Google has launched Gemini 3.5 Live Translate, an advanced AI model that delivers near instant, continuous voice translation across more than 70 languages. Unlike traditional tools, it translates speech as it’s spoken, enabling fluid conversations while preserving the speaker’s natural tone, pitch, and pacing.

AI learnt to decode dog barks, identifying playful versus aggressive barks, as well as the dog’s age, sex, and breed. Originally trained on human speech, AI models have achieved impressive accuracy, offering significant advancements in animal care and communication research.

During the Spring Update event OpenAI’s presented GPT-4о – the unique omnimodel that integrates text, audio and image processing, allowing it to work faster and more efficiently than ever before.
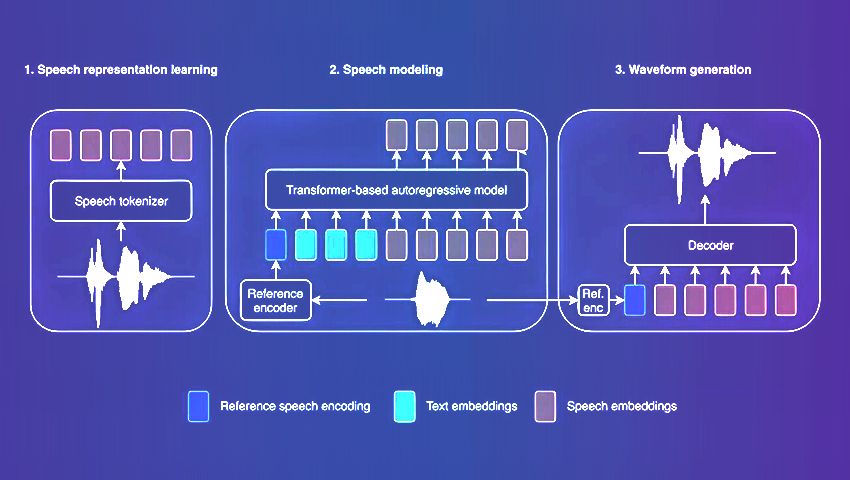
Amazon's latest TTS model with its innovative architecture sets a new benchmark for speech synthesis. BASE TTS not only achieves unparalleled speech naturalness but also demonstrates remarkable adaptability in handling diverse language attributes and nuances.

SeamlessM4T breaks down language barriers with its comprehensive translation and transcription capabilities, This AI model can easily convert speech or text, enabling real-time translation, and fostering cross-cultural understanding.
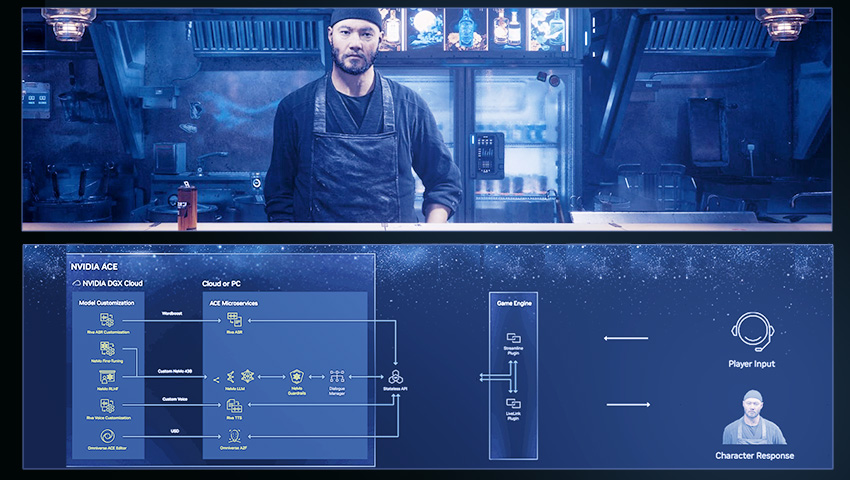
Generative AI is revolutionizing the world of gaming by transforming virtual characters and enhancing their conversational skills. The NVIDIA Avatar Cloud Engine (ACE) for Games empowers developers to infuse intelligence into NPCs, reshaping gaming experiences and pushing the boundaries of what is possible.

Text-to-speech models usually require significantly longer training samples, while VALL-E creates a much more natural-sounding synthetic voice from just a few seconds.

