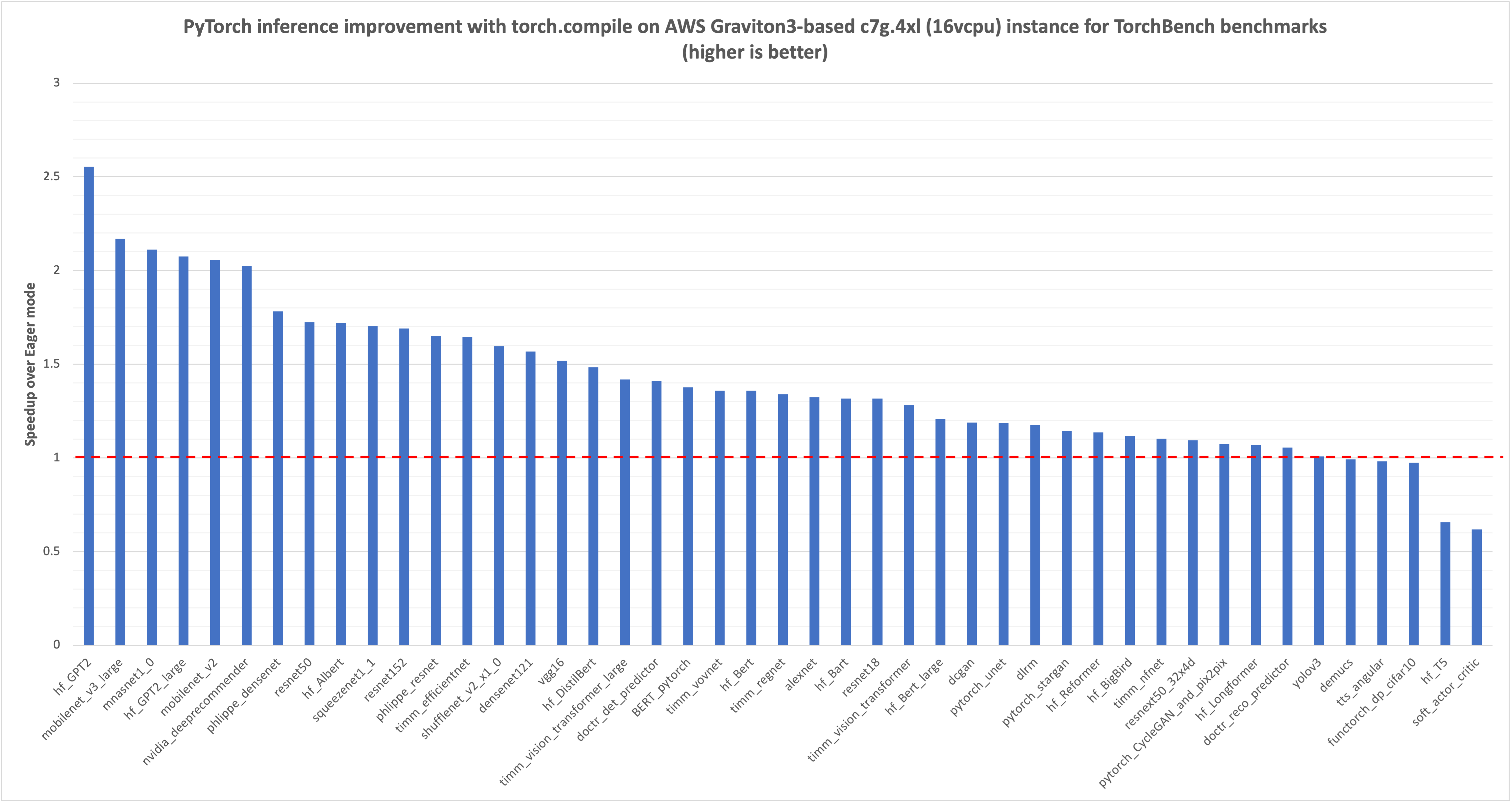
В PyTorch 2.0 появился torch.compile для более быстрого выполнения кода. AWS оптимизировала torch.compile для процессоров Graviton3, что привело к значительному увеличению производительности моделей NLP, CV и рекомендаций.
