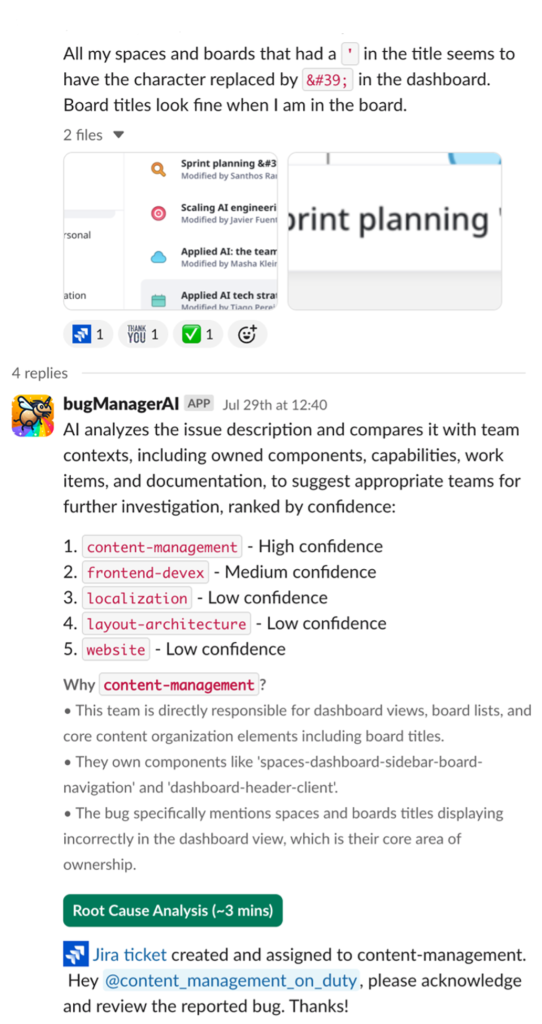
Miro partners with AWS to develop BugManager, an AI-powered solution for automated bug triaging, reducing reassignments and time-to-resolution. BugManager uses optimized prompts and Retrieval Augmented Generation (RAG) for higher accuracy in bug...

Caroline Uhler discusses the data revolution in biology and the potential for machine learning to unlock new understanding of biological systems. Advances like DNA sequencing and vision models are shaping a new era in biology, inspiring innovative ML...
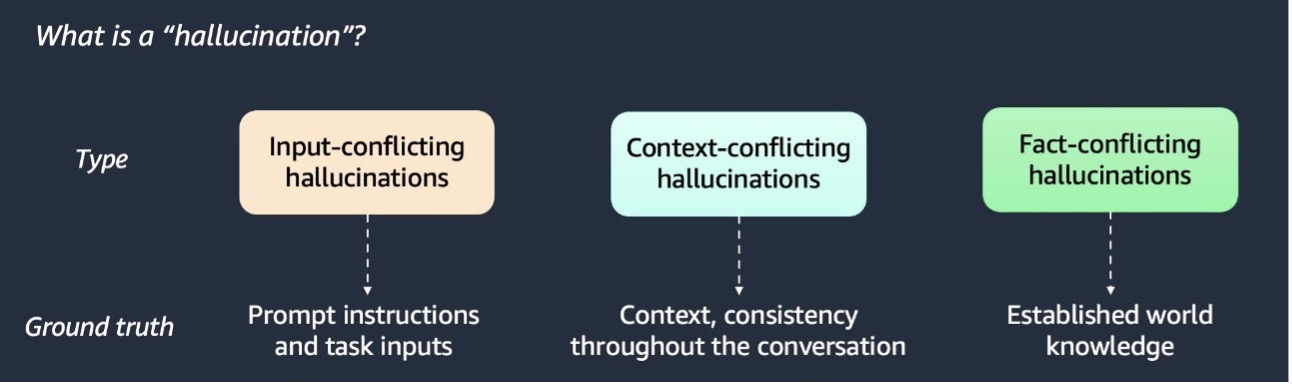
RAG enhances AI responses by incorporating additional data. Detecting and mitigating AI hallucinations is crucial for...

BERTopic, a python library for transformer-based topic modeling, uses 6 core modules to process financial news faster and reveal changing trending topics over time. It includes embeddings, dimensionality reduction, clustering, vectorizers, c-TF-IDF, and representation models for identifying key terms in...