MIT researchers have developed a machine-learning technique that precisely collects and models the underlying acoustics of a location from just a limited number of sound recordings.
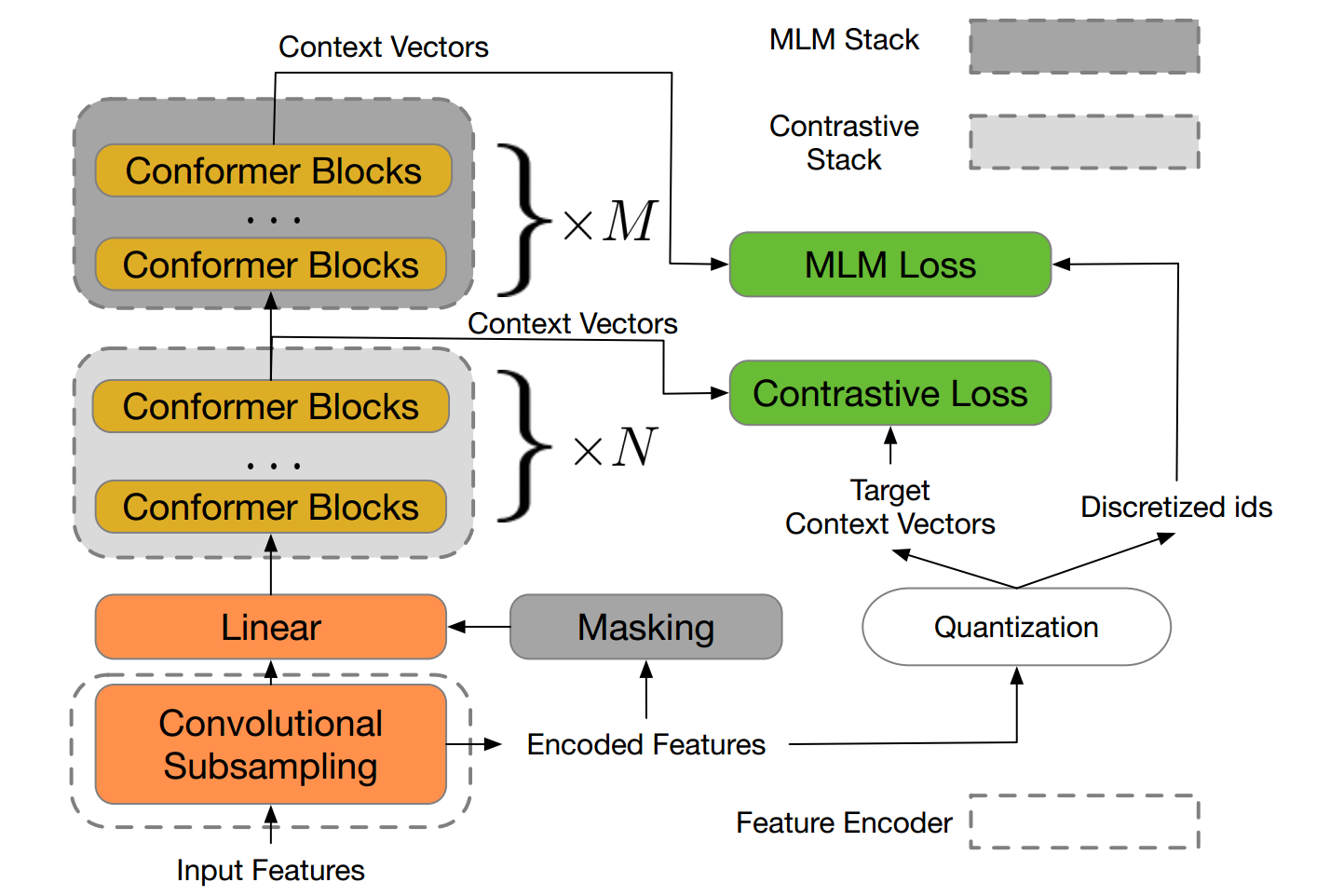
Motivated by the success of masked language modeling (MLM) in pre-training natural language processing models, the developers propose w2v-BERT that explores MLM for self-supervised speech representation learning.