
MIT's SERC symposium focused on AI's impact on society, featuring talks on air pollution forecasting and ethical AI deployment. Panel discussions highlighted challenges of aligning AI with human values and governance of AI...

Researchers from MIT and the MIT-IBM Computing Research Lab developed ChartNet, a dataset and series of open-source models that outperform commercial AI models in tasks like chart interpretation. This breakthrough could empower small firms with limited budgets to leverage AI for business trend analysis and scientific figure...

Amazon Nova 2 Lite offers a cost-effective object detection solution with no training needed. Easily deploy with Amazon Bedrock, AWS Lambda, and API Gateway for various...
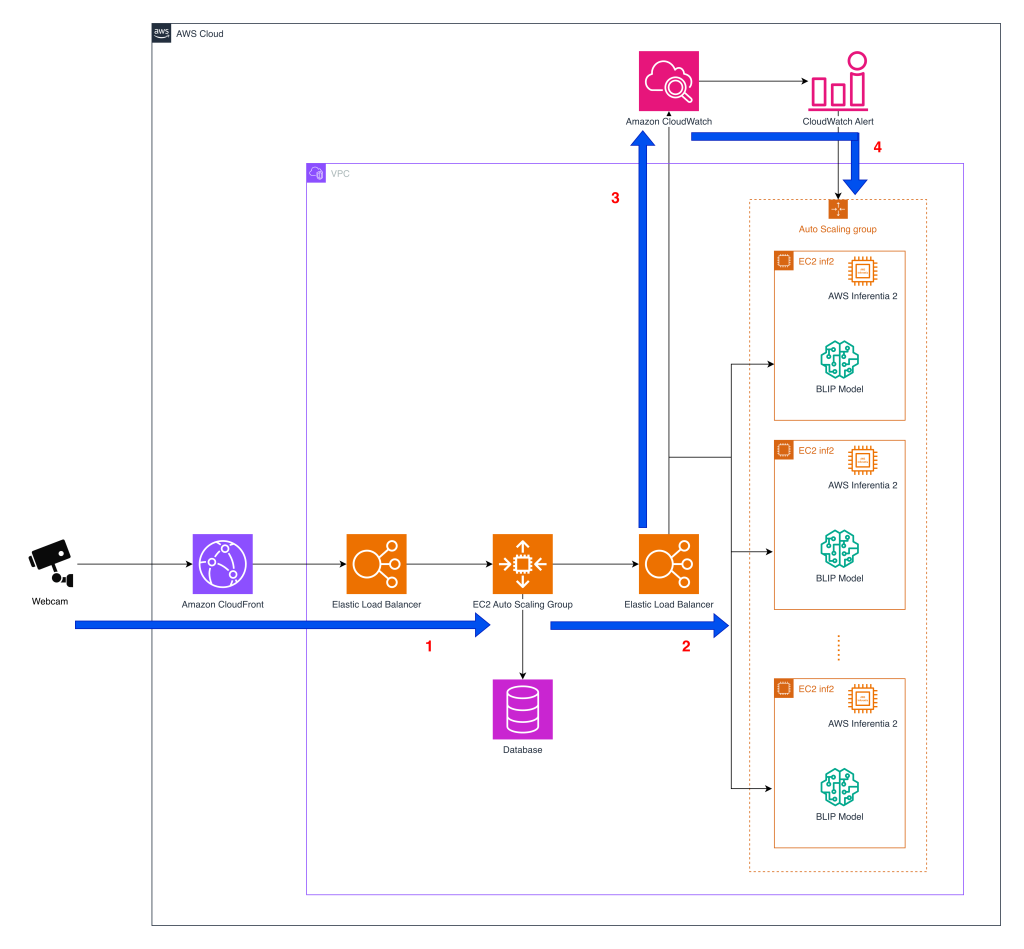
Tomofun's Furbo Pet Camera uses AI to detect pet behaviors, alerting owners in real-time. By switching to AWS Inferentia2, they reduced costs and maintained accuracy for real-time pet activity alerts at...
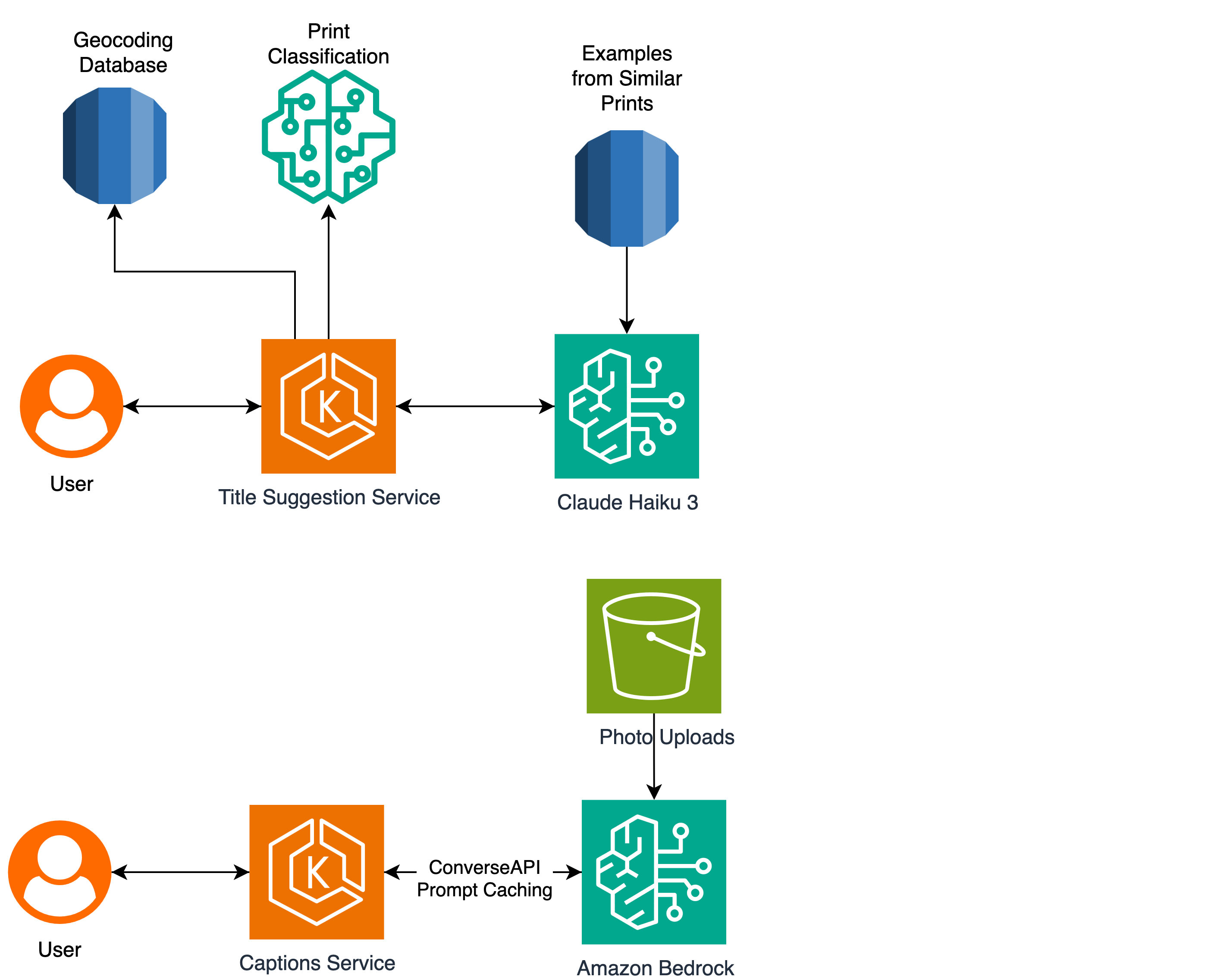
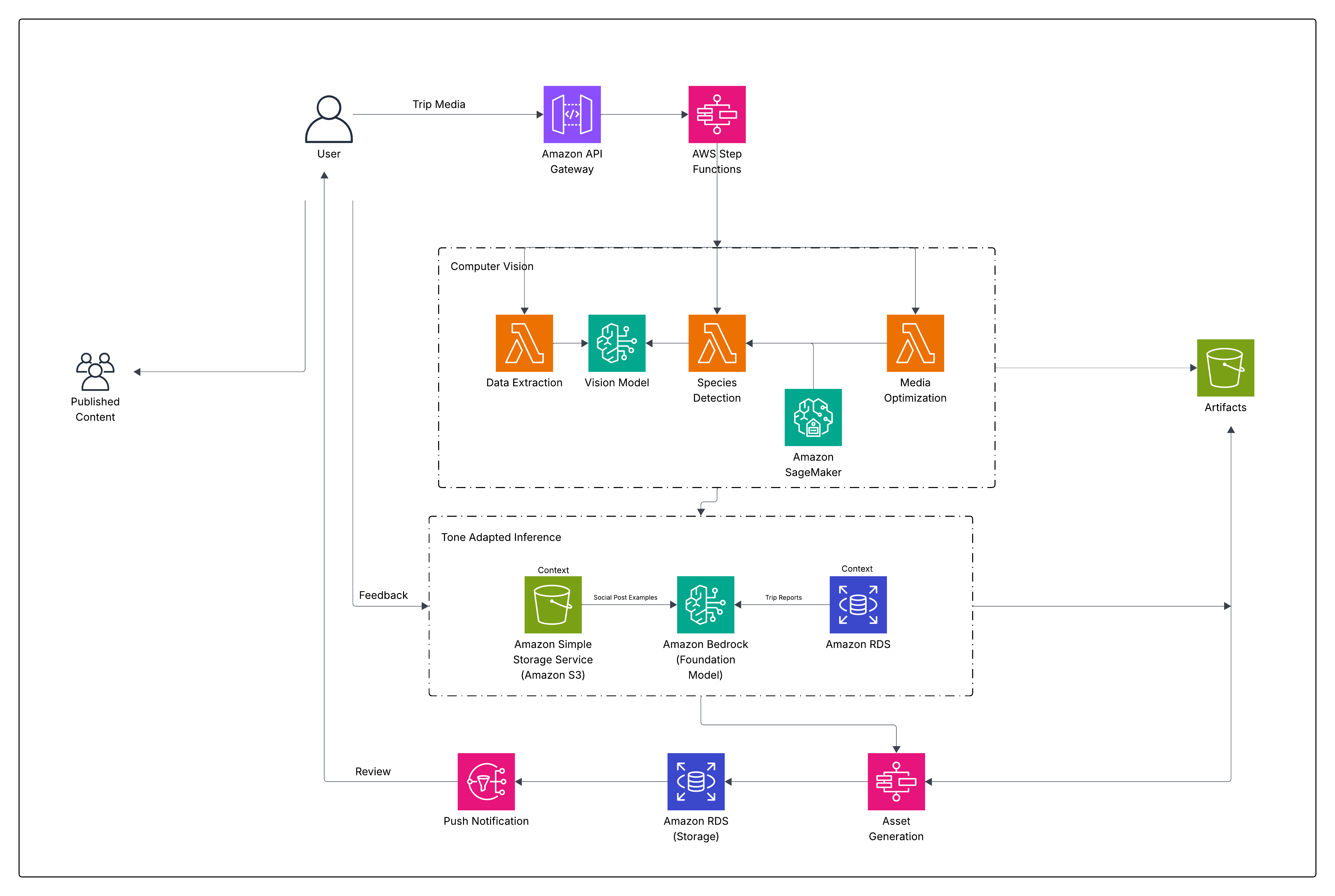
