Автор тексту людина чи робот? Вчені створюють інструмент-детектор
Загальний розвиток штучного інтелекту і, особливо, запуск ChatGPT від OpenAI з його напрочуд точними та логічними відповідями та діалогами розбурхав суспільну свідомість і підняв нову хвилю інтересу до великих мовних моделей (LLM). Стало зрозуміло, що їхні можливості більші, ніж ми будь-коли припускали. Заголовки відображали як захоплення, так і приводи для занепокоєння: чи можуть роботи написати супровідний лист? Чи можуть допомагати учням проходити тестування? Чи впливатимуть вони на виборців через соціальні мережі? Чи здатні створювати дизайн замість художників? Позбавляти письменників роботи?
Після яскравого запуску ChatGPT тепер про появу аналогічних моделей ведуться розмови у Google, Meta та інших компаніях. Дослідники комп'ютерних наук закликають до посилення контролю. Вони вважають, що суспільству необхідний новий рівень інфраструктури та інструментів для захисту цих моделей, і зосередились на розробці такої інфраструктури.
Одним із таких ключових засобів захисту може стати інструмент, який здатний надати вчителям, журналістам та громадянам можливість розрізняти тексти, створені LLM, та тексти, написані людиною.
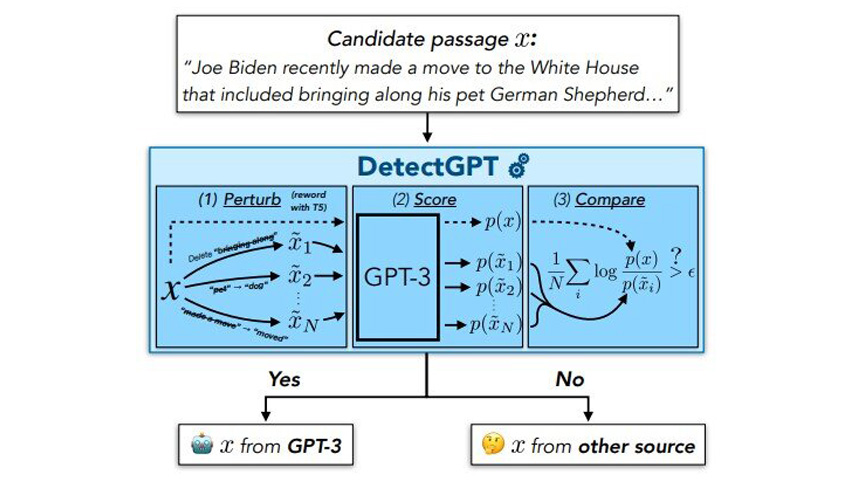
З цією метою Ерік Ентоні Мітчелл, аспірант четвертого курсу комп'ютерних наук Стенфордського університету, у процесі захисту докторського ступеню разом із своїми колегами розробили DetectGPT. Він вийшов у реліз у вигляді демонстрації та документа, який розрізняє текст, згенерований LLM, від тексту, створеного людиною. У початкових експериментах інструмент точно визначає авторство в 95% випадків п'яти популярних LLM з відкритим вихідним кодом. Інструмент знаходиться на ранній стадії розробки, але Мітчелл та його колеги працюють над тим, щоб у майбутньому він приніс значну користь суспільству.
Раніше проводилися дослідження деяких загальних підходів до вирішення проблеми ідентифікації авторства текстів. Один з підходів, що використовується самим OpenAI, включає навчання моделі текстами двох видів: одні тексти були згенеровані LLM, а інші створювалися людьми. Потім модель просять визначити автора тексту. Але, на думку Мітчелла, щоб це рішення було успішним у різних предметних областях та різними мовами, підхід вимагатиме величезної кількості даних для навчання.
Другий підхід дозволяє уникнути навчання нової моделі і просто використовує LLM, на яку подається текст з метою виявлення власних вихідних даних.
По суті, цей спосіб полягає в тому, щоб запитати LLM наскільки їй «подобається» зразок тексту, говорить Мітчелл. І під критерієм «подобається» він не має на увазі, що це розумна модель, яка має власні вподобання. Найімовірніше, якщо моделі «подобається» фрагмент тексту, то це можна розглядати як високу оцінку для цього тексту від моделі. Мітчел припускає, що якщо моделі подобається текст, то ймовірно, що цей текст був згенерований нею чи подібними моделями. Якщо ж текст не подобається, то, швидше за все, він не був згенерований LLM. На думку Мітчела, цей підхід працює набагато краще, ніж випадкове вгадування.