Использование LLM и GenAI может улучшить процесс дедупликации, повысив точность с 30 до почти 60 %. Этот инновационный метод полезен не только для данных о клиентах, но и для выявления дубликатов записей в других сценариях.
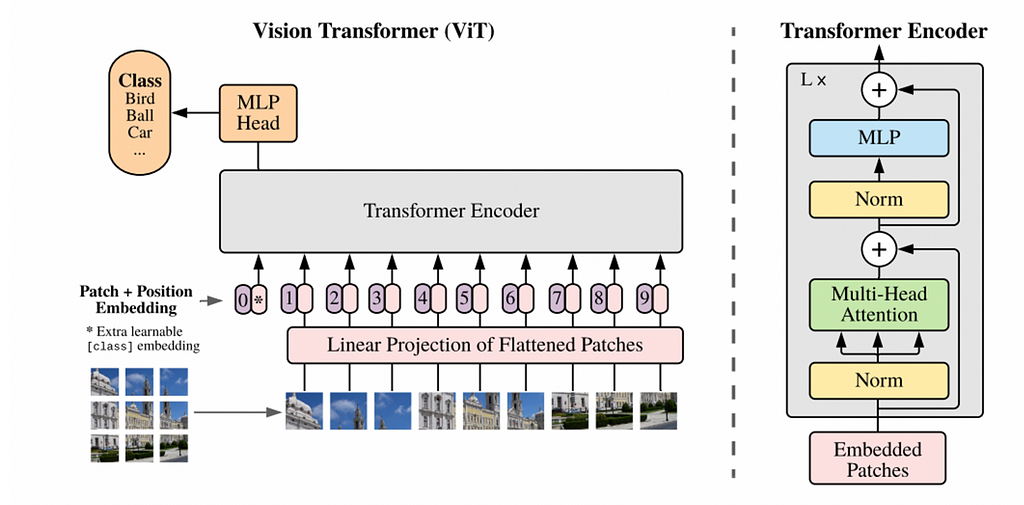
Трансформаторы, известные своей революцией в НЛП, теперь отлично справляются с задачами компьютерного зрения. Ознакомьтесь с архитектурами трансформатора зрения и автокодировщика с маской, обеспечивающими этот прорыв.

Amazon Bedrock использует модель Anthropic Claude 3 Haiku для расширенной обработки документов, предлагая масштабируемое извлечение данных с современными возможностями NLP. Решение упрощает рабочий процесс за счет обработки больших файлов и многостраничных документов, обеспечивая высокое качество результатов благодаря настраиваемым правилам и человеческому контролю.
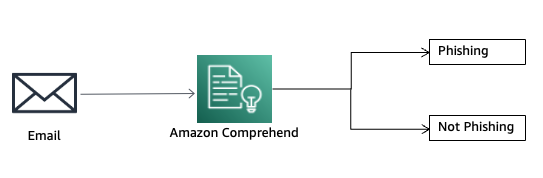
Фишинг - это получение конфиденциальной информации по электронной почте. Amazon Comprehend Custom помогает обнаруживать попытки фишинга с помощью ML-моделей.

Краткое содержание: В этой серии блогов вы узнаете об адаптации доменов для LLM. Узнайте о тонкой настройке для расширения возможностей моделей и повышения их производительности.