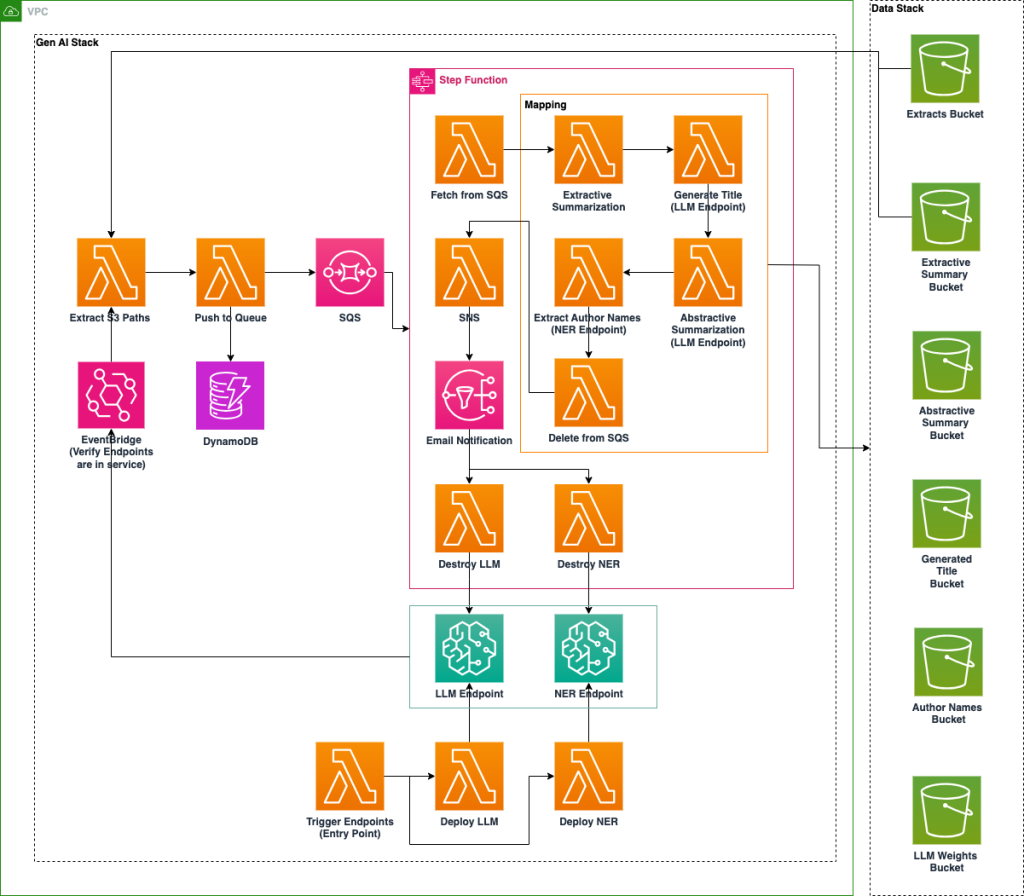
A U.S. National Laboratory implements AI platform on Amazon SageMaker to enhance accessibility of archival data through NER and LLM technologies. The cost-optimized system automates metadata enrichment, document classification, and summarization for improved document organization and...
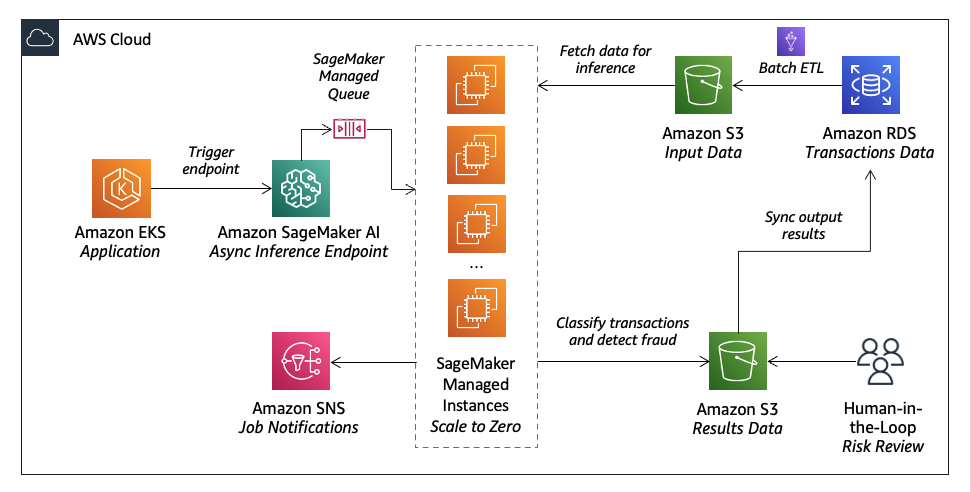
Lumi, an Australian fintech lender, uses Amazon SageMaker AI to provide fast loan decisions with accurate credit assessments. They combine machine learning with human judgment for efficient and accurate risk...

