Является ли глубокое обучение необходимым компонентом искусственного интеллекта?
В мире искусственного интеллекта вопрос о роли глубокого обучения становится все более центральным. Парадигмы искусственного интеллекта традиционно черпали вдохновение из функционирования человеческого мозга, но оказалось, что обучение, присущее нашему мозгу, имеет свои ограничения по сравнению с глубоким обучением (Deep learning). Глубокое обучение, несомненно, достигло впечатляющих успехов, однако оно обладает своими недостатками, включая высокую вычислительную сложность и потребность в большом объеме данных.
В свете вышепоставленных проблем, ученые из Университета Бар-Илан в Израиле задаются важным вопросом: необходимо ли включать глубокое обучение в состав искусственного интеллекта? Они представили свою новую работу, опубликованную в журнале Scientific Reports, которая продолжает их предыдущее исследование о преимуществе древовидных архитектур перед сверточными сетями. Основной целью нового исследования было выяснить, можно ли эффективно обучать сложные задачи классификации, используя менее глубокие нейронные сети, основанные на принципах, вдохновленных работой мозга, и при этом снижать вычислительную нагрузку. В данной статье мы представим вам ключевые результаты исследования, которые могут переписать правила игры в области искусственного интеллекта.
Итак, как мы уже знаем, для успешного решения сложных задач классификации требуется обучение глубоких нейронных сетей, состоящих из десятков или даже сотен сверточных и полносвязных скрытых слоев. Это существенно отличается от того, как функционирует человеческий мозг. В рамках глубокого обучения первый сверточный слой обнаруживает локализованные паттерны во входных данных, а последующие слои определяют более крупномасштабные паттерны, пока не будет достигнута надежная характеристика класса входных данных.
В данном исследовании показано, что при использовании фиксированного соотношения глубины первого и второго сверточных слоев ошибки в небольшой архитектуре LeNet, состоящей всего из пяти слоев, уменьшаются с увеличением количества фильтров в первом сверточном слое по степенному закону. Экстраполяция этого степенного закона позволяет утверждать, что обобщенная архитектура LeNet способна достигать низких значений ошибок, аналогичных тем, которые получаются с использованием глубоких нейронных сетей на базе данных CIFAR-10.
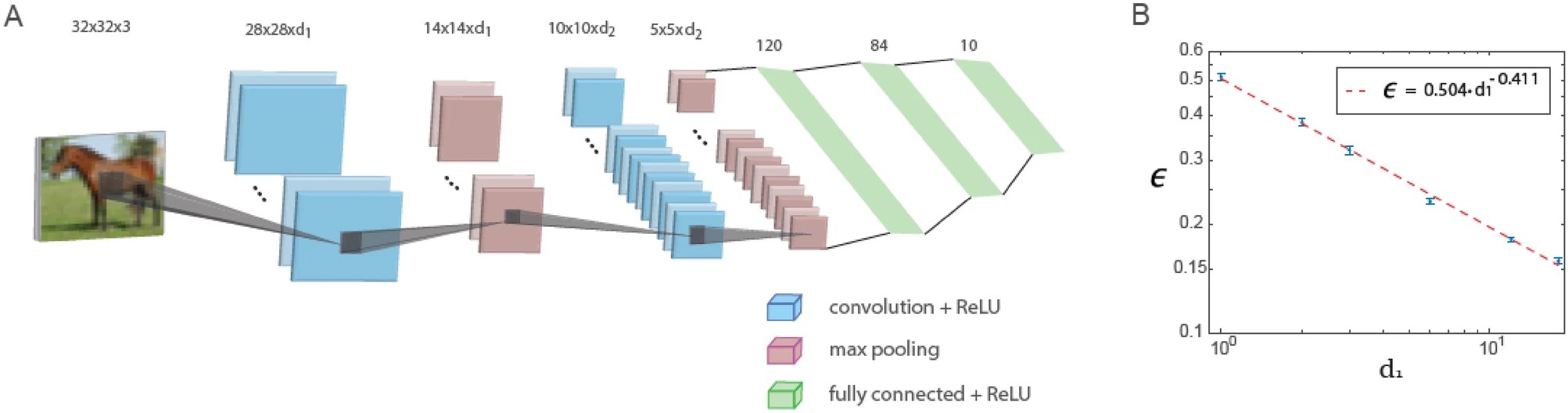
На рисунке ниже показано обучение в обобщенной архитектуре LeNet. Обобщенная архитектура LeNet для базы данных CIFAR-10 (размер входных данных 32 x 32 x 3 пикселя) состоит из пяти слоев: два сверточных слоя с использованием максимальной пулинговой операции и три полносвязных слоя. Первый и второй сверточные слои содержат d1 и d2 фильтров соответственно, где d1 / d2 ≃ 6 / 16. График зависимости тестовой ошибки, обозначенной как ϵ, от d1 на логарифмической шкале, что указывает на степенную зависимость с показателем степени ρ∼0.41. Функция активации нейронов - ReLU.
