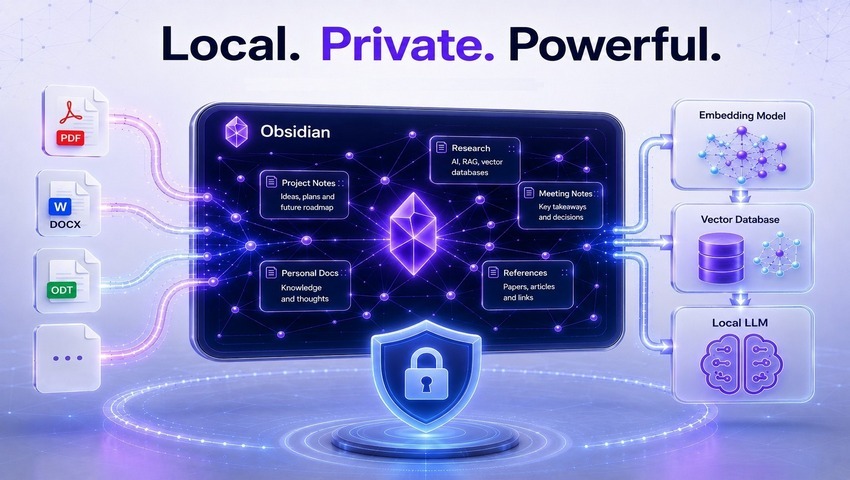
Is it possible to use the full power of modern LLMs while keeping all your data 100% private? Discover how to build a local RAG system with Obsidian, choose the right tools and architectures, integrate PDF, DOCX, and other document formats, and create a powerful AI assistant that runs entirely on your own computer.
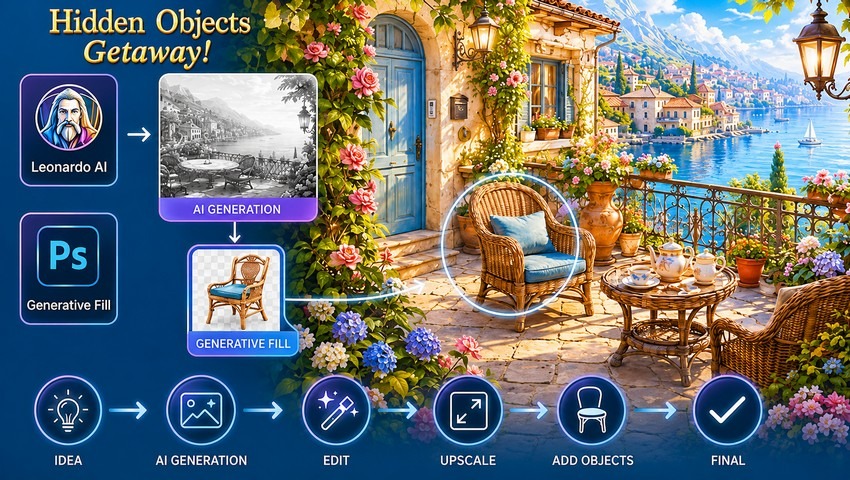
What does it actually take to bring generative AI into real game production? In this article, we break down how to use Leonardo AI and Photoshop Generative Fill to create hidden-object game locations – revealing the unexpected workflow tricks, generation failures, and AI limitations we encountered along the way.
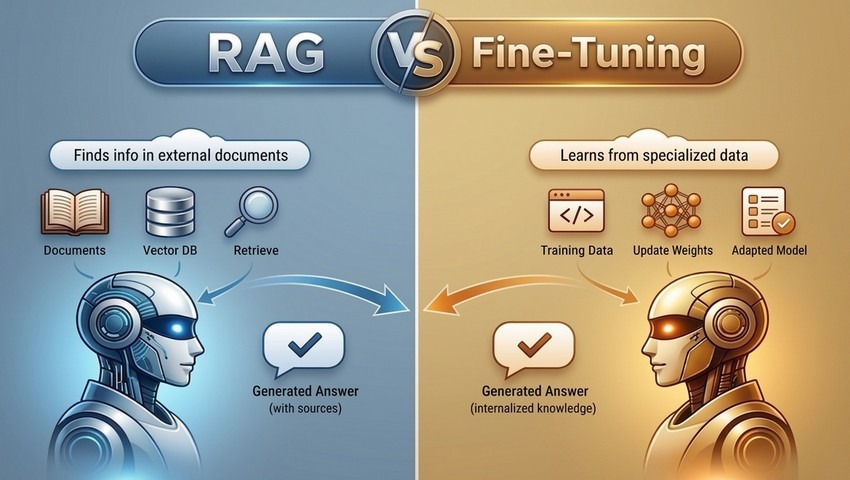
RAG and fine-tuning aren’t competing approaches – they solve fundamentally different problems: one gives models access to fresh, external knowledge, while the other reshapes how they think. The real power comes from knowing when to use each – and how combining them can unlock faster, smarter, and more reliable AI systems.