Popsa uses AI and design automation to create personalized Photo Books in minutes, enhancing user experience and satisfaction. By implementing Amazon Bedrock and Amazon Nova models, over 5.5 million personalized titles were generated in 2025, leading to increased engagement and purchase...
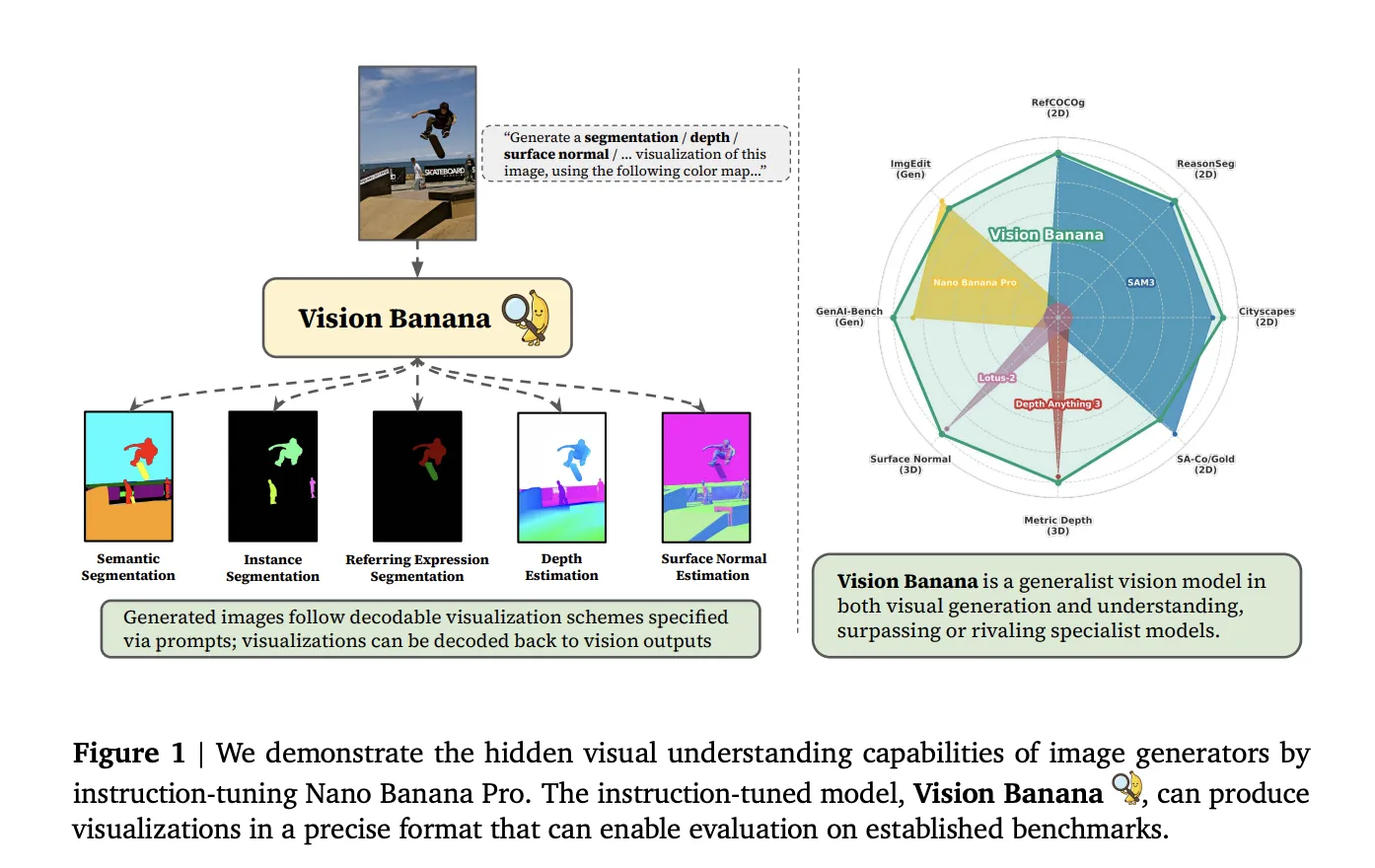
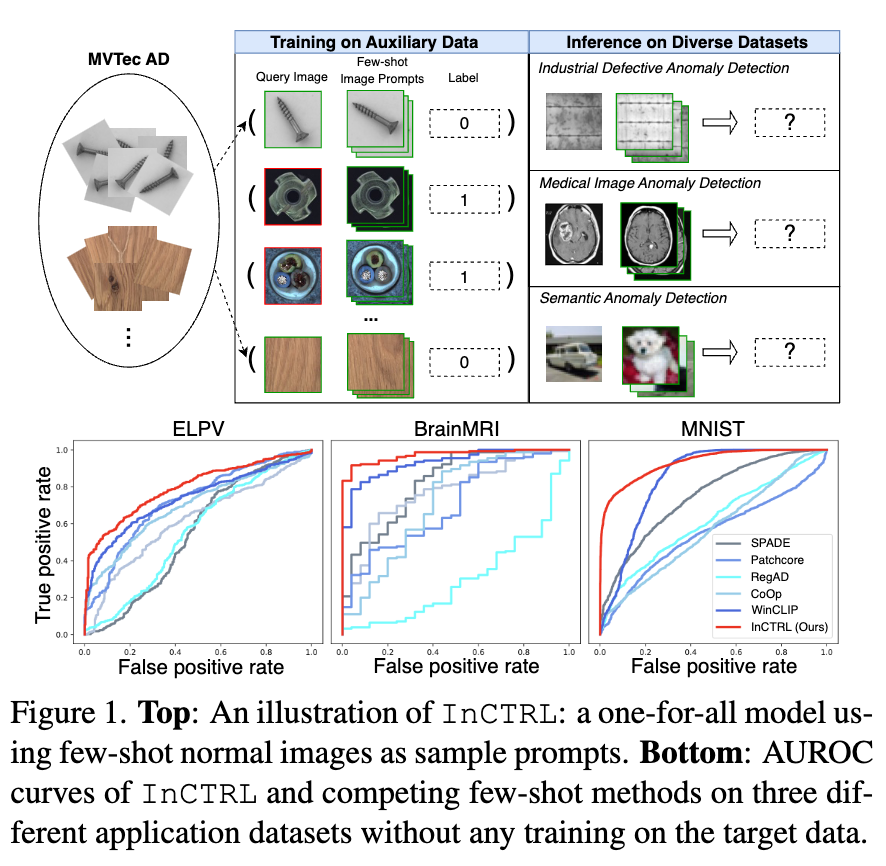
Google's new paper introduces Vision Banana, a unified model excelling in various visual tasks while maintaining image generation abilities. Vision Banana learns to express latent knowledge in measurable formats without task-specific training data, changing the perception of image...
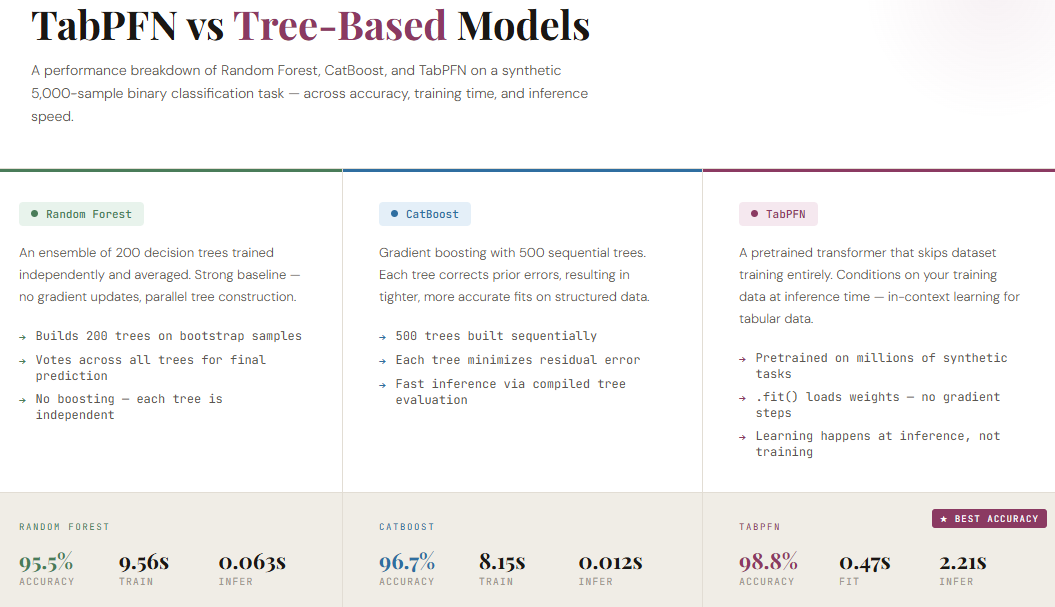
Tabular data is key in ML, with tree-based models like TabPFN challenging traditional approaches, outperforming XGBoost and CatBoost. TabPFN-2.5 offers improved performance, reducing manual effort and enabling faster inference for real-world...
Guidesly Pro streamlines outdoor bookings, payments, and marketing for professionals. Jack AI automates content creation for guides, freeing them from time-consuming marketing...

