
Что такое машинное обучение?
Машинное обучение представляет собой научную дисциплину, посвященную разработке алгоритмов и статистических моделей. В отличие от традиционного программирования в машинном обучении не требуется создавать модель самостоятельно. Дата-инженер собирает и готовит данные для машинного обучения, а также экспериментирует с различными алгоритмами машинного обучения для построения лучшей модели. Когда модель сформирована, остается лишь задействовать ее при решении задачи и получить результат.
Еще одним существенным отличием машинного обучения от традиционного программирования является количество обрабатываемых входных параметров. Для точного прогноза погоды в конкретной локации потребуется введение тысяч параметров, влияющих на результат. Построение алгоритма, способного разумно использовать все эти параметры, представляет собой сложную задачу для человека. В машинном обучении нет таких ограничений: при наличии достаточной мощности процессора и памяти можно использовать любое количество входных параметров по усмотрению пользователя.
В сфере медицины машинное обучение играет важную роль в диагностике, персонализации лечения и прогнозной аналитике. Алгоритмы анализируют обширные наборы данных, выявляя тонкие закономерности, которые могут ускользнуть от человеческого наблюдения. Например, сервис QuData для точной диагностики рака обеспечивает раннее выявление онкопатологии, способствует необходимому медицинскому вмешательству, а также позволяет специалистам получить независимое экспертное мнение.
Распознавание речи с помощью машинного обучения изменило определение взаимодействия человека и компьютера. Усовершенствованные алгоритмы обрабатывают устную речь, преобразуя ее в текст или выполняемые команды. Голосовые помощники, службы языкового перевода и устройства с голосовым управлением — все они используют машинное обучение для точного понимания и реагирования на человеческую речь.
Машинное обучение внедряет перспективные изменения в сферу бизнеса, предоставляя компаниям мощный инструментарий для оптимизации процессов и принятия более обоснованных решений. Эффективность этой технологии проявляется в способности анализа огромных объемов данных, выявлении тенденций и формировании прогнозов, что становится неоценимым активом для принятия стратегических решений.
Как работает машинное обучение?
Машинное обучение – это сложный процесс, начинающийся с сбора данных. На первом этапе проекта исследователи аккуратно формируют датасет, решая, создавать ли его самостоятельно, использовать общедоступные источники или приобретать готовые данные. Это важный шаг, так как качество и объем данных напрямую влияют на последующую эффективность модели машинного обучения.
После сбора данных следует их подготовка. Этот этап включает в себя тщательное преобразование данных в удобный формат, например, в CSV-файлы, и обеспечение их соответствия целям, которые необходимо достичь. Это включает в себя очистку данных от дубликатов, исправление ошибок, добавление недостающей информации и масштабирование данных до стандартного формата.
Выбор подходящего алгоритма машинного обучения становится следующим важным шагом. В зависимости от поставленной задачи и доступных вычислительных ресурсов исследователи могут выбирать множество различных алгоритмов. Нет универсального решения, идеально подходящего для всех случаев. Прежде, чем решать задачу, стоит определиться, с каким объемом данных предстоит работать, с каким типом данных будет осуществляться взаимодействие, какую информацию следует ожидать от данных, и, наконец, какие планируются сферы применения выбранного метода.
Следующий этап в разработке модели включает в себя обучение модели: передачу данных системе и настройку ее внутренних параметров для улучшения прогнозов. Однако, необходимо избегать явления переобучения, при котором модель хорошо справляется с тренировочными данными, но теряет эффективность на новых данных. Также стоит предотвращать недообучение, когда модель недостаточно эффективна как на тренировочных, так и на новых данных.
Оценка точности модели во время обучения – еще один неотъемлемый шаг. Здесь система тестируется на данных, которые не использовались во время тренировки. Обычно около 60% данных используется для тренировки модели (training data), 20% – для проверки прогнозов и корректировки и оптимизации гиперпараметров (validation data). Этот процесс важен для максимизации точности предсказаний системы при представлении новой информации. Оставшиеся 20% данных используются для тестирования (test data).
И, наконец, развертывание модели означает предоставление алгоритму новых данных и использование результатов системы для принятия решений или дальнейшего анализа.
Очень важно регулярно проверять на новых данных показатели качества модели. И если они слишком низкие, возможно, ее потребуется доработать.
Все эти шаги совместно обеспечивают создание гибкой и эффективной системы, способной адаптироваться к новой информации и делать точные прогнозы.
