
Що таке машинне навчання?
Машинне навчання являє собою наукову дисципліну, присвячену розробці алгоритмів та статистичних моделей. На відміну від традиційного програмування у машинному навчанні не потрібно створювати модель самостійно. Дата-інженер збирає та готує дані для машинного навчання, а також експериментує з різними алгоритмами машинного навчання для побудови кращої моделі. Коли модель сформована, залишається лише задіяти її при вирішенні задачі та отримати результат.
Ще однією істотною відмінністю машинного навчання від традиційного програмування є кількість вхідних параметрів, що обробляються. Для точного прогнозу погоди у конкретній локації потрібно введення тисяч параметрів, що впливають на результат. Побудова алгоритму, здатного розумно використовувати всі ці параметри, є складним завданням для людини. У машинному навчанні немає таких обмежень: за наявності достатньої потужності процесора та пам'яті можна використовувати будь-яку кількість вхідних параметрів на розсуд користувача.
У сфері медицини машинне навчання відіграє важливу роль у діагностиці, персоналізації лікування та прогнозній аналітиці. Алгоритми аналізують великі набори даних, виявляючи тонкі закономірності, які можуть бути непомітними для людського спостереження. Наприклад, сервіс QuData для точної діагностики раку забезпечує раннє виявлення онкопатології, сприяє необхідному медичному втручанню, а також дозволяє фахівцям отримати незалежну експертну думку.
Розпізнавання мови за допомогою машинного навчання змінило визначення взаємодії людини та комп'ютера. Удосконалені алгоритми обробляють усне мовлення, перетворюючи його у текст чи команди до виконання. Голосові помічники, служби мовного перекладу та пристрої з голосовим керуванням – усі вони використовують машинне навчання для точного розуміння та відповідне реагування на людську мову.
Машинне навчання впроваджує перспективні зміни у сферу бізнесу, надаючи компаніям потужний інструментарій для оптимізації процесів та прийняття більш обґрунтованих рішень. Ефективність цієї технології проявляється у можливості аналізу величезних обсягів даних, виявленні тенденцій та формуванні прогнозів, що стає неоціненним активом для прийняття стратегічних рішень.
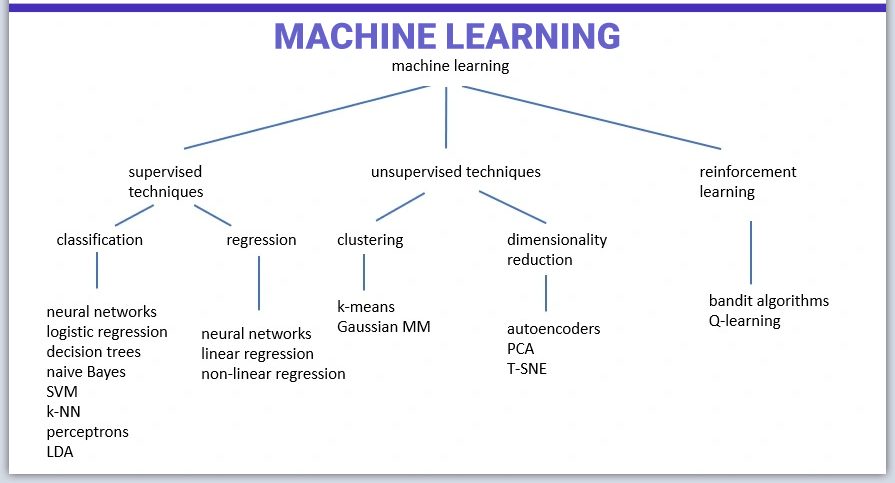
Як працює машинне навчання?
Машинне навчання – це складний процес, що починається зі збору даних. На першому етапі проєкту дослідники акуратно формують датасет, вирішуючи, чи створювати його самостійно, використовувати загальнодоступні джерела або набувати готових даних. Це важливий крок, оскільки якість та обсяг даних безпосередньо впливає на подальшу ефективність моделі машинного навчання.
Після збору даних на черзі їхня підготовка. Цей етап включає ретельне перетворення даних у зручний формат, наприклад, в CSV-файли, і забезпечення їх відповідності цілям, які необхідно досягти. Це включає очищення даних від дублікатів, виправлення помилок, додавання інформації, якої бракує, і масштабування даних до стандартного формату.
Вибір відповідного алгоритму машинного навчання є важливим кроком. Залежно від поставленого завдання та доступних обчислювальних ресурсів дослідники можуть вибирати безліч різних алгоритмів. Немає універсального рішення, що ідеально підходить для всіх випадків. Перш, ніж вирішувати завдання, варто визначитися, з яким обсягом даних доведеться працювати, з яким типом даних здійснюватиметься взаємодія, яку інформацію слід очікувати від даних, і, нарешті, які плануються сфери застосування обраного методу.