Мітчелл припустив, що навіть найпотужніші LLM мають певні упередження щодо використання одного способу вираження думки замість іншого. Модель буде схильна менше "любити" будь-яке мінімальне перефразування власних результатів, ніж свій оригінал. У той самий час, якщо спотворити текст, створений людиною, ймовірність того, що моделі він сподобається більше чи менше оригіналу приблизно однакова.
Мітчелл також зрозумів, що цю теорію можна перевірити за допомогою популярних мовних моделей з відкритим вихідним кодом, зокрема доступних через API OpenAI. Адже обчислення того, наскільки моделі подобається конкретний фрагмент тексту, це, по суті, ключ до навчання моделі. Це може бути дуже корисним.
Щоб перевірити своє припущення, Мітчелл та його колеги провели експерименти, в ході яких вони спостерігали наскільки різним загальнодоступним LLM подобається текст, написаний людьми, а також їхній власний текст, згенерований LLM. У добірку текстів включили вигадані статті новин, творчі листи та академічні есе. Дослідники також вимірювали наскільки LLM у середньому сподобалися 100 спотворень кожного тексту, створеного LLM та людиною. Після всіх вимірів команда побудувала графік різниці між двома числами: для текстів LLM і для текстів, створених людьми. Вони побачили дві криві нормального розподілу, які ледве перекривалися. Дослідники зробили висновок, що можна дуже добре розрізняти джерело текстів, використовуючи одну цю величину. Таким чином, можна отримати набагато надійніший результат порівняно з методами, які просто визначають наскільки моделі подобається вихідний текст.
У початкових експериментах DetectGPT успішно класифікував текст, написаний людиною, і текст, створений LLM, у 95% випадків при використанні GPT3-NeoX, потужного варіанту моделей GPT OpenAI з відкритим вихідним кодом. DetectGPT також був здатний виявляти текст, створений людиною, і текст, згенерований LLM, з використанням великих мовних моделей, відмінних від вихідної моделі, але з дещо меншою достовірністю. На момент початкових експериментів ChatGPT був ще недоступним для прямого тестування.
Інші компанії та команди також шукають способи ідентифікувати текст, написаний ШІ. Наприклад, OpenAI вже випустила свій новий класифікатор тексту. Однак, Мітчелл не хоче прямо порівнювати результати OpenAI з результатами DetectGPT, оскільки немає стандартизованого набору даних для оцінки. Але його команда провела кілька експериментів з використанням завчасно навченого ШІ-детектора OpenAI попереднього покоління і виявила, що він добре працює зі статтями новин англійською мовою, погано працює з медичними статтями і повністю зазнає невдачі зі статтями новин німецькою мовою. За його словами, такі змішані результати є характерними для моделей, які залежать від попередньої підготовки. На відміну від них, DetectGPT працював задовільно для всіх цих трьох зазначених категорій текстів.
Відгуки користувачів DetectGPT вже допомогли виявити деякі вразливості. Наприклад, людина може спеціально запитати ChatGPT таким чином, щоб уникнути визначення автора, скажімо, спеціально попросить LLM написати текст подібно до людини. У команди Мітчела вже є кілька ідей як мінімізувати ці недоліки, але вони ще не перевірялися.
Ще одна проблема полягає в тому, що студенти, які використовують LLM, такі як ChatGPT, для обману при виконанні завдань просто редагуватимуть згенерований ШІ текст, щоб уникнути визначення автора. Мітчелл та його команда досліджували цю можливість у своїй роботі та зрозуміли, що, незважаючи на зниження якості виявлення відредагованих есе, система, як і раніше, непогано справляється з виявленням машинно-генерованого тексту, коли менше 10–15% слів було змінено.
У довгостроковій перспективі мета команди DetectGPT полягає в тому, щоб надати громадськості надійний і дієвий інструмент прогнозування того, чи був текст, повністю або лише його частина, згенерований машиною. Навіть якщо модель не думає, що всі есе або стаття новин були написані машиною, потрібен інструмент, який може виділити абзац або речення, які виглядають особливо машинно-створеними.
Варто підкреслити, що, на думку Мітчелла, існує безліч законних варіантів використання LLM в освіті, журналістиці та інших сферах. Однак надання суспільству інструментів для перевірки джерела інформації завжди було корисним і залишається таким навіть у епоху ШІ.
DetectGPT – лише одна з кількох робіт, які Мітчелл створює для LLM. Минулого року він також опублікував кілька підходів до редагування LLM, а також стратегію під назвою «самознищувальні моделі», яка відключає LLM, коли хтось намагається використовувати її в негідних цілях.
Перед тим, як захистити докторську дисертацію, Мітчелл сподівається вдосконалити кожну з цих стратегій хоча б ще раз.
Дослідження опубліковано на сервері препринтів arXiv.