
Effective methods for solving text problems using LLM, llama.cpp and guidance
In recent years, neural models using machine learning have become a large part of various domains of human activity. One of the most growing areas in this context has been the use of language models such as LLM (Large Language Models). These models, which incorporate modern advances in language processing, have the potential to solve a variety of problems in a wide range of domains. From text analysis, summarization and automatic translation to content generation and data management, LLM models have proven to be extremely useful tools for solving complex problems in the modern world.
Automated text processing is one of those tasks in which the human factor plays a crucial role - the same sentence written by different people can be either simple and engaging or deliberately overloaded and complex. In this article, we will analyze how such a problem can be solved and, without spending significant resources, work with texts at an acceptable speed using AI models, processing them automatically.
The list of problems that can be solved using large language models and the right instructions can be quite long. These include any tasks of summarizing a text, extracting entities from the text, paraphrasing the text from one style to another, or "smartly" adding keywords to the text.
Modern linguistic models and LLM
Instruct LLM is a fairly recent development in the field of natural language processing. This is a range of models built on Transformer blocks that perceive text as "tokens", with words or their particles, and have the unique ability to understand the complex relationships between words in sentences. It allows them to process text more intelligently. The model itself is engaged in predicting the next token from its dictionary, and determines the probabilities of all words in the dictionary as the next token, and then selects a token with a probability based on sampling.
With this functionality, Instruct LLM can effectively paraphrase a text with additional guidance and context from a specific example, making the text itself feel more natural. A fairly big disadvantage that such a wide functionality of LLM models leads to is the size. The typical size of such models that have good processing quality and "understanding" of texts is 7-14 billion parameters in float16 format (2 bytes of memory). It means that to use such a model with a size of, for example, 7 billion parameters it is necessary:
2 (bytes) * 7 000 000 000 (parameters) / 1024 (KB) / 1024 (MB) / 1024 (GB) ≈ 13.04 GB
So, 13.04 gigabytes of memory is needed for the model when it is running, and for significant speed, this memory on the video card (VRAM) is quite a lot. Using such models leads to high hardware costs, but a tool such as quantization can solve this problem.
The model itself that will be used for this task is called Mistral-7B-Instruct by Mistral.AI. It is a model with instructions (trained using RLHF to follow user instructions) with 7 billion parameters. After using all the tools, such a model will occupy ≈4.5GB of regular RAM memory when running, and also have a speed of approximately 1.2 tokens per second when used on a mid-priced processor.
Model quantization
As we've already noted, one of the biggest challenges when working with large language models is that they require significant computational resources. To solve this problem, we use quantization, a process of compressing a model by reducing the number of bits needed to represent each parameter. Since float16 is usually the standard parameter format for LLM models with a fractional part, the memory footprint of its use can be reduced by using a data type with a smaller size and only an integer part - for example, an 8-bit Integer, which when used with a sign will result in possible values from -127 to 127. In general, this quantization method looks like this:
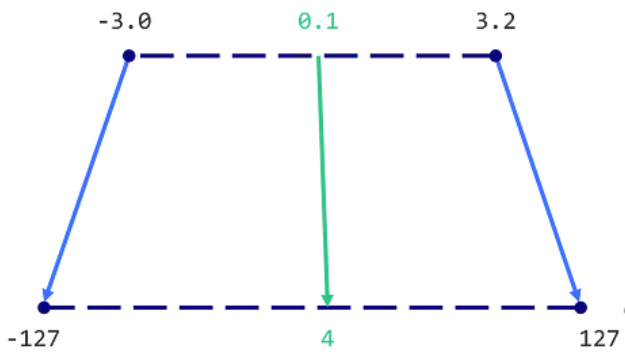
From the image you can see that the values will be scaled to the new format. It will reduce the amount of memory the model takes up without reducing its efficiency and quality radically. To quantize our Mistral-7b-Instruct model, we use llama.cpp, an open source library for using machine learning models efficiently. Thanks to llama.cpp we can quantize our model while maintaining its accuracy and efficiency.
The principle of its operation is different - an importance matrix is used for quantization. The essence of the importance matrix is to obtain gradients of parameter weights over a model run on a given set of training tokens. When the weight gradient of a given model is large, this means that a large change in the model parameter weight, a change in the parameter during quantization, will lead to a small change in model performance. And vice versa, a large gradient implies a large change in model performance from a small change in the model parameter weight. Gradient squares can be used as an importance matrix, or based on this matrix, and a more "smart" quantization occurs. This algorithm allowed us to reduce the Mistral-7B-Instruct model from 13GB to approximately 4.5GB, while maintaining speed and quality. An important aspect is the assessment of the deterioration of the model after such quantization; you can intuitively see it here:
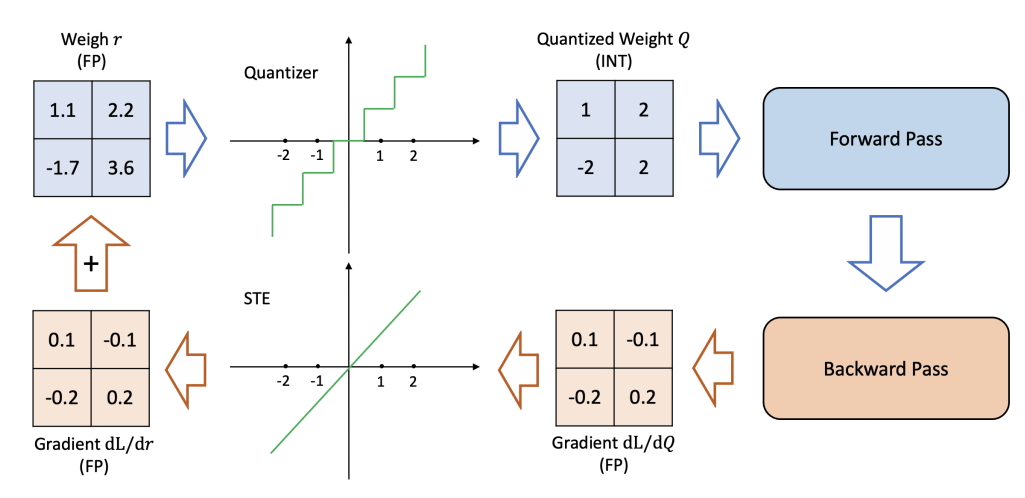
Since there are fewer values in the parameters, the quality of the model decreases. For large language models, this quality is calculated using Perplexity, a metric that calculates the change in the probability of the next correct token on a data prediction. This can be seen schematically in the following figure:

