
Эффективные методы решения задач работы с текстом с помощью LLM, llama.cpp и guidance
В последние годы нейронные модели с использованием машинного обучения стали большой частью разнообразных сфер человеческой деятельности. Одним из наиболее растущих направлений в этом контексте стало использование языковых моделей, таких как LLM (Large Language Models). Эти модели, которые включают в себя современные достижения в сфере обработки языка, имеют потенциал решать разнообразные задачи в широком спектре областей. От анализа текста, суммаризации и автоматического перевода до генерации контента и управления данными, LLM модели оказались чрезвычайно полезными инструментами для решения сложных задач в современном мире.
Автоматическая обработка текста – одна из таких задач, в которых человеческий фактор играет значительную роль – одно и то же предложение, написанное разными людьми, может быть как простым и увлекательным, так и заведомо перегруженным и сложным. В этой статье мы разберем, как подобную задачу можно решить и без расходования значительных ресурсов, с приемлемой скоростью работать с текстами с помощью моделей ИИ, обрабатывая их автоматически.
Список задач, которые можно решать с помощью больших лингвистических моделей и правильных инструкций, может быть достаточно длинным. Это и любые задачи суммаризации текста, выделение из текста сущностей, перефразирование текста из одного стиля в другой или "умное" добавление ключевых слов в текст.
Современные лингвистические модели и LLM
Instruct LLM – это достаточно новая разработка в сфере обработки естественного языка. Это спектр моделей, построенный на основе Transformer блоков, которые воспринимают текст как "токены", то есть слова или их частицы, и обладает уникальной способностью понимать сложные взаимосвязи между словами в предложениях. Это позволяет им более интеллектуально обрабатывать текст. Сама модель занимается предсказанием следующего токена из ее словаря, то есть определяет вероятности всех слов из словаря как следующего токена, а затем выбирает токен с вероятностью на основе сэмплинга.
Благодаря этой функциональности Instruct LLM может эффективно перефразировать текст, учитывая дополнительные указания и контекст на конкретном примере, делая сам текст "живым" и естественным. Достаточно большой минус, к которому приводит такой широкий функционал LLM-моделей – это размер. Типичный размер таких моделей, имеющих хорошее качество обработки и "понимание" текста – это 7-14 миллиардов параметров в формате float16 (2 байта памяти). Это означает, что для использования такой модели с размером, например, 7 миллиардов параметров необходимо:
2 (байта) * 7 000 000 000 (параметры) / 1024 (KB) / 1024 (MB) / 1024 (GB) ≈ 13.04 GB
Итак, 13.04 гигабайт памяти потребуется для работы модели, а для значительной скорости более 13 GB памяти на видеокарте (VRAM) это достаточно много. Это и приводит к значительным затратам на железо при использовании подобных моделей, однако эту проблему может решить такой инструмент, как квантизация.
Сама модель, которая будет использоваться для данной задачи, называется Mistral-7B-Instruct от компании Mistral.AI. Это модель с инструкциями (то есть обученная с помощью RLHF следовать инструкциям пользователя) на 7 миллиардов параметров. После использования всех инструментов такая модель при работе будет занимать ≈4.5GB обычной RAM памяти, а также иметь скорость примерно 1.2 токена в секунду при использовании на среднеценовом процессоре.
Квантизация модели
Как мы уже отметили, одна из самых больших проблем при работе с большими лингвистическими моделями состоит в том, что они требуют значительных вычислительных ресурсов. Для решения этой проблемы мы используем квантизацию – процесс сжатия модели путем уменьшения количества битов, необходимых для представления каждого параметра. Так как float16 это обычно стандартный формат параметров для LLM-моделей, имеющий дробную часть, объем памяти для его использования можно сократить, используя тип данных с меньшим размером и только целой частью, например, 8 битный Integer, что при использовании его с знаком приведет к возможным значениям от -127 до 127. В общем виде такой метод квантизации выглядит так:
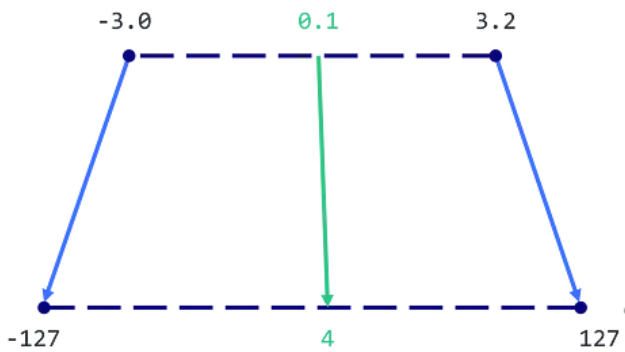
На рисунке можно увидеть, что значения будут масштабированы в новый формат. Это уменьшит объем памяти, которую занимает модель, не уменьшая ее эффективность и качество радикально. Для квантизации нашей модели Mistral-7b-Instruct мы используем llama.cpp – библиотеку с открытым кодом для эффективного использования моделей машинного обучения. Благодаря llama.cpp мы можем квантовать нашу модель, сохраняя при этом ее точность и эффективность.
