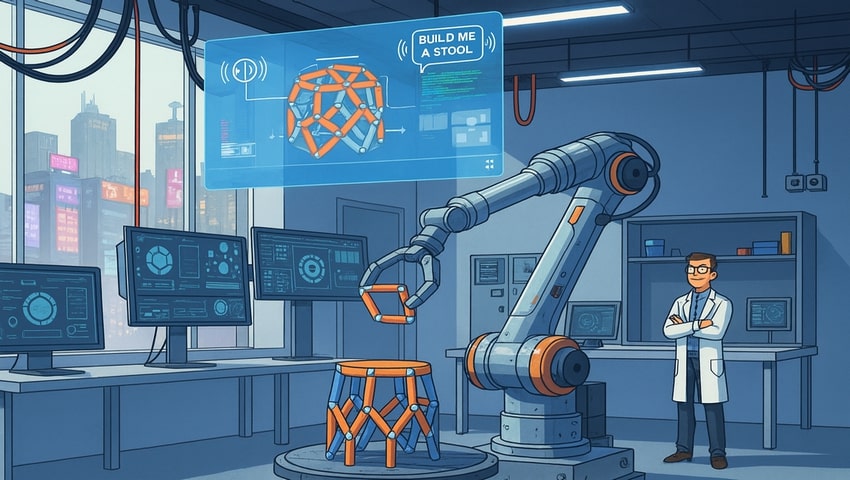
Від слів до реальності за лічені хвилини
Межа між науковою фантастикою та реальністю стає все більш розмитою завдяки дослідникам з Массачусетського технологічного інституту (MIT), які розробили систему, здатну за лічені хвилини перетворювати голосові команди на фізичні об’єкти. Платформа “Speech-to-Reality” використовує обробку природної мови, генеративний ШІ для 3D-моделювання, геометричний аналіз та роботизований монтаж. Платформа дозволяє виготовляти меблі, функціональні та декоративні предмети на замовлення, без потреби в навичках 3D-моделювання чи робототехніки.
Робочий процес системи починається з розпізнавання мови, перетворюючи голосові команди користувача в текст. Велика мовна модель (LLM) інтерпретує текст, щоб ідентифікувати бажаний фізичний об’єкт, фільтруючи абстрактні або нездійсненні команди. Опрацьований запит служить вхідними даними для генеративної 3D-моделі, яка створює полігональну сітку зображення об’єкта (mesh model).
Оскільки згенеровані штучним інтелектом 3D-моделі не завжди придатні для безпосереднього збору, система застосовує алгоритм дискретизації компонентів, що перетворює сітку в набір модульних кубооктаедричних елементів. Кожен модуль має розмір 10 см і з’єднується за допомогою магнітних фіксаторів, забезпечуючи багаторазове, безінструментальне складання. Далі геометричні алгоритми перевіряють можливість збірки з урахуванням обмежень: доступності елементів, наявності непідтримуючих виступів, стійкості вертикальних сегментів та з’єднаності конструкції. Додатково застосовується направлене перемасштабування та послідовність з урахуванням зв’язності, що забезпечує структурну цілісність і запобігає зіткненням під час роботизованого монтажу.
Модуль автоматичного планування траєкторій, побудований на бібліотеці Python-URX, генерує команди руху для шестивісного робота-маніпулятора UR10, оснащеного спеціальним захватом. Пасивні центрувальні елементи захвата забезпечують точне розміщення навіть при незначному зносі компонентів. Збірка відбувається пошарово, у порядку, який забезпечує постійну опору та стабільність конструкції. Конвеєрна система повертає використані модулі у цикл для наступних збірок, що підтримує стале та циклічне виробництво.
Платформа успішно продемонструвала швидке складання різних об’єктів: табурети, столи, полиці та декоративні предмети, такі як літери або фігурки тварин. Завдяки алгоритмам, що враховують геометричні обмеження, система здатна виконувати складні конструкції з великими виступами, високими вертикальними секціями чи розгалуженою геометрією. Точне калібрування швидкості та прискорення роботизованої руки додатково підвищує надійність складання та запобігає структурним зсувам.
Попри використання 10-сантиметрових модулів, система є повністю масштабованою та може працювати з меншими елементами. Також можлива інтеграція з гібридними методами виробництва. Майбутні ітерації можуть включати управління жестами, доповнену реальність для попереднього перегляду та уточнення конструкцій, а також повністю автоматизований демонтаж й модифікацію вже створених об’єктів.
Платформа Speech-to-Reality формує технічний фундамент для інтеграції генеративного дизайну на основі штучного інтелекту з фізичною роботизованою збіркою. Поєднання технологій розпізнавання мовлення, 3D-ШІ, дискретного модульного складання та роботизованого управління створює умови для швидкого, масштабованого та сталого виготовлення фізичних предметів, відкриваючи новий рівень співтворення між людиною та ШІ в реальних умовах.