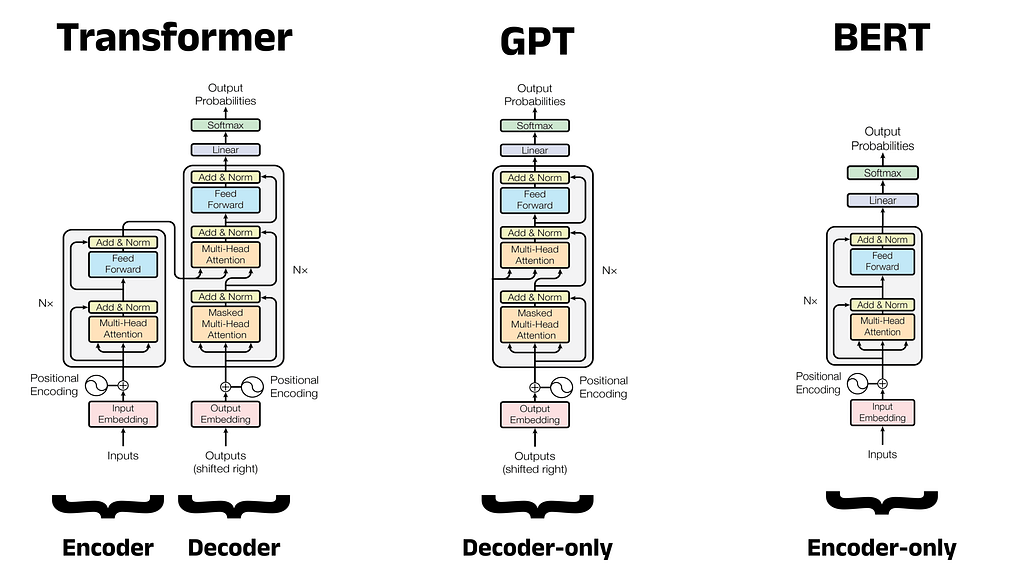
BERT, разработанная Google AI Language, - это новаторская модель большого языка для обработки естественного языка. Ее архитектура и фокус на понимании естественного языка изменили ландшафт НЛП, вдохновив такие модели, как RoBERTa и DistilBERT.

ONNX Runtime на AWS Graviton3 повышает производительность ML-выводов на 65% благодаря оптимизированным ядрам GEMM. Бэкэнд MLAS обеспечивает ускорение операторов глубокого обучения для повышения производительности.
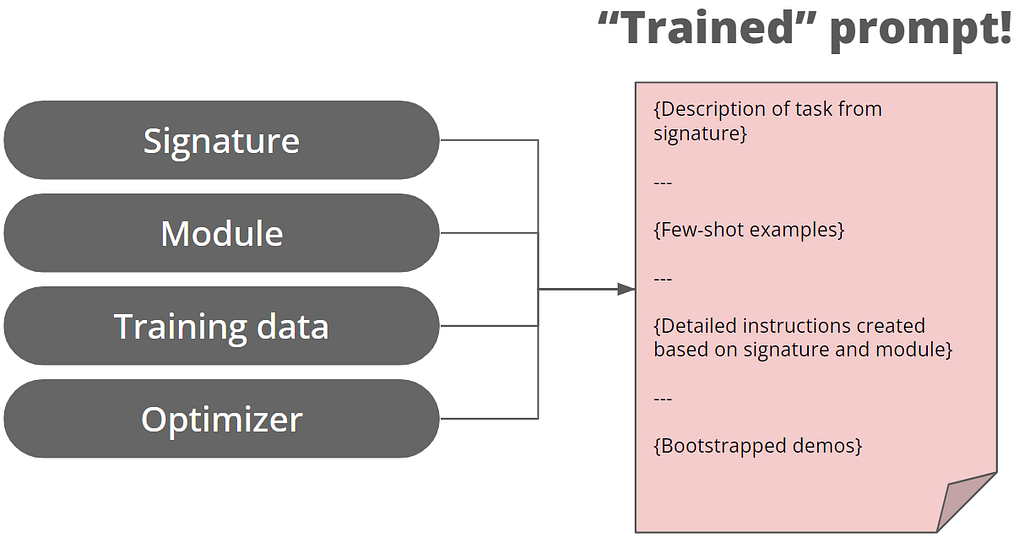
Stanford NLP представляет DSPy для разработки подсказок, переходя от ручного написания подсказок к модульному программированию. Новый подход направлен на оптимизацию подсказок для LLM, повышая надежность и эффективность.
Статья рассказывает о развитии векторных баз данных в интеграции ИИ, уделяя особое внимание системам Retrieval Augmented Generation (RAG). Компании хранят текстовые вкрапления в векторных базах данных для эффективного поиска, что вызывает опасения по поводу возможной утечки и несанкционированного использования данных.
Alida использовала модель Claude Instant компании Anthropic на Amazon Bedrock, чтобы в 4-6 раз улучшить утверждение темы в ответах на опросы, преодолев ограничения традиционного NLP. Amazon Bedrock позволил Alida быстро создать масштабируемый сервис для исследователей рынка, собирающий качественные данные с нюансами, выходящими за рамки вопросов с несколькими вариантами ответов.

