Эмбеддинг стохастического кластера – новый метод визуализации больших наборов данных
Удивительная способность человеческого мозга - умение находить различия даже в огромном количестве визуальной информации. При изучении больших массивов данных эта способность оказывается весьма полезной, ведь содержание данных необходимо сжать в форму, понятную человеческому интеллекту. Для визуальной аналитики проблема уменьшения размерности остается основной.
Ученые из Университета Аалто и Хельсинкского университета в Финском центре искусственного интеллекта (FCAI) провели исследование, где они проверили функциональность самых известных методов визуальной аналитики и обнаружили, что ни один из них не работает, когда объем данных значительно возрастает. Например, методы t-SNE, LargeViz и UMAP больше не могли различать чрезвычайно сильные сигналы группировок наблюдений в данных, когда число наблюдений стало исчисляться сотнями тысяч. Методы t-SNE, LargeViz и UMAP уже не работают должным образом.
Исследователи разработали новый метод нелинейного уменьшения размерности под названием Stochastic Cluster Embedding (SCE) для лучшей визуализации кластера. Он направлен на максимально четкую визуализацию наборов данных и призван изобразить кластеры данных и другие макроскопические признаки так, чтобы они были максимально отчетливы, легко наблюдаемые и понятные человеку. SCE использует графическое ускорение аналогично современным методам искусственного интеллекта для вычислений в нейронных сетях.
Основой для изобретения этого алгоритма стало открытие бозона Хиггса. Набор данных для экспериментов, связанных с ним, содержит более 11 миллионов векторов признаков. И эти данные требовали удобной, наглядной визуализации. Что и вдохновило ученных на разработку нового метода.
Исследователи обобщили SNE, используя семейство I-дивергенций, параметризованных масштабным коэффициентом s, между не нормализованными сходствами во входном и выходном пространстве. SNE является особым случаем в семействе, где s выбрано в качестве нормализующего фактора сходства выходов. Однако в ходе тестирования было обнаружено, что наилучшее значение s для визуализации кластера часто отличается от значения, выбранного SNE. Поэтому, чтобы преодолеть недостаток t-SNE, новый метод SCE использует другой выбор, который смешивает входные сходства при вычислении s. Коэффициент адаптивно корректируется при оптимизации новой цели обучения, и, таким образом, точки данных лучше сгруппированы. Также исследователями был разработан эффективный алгоритм оптимизации, использующий асинхронный стохастический спуск по блочным координатам. Новый алгоритм может использовать параллельные вычислительные устройства и подходит для мегамасштабных задач с большими объемами данных.