AI agents aren’t assistants anymore – they’re autonomous teams that plan, reason, collaborate, and execute entire workflows with almost no human help. Discover why multi-agent swarms and local agents are quietly becoming the strategic core of the most powerful companies and industry leaders.

Where do neural networks truly accelerate production, and where does real creative magic begin? Drawing on real art studio experience, this article reveals how AI can be used to rapidly generate concepts, characters, and backgrounds – and when a skilled artist’s hand remains essential for achieving high-quality results.

AI is no longer working behind the scenes in games! It is actively shaping how worlds are built, how characters think, and how players experience every moment of gameplay. In this article, we dive into why AI is no longer a competitive advantage but a core requirement for studios that want to build scalable, immersive, and future-proof games.

Step inside the making of Guess Mess – a casual game born from AI’s quirky and unpredictable imagination. Discover how we harnessed ChatGPT’s chaotic creativity to design 1,000 unique levels and transformed its “mistakes” into a bold visual identity.

LangGraph transforms chatbot development by replacing LangChain’s linear chains with a flexible, state-based graph system that supports branching, loops, and Human-In-The-Loop interactions. Paired with FastAPI, it powers scalable chatbot microservices that handle complex dialogues with full context.

As AI systems evolve beyond simple pattern recognition, reasoning models are unlocking the ability to think, adapt, and make sense of complex, ambiguous situations. From probabilistic logic to agentic AI and interactive dialogue, these models mark a shift toward truly intelligent systems.

AI hallucinations – instances where AI generates false or misleading content while presenting it as factual – are becoming more frequent, even in the most advanced models like GPT or Gemini. Let’s explore why these errors happen, their real-world risks, and how developers and users can reduce them.

RAG empowers AI systems to deliver accurate, dynamic responses by tapping into up-to-date external knowledge bases. Let’s explore RAG’s architecture, practical applications, and key benefits, including enhanced transparency, data reliability, and source traceability.


Ideogram 2.0 is the latest AI-powered image generator with a variety of styles: realistic, design, 3D, and anime, each tailored for unique creative visions. Watch this video and discover how the model’s features and settings can fine-tune text prompts and create stunning, high-quality images in just a few clicks.

From the powerful A18 Bionic Neural Engine to enhanced privacy with on-device ML processing – explore the top 6 AI and machine learning innovations from Apple's 2024 presentation. Discover how these advancements are shaping the future of Apple devices.

It’s time to discover Leonardo AI’s Style Reference feature. In just 1 minute you will learn how to effortlessly match any art style you want using this powerful, free image generator. All you need is to provide the reference image and Leonardo AI will do the rest.

In this video we're going to explore the Image to Motion feature. This tool can easily turn your static images into dynamic, eye-catching animations with just a few clicks! Our step by step 1 minute tutorial will help you bring your photos to life and add some magic to any picture.