NVIDIA showcases AI-driven robots transforming industries like solar energy and agriculture. Maximo and Aigen use NVIDIA technology for faster, safer, and more sustainable infrastructure...

Amazon Bedrock's multimodal foundation models offer scalable video understanding through three architectural approaches, enabling organizations to extract nuanced insights from large volumes of video. The frame-based workflow optimizes precision and cost for use cases like security surveillance and compliance monitoring, utilizing intelligent frame deduplication to enhance processing...

Researchers from Woodwell Climate Research Center, MIT, and Intuit developed a computer vision system for automated fish monitoring using underwater video, enhancing traditional methods. This scalable, cost-effective solution improves efficiency and accuracy in tracking river herring populations during their annual...

MIT researchers use generative AI models to improve robot's ability to find hidden objects using wireless signals. The new technique can reconstruct hidden objects and entire rooms, enabling applications in warehouse and smart home...

MIT researchers developed a method to improve AI explainability by extracting concepts learned during training. This approach enhances accuracy and accountability of computer vision...
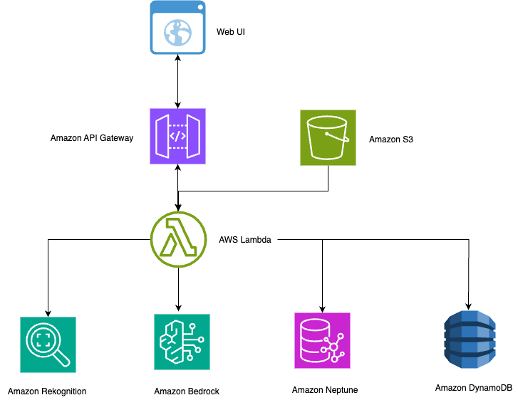
Intelligent photo search systems use computer vision and natural language processing to revolutionize photo organization. Amazon Rekognition, Neptune, and Bedrock enable personalized search with complex relationship mapping for thousands of...

Hexagon, a leader in measurement technologies, collaborates with Amazon to scale AI model production for specialized applications in industries like construction and autonomous vehicles. Specialized AI models by Hexagon improve precision and efficiency, enabling faster creation of accurate 3D models for various geospatial...