Multimodal embeddings merge text and image data into a single model, enabling cross-modal applications like image captioning and content moderation. CLIP aligns text and image representations for 0-shot image classification, showcasing the power of shared embedding...
ML metamorphosis, a process chaining different models together, can significantly improve model quality beyond traditional training methods. Knowledge distillation transfers knowledge from a large model to a smaller, more efficient one, resulting in faster and lighter models with improved...
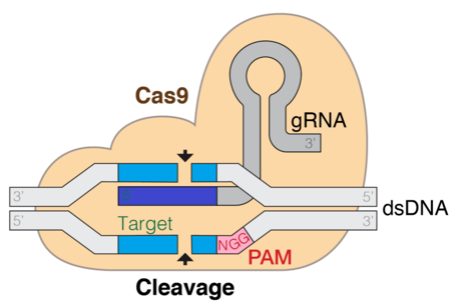
CRISPR technology is transforming gene editing by using computational biology to predict gRNA efficiency with large language models like DNABERT. Parameter-Efficient Fine-Tuning methods, such as LoRA, are key in optimizing LLMs for molecular biology...
Meta and Waymo introduce Transfusion model combining transformer and diffusion for multi-modal prediction. Transfusion model uses bi-directional transformer attention for image tokens and pre-training tasks for text and...
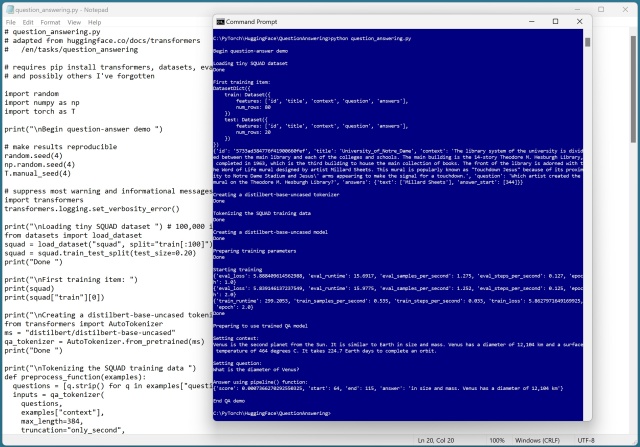
HuggingFace offers a vast library of pretrained language and image models for natural language tasks. Despite some errors, the QA system showcases the simplicity and effectiveness of using the pipeline...
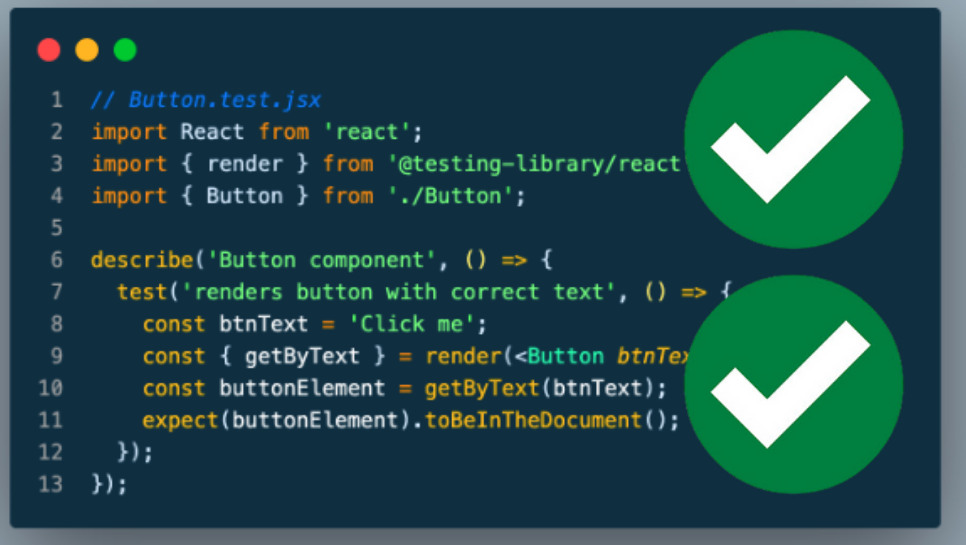
Learn how to test machine learning projects with Pytest and Pytest-cov. Guide focuses on BERT for text classification using industry standard...

