
Ефективні методи вирішення задач роботи з текстом за допомогою LLM, llama.cpp та guidance
В останні роки нейронні моделі з машинного навчання стали невід'ємною частиною різноманітних сфер людської діяльності. Однією з найбільш зростаючих областей в цьому контексті є використання мовних моделей, таких як LLM (Large Language Models). Ці моделі, які включають в себе найсучасніші досягнення у сфері обробки природної мови, мають потенціал вирішити різноманітні завдання в широкому спектрі областей. Від аналізу тексту, суммаризації та автоматичного перекладу до генерації контенту та управління даними, LLM моделі виявилися надзвичайно корисними інструментами для вирішення складних завдань у сучасному світі.
Автоматична обробка тексту - одна з таких задач, в яких людський фактор відіграє значну роль - одне і те ж речення, написане різними людьми, може бути як простим та цікавим, так і занадто перевантаженим та складним. У цій статті ми розберемо, як подібну задачу можна вирішити, і без витрачання значних ресурсів з прийнятною швидкістю працювати з текстами за допомогою моделей ШІ, обробляючи їх автоматично.
Список задач, які можна вирішити за допомогою великих мовних моделей та правильних інструкцій до них може бути досить довгим. Це і будь-які задачі суммаризації тексту, виділення з тексту сутностей, перефразування тексту з одного стиля в інший чи "розумне" додавання ключових слів в текст.
Сучасні мовні моделі та LLM
Instruct LLM - це досить новітня розробка в галузі обробки природної мови. Це спектр моделей, який побудований на основі Transformer блоків, які сприймають текст як "токени", тобто слова або їх частинки, та має унікальну здатність розуміти складні взаємозв'язки між словами в реченнях. Це дозволяє їм більш інтелектуально оброблювати текст. Сама модель займається передбаченням наступного токену з її словника, тобто визначає ймовірності всіх слів зі словника як наступний токен, а потім обирає токен з ймовірністю на основі семплінгу.
Завдяки цій функціональності, Instruct LLM може ефективно перефразовувати текст, враховуючи додаткові вказівки та контекст на конкретному прикладі, роблячи сам текст "живим" та природним. Досить великий недолік, до якого призводить такий широкий функціонал LLM-моделей - це розмір. Типовий розмір таких моделей, які мають гарну якість обробки та "розуміння" тексту - це 7-14 мільярдів параметрів в форматі float16 (2 байти пам'яті). Це означає, що для використання такої моделі з розміром, наприклад, 7 мільярдів параметрів необхідно:
2 (байти) * 7 000 000 000 (параметри) / 1024 (KB) / 1024 (MB) / 1024 (GB) ≈ 13.04 GB
Отже, 13.04 гігабайт пам'яті необхідно для роботи моделі, а для значної швидкості більше 13 GB пам'яті на відеокарті (VRAM) це досить багато. Це і призводить до значних витрат на залізо при використанні подібних моделей, проте цю проблему може вирішити такий інструмент, як квантизація.
Сама модель, яка буде використовуватись для цієї задачі називається Mistral-7B-Instruct від компанії Mistral.AI. Це модель з інструкціями (тобто така, яка навчена за допомогою RLHF слідувати інструкціям користувача) на 7 мільярдів параметрів. Після використання всіх інструментів, така модель при роботі буде займати ≈4.5GB звичайної RAM пам'яті, а також мати швидкість приблизно 1.2 токена в секунду при використанні середньо цінового процесора.
Квантизація моделі
Як ми вже зазначили, одна з найбільших проблем при роботі з великими мовними моделями полягає в тому, що вони вимагають значних обчислювальних ресурсів. Для вирішення цієї проблеми ми використовуємо квантизацію - процес стиснення моделі шляхом зменшення кількості біт, необхідних для представлення кожного параметра. Так як float16 це зазвичай стандартний формат параметрів для LLM-моделей, який має дрібну частину, обсяг пам'яті для його застосування можна скоротити, використавши тип даних з меншим розміром та тільки цілою частиною, наприклад, 8 бітний Integer, що при використанні його зі знаком призведе до можливих значень від -127 до 127. В загальному виді такий метод квантизації виглядає так:
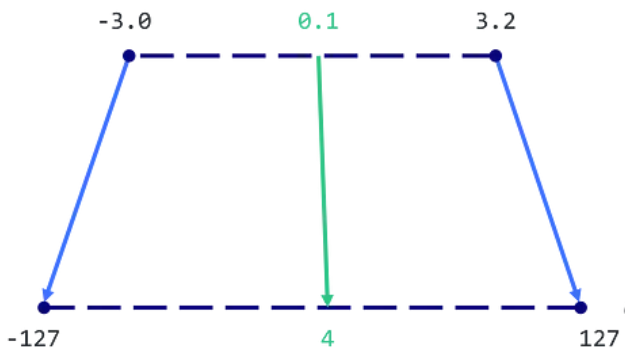
З рисунку можемо побачити, що значення будуть відмаштабовані в новий формат. Це зменшить обсяг пам'яті, яку займає модель, не зменшуючи радикально її ефективність та якість. Для квантизації нашої моделі Mistral-7b-Instruct ми використовуємо llama.cpp - бібліотеку з відкритим кодом для ефективного використання моделей машинного навчання. Завдяки llama.cpp ми можемо квантувати нашу модель, зберігаючи при цьому її точність та ефективність.
