
Як чат-боти та роботи після скоєних помилок можуть повернути довіру людей
При взаємодії з людьми роботи можуть робити помилки, підриваючи довіру до себе. Люди починають вважати ботів ненадійними. Різні стратегії відновлення довіри, які застосовують роботи, можуть бути використані для пом'якшення негативних наслідків цих порушень довіри. Проте незрозуміло, чи можуть такі стратегії повністю відновити довіру, і наскільки вони ефективні після неодноразових помилок.
Тому вчені з університету Мічигану вирішили провести дослідження стратегій поведінки роботів з метою відновлення довіри між ним і людиною. Цими стратегіями довіри були вибачення, спростування, пояснення та обіцянки надійності.
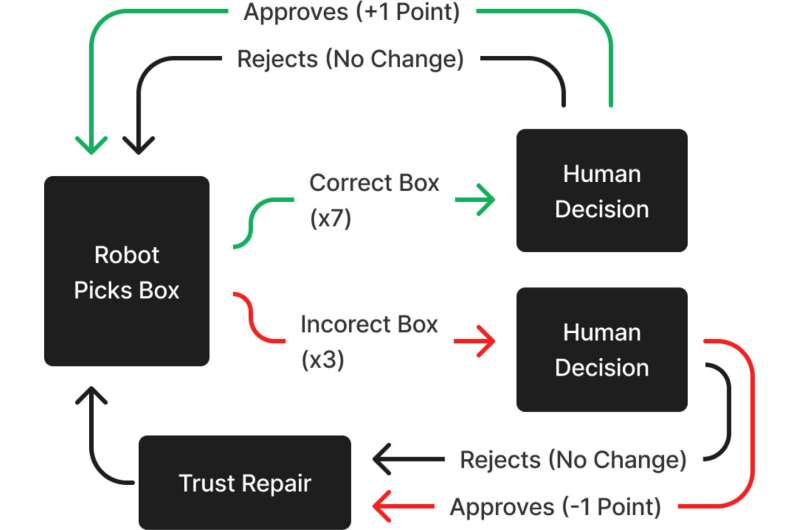
Було проведено експеримент, у якому 240 учасників працювали з колегою-роботом над виконанням завдання, в якому іноді робот робив помилки. Робот порушував довіру учасника, а потім пропонував певну стратегію відновлення довіри. Учасники були задіяні як члени команди, спілкування пари людина-робот відбувалось через інтерактивне віртуальне середовище, розроблене в Unreal Engine 4.

Це середовище було змодельовано так, щоб виглядати як справжній склад. Учасники розташовувалися за столом із двома дисплеями та трьома кнопками. На дисплеях відображався поточний рахунок команди, швидкість обробки коробок та серійний номер, необхідний учасникам для оцінки коробки, представленої їх товаришем по команді – роботом. Рахунок кожної команди збільшувався на 1 очко щоразу, коли на стрічку конвеєра відправлялась правильна коробка, і зменшувався на 1 очко щоразу, коли на конвеєр ставилася неправильна коробка. У тих випадках, коли робот вибирав не ту коробку, і учасники відзначали це як помилку, на екрані з'являвся індикатор і вказував, що ця коробка невірна, але очки з рахунку команди не додавалися і не віднімалися.
“Щоб перевірити наші гіпотези, ми використали план між суб'єктами з чотирма умовами виправлення та двома умовами контролю”, – прокоментува Коннор Естервуд, дослідник із UM School of Information та провідний автор дослідження.
Умови контролю мали форму мовчання робота після помилки. Робот не намагався ніяк відновити довіру людини, він просто мовчав. Також у разі ідеальної роботи робота без помилок під час експерименту він теж нічого не говорив.
Умови виправлення, що використовуються в цьому дослідженні, мали вигляд вибачення, спростування, пояснення або обіцянки. Вони застосовувалися після кожної помилки. При умові вибачення робот говорив: “Мені шкода, що я отримав не ту коробку того разу”. У разі відмови робот заявляв: “Того разу я вибрав правильну коробку, але щось ще пішло не так”. Для пояснень робот використовував фразу: “Я бачу, що це був неправильний серійний номер”. І, нарешті, щодо умови обіцянок робот говорив: “Наступного разу я зроблю краще і візьму правильну коробку”.
Кожна з цих відповідей була розроблена, щоб представити тільки один тип стратегії відновлення довіри і уникнути ненавмисного об'єднання двох або більше стратегій. Під час експерименту учасникам повідомляли про ці виправлення як за допомогою аудіо, так і текстових субтитрів. Примітно, що робот лише тимчасово змінював свою поведінку після того, як одну зі стратегій відновлення довіри було реалізовано. Він обирав правильні коробки ще двічі перш, ніж припускався наступної помилки.
Для оцінки результатів дослідники використали серію непараметричних тестів суми рангів Крускала-Уолліса. Далі слідували апостеріорні тести множинних порівнянь Данна з поправкою Бенджаміні-Хохберга для контролю множинної перевірки гіпотез.
“Ми обрали ці методи замість інших тому, що дані у цьому дослідженні не мали нормального розподілу. У першому з цих тестів ми вивчали наші маніпуляції з надійністю та порівнювали відмінності у надійності між станом ідеальної продуктивності та станом відсутності відновлення довіри. У другому тесті використовувалися три окремих тести Крускала-Уолліса, за якими слідували апостеріорні дослідження для визначення оцінок здібностей та доброзичливості учасників при спробах відновлення довіри”, – зазначили Естервуд та Роберт Лайонел, професор інформації та співавтор досліджень.
Основні результати дослідження:
- Жодна стратегія відновлення довіри повністю не відновлювала надійність робота.
- Вибачення, пояснення та обіцянки не могли відновити уявлення про здібності.
- Вибачення, пояснення та обіцянки не могли відновити уявлення про чесність.
- Вибачення, пояснення та обіцянки однаково відновили доброзичливість робота.
- Відмовами було неможливо відновити уявлення про надійність робота.
- Після трьох помилок жодна із стратегій відновлення довіри ніколи повністю не відновлювала надійність робота.
Результати дослідження мають два наслідки. Естервуд відмітив, що дослідники повинні розробити більш ефективні стратегії відновлення, щоб допомогти роботам краще відновлювати довіру після їхніх помилок. Крім того, роботи повинні бути впевнені, що вони впоралися з новим завданням перш, ніж намагатись відновити довіру людини до них.
“В іншому випадку вони ризикують втратити довіру людини настільки, що її неможливо буде відновити”, – сказав Естервуд.