MIT professor Antonio Torralba named 2025 ACM Fellow for pioneering work in computer vision and AI. Torralba co-authored an 800-page textbook on computer vision and received numerous prestigious...
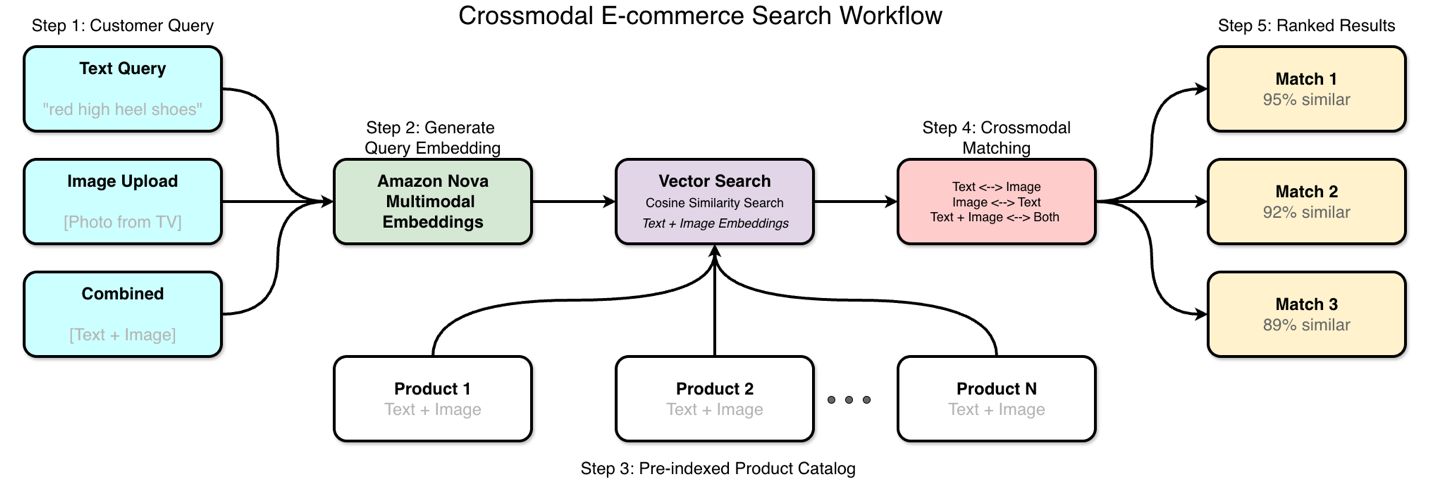
Amazon Nova Multimodal Embeddings simplifies crossmodal search by processing text, images, video, and audio in a single model architecture within Amazon Bedrock. This unified approach enables direct similarity calculations across different content types, eliminating the need for separate embedding models and improving user experience in ecommerce...
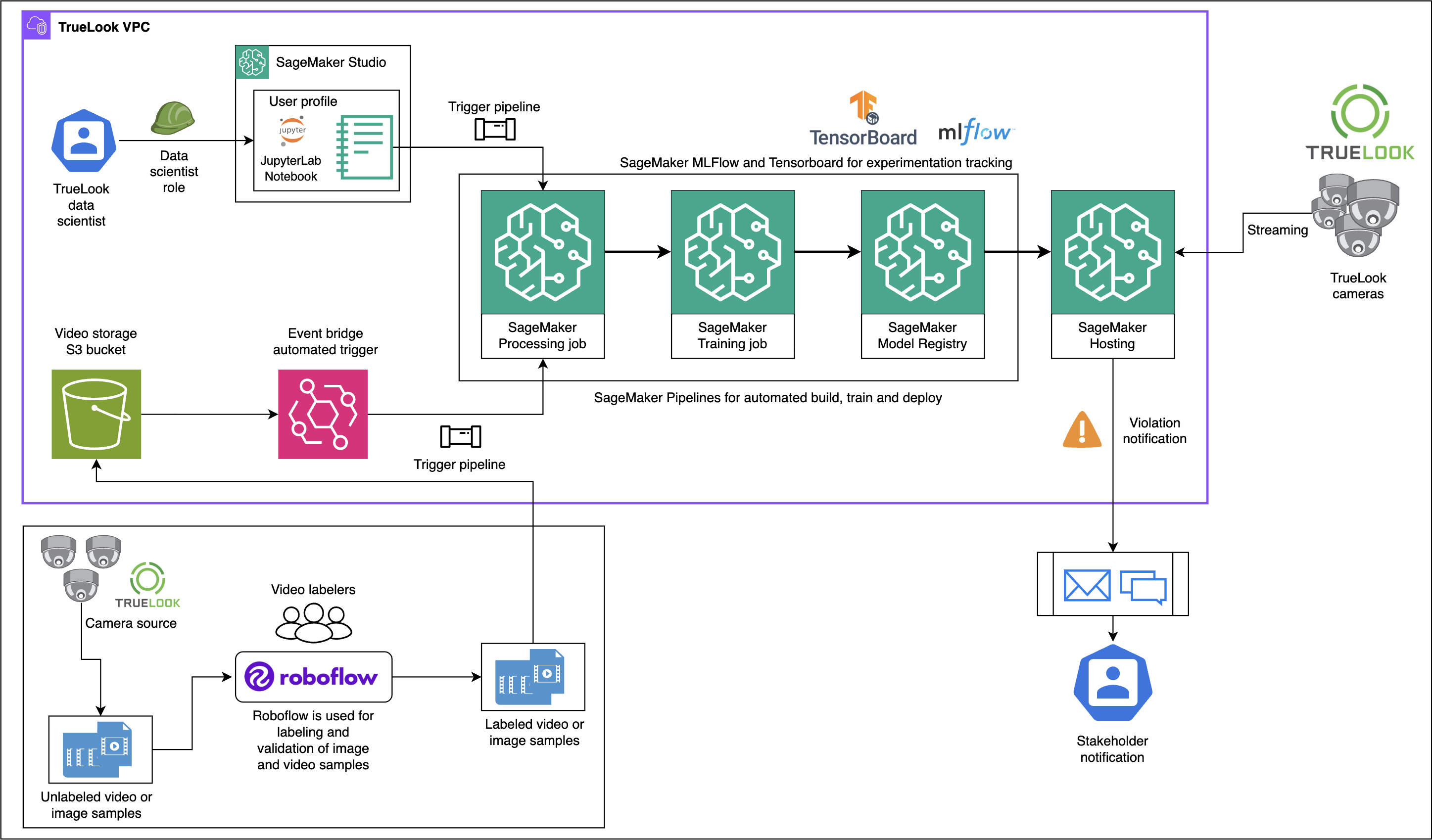
TrueLook and AWS collaborated to create an AI-powered construction safety monitoring system that automatically detects PPE to improve accountability and reduce risks on construction sites. This innovative solution utilizes high-resolution cameras, live video streaming, and AI insights to identify safety issues in real-time, moving from manual checks to a scalable approach for enhancing overall...

Amazon S3 offers high-performance for ML workloads. Optimize throughput with data shard consolidation and caching for...

MIT researchers developed a new method to stack transistors and memory devices, reducing energy waste and boosting computation speed. This advance in electronics fabrication could lead to faster, more energy-efficient devices for demanding applications like AI and deep...

Amazon discontinues Lookout for Vision, recommends SageMaker for AI/ML computer vision models. AWS offers pre-trained defect detection model on Marketplace for...

