Як нейронні мережі навчаються руху? Інтерпретація моделювання руху з використанням відносної зміни положення
Розуміння руху відіграє важливу роль у крос-медійному аналізі на основі відео та навчанні множинному уявленню знань. Група дослідників під керівництвом Хехе Фана вивчила проблеми розпізнавання та прогнозування фізичного руху за допомогою глибинних нейронних мереж (DNNs), зокрема згорткові нейронні мережі та рекурентні нейронні мережі. Вчені розробили та протестували підхід до глибинного навчання, заснований на відносній зміні положення, яка закодована у вигляді серії векторів, та виявили, що їх метод працює краще, ніж існуючі фреймворки для моделювання руху.
У фізиці рух - це відносна зміна положення в часі. Щоб виключити вплив факторів об'єкта і фону, вчені сфокусувалися на ідеальному сценарії, в якому точка рухається в двомірній (2D) площині. Для оцінки здатності архітектур DNN моделювати рух використовувалися два завдання: розпізнавання руху та прогнозування руху. В результаті було розроблено векторну мережу (VecNet) для моделювання відносної зміни положення. Ключовим нововведенням вчених було кодування руху окремо від положення.
Дослідження групи було опубліковано у журналі Intelligent Computing.
Дослідження присвячене аналізу руху. Розпізнавання руху спрямоване на розпізнавання різних типів рухів із серії спостережень. Це можна розглядати як одну з необхідних умов розпізнавання дій, оскільки розпізнавання дій можна розкласти на розпізнавання об'єкта та розпізнавання руху. Наприклад, щоб розпізнати дію «відчинити двері», DNN повинні розпізнати об'єкт «двері» та рух «відкрити». В іншому випадку модель не відрізняла б «відкрити двері» від «відкрити вікно» або «відкрити двері» від «зачинити двері». Прогнозування руху спрямовано на прогнозування майбутньої зміни положення після перегляду частини руху, тобто контексту руху, що можна вважати однією з необхідних умов для відеопрогнозування.
VecNet сприймає рух на короткому інтервалі як вектор. VecNet також може перемістити точку у відповідну позицію, задану векторним представленням. Щоб отримати уявлення про рух протягом тривалого часу, використовувалася довга короткострокова пам'ять (LSTM) для агрегування або прогнозування векторних представлень з часом. Отриманий у результаті новий метод VecNet+LSTM здатний ефективно підтримувати як розпізнавання, так і прогнозування, доводячи, що моделювання зміни відносного положення необхідне для розпізнавання руху і спрощує прогнозування руху.
Розпізнавання дій пов'язане з розпізнаванням руху, оскільки воно пов'язане з рухом. Так як не існує однозначної сучасної архітектури DNN для розпізнавання дій, дослідники порівняли та вивчили підмножину моделей, що охоплюють більшу частину області.
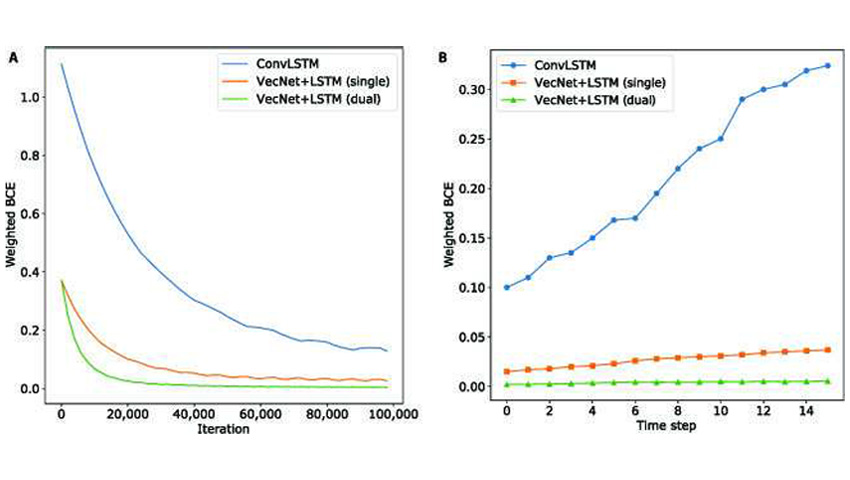
Підхід VecNet + LSTM при тестуванні розпізнавання руху отримав більш високі оцінки, ніж шість інших популярних архітектур DNN із відеодосліджень щодо моделювання зміни відносного стану. Частина з них виявилася просто слабшою, а частина абсолютно не підходила для завдання моделювання руху.
Наприклад, при порівнянні з методом ConvLSTM новий метод виявився точнішим, вимагав менше часу для навчання і не так швидко втрачав точність при виконанні додаткових прогнозів.
Експерименти показали, що метод VecNet + LSTM ефективний для розпізнавання та прогнозування руху. Він підтверджує, що використання відносної зміни положення значно покращує моделювання руху. За допомогою методів зовнішнього вигляду або обробки зображень пропонований метод моделювання руху можна використовувати для загального розуміння відео, яке можна буде вивчити у майбутньому.