Name entity recognition (NER) extracts entities from text, traditionally requiring fine-tuning. New large language models enable zero-shot NER, like Amazon Bedrock's LLMs, revolutionizing entity...
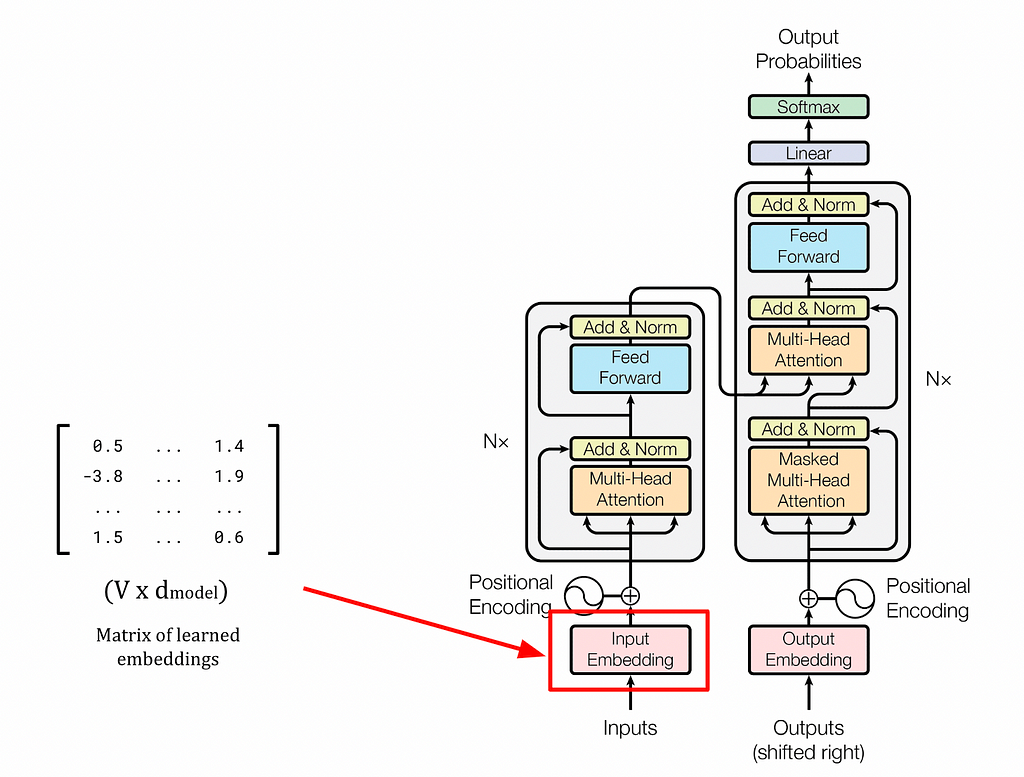
Large language models like GPT and BERT rely on the Transformer architecture and self-attention mechanism to create contextually rich embeddings, revolutionizing NLP. Static embeddings like word2vec fall short in capturing contextual information, highlighting the importance of dynamic embeddings in language...