Наступний етап у розробці моделі включає в себе навчання моделі: передачу даних системі та налаштування її внутрішніх параметрів для покращення прогнозів. Однак, необхідно уникати явища перенавчання, при якому модель добре справляється з тренувальними даними, але втрачає ефективність на нових даних. Також варто запобігати недонавченню, коли модель недостатньо ефективна як на тренувальних, так і нових даних.
Оцінка точності моделі під час навчання – ще один невід'ємний крок. Тут система тестується на даних, які використовувалися під час тренування. Зазвичай близько 60% даних використовується для тренування моделі (training data), 20% – для перевірки прогнозів, коригування та оптимізації гіперпараметрів (validation data). Цей процес є важливим для максимізації точності передбачень системи при подачі нової інформації. Ті 20% даних, що залишилися, використовуються для тестування (test data).
І, нарешті, розгортання моделі означає надання алгоритму нових даних та використання результатів системи для прийняття рішень чи подальшого аналізу.
Дуже важливо регулярно перевіряти на нових даних показники якості моделі. І якщо вони надто низькі, можливо, її потрібно доопрацювати.
Всі ці кроки разом забезпечують створення гнучкої та ефективної системи, здатної адаптуватися до нової інформації та робити точні прогнози.
Типи машинного навчання
Машинне навчання можна розділити на три основні типи: кероване навчання, некероване навчання та навчання з підкріпленням. Кожен із цих типів має конкретну мету і використовує різні форми даних.
Кероване навчання
Кероване навчання (навчання з учителем) – це метод машинного навчання, заснований на використанні даних, які мають присвоєні класи або ярлики (labels). У цьому процесі інженер контролює навчання, надаючи алгоритму великі обсяги розмічених даних. Шляхом аналізу цих даних модель виявляє закономірності та структури, що дозволяє їй точно визначати класи об'єктів нових даних. Однак для досягнення високої точності потрібен значний обсяг розмічених даних, що може бути трудомістким етапом у процесі навчання.
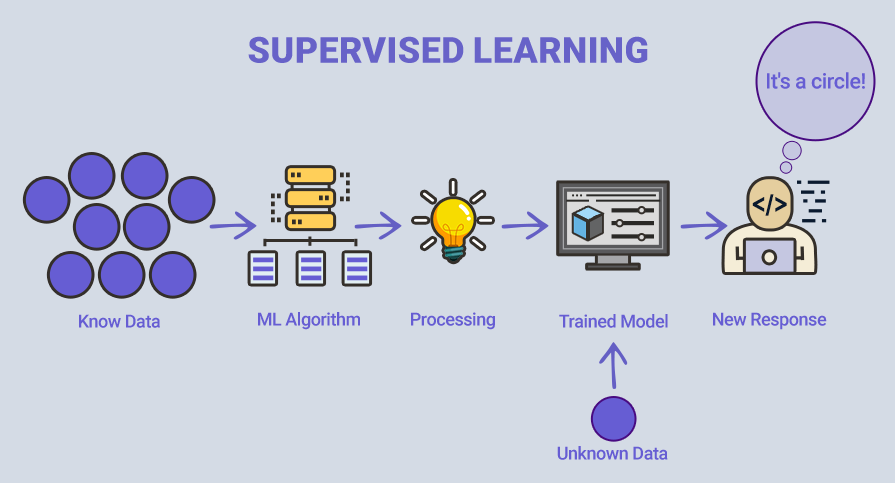
У випадку, наведеному на ілюстрації, модель намагається з'ясувати, чи є дані колом або іншою фігурою. Як тільки модель буде добре навчена, вона визначить, що дані це коло, і дасть бажану відповідь.
Кероване навчання може вирішувати два типи завдань: класифікація та регресійний аналіз.
Класифікаційні алгоритми в машинному навчанні підходять для завдань, пов'язаних із прогнозуванням належності об'єктів до заздалегідь визначених категорій чи класів. Вони добре підходять для вирішення завдань, таких як:
- Розпізнавання образів
- Фільтрування спаму
- Медична діагностика
- Фінансовий моніторинг
Проте класифікаційні алгоритми не можуть бути оптимальними для завдань, де потрібно передбачення чисельного значення (регресія). Також вони можуть неефективно працювати у випадках, де класи неоднорідні або перекриваються, і коли в наявних даних є багато шуму. У такому разі краще використовувати регресійні моделі чи інші типи алгоритмів, більш підходящих для конкретних умов завдання.
Регресійний аналіз у керованому навчанні – це метод, який використовується для аналізу відношення між залежною змінною (цільовою) і однією або декількома незалежними змінними (ознаками). Він дозволяє передбачати значення залежної змінної на основі значень незалежних змінних, виявляти закономірності та будувати моделі, які можуть використовуватися для прогнозування значень на основі вхідних даних.
