
Преимущество древовидных архитектур перед сверточными сетями: исследование производительности
Традиционно методы обучения решений для глубокого обучения (DL) имеют свои корни в принципах работы человеческого мозга, где нейроны представлены узлами, которые связаны друг с другом, и сила этих связей меняется, когда нейроны активно взаимодействуют. Глубокие нейронные сети состоят из трех или более слоев, включая входные и выходные слои. Однако эти два сценария обучения существенно отличаются. Во-первых, для эффективных архитектур DL требуются десятки скрытых слоев прямого распространения, которые в настоящее время расширяются до сотен, в то время как динамика мозга состоит всего из нескольких слоев прямого распространения.
Во-вторых, архитектуры глубокого обучения обычно включают в себя много скрытых слоев, и большая часть из них - это сверточные слои. Эти сверточные слои ищут определенные образы или симметрии в небольших участках входных данных. Затем, когда эти операции повторяются в последующих скрытых слоях, они помогают выявить более крупные характеристики, которые определяют класс входных данных. Похожие процессы наблюдались в нашей зрительной коре, однако аппроксимированные сверточные связи были подтверждены главным образом от входа сетчатки глаза до первого скрытого слоя.
Еще один сложный аспект в глубоком обучении связан с тем, что метод обратного распространения ошибки, который важен для работы нейронных сетей, не имеет биологического аналога. Этот метод изменяет веса нейронов таким образом, что они становятся более подходящими для решения задачи.
В процессе обучения мы предоставляем сети входные данные и сравниваем, насколько она ошибается по сравнению с тем, что мы ожидали бы получить. Мы используем функцию ошибки для измерения этой разницы.
Затем мы начинаем обновлять веса нейронов так, чтобы уменьшить эту ошибку. Для этого мы рассматриваем каждый путь между входом и выходом сети, и определяем, как каждый вес на этом пути вносит свой вклад в общую ошибку. Мы используем эту информацию для коррекции весов.
Сверточные и полносвязные слои сети играют важную роль в этом процессе, и они особенно эффективны благодаря параллельным вычислениям на графических процессорах. Однако стоит отметить, что такой метод не имеет аналогов в биологии и отличается от того, как мозг человека обрабатывает информацию.
Итак, хотя глубокое обучение мощное и эффективное, оно является алгоритмом, разработанным исключительно для машинного обучения и не имитирует биологический процесс обучения.
Исследователи из Университета Бар-Илан в Израиле задались вопросом, можно ли создать новый вид эффективного искусственного интеллекта, используя архитектуру, похожую на искусственное дерево. В этой архитектуре каждый вес имеет только один путь к выходному блоку. Их гипотеза заключается в том, что такой подход может привести к более высокой точности при классификации, чем более сложные архитектуры глубокого обучения, которые используют большее количество слоев и фильтров. Исследование опубликовано в журнале Scientific Reports.
В основе этой работы стоит вопрос о том, может ли обучение на древовидной архитектуре, вдохновленной дендритными деревьями, достичь таких же успешных результатов, какие обычно достигаются при использовании более структурированных архитектур, включающих несколько полносвязных и сверточных слоев.
