
Чи проходить GPT-4 тест Тюрінга?
Великі мовні моделі (LLM), такі як GPT-4, на думку багатьох, вважаються технологічними дивами, здатними успішно проходити тест Тюрінга. Але як це відповідає дійсності?
ChatGPT підкорив вершини в галузі штучного інтелекту (ШІ). Він може здаватися розумним, швидким та вражаючим. Він уміло демонструє видимий інтелект, веде розмови з людьми, може наслідувати людське спілкування і навіть проходить іспити з юриспруденції. Однак, у деяких випадках він все ще надає неправдиву інформацію.
Так чи може ChatGPT успішно пройти тест Тюрінга і створювати текст, який не відрізняється від відповіді людини?
Двоє дослідників з Університету Каліфорнії в Сан-Дієго вивчили це питання та отримали цікаві результати. Кемерон Джонс, який спеціалізується на мові, семантиці та машинному навчанні, і Бенджамін Берген, професор когнітивних наук, провели онлайн-тест Тюрінга. В ході тесту одна людина намагалася визначити, чи є досліджуваний суб'єкт штучним інтелектом або ж людиною. У ролі штучного інтелекту виступав GPT-3.5 чи GPT-4.
Експеримент передбачав проведення онлайн-тестування, що включало діалоги між 650 учасниками та моделями GPT. Учасникам пропонувалося визначити, з ким вони розмовляють, людиною чи ШІ. Конфігурації GPT-3.5 та GPT-4 змінювалися під час експерименту. Значною частиною дослідження став промпт, який направляв LLM на певну тематику та стиль розмови. Цей промпт задавав характер взаємодії та особи агента, і його змінювали, щоб з'ясувати, як він впливає на результат.
Кожен діалог мав обмеження часу – 5 хвилин, та обмеження за обсягом повідомлення – менше 300 символів. Загалом в експерименті взяли участь 652 судді, які завершили 1810 “ігор”. Після виключення підозрілих результатів кількість “ігор” скоротилася до 1405.
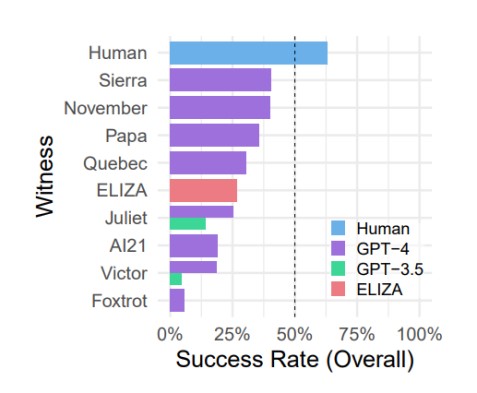
Результати показали, що у 41% випадків моделі GPT-4 змогли обдурити учасників, тоді як моделі GPT-3.5 впоралися лише у 5–14% випадків. Для порівняння, стара модель ELIZA (1966) набрала цілих 27% випадків визнання її людиною. Крім цього, виявили цікавий факт: учасникам вдалося переконати інших учасників, що вони не є машинами лише у 63% випадків.
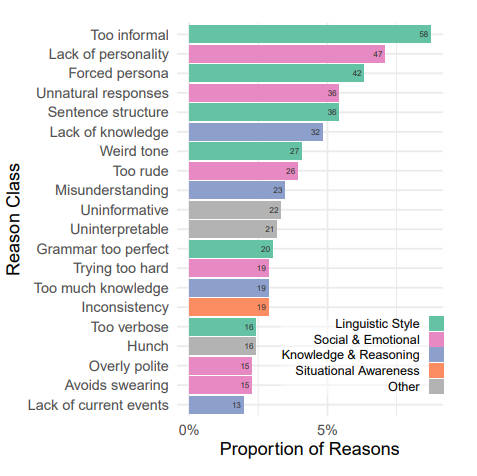
Досить цікавим моментом виявилися мотиви, за якими учасники ухвалювали свої рішення. Причини, з яких ШІ вважався ШІ були такими. Якщо штучний інтелект видавався надто формальним чи неформальним, це могло викликати в них занепокоєння. Аналогічно, надто багатослівні чи надто короткі відповіді, дивний тон розмови чи ідеальна граматика ставали важливими чинниками у визначенні, чи є співрозмовник людиною чи машиною. Також варто зазначити, що недолік знань виявлявся важливішим за надмірність знань. Можливо, моделям штучного інтелекту слід продовжувати вчитися. Учасники тестування також виявляли чутливість до загальних відповідей.
Дослідники дійшли висновку, що на основі цього експерименту не можна стверджувати, що GPT-4 успішно пройшов тест Тюрінга. Незважаючи на це, показник успішних обманів на рівні 41% свідчить про те, що використання штучного інтелекту для обману стає дедалі реальнішим. Особливо це актуально у ситуаціях, де співрозмовники-люди менш уважні до можливості спілкування з машиною.
Моделі штучного інтелекту, здатні з успіхом імітувати людські відповіді, мають потенціал спричинити широкі соціальні та економічні наслідки. Стане все більш важливим відстежувати моделі штучного інтелекту та визначати фактори, що призводять до обману, а також розробляти стратегії щодо його пом'якшення. Тим не менш, дослідники підкреслюють, що тест Тюрінга, як і раніше, залишається важливим інструментом для оцінювання машинного діалогу та розуміння взаємодії людини зі штучним інтелектом.
З подивом можна відзначити, як швидко ми досягли часу, коли технічні системи можуть змагатися з людиною у сфері спілкування. Незважаючи на сумніви в успіху GPT-4 у цьому тесті, його результати вказують на те, що ми наближаємося до створення штучного інтелекту, здатного конкурувати з людиною у діалогах.
Ознайомитись із дослідженням можна тут.