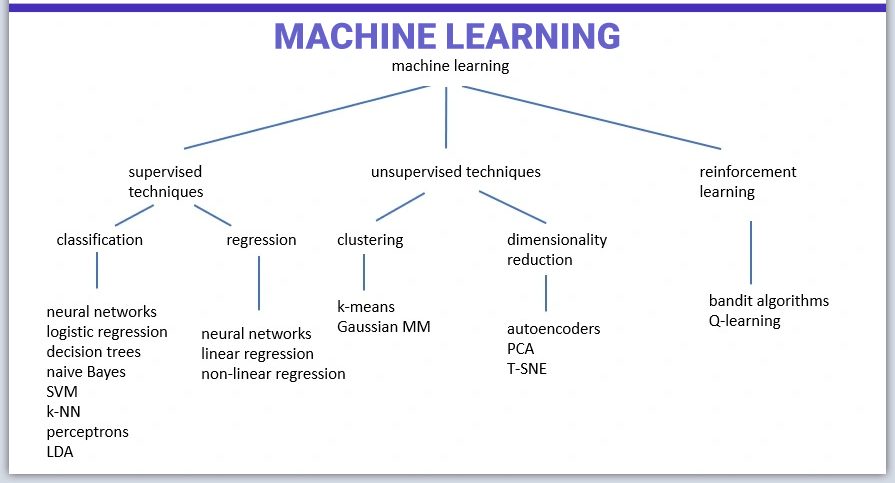
Типы машинного обучения
Машинное обучение можно разделить на три основных типа: обучение с учителем, обучение без учителя и обучение с подкреплением. Каждый из этих типов имеет конкретную цель и использует различные формы данных.
Обучение с учителем
Представляет собой метод машинного обучения, основанный на использовании данных, которые имеют присвоенные классы или ярлыки (labels). В этом процессе инженер контролирует обучение, предоставляя алгоритму большие объемы размеченных (labeled) данных. Путем анализа этих данных модель выявляет закономерности и структуры, что позволяет ей точно определять классы объектов на новых данных. Однако для достижения высокой точности требуется значительный объем размеченных данных, что может быть трудоемким этапом в процессе обучения.
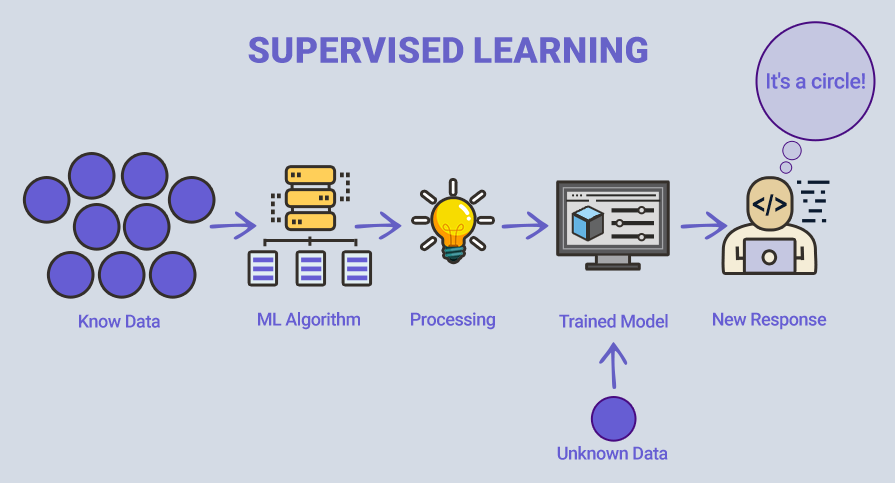
В случае, представленным на иллюстрации, модель пытается выяснить, являются ли данные кругом или другой фигурой. Как только модель будет хорошо обучена, она определит, что данные представляют собой круг, и даст желаемый ответ.
Обучение с учителем может решать два типа задач: классификация и регрессионный анализ.
Классификационные алгоритмы в машинном обучении подходят для задач, связанных с прогнозированием принадлежности объектов к заранее определенным категориям или классам. Они хорошо подходят для решения задач, таких как:
- Распознавание образов
- Фильтрация спама
- Медицинская диагностика
- Финансовый мониторинг
Однако классификационные алгоритмы могут не быть оптимальными для задач, где требуется предсказание численного значения (регрессия). Также они могут не эффективно работать в случаях, где классы неоднородны или перекрываются, и когда в данных присутствует много шума. В таких случаях лучше использовать регрессионные модели или другие типы алгоритмов, более подходящих для конкретных условий задачи.
Регрессионный анализ в обучении с учителем представляет собой метод, используемый для анализа отношений между зависимой переменной (целевой) и одной или несколькими независимыми переменными (признаками). Он позволяет предсказывать значения зависимой переменной на основе значений независимых переменных, выявлять закономерности и строить модели, которые могут использоваться для прогнозирования значений на основе входных данных.