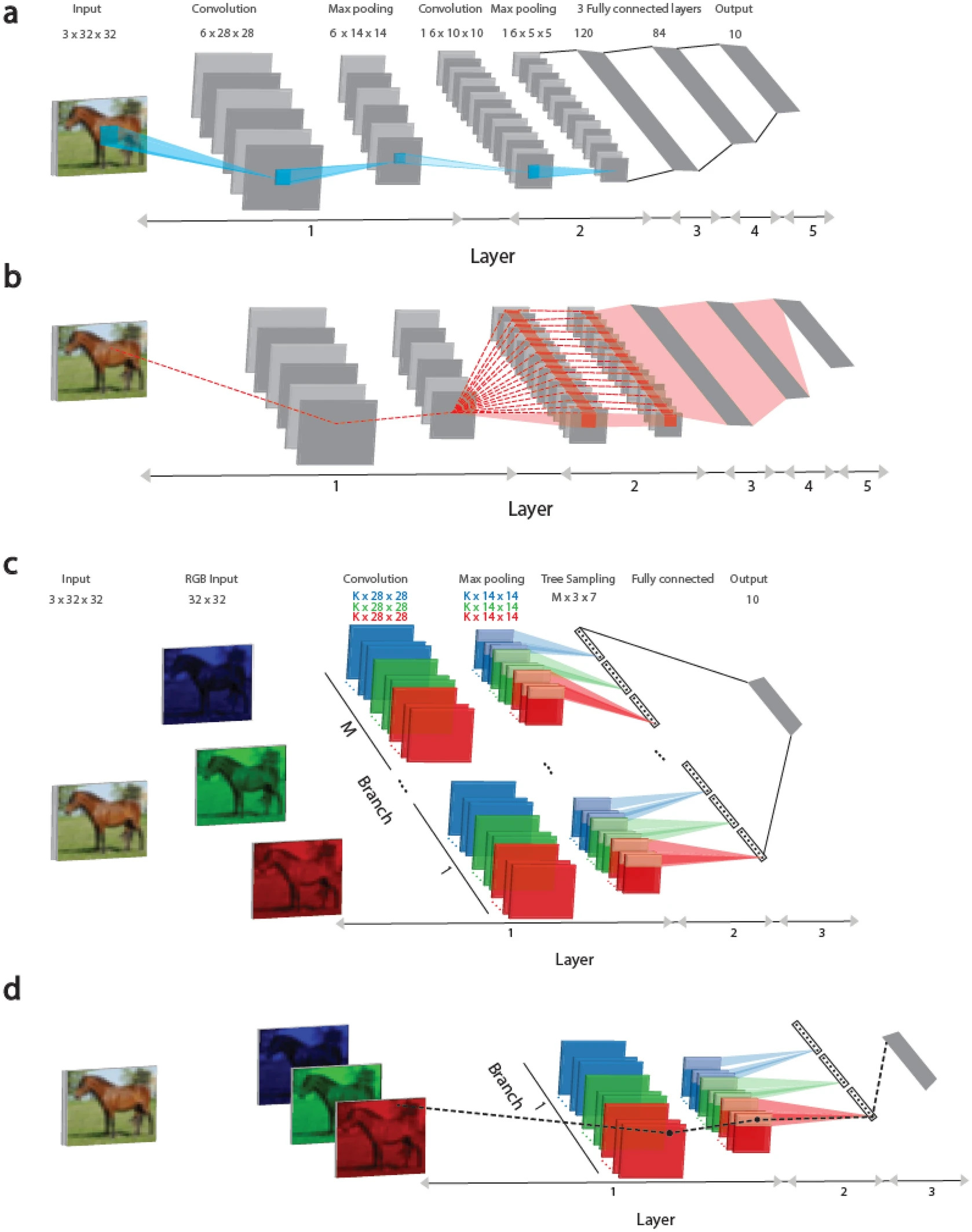
В этом исследовании представлен подход к обучению, основанный на древовидной архитектуре, где каждый вес подключен к выходному блоку только одним маршрутом, рисунок 1 (c, d). Такой подход, это еще один шаг к правдоподобной реализации биологического обучения. Он основывается на недавних данных о том, что дендриты (части нейрона) и их ближайшие ветви могут изменяться, а сигналы, проходящие через эти структуры, становятся сильнее и выразительнее.
Здесь показано, что показатели успеха предложенной архитектуры Tree-3, имеющей всего три скрытых уровня, превосходят достижимые показатели успеха LeNet-5 в базе данных CIFAR-10.
На рисунке 1 (а) рассмотрены сверточные архитектуры LeNet-5 и Tree-3. Сверточная сеть LeNet-5 для базы данных CIFAR-10 состоит из входящих изображений RGB размером 32 × 32, принадлежащих 10 выходным меткам. Первый слой состоит из шести (5 × 5) сверточных фильтров, за которыми следует (2 × 2) макс-пулинг, второй слой состоит из 16 (5 × 5) сверточных фильтров, а слои 3–5 имеют три полносвязных скрытых слоя размером 400, 120 и 84, которые подключаются к 10 выходным блокам.