В статье рассматривается эволюция моделей GPT, особое внимание уделяется улучшениям GPT-2 по сравнению с GPT-1, включая больший размер и возможности многозадачного обучения. Понимание концепций, лежащих в основе GPT-1, очень важно для осознания принципов работы более продвинутых моделей, таких как ChatGPT или GPT-4.

Рекомендательные системы приносят значительный доход: Amazon и Netflix в значительной степени полагаются на рекомендации продуктов. В этой статье рассматривается использование контролируемых словарей и LLM для улучшения моделей сходства в рекомендательных системах. Выяснилось, что контролируемый словарь улучшает результаты, а создание списка жанров с помощью LLM не представляет труда, но созда...
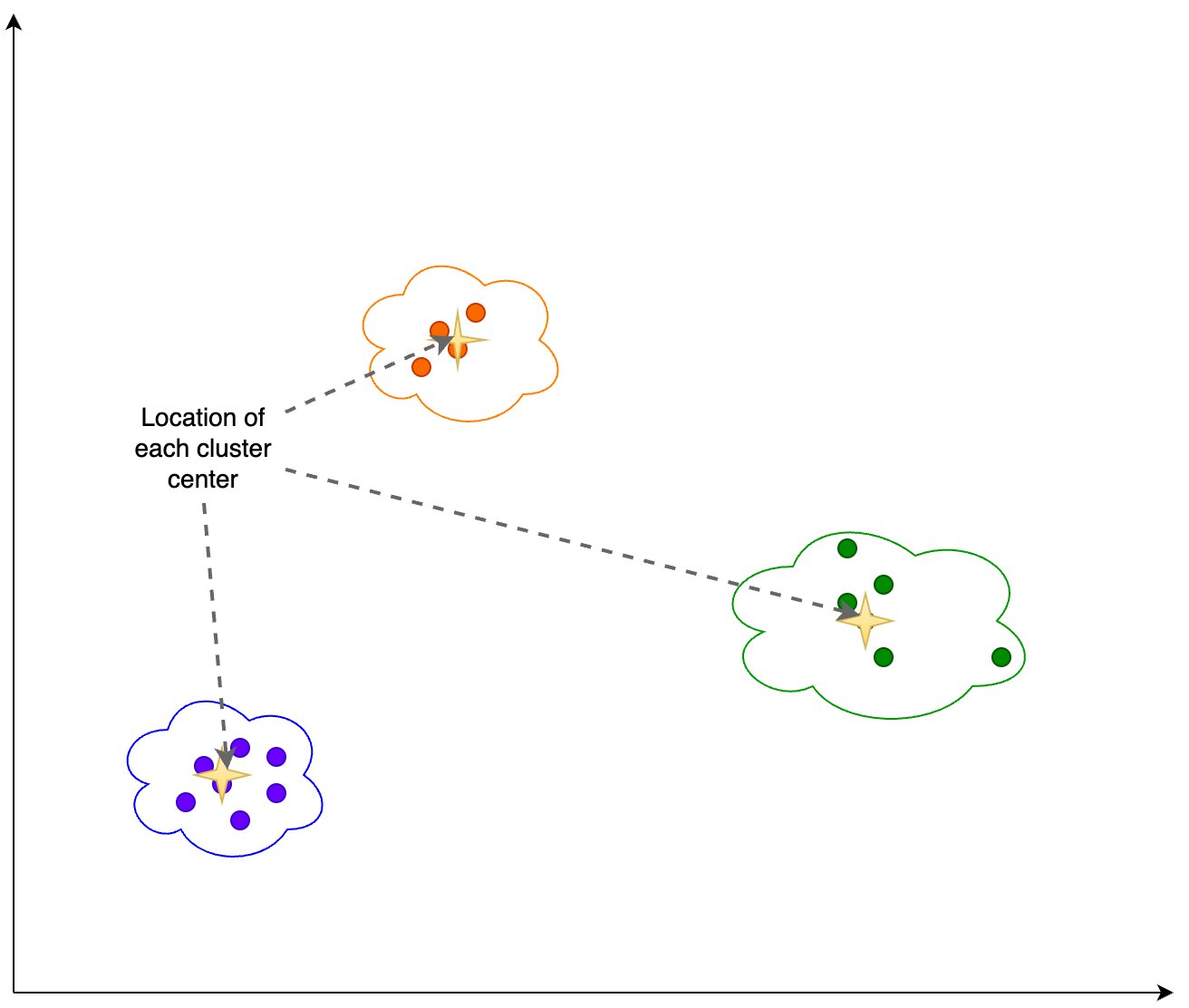
В статье рассматривается паттерн Retrieval Augmented Generation (RAG) для генеративных рабочих нагрузок ИИ с упором на анализ и обнаружение дрейфа встраивания. В ней рассматривается, как векторы встраивания используются для получения знаний из внешних источников и дополнения подсказок, а также объясняется процесс анализа дрейфа этих векторов с помощью анализа главных компонент (PCA).