Декілька типових завдань, для яких застосовується регресійний аналіз:
- Прогнозування
- Економічний аналіз
- Маркетингові дослідження
- Медична статистика
- Наукові дослідження
- Інженерні програми
Некероване навчання
При некерованому навчанні (навчанні без вчителя) використовуються невідомі та не помічені дані (unlabeled data), що означає, що вони не були попередньо вивчені. Без урахування наперед відомої інформації, вхідні дані передаються алгоритму машинного навчання для тренування моделі. Основна мета в машинному навчанні без вчителя полягає у виявленні структури та закономірностей у даних, без явного керівництва у вигляді цільових відповідей.
Приклади методів машинного навчання без вчителя включають:
- Кластеризація: Групування даних на основі їх подібності таким чином, щоб об'єкти в одній групі (кластері) були більш схожі один на одного, ніж на об'єкти з інших груп.
- Зниження розмірності: Зниження кількості ознак даних, зберігаючи при цьому основні характеристики набору даних. Прикладами можуть бути метод головних компонент (PCA) або t-розподілене вкладення стохастичної близькості (t-SNE).
- Навчання уявлень: Створення автоматичного представлення даних, що дозволяє моделі отримувати значимі ознаки без явного програмування. Нейронні мережі, такі як автокодувальники, можуть використовуватись у цьому контексті.
- Виявлення викидів (аномалій): Виявлення незвичайних або аномальних зразків даних, що відрізняються від загальних трендів.
- Асоціативні правила: Виявлення зв'язків та взаємозв'язків між змінними у наборі даних, наприклад, в аналізі купівельної поведінки.
Машинне навчання без вчителя корисне в тих випадках, коли ми не маємо чітко визначених міток або цільових змінних, і ми хочемо вивчити структуру даних, виявити приховані закономірності або зробити попередній аналіз даних.
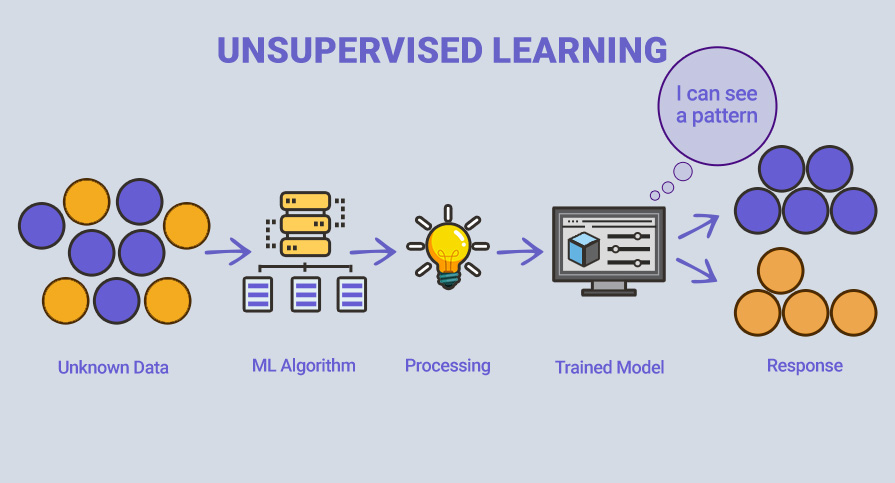
У випадку, наведеному на ілюстрації, невідомі дані складаються з фігур, які схожі одна на одну. Навчена модель намагається зібрати їх усі разом, щоб ви отримали ті самі речі в схожих групах.
Навчання з підкріпленням
Машинне навчання з підкріпленням включає агента, середовище та дії, де агент взаємодіє з навколишнім середовищем, приймаючи рішення. Навчання полягає у виборі дій для максимізації очікуваної винагороди, особливо при дотриманні розумної стратегії. У штучному інтелекті цей процес включає отримання нагороди чи штрафу за кожну дію з метою максимізації загальної кількості балів. Це можна порівняти з новачком, який грає в гру та поступовим поліпшенням продуктивності через аналіз взаємозв'язку дій, відображення та рахунку.
Переваги та недоліки машинного навчання
Машинне навчання пропонує унікальні переваги, такі як здатність до обробки великих обсягів даних, автоматизація рутинних завдань та підвищення точності прогнозування.
За допомогою машинного навчання можна визначити такі закономірності даних, які часто вислизають від людського сприйняття. З'являється можливість обробляти різноманітні формати даних у динамічних, об'ємних та складних середовищах даних.
Однак серед недоліків можна виділити залежність від якості та кількості даних, витрати та труднощі на етапі підготовки даних, висока вартість та ресурсоємність впровадження без достатнього обсягу даних, а також складність інтерпретації результатів та вирішення невизначеності без участі кваліфікованого фахівця.
Цей баланс переваг і недоліків робить машинне навчання корисним інструментом, але таким, що потребує уважного керування.
Марія Липа, QuData розробник