In this example, we can calculate the probability of the word "going" in the quantized or non-quantized model against the most likely token in the generation, thus calculating the difference in probability, which is the Perplexity indicator. In solving this problem, we use the smallest model after quantization, and although it has the highest Perplexity index, a change from its original probability, this is enough for the problem under consideration. The table with Perplexity indicators for Mistral-7B-Instruct is shown below:
| Quant Type | Float16 | Q2_K | Q3_K | Q4_K | Q5_K | Q6_K |
| perplexity | 5.9066 | 6.7764 | 6.1503 | 5.9601 | 5.9208 | 5.9110 |
Model source data format
LLM models also differ from others in that, having a wide range of tasks that they can solve, they format the output in an arbitrary way, i.e. in problems of a particular type, text2text can add explanations, additional notes and other structures that may interfere with the automatic selection of model results. This behavior can be corrected using instructions to the model when requesting a prompt, but on small models this does not always work; the model may "not obey" the prompt. To solve this problem, you can use the guidance library. It allows you to use a wide range of different LLM models with model output formatting, which allows you to more accurately control the generation. For example, you can limit generation to "stop at newline generation" conditions, or allow the model to provide only a certain list of tokens. Example:

In this example, we can see that we specified the word "Answer" in the answer in advance, so the model immediately began generating the data we needed, and did not get hung up on the instructional markup of this data. When formatting the output of our task, we can specify the words “Summarized result text:” or similar in the generation, and generate short texts only on a new line. It will eliminate the main problems with formatting and help generate more natural and high-quality texts. However, this is only a small part of everything that can be implemented using guidance. Here's an example of using "select" to give the model only a certain range of values that it can select. This will help generate only the required entities based on the context of the request.

Another complex example of such generations, which allows you to create entire structures based on guidance functions, is given below:
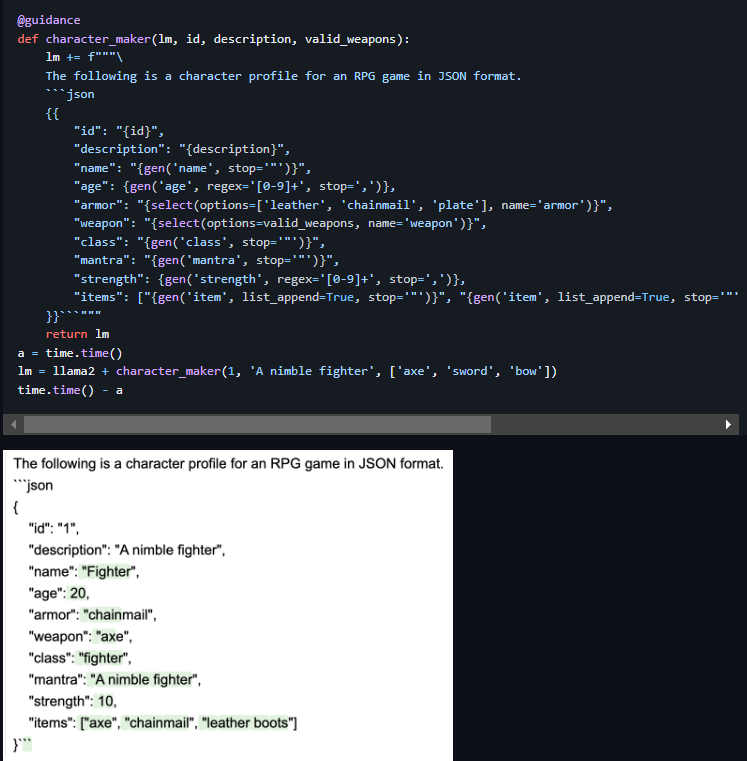
As we can see, when we started generating a "Fighter" character for the RPG game, the model continued to respect the context of this character, setting realistic parameters for the character, and even generated his things correctly. Accordingly, in such constructions you can use both regular expressions, for example for age, as shown in the example, and “for” loops to generate the required number of things. Or, for example, ask the model to generate the number of things a character has as a number using a regular expression, and then, having received this number, use it in a loop to generate a dynamic number of items. And this is not all the possibilities for controlling generation, so using this library can solve many problems in text processing tasks.
The developed system optimizes various applied tasks related to working with text by incorporating automatic analysis and processing based on large language models. This significantly reduces the time spent on routine tasks and effectively addresses applied problems.
Nikolai Andriushchenko, ML engineer
Resources:
1. Mistral-7B-Instruct
2. Llama.cpp
3. Guidance
4. ChatGPT and Instruct models insights