
Прорыв NVIDIA в создании синтетических данных для искусственного интеллекта
Компания NVIDIA представила семейство моделей Nemotron-4 340B, набор мощных моделей с открытым доступом, разработанных для улучшения генерации синтетических данных и обучения больших языковых моделей (LLM). Группа включает три разных модели: Nemotron-4 340B Base, Nemotron-4 340B Instruct и Nemotron-4 340B Reward. Эти модели обещают значительно расширить возможности искусственного интеллекта во многих отраслях, включая здравоохранение, финансы, производство и розничную торговлю.
Главная инновация Nemotron-4 340B заключается в способности модели генерировать высококачественные синтетические данные, являющиеся ключевым компонентом для эффективного обучения LLM. Качественные тренировочные данные зачастую дорогостоящие и их трудно получить, но с помощью Nemotron-4 340B разработчики могут создавать надежные наборы данных в больших масштабах.Фундаментальная модель Nemotron-4 340B Base была обучена на огромном датасете из 9 триллионов токенов и может быть дополнительно доработана с помощью собственных данных. Модель Nemotron-4 340B Instruct генерирует различные синтетические данные, имитирующие реальные сценарии, в то время как модель Nemotron-4 340B Reward обеспечивает качество данных, оценивая ответы на основе полезности, правильности, согласованности, сложности и многословности.
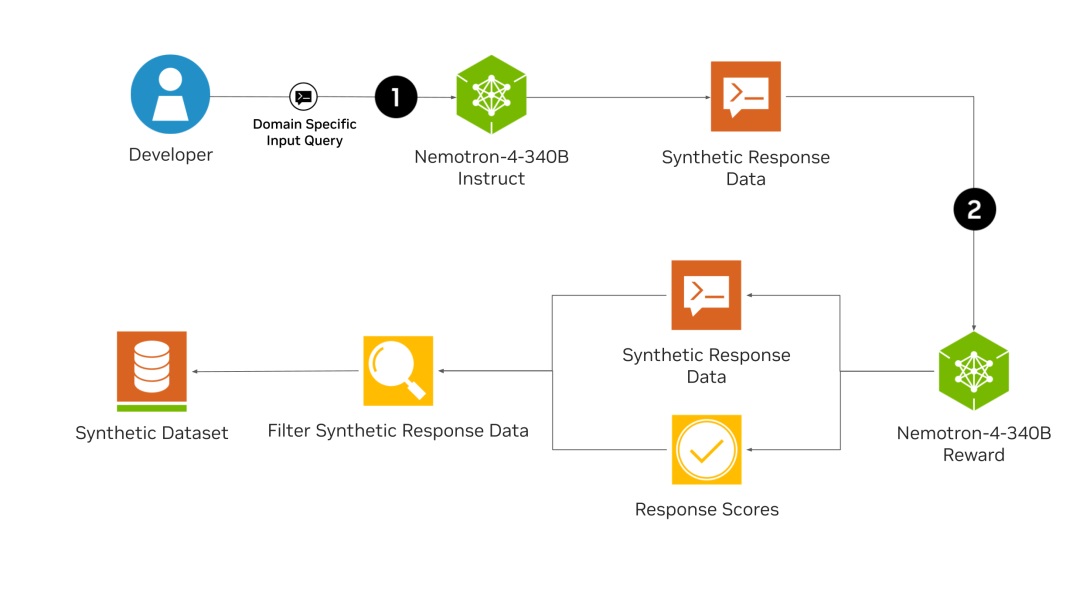
Отличительной особенностью модели Nemotron-4 340B является ее сложный процесс согласования, использующий как прямую оптимизацию преимуществ (direct preference optimization, DPO), так и оптимизацию преимуществ с учетом вознаграждения (reward-aware preference optimization, RPO) для точной настройки моделей. DPO оптимизирует ответы модели, максимизируя разницу в вознаграждении между желаемыми и нежелательными ответами, тогда как RPO дополнительно уточняет это, учитывая разницу в вознаграждении между ответами. Этот двойной подход гарантирует, что модели не только создают высококачественные результаты, но и сохраняют баланс между разными показателями оценки.
NVIDIA применила процесс поэтапной контролируемой тонкой настройки (staged supervised fine-tuning, SFT) для улучшения возможностей модели. Первый этап Code SFT сосредотачивается на совершенствовании способностей кодирования и логического мышления с помощью синтетических данных кодирования, сгенерированных с помощью Genetic Instruct – метода, который моделирует эволюционные процессы для создания высококачественных образцов. Следующий этап General SFT подразумевает обучение на различных наборах данных, чтобы убедиться, что модель хорошо работает в широком диапазоне задач, сохраняя при этом свои навыки кодирования.
Модели Nemotron-4 340B выигрывают от итеративного процесса согласования от слабого к сильному, который непрерывно совершенствует модели с помощью последовательных циклов генерации данных и тонкой настройки. Начиная с первоначальной согласованной модели, каждая итерация генерирует данные более высокого качества и более согласованные модели, создавая самоусиливающийся цикл совершенствования. Этот итеративный процесс использует как мощные базовые модели, так и высококачественные наборы данных для повышения общей производительности обучающих моделей.
Практическое применение моделей Nemotron-4 340B очень многообразно. Благодаря генерированию синтетических данных и усовершенствованию согласования моделей эти инструменты могут значительно повысить точность и надежность систем ИИ в различных отраслях. Разработчики могут легко получить доступ к этим моделям на NVIDIA NGC, Hugging Face, и в будущем через платформу ai.nvidia.com.