Принцип її роботи трохи інакший - для квантизації використовується матриця важливості. Суть матриці важливості полягає в тому, щоб отримати градієнти вагів параметрів із прогону моделі на заданому наборі навчальних токенів. Коли градієнт ваги даної моделі невеликий, це означає, що велика зміна ваги параметру моделі, тобто зміна параметру при квантизації, призведе до невеликої зміни продуктивності моделі. І, навпаки, великий градієнт передбачає велику зміну продуктивності моделі від невеликої зміни у вазі параметру моделі. Квадрати градієнтів можна використовувати як матрицю важливості, і на основі цієї матриці і відбувається більш "розумна" квантизація. Такий алгоритм дозволив скоротити модель Mistral-7B-Instruct з 13GB до приблизно 4.5GB, при цьому зберігаючи адекватну швидкість та якість. Важливим аспектом є оцінка погіршення роботи моделі після такої квантизації, інтуїтивно можна побачити її тут:
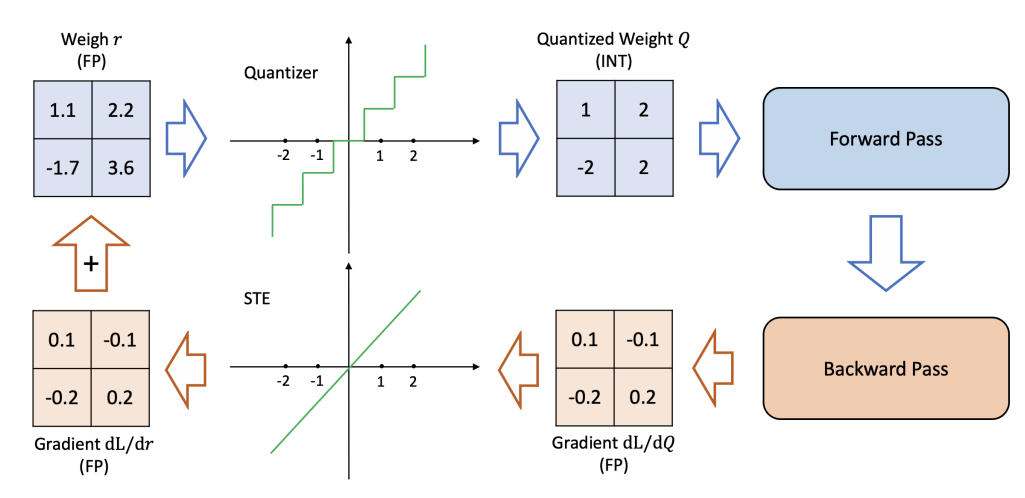
Так як кількість значень в параметрах менша, якість моделі зменшується. Для великих мовних моделей така якість розраховується за допомогою Perplexity, метрики, яка вираховує зміну ймовірності наступного правильного токену на передбаченні даних. Схематично це можна побачити на наступному рисунку:

В цьому прикладі ми можемо порахувати ймовірність на слово "going" в квантизованій або неквантизованій моделі на відповідність найбільш ймовірному токену в генерації, таким чином розрахувавши відмінність ймовірності, що і буде показником Perplexity. В вирішенні цієї задачі ми використовуємо найменшу модель після квантизації, і хоч вона має і найбільший показник Perplexity, тобто зміну від своєї початкової ймовірності, цього достатньо для задачі, яку ми розглядаємо. Таблиця з показниками Perplexity для Mistral-7B-Instruct наведена нижче:
| Quant Type | Float16 | Q2_K | Q3_K | Q4_K | Q5_K | Q6_K |
| perplexity | 5.9066 | 6.7764 | 6.1503 | 5.9601 | 5.9208 | 5.9110 |
Формат вихідних даних моделі
LLM моделі відрізняються від інших також і тим, що маючи великий спектр задач, які вони можуть вирішувати, вони і форматують вихід довільним чином. Тобто в задачах конкретного виду text2text можуть додавати пояснення, додаткові примітки та інші конструкції, які будуть заважати автоматично відбирати результати роботи моделі та обробляти їх. Таку поведінку можна виправляти за допомогою інструкції до моделі при запиті, тобто промпту, але на малих моделях це не завжди працює. Модель може "не слухатись" промпту. Для вирішення такої проблеми можна використати бібліотеку guidance. Вона дозволяє використовувати великий спектр різних LLM-моделей з форматингом виводу моделі, що дозволяє більш точно контролювати генерацію. Наприклад, можна обмежити генерацію умовами "зупинись на генерації нового рядка" чи дозволити моделі передбачати тільки деякий список з токенів. Приклад:

На цьому прикладі можемо побачити, що ми завчасно вказали слово "Answer" у відповіді, тому модель відразу почала генерувати необхідні нам дані, і не зациклювалась на інструктивній розмітці цих даних. Форматуючи вихід на нашій задачі, можна вказати в генерації слова "Summarized result text:" чи подібні, та генерувати короткі тексти тільки до нового рядка. Це усуне основні проблеми з форматуванням та допоможе генерувати більш природні та якісні тексти. Проте це тільки мала частина з усього того, що може бути реалізовано за допомогою guidance. Ось приклад використання "select", який дозволяє задати моделі тільки деякий спектр значень, які вона може обрати. Це допоможе генерувати тільки потрібні сутності на основі контексту запиту.

Ще один комплексний приклад таких генерацій, які дозволяють створювати цілі конструкції на основі guidance функцій наведено нижче:
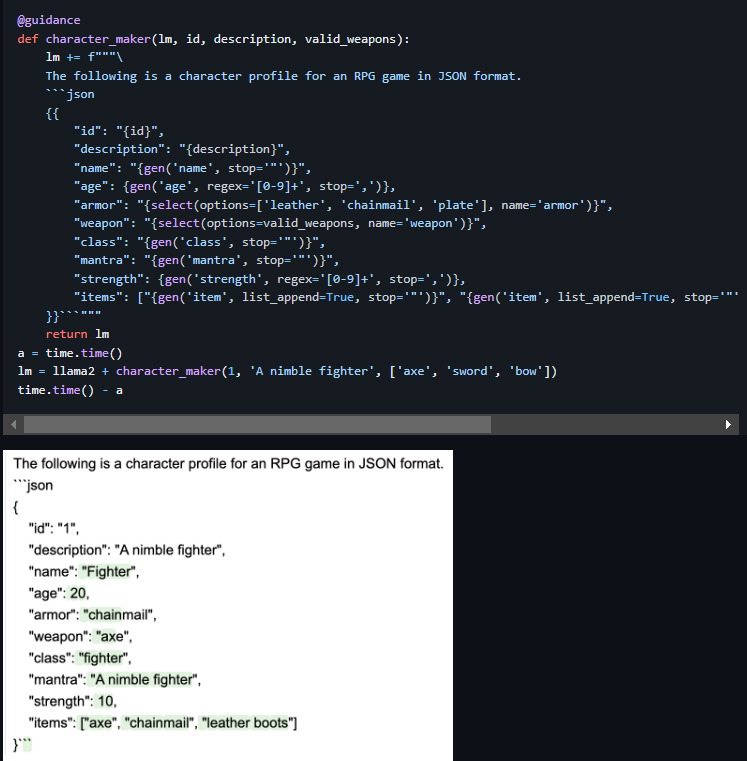
Як можемо побачити, почавши генерувати персонажа для RPG-гри "воїн" модель і надалі дотримувалась контексту цього персонажа, задаючи реалістичні параметри персонажу, та навіть його речі згенерувала правильно. Відповідно в таких конструкціях можна використовувати як регулярні вирази, наприклад для віку, як це показано на прикладі, так і "for" цикли для генерації необхідної кількості речей. Або, наприклад, запросити модель згенерувати кількість речей у персонажа як число за допомогою регулярного виразу, а потім, отримавши це число, використати його в циклі для генерації динамічної кількості предметів. І це далеко не всі можливості щодо управління генерацією, тому використання цієї бібліотеки може вирішити багато проблем в задачах обробки тексту.
Розроблена система має змогу оптимізувати прикладні задачі по роботі з текстом, додаючи і автоматичний аналіз, і обробку цих текстів на основі великих мовних моделей. Це значно економить час роботи за рутинними задачами та ефективно вирішує прикладні проблеми.
Микола Андрющенко, ML-інженер
Ресурси:
1. Mistral-7B-Instruct
2. Llama.cpp
3. Guidance
4. ChatGPT та інтуіція Instruct-моделей