Ембедінг стохастичного кластера – новий метод візуалізації великих наборів даних
Дивовижна здатність людського мозку – вміння знаходити відмінності навіть у величезній кількості візуальної інформації. При вивченні великих масивів даних ця здатність виявляється дуже корисною, адже зміст даних необхідно стиснути у форму, зрозумілу людському інтелекту. Для візуальної аналітики проблема зменшення розмірності залишається основною.
Вчені з Університету Аалто та Гельсінського університету у Фінському центрі штучного інтелекту (FCAI) провели дослідження, де вони перевірили функціональність найвідоміших методів візуальної аналітики та виявили, що жоден з них не працює, коли обсяг даних значно зростає. Наприклад, методи t-SNE, LargeViz та UMAP більше не могли розрізняти надзвичайно сильні сигнали груп спостережень у даних, коли кількість спостережень стала обчислюватися сотнями тисяч. Методи t-SNE, LargeViz та UMAP вже не працюють належним чином.
Дослідники розробили новий метод нелінійного зменшення розмірності під назвою Stochastic Cluster Embedding (SCE) для кращої візуалізації кластера. Він спрямований на максимально чітку візуалізацію наборів даних та покликаний візуалізувати кластери даних та інші макроскопічні ознаки так, щоб вони були максимально чіткими, легкими для спостереження та зрозумілими людині. SCE використовує графічне прискорення аналогічно сучасним методам штучного інтелекту для обчислень у нейронних мережах.
Основою винаходу цього алгоритму стало відкриття бозона Хіггса. Набір даних для експериментів, пов'язаних із ним, містить понад 11 мільйонів векторів ознак. І ці дані вимагали зручної, наочної візуалізації. Це надихнуло вчених на розробку нового методу.
Дослідники узагальнили SNE, використовуючи сімейство I-дивергенцій, параметризованих масштабним коефіцієнтом s, між не нормалізованими подібностями у вхідному і вихідному просторі. SNE є особливим випадком у сімействі, де s вибрано як нормалізуючий фактор подібності виходів. Однак у ході тестування було виявлено, що найкраще значення s для візуалізації кластера часто відрізняється від вибраного значення SNE. Тому, щоб подолати недоліки t-SNE, новий метод SCE використовує інший підхід, який змішує вхідні подібності при обчисленні s. Коефіцієнт адаптивно коригується при оптимізації нової мети навчання, і, таким чином, точки даних краще згруповані. Також дослідниками було розроблено ефективний алгоритм оптимізації, що використовує асинхронний стохастичний спуск по блокових координатах. Новий алгоритм може використовувати паралельні обчислювальні пристрої та підходить для мегамасштабних завдань з великими обсягами даних.
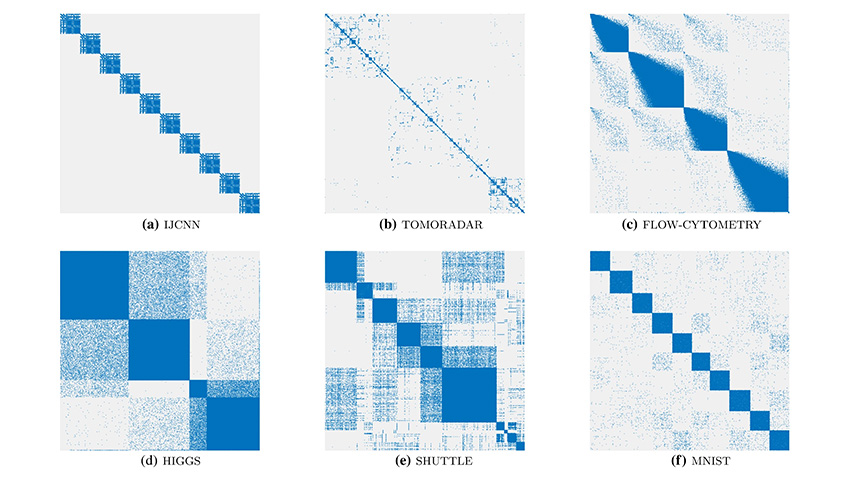
У ході розробки проєкту вчені протестували метод на різних наборах реальних даних та порівняли його з іншими сучасними методами NLDR. Користувачі, які брали участь у тестуванні, вибирали найбільш вдалі візуалізації, які відповідають діапазону значень s для перегляду кластерів. Потім дослідники порівнювали отримані значення s у SCE та t-SNE, щоб подивитися, що ближче до людського вибору. Для тестування використовувалися чотири найменші набори даних IJCNN, TOMORADAR, SHUTTLE та MNIST. Для кожного набору даних учасникам тестування надавалася серія візуалізацій, де вони використовували повзунок для вказівки значення s та перевіряли відповідну попередньо обчислену візуалізацію. Користувач обирав найкраще значення s для візуалізації кластера.
У результатах тестування наочно видно, що s, вибраний SNE, знаходиться праворуч від медіани людини (суцільна зелена лінія) для всіх наборів даних. Це свідчить про те, що для людини GSNE з меншим s часто краще ніж t-SNE для візуалізації кластера. А вибір SCE (червоні пунктирні лінії) ближче до медіани людини для всіх чотирьох наборів даних.

При застосуванні методу Stochastic Cluster Embedding до даних про бозони Хіггса було чітко виділено їх найважливіші фізичні характеристики. Новий метод нелінійного зменшення розмірності Stochastic Clustering Embedding для кращої візуалізації кластера працює на кілька порядків швидше, ніж попередні методи, а також набагато надійніший у складних програмах. Він модифікує t-SNE, використовуючи адаптивний та ефективний компроміс між тяжінням та відштовхуванням. Експериментальні результати показали, що метод послідовно може ідентифікувати внутрішні кластери. Крім того, вченими було запропоновано простий та швидкий алгоритм оптимізації, який можна легко реалізувати на сучасних платформах паралельних обчислень. Розроблено ефективне програмне забезпечення, що використовує асинхронний стохастичний градієнтний блоковий спуск для оптимізації нового сімейства цільових функцій. Експериментальні результати продемонстрували, що метод послідовно та суттєво покращує візуалізацію кластерів даних у порівнянні з сучасними підходами стохастичного ембеддингу сусідів (Neighbor Embedding).
Код методу знаходиться у відкритому доступі на сайті github.