Принцип ее работы несколько иной – для квантизации используется матрица важности. Суть матрицы важности состоит в том, чтобы получить градиенты весов параметров по прогону модели на заданном наборе обучающих токенов. Когда градиент веса данной модели невелик, это означает, что большое изменение веса параметра модели, то есть изменение параметра при квантизации, приведет к небольшому изменению продуктивности модели. И, напротив, большой градиент предполагает большое изменение производительности модели от небольшого изменения в весе параметра модели. Квадраты градиентов можно использовать как матрицу важности, и на основе этой матрицы и происходит более "умная" квантизация. Такой алгоритм позволил сократить модель Mistral-7B-Instruct с 13GB до примерно 4.5GB, при этом сохраняя адекватную скорость и качество. Важным аспектом является оценка ухудшения работы модели после такой квантизации, интуитивно можно ее увидеть здесь:
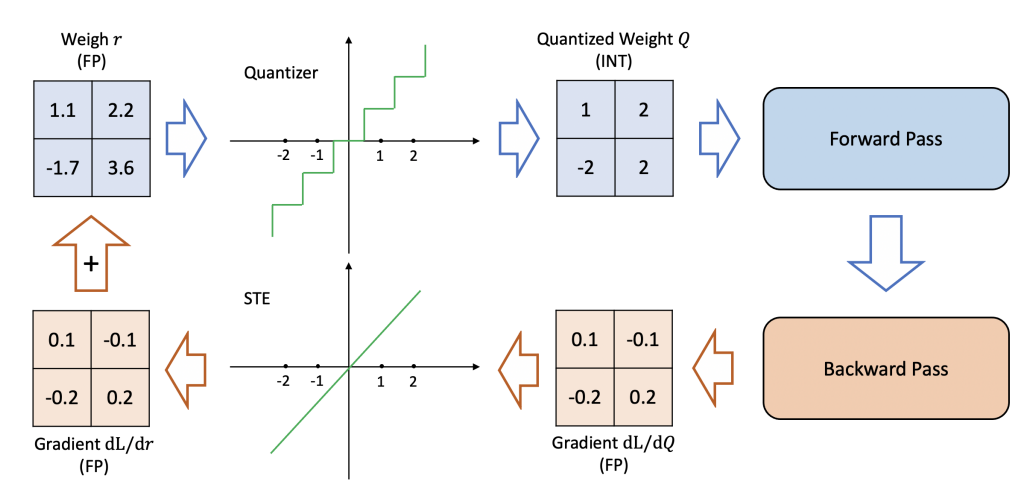
Так как количество значений в параметрах меньше, качество модели уменьшается. Для больших языковых моделей такое качество рассчитывается с помощью Perplexity, метрики, вычисляющей изменение вероятности следующего правильного токена на предсказании данных. Схематически это можно увидеть на следующем рисунке:

В этом примере мы можем рассчитать вероятность на слово "going" в квантизированной или неквантизированной модели на соответствие наиболее вероятному токену в генерации, таким образом рассчитав отличие вероятности, что и будет показателем Perplexity. В решении этой задачи мы используем наименьшую модель после квантизации. И хотя она имеет и самый высокий показатель Perplexity, то есть изменение от своей первоначальной вероятности, этого достаточно для рассматриваемой задачи. Таблица с показателями Perplexity для Mistral-7B-Instruct приведена ниже:
| Quant Type | Float16 | Q2_K | Q3_K | Q4_K | Q5_K | Q6_K |
| perplexity | 5.9066 | 6.7764 | 6.1503 | 5.9601 | 5.9208 | 5.9110 |
Формат исходных данных модели
LLM модели отличаются от других также и тем, что имея большой спектр задач, которые они могут решать, они и форматируют выход произвольным образом. Т.е. в задачах конкретного вида text2text могут добавлять объяснения, дополнительные примечания и другие конструкции, которые могут мешать автоматически отбирать результаты работы модели. Такое поведение можно исправлять с помощью инструкции к модели при запросе, то есть промпте, но на малых моделях это не всегда работает. Модель может "не слушаться" промпта. Для решения такой проблемы можно использовать библиотеку guidance. Она позволяет использовать большой спектр различных LLM-моделей с форматингом вывода модели, что позволяет более точно контролировать генерацию. Например, можно ограничить генерацию условиями "остановись на генерации новой строки" или позволить модели предусматривать только некоторый список из токенов. Пример:

На этом примере мы можем увидеть, что мы заранее указали слово "Answer" в ответе, поэтому модель сразу начала генерировать необходимые нам данные, и не зацикливалась на инструктивной разметке этих данных. Форматируя выход на нашей задаче, можно указать в генерации слова "Summarized result text:" или подобные, и генерировать короткие тексты только к новой строке. Это устранит основные проблемы с форматированием и поможет генерировать более естественные и качественные тексты. Однако это лишь малая часть всего того, что может быть реализовано с помощью guidance. Вот пример использования "select", позволяющий задать модели только некоторый спектр значений, которые она может выбрать. Это поможет генерировать только нужные сущности на основе контекста запроса.

