W2V-BERT: Поєднання контрастного навчання та моделювання мови з маскою для самостійного попереднього навчання мовлення
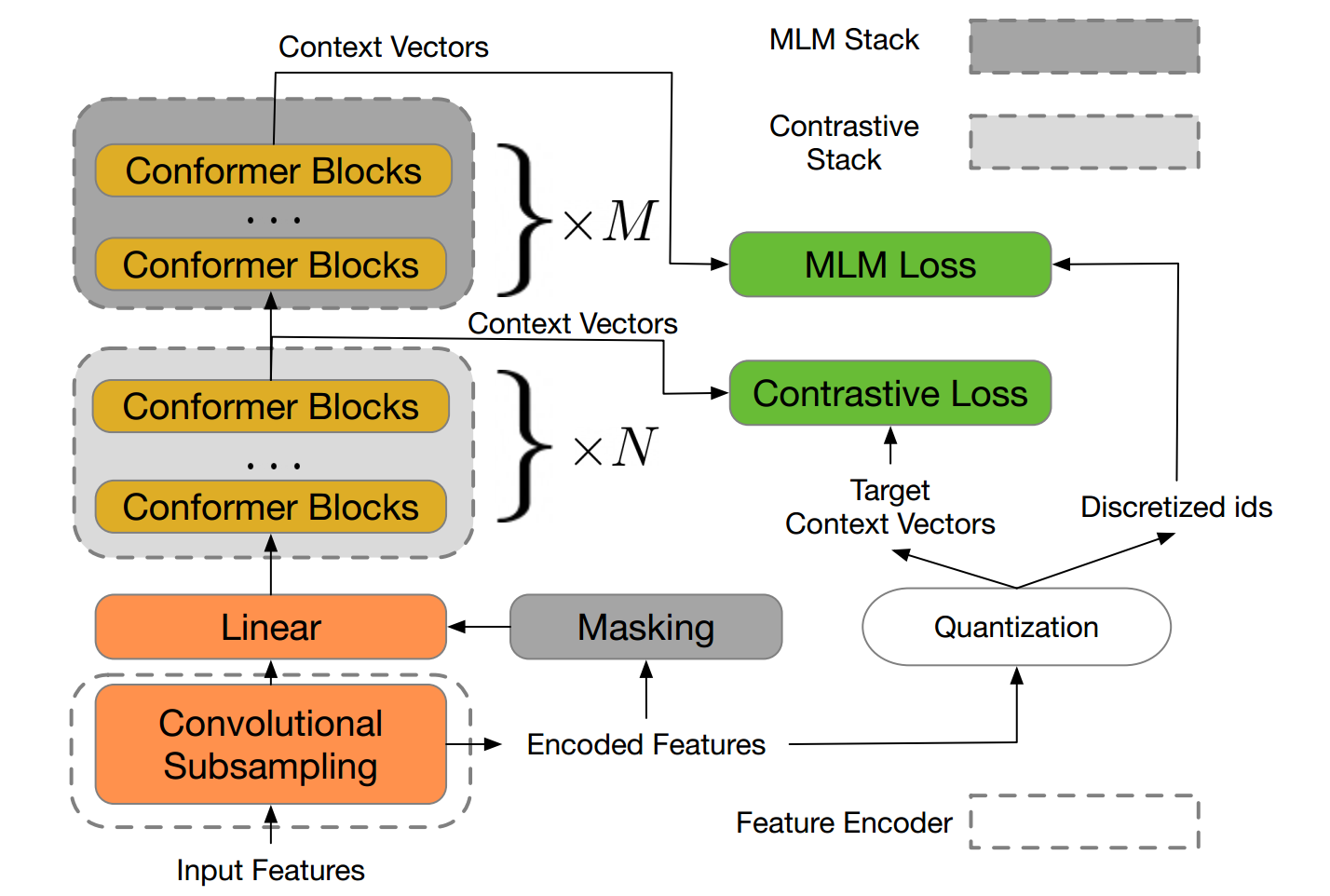
Мотивовані успіхом маскового мовного моделювання (МЛМ) в допідготовлених моделях обробки природної мови перед навчанням, автори пропонують модель w2v-BERT, яка досліджує МЛМ для самонавчального мовного представлення.
w2v-BERT – це фреймворк, який об'єднує контрастне навчання та МЛМ, де перший тренує модель вибірки вхідних безперервних мовних сигналів у скінченний набір описових назв мовлення, а другий тренує модель вивчення контекстуалізованих мовних уявлень шляхом вирішення проблеми прогнозування з маскою, яка живить дискретизовані токени як вхідні.
На базі МЛМ, таких як HuBERT, в основі яких лежить процес перегрупування і перепідготовки, abo vq-wav2vec, певних двох активних модулів, w2v-BERT можна оптимізувати під якнайкраще, годинні віртуальні два завдання і МЛМ).
Експерименти, проведені авторами, показують, що w2v-BERT досягає конкурентних результатів у порівнянні з сучасними заздалегідь навченими моделями на бенчмарках LibriSpeech при використанні пакету Libri-Light ~ 60k в якості «неконтрольованих» даних.
На зокрема, в порівнянні з опублікованими моделями, такими як wav2vec~2.0 і HuBERT, представлена модель показує відносне зниження WER з 5% до 10% на тест-чистих і тестово-інших підмножинах. При застосуванні до набору даних про трафік голосового пошуку Google w2v-BERT перевершує авторську модель wav2vec ~ 2.0 більш ніж на 30%.
Целиком статью можно просмотреть здесь.
Також на YouTube є навчальне відео.