Подобное явление степенного закона также наблюдается для обобщенной архитектуры VGG-16. Однако это приводит к увеличению числа операций, необходимых для достижения заданного уровня ошибки по сравнению с LeNet.
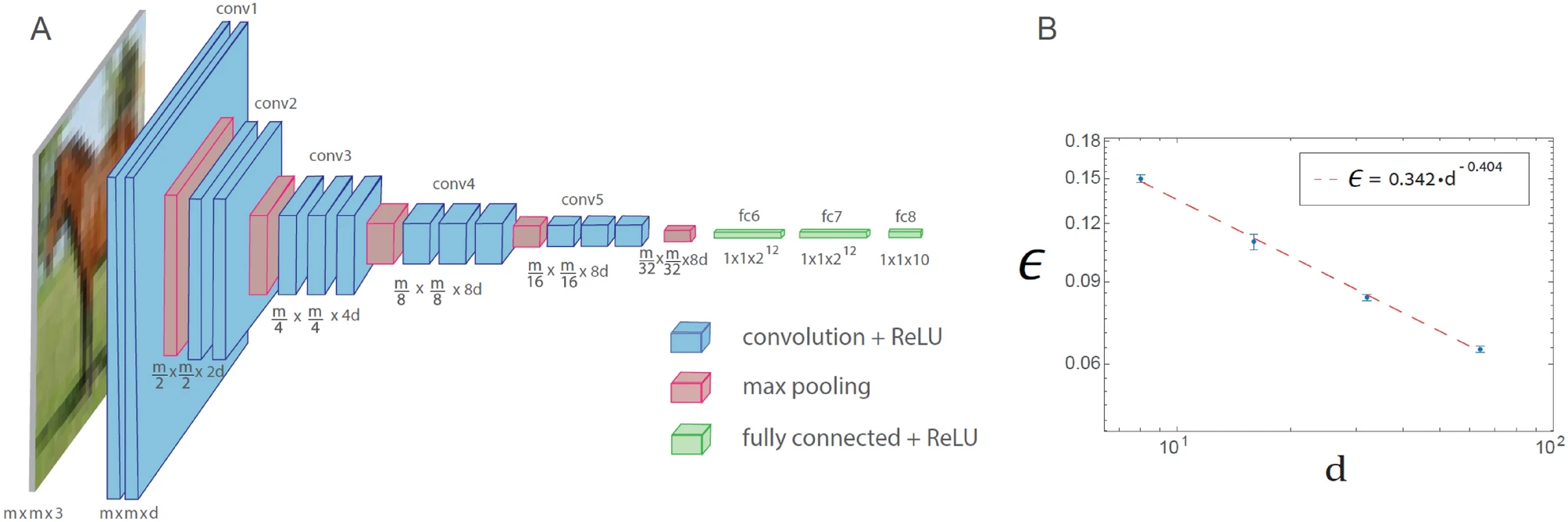
Обучение в обобщенной архитектуре VGG-16 отображено на рисунке ниже. Обобщенная архитектура VGG-16 состоит из 16 слоев, где количество фильтров в n-м наборе сверток равно d х 2n − 1 (n ≤ 4), а квадратный корень от размера фильтра равен m х 2 − (n − 1) (n ≤ 5), где m x m x 3 - размер каждого входа (d = 64 в оригинальной архитектуре VGG-16). График зависимости тестовой ошибки, обозначенной как ϵ, от d на логарифмической шкале, для базы данных CIFAR-10 (m = 32), что указывает на степенную зависимость с показателем степени ρ∼0.4. Функция активации нейронов - ReLU.
Феномен степенного закона охватывает различные обобщенные архитектуры LeNet и VGG-16, что указывает на его универсальное поведение и свидетельствует о количественной иерархической сложности в машинном обучении. Кроме того, обнаружено, что закон сохранения для сверточных слоев, равный квадратному корню от их размера, умноженному на их глубину, асимптотически минимизирует ошибки. Показанный в данном исследовании эффективный подход к поверхностному обучению требует дальнейшего количественного изучения с использованием различных баз данных и архитектур, а также его ускоренной реализации при помощи будущих специализированных аппаратных разработок.