Berger-Wolf's BioCLIP 2 model, trained on the largest organism dataset, can arrange species by traits and relationships, aiding conservation efforts. The open-source model was downloaded over 45,000 times last month, showcasing its potential as a powerful research tool at NeurIPS AI...
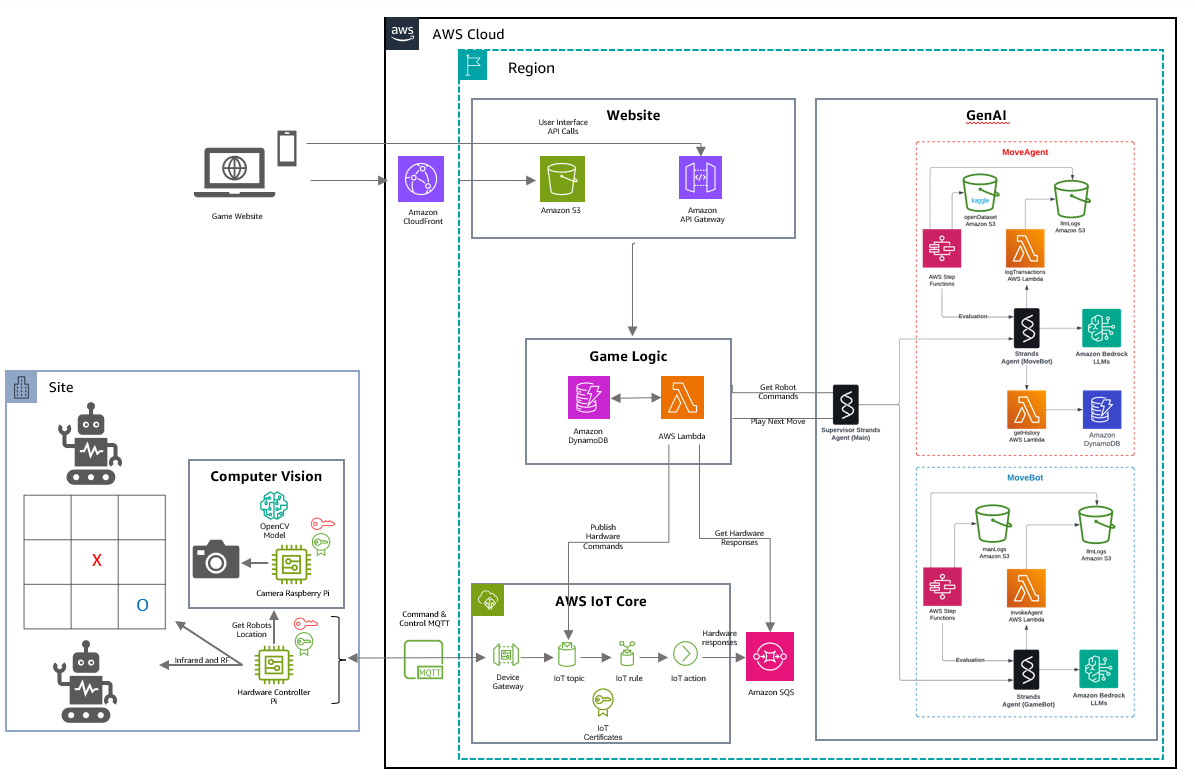
LLMs applied to physical robotics in RoboTic-Tac-Toe game at AWS re:Invent 2024, showcasing AI reasoning in real-time gameplay. Seamless AWS integration enables dynamic movement plans and game strategies without...
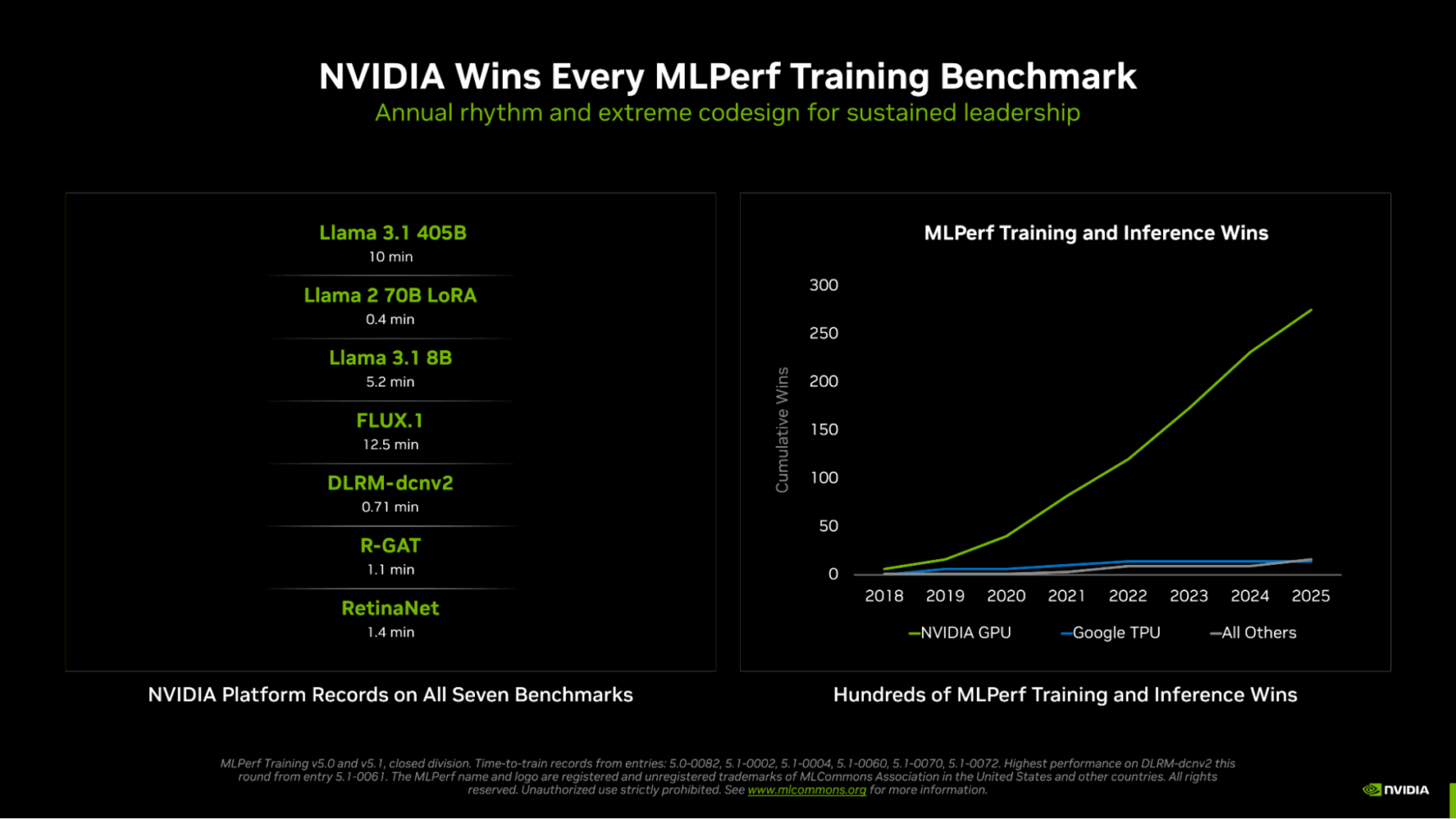
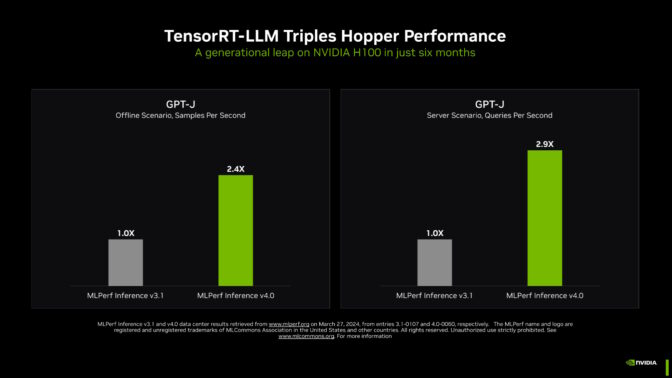
NVIDIA dominates MLPerf Training v5.1 with fastest time to train across various AI models. The Blackwell Ultra GPU architecture delivers record-breaking performance with FP4 precision, setting a new standard in AI...

Phillip Isola, an associate professor at EECS, explores human-like intelligence in AI models, focusing on computer vision and machine learning. His goal is to understand the commonalities between human, animal, and AI intelligence to safely integrate AI into...

MIT researchers have developed a new AI-driven system for search-and-rescue robots to quickly generate accurate 3D maps of complex scenes. The system can process an arbitrary number of images in real-time, making it easier to scale up for real-world applications in disaster scenarios and industrial...

Study from Oregon State University estimates 3,500 animal species at risk of extinction. MIT researchers develop AI algorithms to monitor and protect vulnerable wildlife...

AWS introduces Web Bot Auth, a solution for AI agents to browse the web securely. CAPTCHA friction reduced, allowing agents to verify their identities cryptographically with the new IETF...

MIT faculty members Dina Katabi and Facundo Batista elected to the National Academy of Medicine for groundbreaking work in health and medicine. Katabi pioneers digital health tech for remote monitoring, while Batista advances vaccine development for diseases like HIV and...

MIT and MIT-IBM Watson AI Lab researchers introduce a new training method to teach vision-language models to localize personalized objects in a scene, outperforming state-of-the-art systems. This approach could help AI systems track specific objects over time and assist visually impaired users in finding items in a...
MIT researchers developed an AI system for rapid medical image segmentation, allowing users to annotate images with minimal input. This tool could accelerate studies and reduce costs in medical research, without the need for extensive training or...
Enterprise document processing faces challenges in accurately locating and extracting specific fields. Traditional computer vision solutions are complex, but multimodal large language models like Amazon Nova Pro simplify high-accuracy field localization, reducing errors and manual...