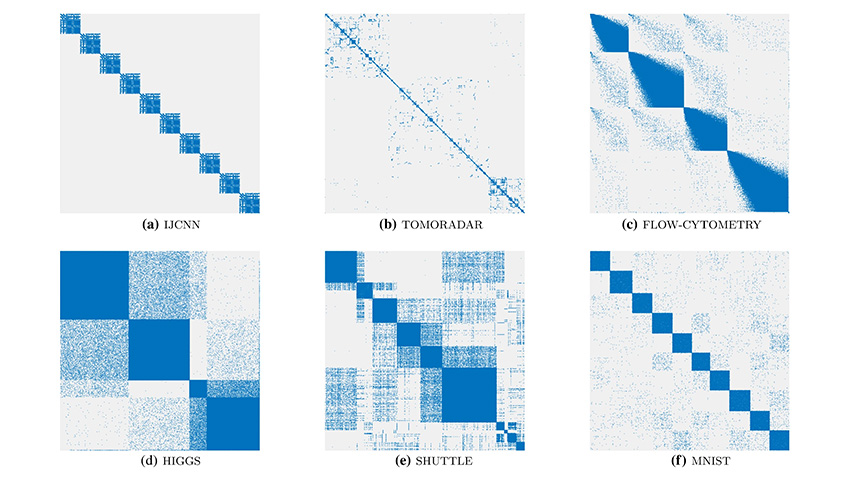
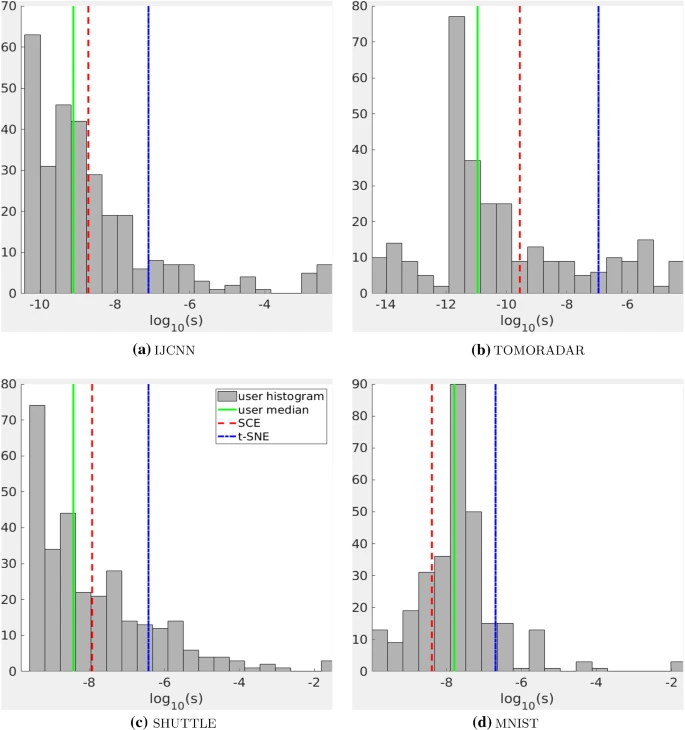
В ходе разработки проекта ученые протестировали метод на различных наборах реальных данных и сравнили его с другими современными методами NLDR. Пользователи, участвующие в тестировании, выбирали наиболее подходящие визуализации, которые соответствуют диапазону значений s для просмотра кластеров. Затем исследователи сравнивали полученные значения s в SCE и t-SNE, чтобы увидеть, что ближе к человеческому выбору. Для тестирования использовались четыре самых маленьких набора данных IJCNN, TOMORADAR, SHUTTLE и MNIST. Для каждого набора данных участникам тестирования предоставлялась серия визуализаций, где они использовали ползунок для указания значения s и проверяли соответствующую предварительно вычисленную визуализацию. Пользователь выбирал предпочтительное значение s для визуализации кластера.
В результатах тестирования наглядно видно, что s, выбранное SNE, находится справа от медианы человека (сплошная зеленая линия) для всех наборов данных. Это говорит о том, что для человека GSNE с меньшим s часто лучше, чем t-SNE для визуализации кластера. В то же время, выбор SCE (красные пунктирные линии) ближе к медиане человека для всех четырех наборов данных.
При применении метода Stochastic Cluster Embedding к данным о бозонах Хиггса были четко выделены их наиболее важные физические характеристики. Новый метод нелинейного уменьшения размерности Stochastic Clustering Embedding для лучшей визуализации кластера работает на несколько порядков быстрее, чем предыдущие методы, а также намного надежнее в сложных приложениях. Он модифицирует t-SNE, используя адаптивный и эффективный компромисс между притяжением и отталкиванием. Экспериментальные результаты показали, что метод может последовательно идентифицировать внутренние кластеры. Кроме того, учеными был предоставлен простой и быстрый алгоритм оптимизации, который можно легко реализовать на современных платформах параллельных вычислений. Разработано эффективное программное обеспечение, использующее асинхронный стохастический блочный градиентный спуск для оптимизации нового семейства целевых функций. Экспериментальные результаты показали, что метод последовательно и существенно улучшает визуализацию кластеров данных по сравнению с современными подходами стохастического эмбеддинга соседей (Neighbor Embedding).
Код метода находится в открытом доступе на github.