Технология искусственного интеллекта способна преобразовывать изображения продуктов питания в рецепты, позволяя создавать персональные рекомендации, учитывать культурные особенности и автоматизировать процесс приготовления пищи. Этот инновационный метод сочетает в себе компьютерное зрение и обработку естественного языка для создания комплексных рецептов на основе изображений продуктов питания,...
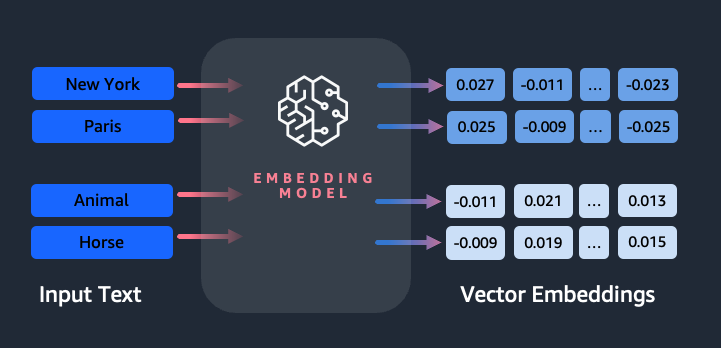
Amazon Titan Text Embeddings - это модель встраивания текста, которая преобразует текст на естественном языке в числовые представления для поиска, персонализации и кластеризации. В ней используются алгоритмы вкрапления слов и большие языковые модели для выявления семантических связей и улучшения последующих задач NLP.

Сотрудники отдела науки о данных использовали методы NLP для анализа дискуссий на Reddit о депрессии, исследуя гендерные табу, связанные с психическим здоровьем. Они обнаружили, что классификация по нулевым снимкам может легко давать результаты, схожие с традиционным анализом настроений, упрощая процесс и устраняя необходимость в наборе обучающих данных.
В 2017 году Google Brain представил Transformer - гибкую архитектуру, которая превзошла существующие подходы к глубокому обучению и теперь используется в таких моделях, как BERT и GPT. GPT, модель декодера, использует задачу языкового моделирования для генерации новых последовательностей и следует двухэтапной схеме предварительного обучения и тонкой настройки.

Генеративный ИИ раскрыл потенциал ИИ, включая генерацию текста и кода. Одна из развивающихся областей - использование NLP для генерации SQL-запросов, что делает анализ данных более доступным для нетехнических пользователей.

2024 год может стать переломным моментом для музыкального ИИ благодаря прорывам в области генерации текста в музыку, музыкального поиска и чат-ботов. Однако эта область все еще отстает от речевого ИИ, и для революции в музыкальном взаимодействии с помощью ИИ необходимы достижения в области гибкого и естественного разделения источников.
Большая языковая модель Mixtral-8x7B от Mistral AI теперь доступна на Amazon SageMaker JumpStart для легкого развертывания. Благодаря многоязыковой поддержке и превосходной производительности Mixtral-8x7B является привлекательным выбором для приложений NLP, предлагая более высокую скорость вывода и более низкие вычислительные затраты.