MIT study shows 15% increase in pedestrian walking speed in northeastern U.S. cities from 1980 to 2010. Public spaces now function more as thoroughfares than meeting places, impacting urban...
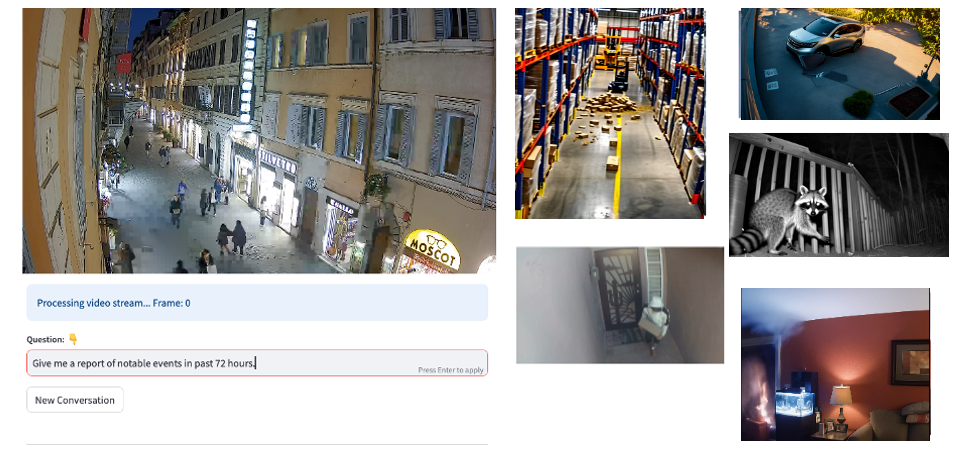
Organizations face challenges in video monitoring. Amazon Bedrock Agents offer a solution for real-time analysis, context understanding, and automated responses. This system enhances security and operational efficiency in complex monitoring...

MIT graduate student Alex Kachkine develops a method to physically apply digital restorations onto original paintings, speeding up the process by 66 times. His innovative approach allows for a clear digital record of restoration changes, potentially bringing more damaged art back to the public...
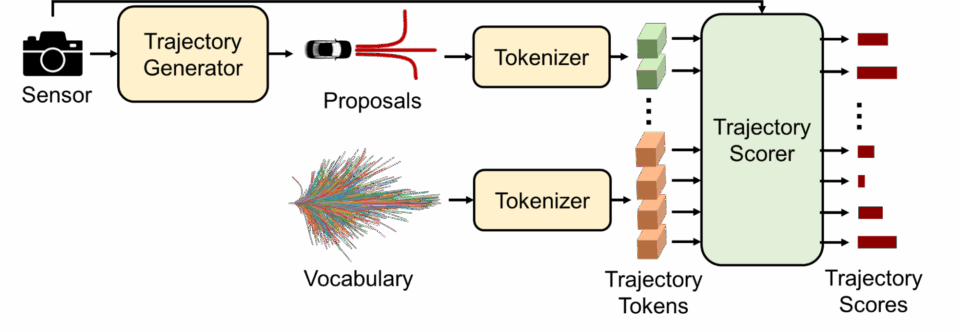
NVIDIA wins Autonomous Grand Challenge at CVPR for second year in a row. Introduces Generalized Trajectory Scoring for smarter, safer...
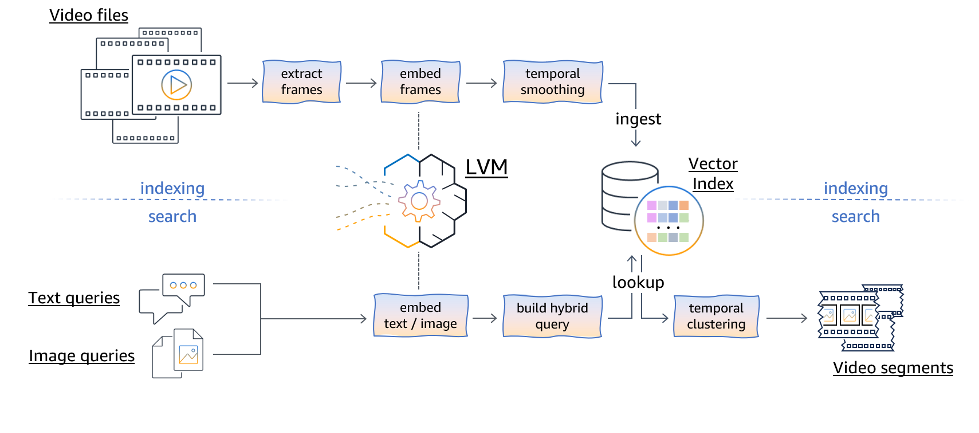
Semantic video search using large vision models enables users to search for video content with natural language queries, enhancing content discovery and moderation. Large vision models like CLIP allow for zero-shot transfer to various computer vision tasks, revolutionizing video search...

MIT and Stanford develop SketchAgent, an AI system that creates sketches stroke-by-stroke based on natural language prompts. The tool aims to revolutionize how humans communicate with AI through a more natural and iterative drawing...

Researchers from MIT improve AI model's ability to learn like humans, connecting audio and visual data without human labels. Method enhances accuracy in video retrieval tasks and action classification in audiovisual scenes, opening new...