На рисунке 1 (b) пунктирной красной линией отмечена схема маршрутов, влияющих на обновление весов, принадлежащих первому слою, на панели (a) во время процедуры обратного распространения ошибки. Вес подключен к одному из выходных блоков несколькими маршрутами (пунктирные красные линии) и может превышать один миллион. Важно отметить, что все веса на первом слое приравниваются к весам 6 × (5 × 5), принадлежащим шести сверточным фильтрам, рисунок 1 (c).
Архитектура Tree-3 состоит из М = 16 ветвей. Первый слой каждой ветви состоит из K (6 или 15) фильтров размером (5 × 5) для каждого из трех каналов RGB. Каждый канал свернут с собственным набором K фильтров, в результате чего получается 3 × K различных фильтров. Фильтры сверточного слоя одинаковы для всех ветвей M. Первый слой заканчивается макс-пулингом состоящим из (2 × 2) неперекрывающихся квадратов. В результате этого получается (14 × 14) выходных единиц для каждого фильтра. Второй слой состоит из выборки дерева. Для набора данных CIFAR-10 этот слой соединяет скрытые единицы первого слоя с помощью древовидной (непересекающейся) выборки (2 × 2 × 7 единиц) по K-фильтрам для каждого цвета RGB в каждой ветви, в результате чего для каждой ветви получается 21 выходной сигнал (7 × 3). Третий слой полностью соединяет выходы 21 × M ветвей M слоя 2 с 10 выходными модулями. Для онлайн-обучения используется функция активации ReLU, тогда как для офлайн-обучения используется Sigmoid.
На рисунке 1 (d) пунктирной черной линией отмечена схема одного маршрута, соединяющего обновленный вес на первом слое, отображенной на рисунке 1 (c) во время процедуры обратного распространения ошибки с выходным устройством.
Для решения задачи классификации исследователи применили функцию стоимости перекрестной энтропии и использовали алгоритм стохастического градиентного спуска для ее минимизации. Для настройки модели наилучшим образом были найдены оптимальные гиперпараметры, такие как скорость обучения, константа импульса и коэффициент затухания весов. Для проверки модели использовались несколько наборов данных проверки, состоящих из 10 000 случайных примеров, так же как и в тестовом наборе данных. Средние результаты были вычислены с учетом стандартного отклонения от заявленных средних показателей успеха. В исследовании были применены метод Нестерова и метод регуляризации L2.
Гиперпараметры для автономного обучения - η (скорость обучения), μ (константа импульса) и α (регуляризация L2), были оптимизированы для автономного обучения с 200 эпохами. Гиперпараметры онлайн-обучения были оптимизированы с использованием трех различных размеров наборов данных примеров.
В результате эксперимента был продемонстрирован эффективный подход к обучению древовидной архитектуре, где каждый вес подключается к выходному блоку только одним маршрутом. Это приближение к биологическому обучению и способ использовать глубокое обучение с помощью сильно сокращенных дендритных деревьев одного или нескольких нейронов. Важно отметить, что добавление одного сверточного слоя к входу помогает сохранить древовидную структуру и улучшить успех по сравнению с архитектурами без свертки.
Вычислительная сложность LeNet-5 оказалась значительно выше, чем у архитектуры Tree-3 с аналогичными показателями успешности. Однако для его эффективной реализации требуется новый тип аппаратного обеспечения. Ожидается также, что обучение древовидной архитектуре сведет к минимуму вероятность возникновения взрыва градиентов, что является одной из проблем глубокого обучения. Введение параллельных ветвей вместо второго сверточного слоя в LeNet-5 улучшило показатели успеха при сохранении древовидной структуры. Возможность того, что крупномасштабные и более глубокие древовидные архитектуры с расширенным количеством ветвей и фильтров могут конкурировать с современными показателями успеха CIFAR-10, заслуживает дальнейшего исследования. Этот эксперимент, использующий LeNet-5 как отправную точку, подчеркивает потенциальные преимущества дендритного обучения и его вычислительных возможностей.