Несколько типичных задач, для которых применяется регрессионный анализ:
- Прогнозирование
- Экономический анализ
- Маркетинговые исследования
- Медицинская статистика
- Научные исследования
- Инженерные приложения
Обучение без учителя
При обучении без учителя используются неизвестные и не помеченные данные (unlabeled data), что означает, что они не были предварительно изучены. Без учета заранее известной информации, входные данные передаются алгоритму машинного обучения для обучения модели. Основная цель в машинном обучении без учителя заключается в выявлении структуры и закономерностей в данных, без явного руководства в виде целевых ответов.
Примеры методов машинного обучения без учителя включают в себя:
- Кластеризация: Группировка данных на основе их сходства так, чтобы объекты в одной группе (кластере) были более похожи друг на друга, чем на объекты из других групп.
- Понижение размерности: Снижение количества признаков в данных, сохраняя при этом основные характеристики набора данных. Примерами могут быть методы главных компонент (PCA) или t-распределения стохастического вложения соседей (t-SNE).
- Обучение представлений: Создание автоматического представления данных, позволяющего модели извлекать значимые признаки без явного программирования. Нейронные сети, такие как автокодировщики, могут использоваться в этом контексте.
- Обнаружение выбросов (аномалий): Выявление необычных или аномальных образцов в данных, отличающихся от общих трендов.
- Ассоциативные правила: Выявление связей и взаимосвязей между переменными в наборе данных, например, в анализе покупательского поведения.
Машинное обучение без учителя полезно в тех случаях, когда у нас нет четко определенных меток или целевых переменных, и мы хотим изучить структуру данных, выявить скрытые закономерности или сделать предварительный анализ данных.
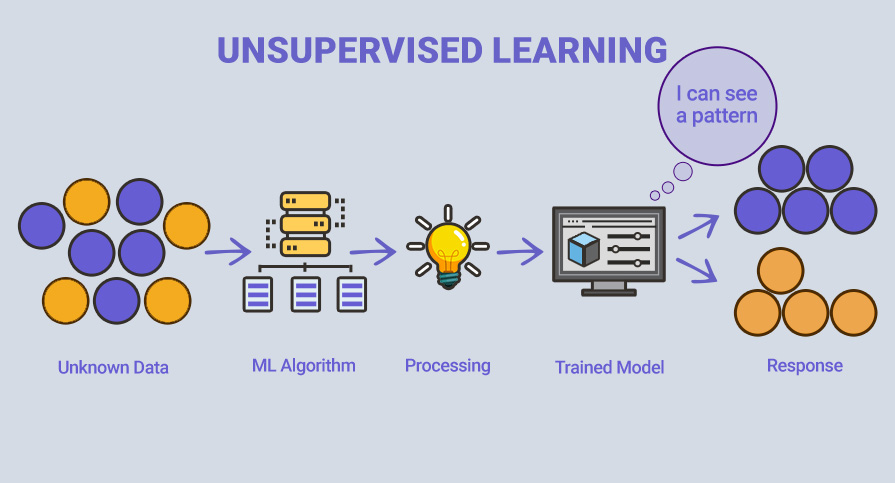
В случае, представленным на иллюстрации, неизвестные данные состоят из фигур, которые похожи друг на друга. Обученная модель пытается собрать их все вместе, чтобы вы получили одни и те же вещи в похожих группах.
Обучение с подкреплением
Машинное обучение с подкреплением включает агента, среду и действия, где агент взаимодействует с окружающей средой, принимая решения. Обучение заключается в выборе действий для максимизации ожидаемого вознаграждения, особенно при соблюдении разумной стратегии. В искусственном интеллекте этот процесс включает получение награды или штрафа за каждое действие, с целью максимизации общего количества баллов. Это можно сравнить с новичком, играющим в игру и постепенным улучшением производительности через анализ взаимосвязи действий, отображения и счета.
Преимущества и недостатки машинного обучения
Машинное обучение предоставляет уникальные преимущества, такие как способность к обработке больших объемов данных, автоматизация рутинных задач и повышение точности прогнозирования.
С помощью машинного обучения можно определить такие закономерности данных, которые часто ускользают от человеческого восприятия. Появляется возможность обрабатывать разнообразные форматы данных в динамических, объемных и сложных средах данных.
Однако среди недостатков можно выделить зависимость от качества и количества данных, затраты и трудности на этапе подготовки данных, высокая стоимость и ресурсоемкость внедрения без достаточного объема данных, а также сложность интерпретации результатов и решения неопределенности без участия квалифицированного специалиста.
Этот баланс преимуществ и недостатков делает машинное обучение значимым, но требующим внимательного управления инструментом.
Мария Липа, QuData разработчик