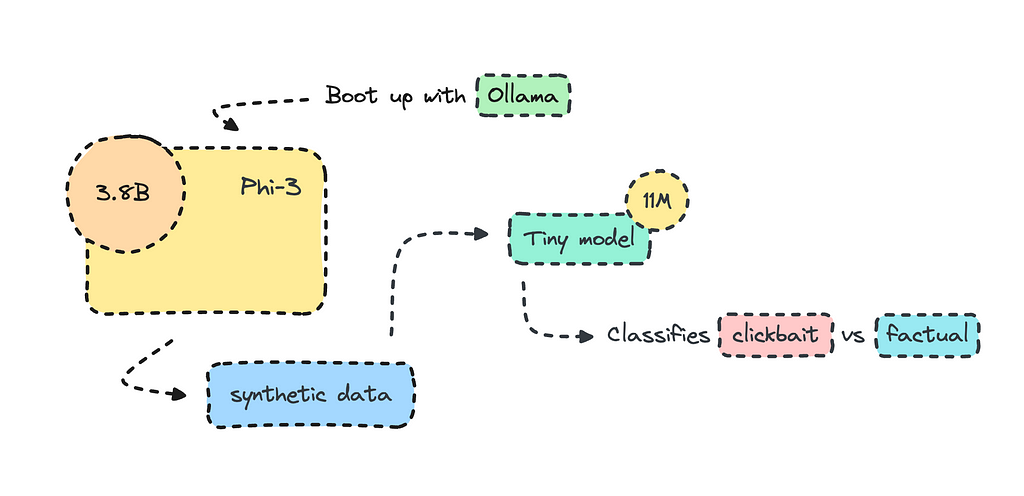
Microsoft’s Phi-3 creates smaller, optimized text classification models, outperforming larger models like GPT-3. Synthetic data generation with Phi-3 via Ollama improves AI workflows for specific use cases, offering insights into clickbait versus factual content...
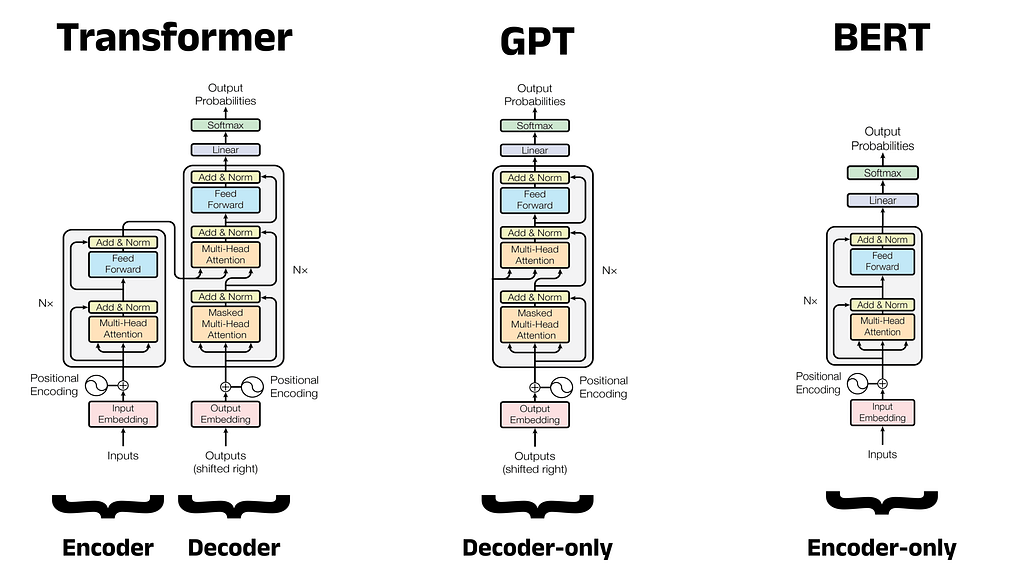
BERT, developed by Google AI Language, is a groundbreaking Large Language Model for Natural Language Processing. Its architecture and focus on Natural Language Understanding have reshaped the NLP landscape, inspiring models like RoBERTa and...
Discover the latest groundbreaking research on AI applications in healthcare. Learn how companies like IBM and Google are revolutionizing patient care with innovative...

The pharmaceutical industry generated $550 billion in US revenue in 2021, with a projected cost of $384 billion for pharmacovigilance activities by 2022. To address the challenges of monitoring adverse events, a machine learning-driven solution using Amazon SageMaker and Hugging Face's BioBERT model is developed, providing automated detection from various data...