Еще один комплексный пример таких генераций, позволяющих создавать целые конструкции на основе guidance функций, приведен ниже:
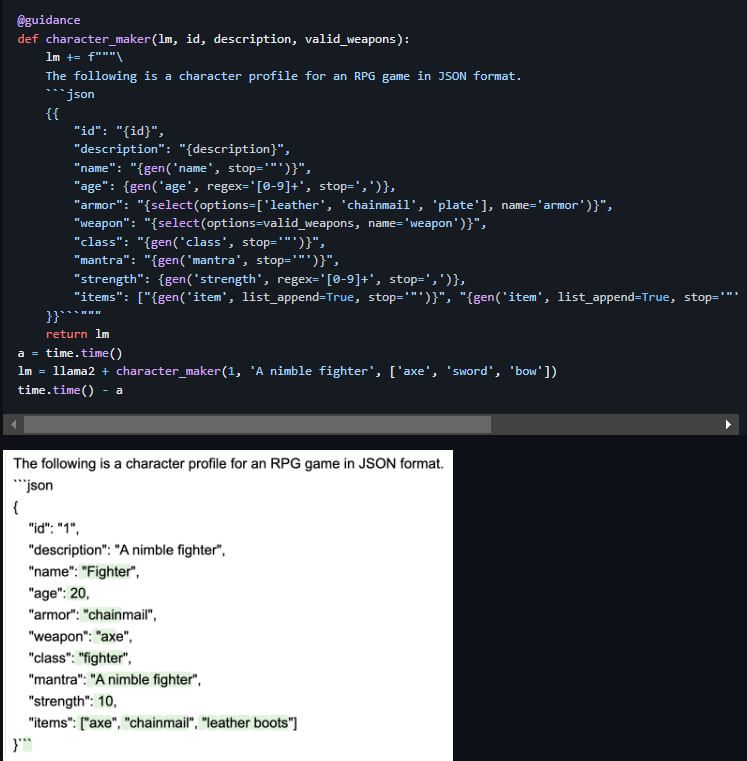
Как мы можем увидеть, начав генерировать персонажа для RPG-игры "воин", модель и в дальнейшем соблюдала контекст этого персонажа, задавая реалистичные параметры персонажа, и даже его вещи сгенерировала правильно. Соответственно, в таких конструкциях можно использовать как регулярные выражения, например для возраста, как это показано на примере, так и "for" циклы для генерации необходимого количества вещей. Или, например, запросить модель сгенерировать количество вещей у персонажа как число с помощью регулярного выражения, а затем, получив это число, использовать его в цикле для генерации динамического количества предметов. И это далеко не все возможности по управлению генерацией, поэтому использование этой библиотеки может решить многие проблемы в задачах обработки текста.
Разработанная система оптимизирует прикладные задачи по работе с текстом, добавляя и автоматический анализ, и обработку этих текстов на основе больших языковых моделей. Это значительно экономит время на выполнение рутинных задач и эффективно решает прикладные проблемы.
Николай Андрющенко, ML-инженер
Ресурсы:
1. Mistral-7B-Instruct
2. Llama.cpp
3. Guidance
4. ChatGPT и интуиция Instruct-моделей