Discover how to harness your Nvidia GPU's power with PyTorch, a machine learning library optimized for GPU operations. PyTorch's CUDA support enables efficient tensor manipulation, making it ideal for high-demand computational tasks beyond...
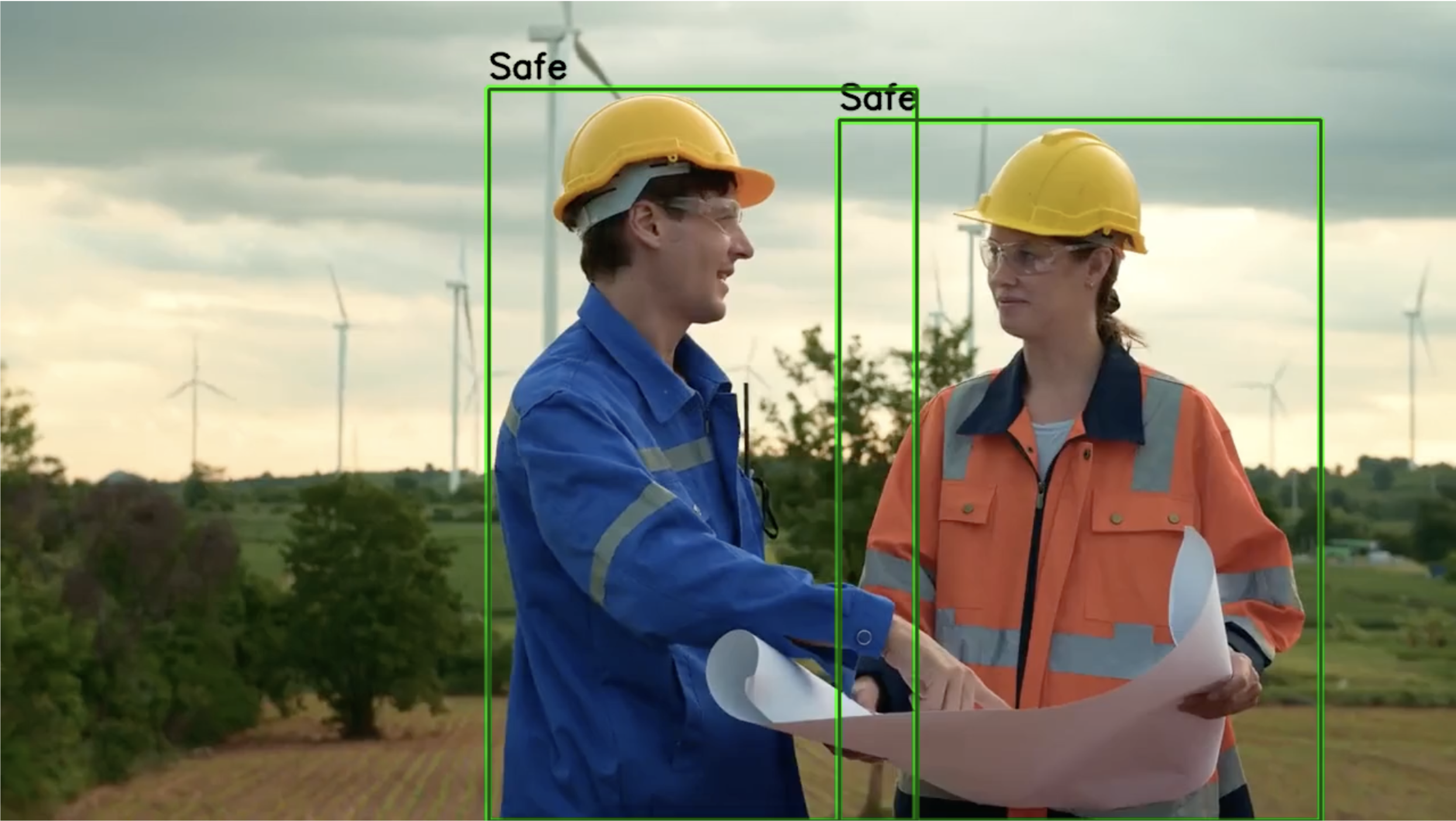
SiMa.ai and AWS collaborate for efficient ML model deployment at the edge with Amazon SageMaker AI and Palette Edgematic. Detect human presence and safety equipment in real-time on edge devices for enhanced workplace safety with optimized object detection...
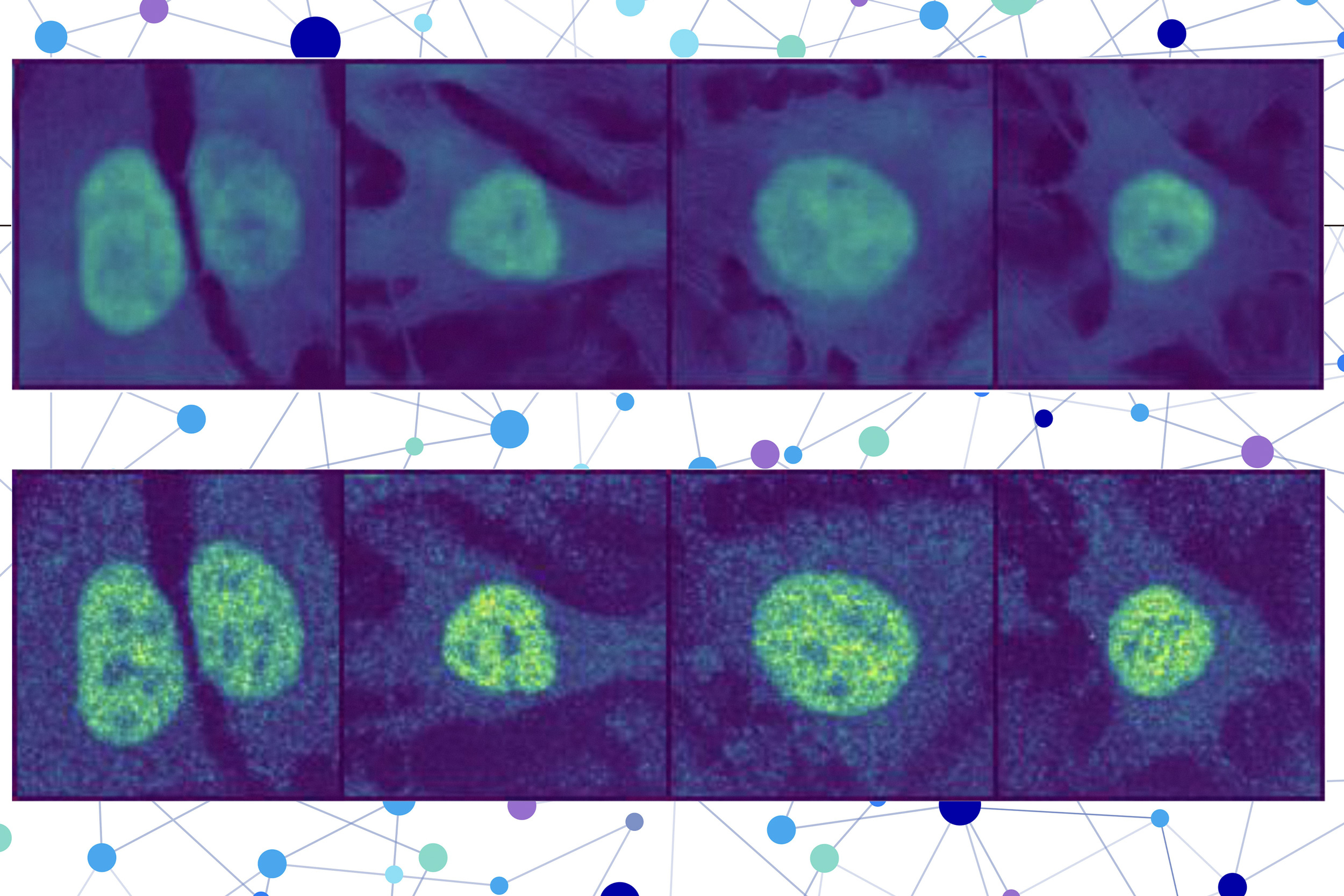
New computational approach predicts protein locations in cells, aiding in disease diagnosis and drug target identification. MIT, Harvard, and Broad Institute researchers develop method for single-cell protein localization using AI...
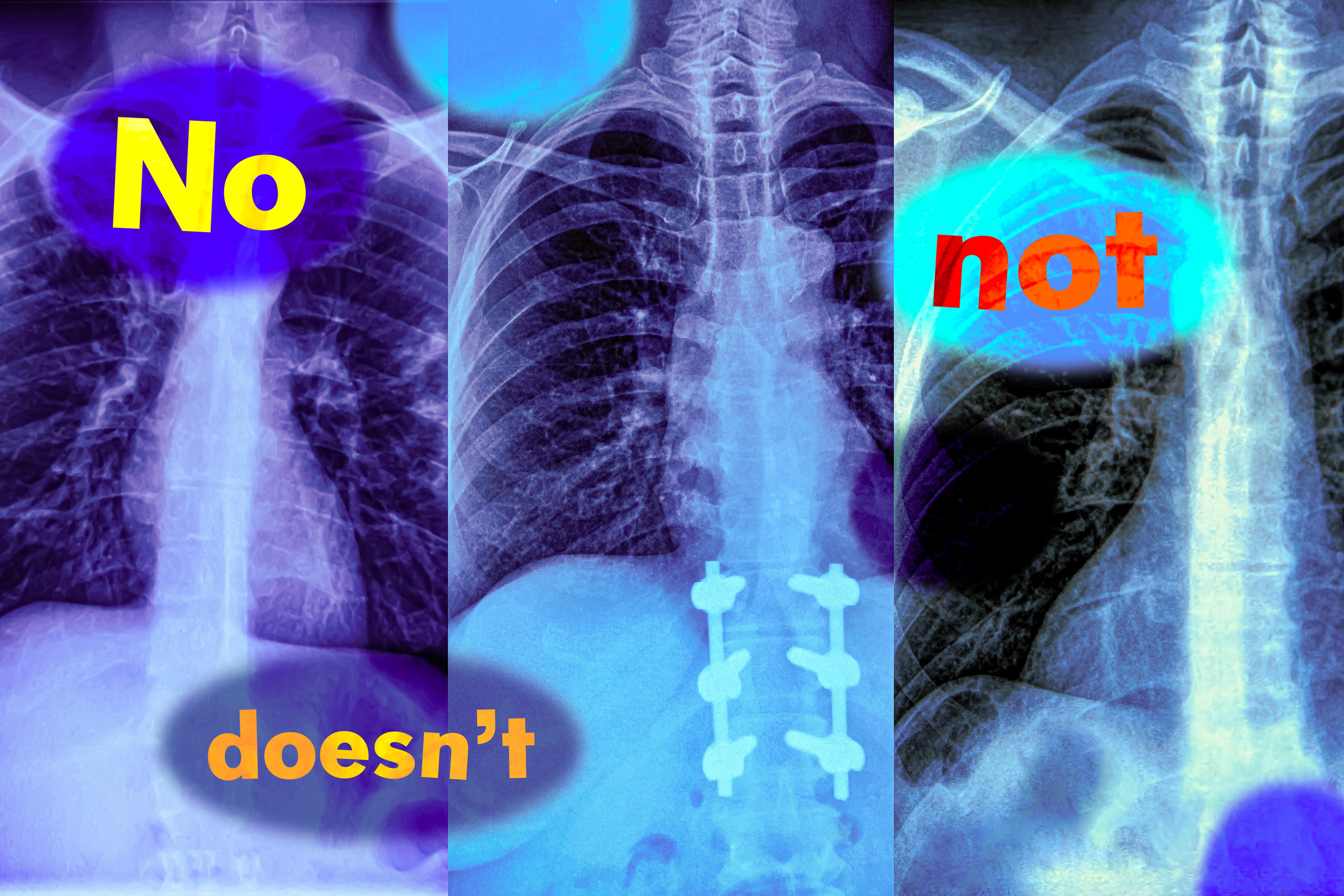
Vision-language models struggle with negation, impacting accuracy. MIT researchers urge caution in using these models...

