
Прорив NVIDIA у створенні синтетичних даних для штучного інтелекту
Компанія NVIDIA представила сімейство моделей Nemotron-4 340B, набір потужних моделей з відкритим доступом, які було розроблено для покращення генерації синтетичних даних і навчання великих мовних моделей (LLM). Группа включає три різні моделі: Nemotron-4 340B Base, Nemotron-4 340B Instruct і Nemotron-4 340B Reward. Зазначені моделі обіцяють значно розширити можливості штучного інтелекту в багатьох галузях, включаючи охорону здоров’я, фінанси, виробництво та роздрібну торгівлю.
Головна інновація Nemotron-4 340B полягає в здатності моделі генерувати високоякісні синтетичні дані, що є ключовим компонентом для ефективного навчання LLM. Якісні навчальні дані часто дорогі та їх важко отримати, але за допомогою Nemotron-4 340B розробники можуть створювати надійні набори даних у великих масштабах. Фундаментальна модель Nemotron-4 340B Base була навчена на величезному датасеті з 9 трильйонів токенів і може бути додатково доопрацьована за допомогою власних даних. Модель Nemotron-4 340B Instruct генерує різноманітні синтетичні дані, які імітують реальні сценарії, тоді як модель Nemotron-4 340B Reward забезпечує якість цих даних, оцінюючи відповіді на основі корисності, правильності, узгодженості, складності та багатослівності.
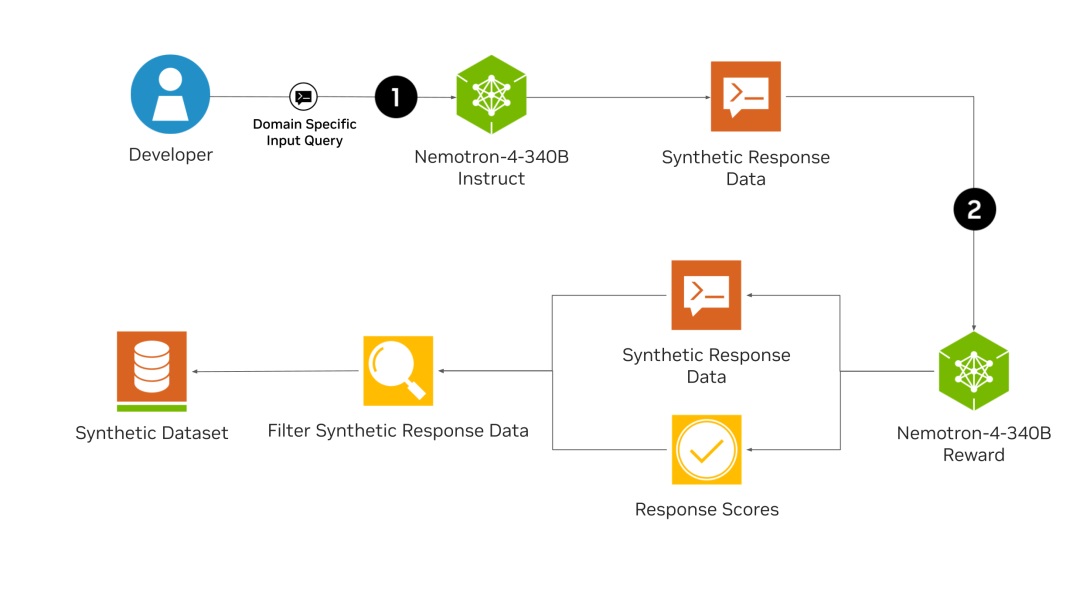
Відмінною особливістю моделі Nemotron-4 340B є її складний процес узгодження, який використовує як пряму оптимізацію переваг (direct preference optimization, DPO), так і оптимізацію переваг з урахуванням винагороди (reward-aware preference optimization, RPO) для точного налаштування моделей. DPO оптимізує відповіді моделі, максимізуючи різницю у винагороді між бажаними та небажаними відповідями, тоді як RPO додатково уточнює це, враховуючи різницю у винагороді між відповідями. Цей подвійний підхід гарантує, що моделі не тільки створюють високоякісні результати, але й зберігають баланс між різними показниками оцінки.
NVIDIA застосувала процес поетапного контрольованого тонкого налаштування (staged supervised fine-tuning, SFT) для покращення можливостей моделі. Перший етап, Code SFT, зосереджується на вдосконаленні здібностей кодування та логічного мислення за допомогою синтетичних даних кодування, згенерованих за допомогою Genetic Instruct – методу, який моделює еволюційні процеси для створення високоякісних зразків. Наступний етап General SFT передбачає навчання на різноманітних наборах даних, щоб переконатися, що модель добре працює в широкому діапазоні завдань, зберігаючи при цьому свої навички кодування.
Моделі Nemotron-4 340B отримують значну перевагу від ітеративного процесу узгодження від слабкого до сильного, який безперервно вдосконалює моделі за допомогою послідовних циклів генерації даних і тонкого налаштування. Починаючи з початкової узгодженої моделі, кожна ітерація генерує дані вищої якості та більш уточнені моделі, створюючи самопосилювальний цикл вдосконалення. Цей ітеративний процес використовує як потужні базові моделі, так і високоякісні набори даних для підвищення загальної продуктивності навчальних моделей.
Практичне застосування моделей Nemotron-4 340B дуже різноманітне. Завдяки генеруванню синтетичних даних і вдосконаленню узгодження моделей ці інструменти можуть значно підвищити точність і надійність систем ШІ в різних галузях. Розробники можуть легко отримати доступ до цих моделей на NVIDIA NGC, Hugging Face, і в майбутньому через платформу ai.nvidia.com.