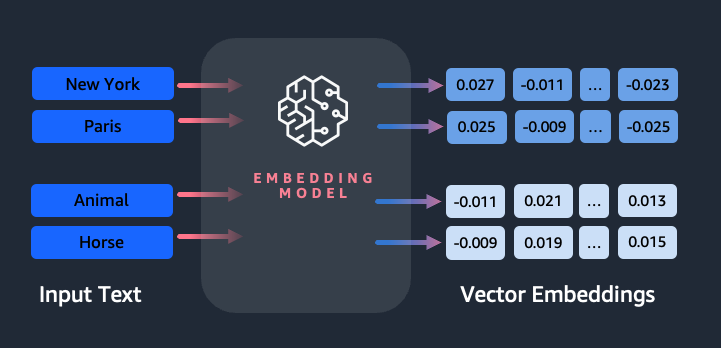
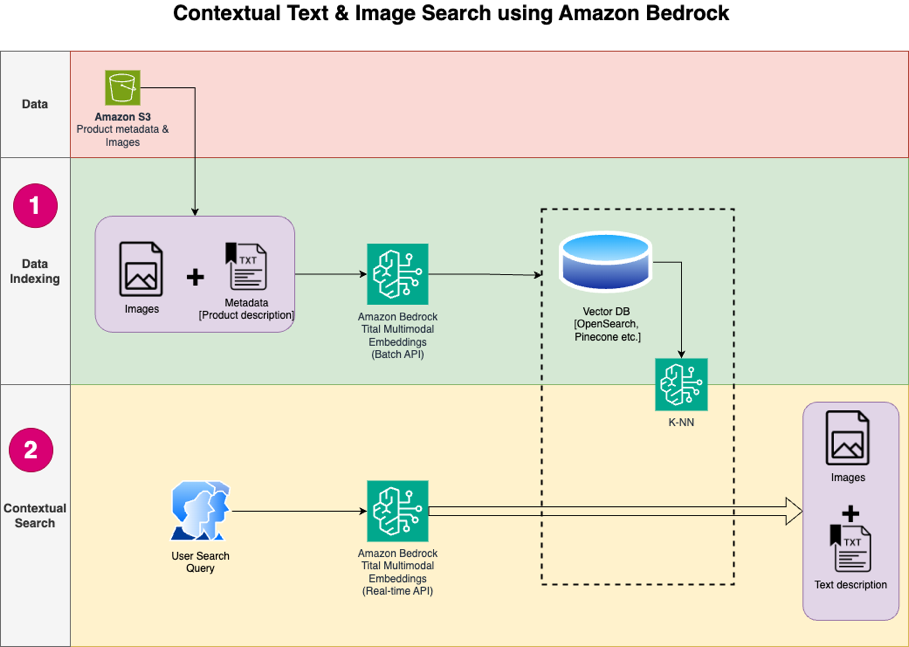
Amazon Titan Text Embeddings is a text embeddings model that converts natural language text into numerical representations for search, personalization, and clustering. It utilizes word embeddings algorithms and large language models to capture semantic relationships and improve downstream NLP...
Google Brain introduced Transformer in 2017, a flexible architecture that outperformed existing deep learning approaches, and is now used in models like BERT and GPT. GPT, a decoder model, uses a language modeling task to generate new sequences, and follows a two-stage framework of pre-training and...