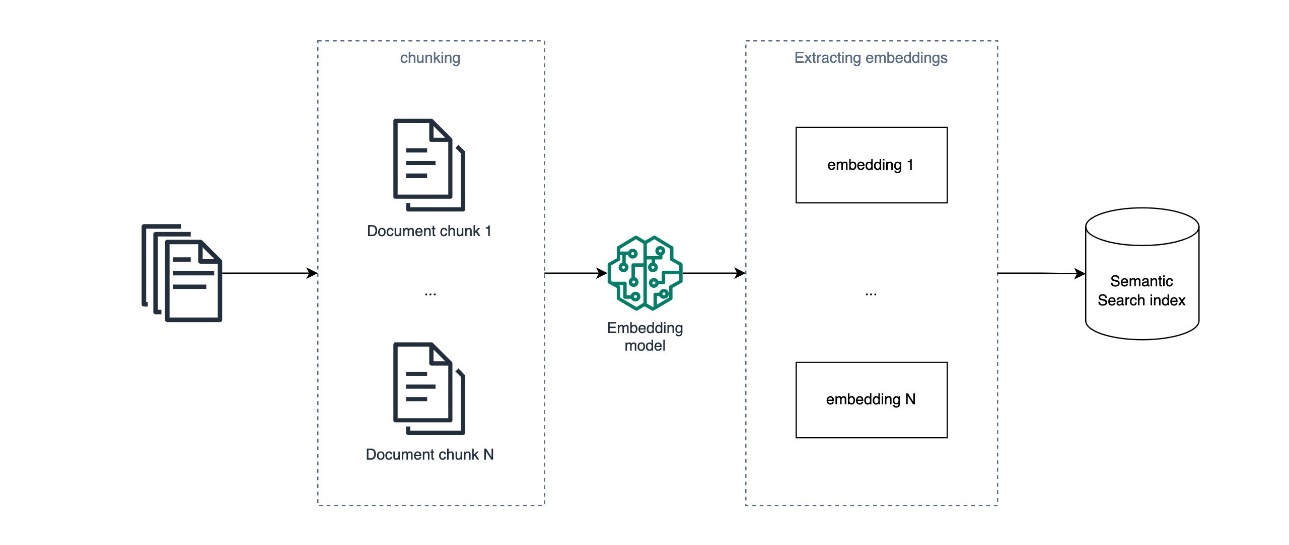
Разговорный ИИ развивался с помощью генеративного ИИ и больших языковых моделей, но для точных ответов ему не хватает специальных знаний. Retrieval Augmented Generation (RAG) соединяет генеративные модели с внутренними базами знаний, позволяя создавать ИИ-помощников, ориентированных на конкретную область. Amazon Kendra и OpenSearch Service предлагают зрелые решения векторного поиска для реализ...
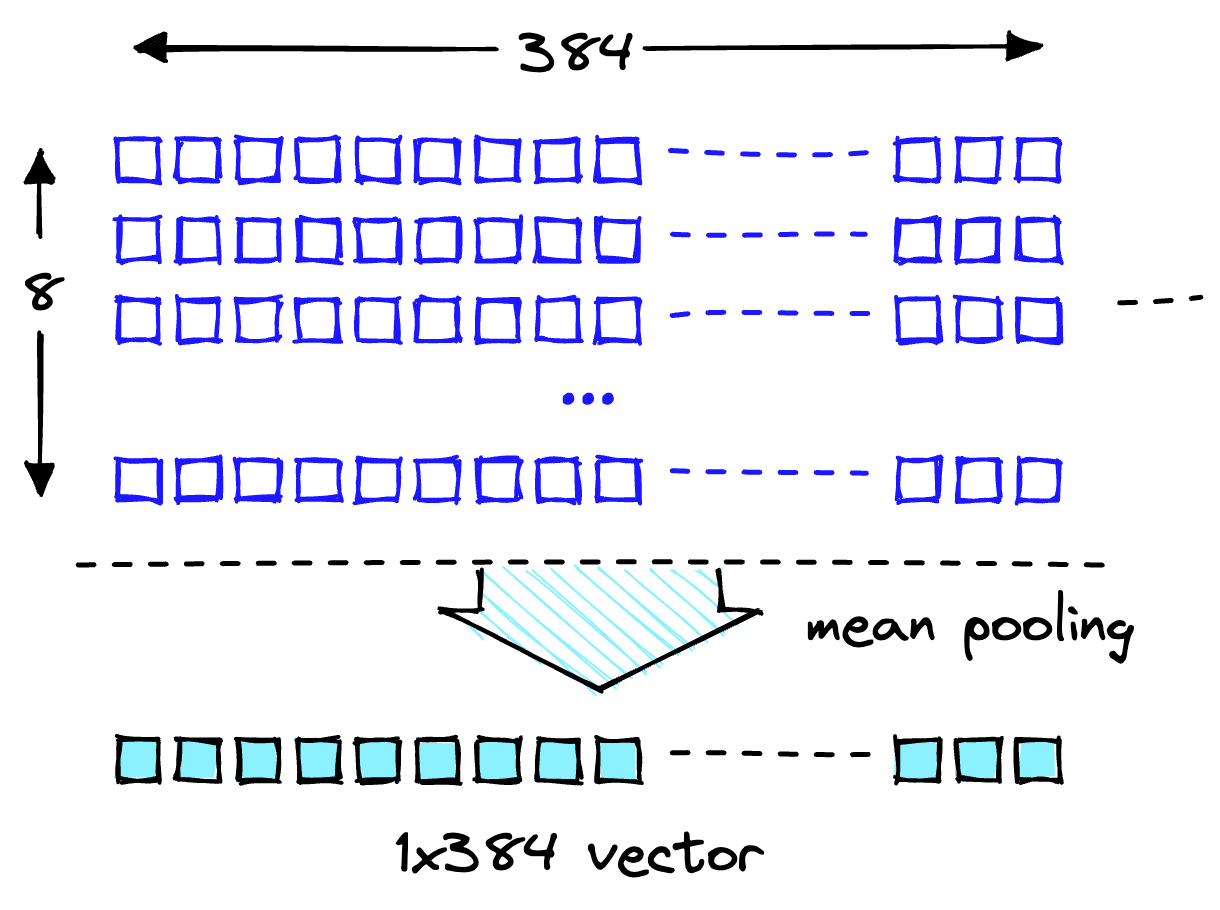
Такие LLM, как Llama 2, Flan T5 и Bloom, необходимы для использования в разговорном ИИ, но для обновления их знаний требуется переобучение, что требует много времени и