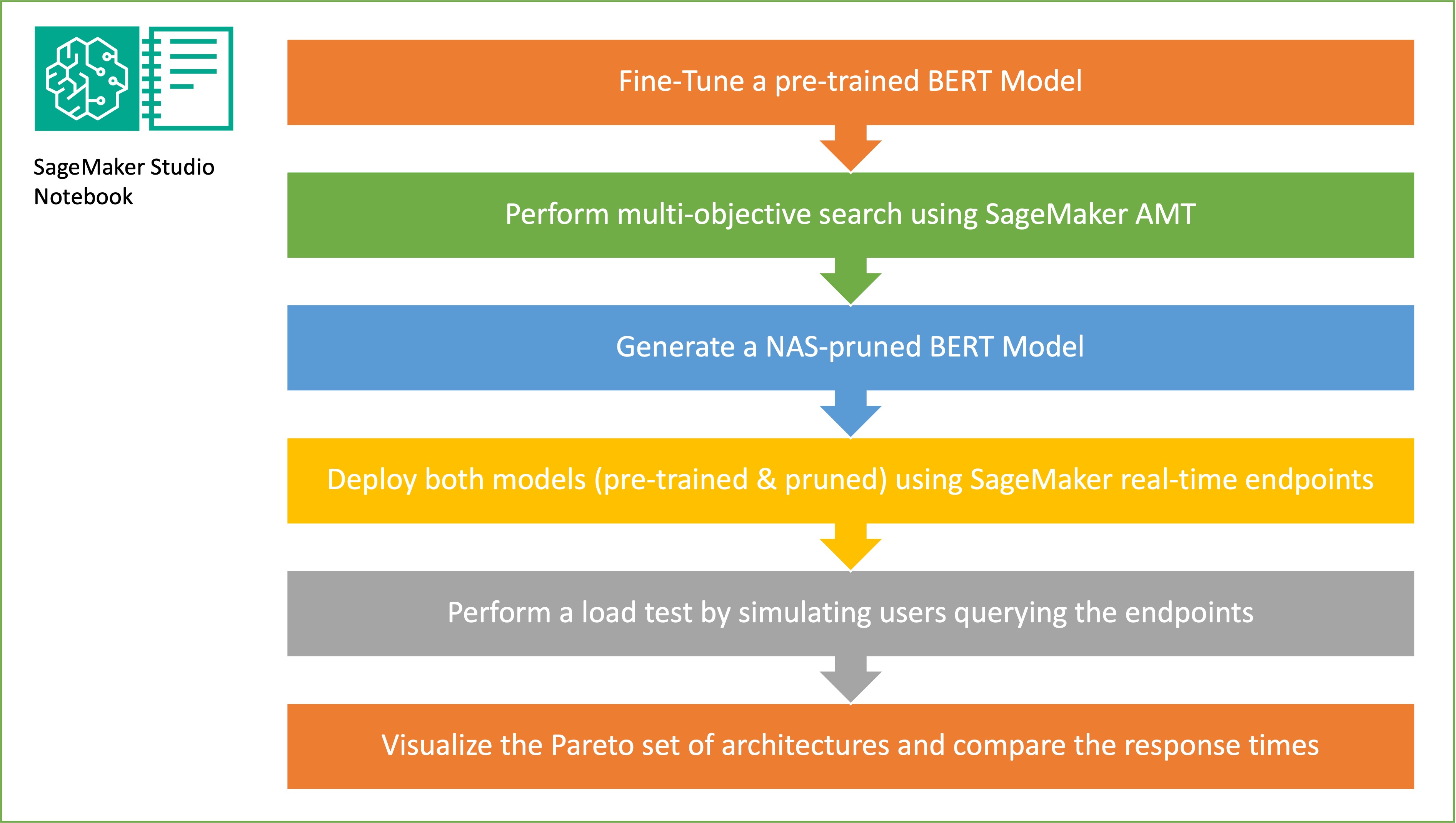
This article demonstrates how neural architecture search can be used to compress a fine-tuned BERT model, improving performance and reducing inference times. By applying structural pruning, the size and complexity of the model can be reduced, resulting in faster response times and improved resource...
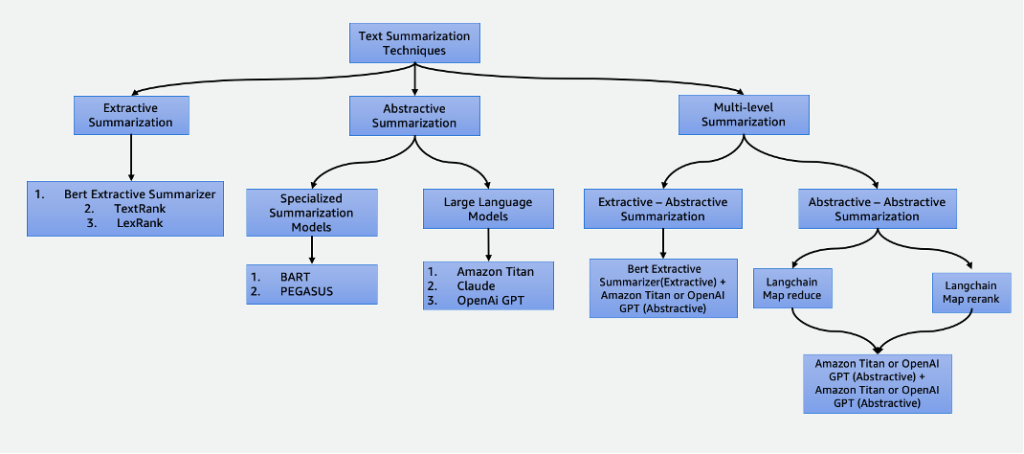
Summarization is essential in our data-driven world, saving time and improving decision-making. It has various applications, including news aggregation, legal document summarization, and financial analysis. With advancements in NLP and AI, techniques like extractive and abstractive summarization are becoming more accessible and...