средств. Однако с помощью технологии Retrieval Augmented Generation (RAG), использующей Amazon Sagemaker JumpStart и векторную базу данных Pinecone, LLM можно развернуть и постоянно обновлять актуальную информацию, чтобы предотв...
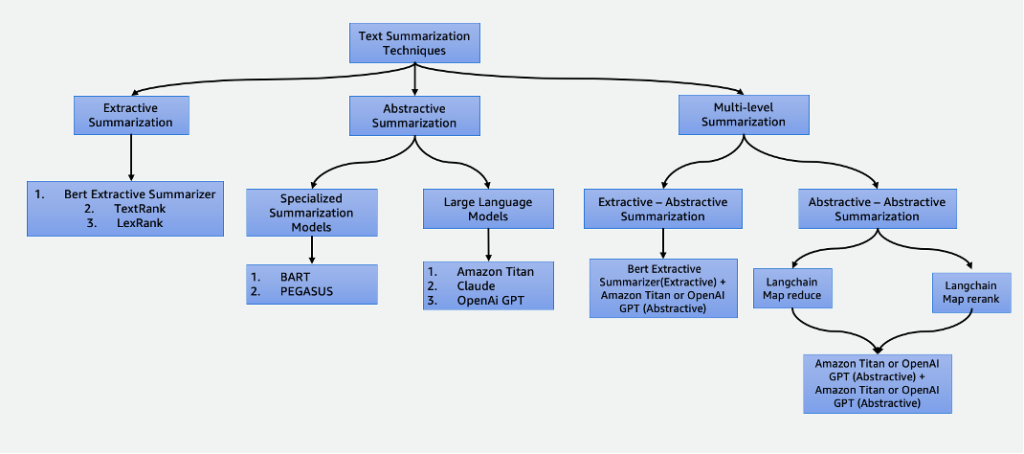
Обобщение данных играет важную роль в нашем мире, основанном на данных, позволяя экономить время и улучшать процесс принятия решений. Оно находит различные применения, включая агрегирование новостей, обобщение юридических документов и финансовый анализ. С развитием НЛП и ИИ такие техники, как экстрактивное и абстрактное обобщение, становятся все более доступными и эффективными.