Understanding image storage and representation is key in Computer Vision. RGB and HSV color models provide valuable insights for image processing in Python using...

AI model aids clinicians in medical imaging by generating smaller, more reliable prediction sets, improving diagnostic efficiency. MIT researchers develop conformal classification method to enhance accuracy in identifying diseases, presenting findings at a major...
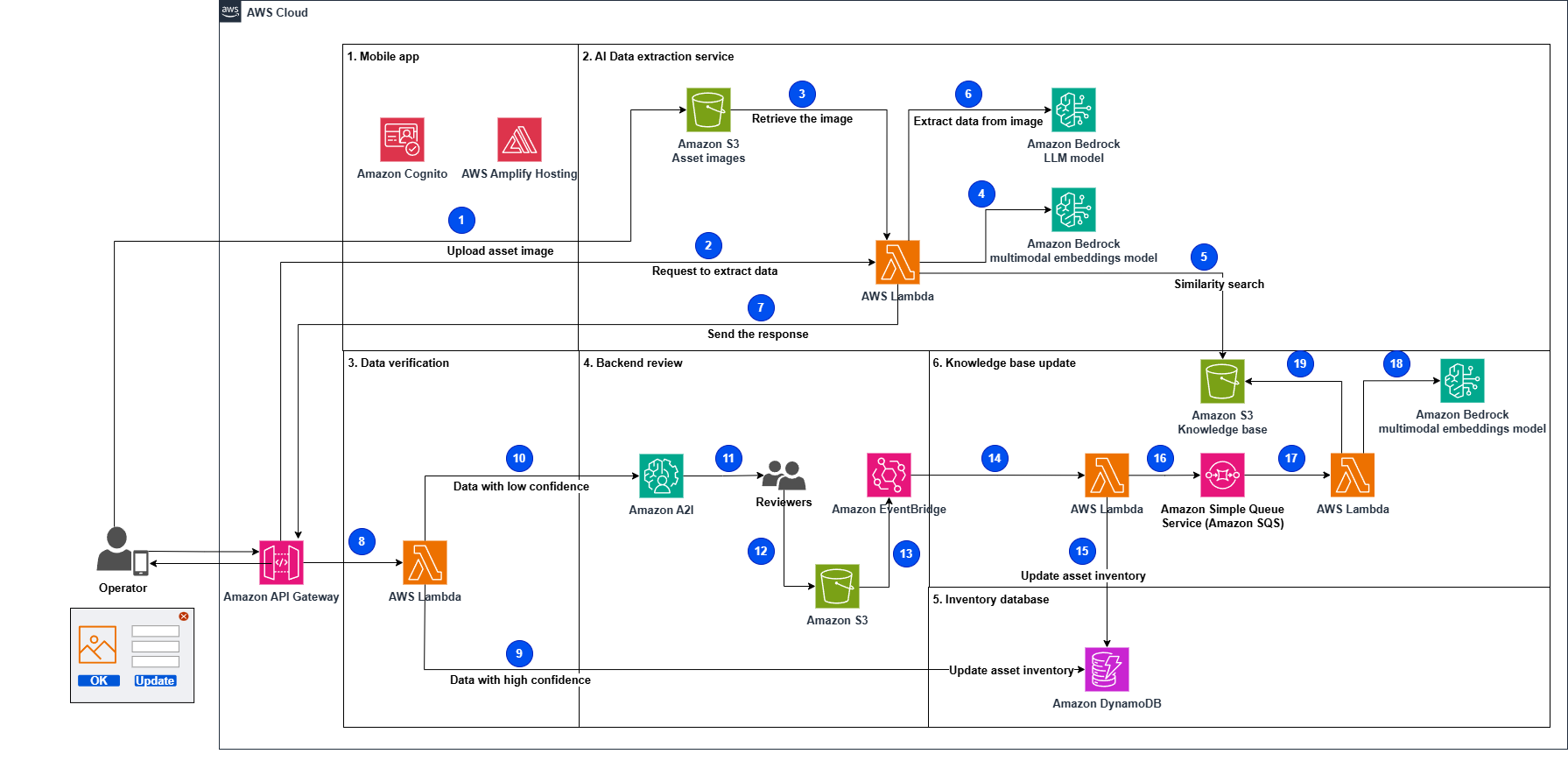
Using generative AI and large language models, electricity providers can streamline asset inventory management by automatically extracting data from labels using computer vision. This innovative solution leverages AWS services like Amazon Bedrock and Anthropic’s Claude 3 to simplify the process, allowing field technicians to easily update inventory databases with accurate...
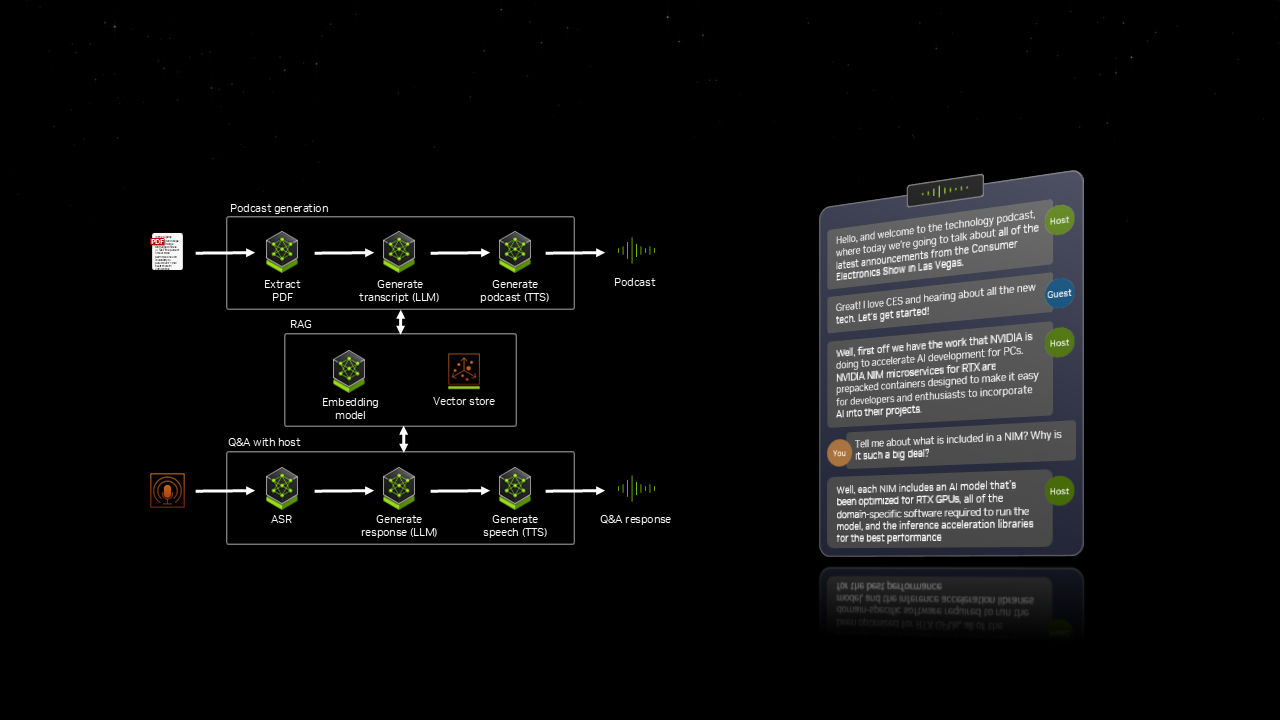
Generative AI enhances PCs with NVIDIA NIM microservices, AI Blueprints, and Project G-Assist for improved accessibility and productivity. NVIDIA NIM offers prepackaged AI models optimized for RTX, simplifying AI development and expanding AI-powered tools for...

Randall Pietersen, a MathWorks Fellow at MIT and U.S. Air Force engineer, aims to develop drone-based systems for remote airfield assessment, focusing on detecting unexploded munitions using hyperspectral imaging. His multidisciplinary approach and extreme sports background contribute to cutting-edge research at...
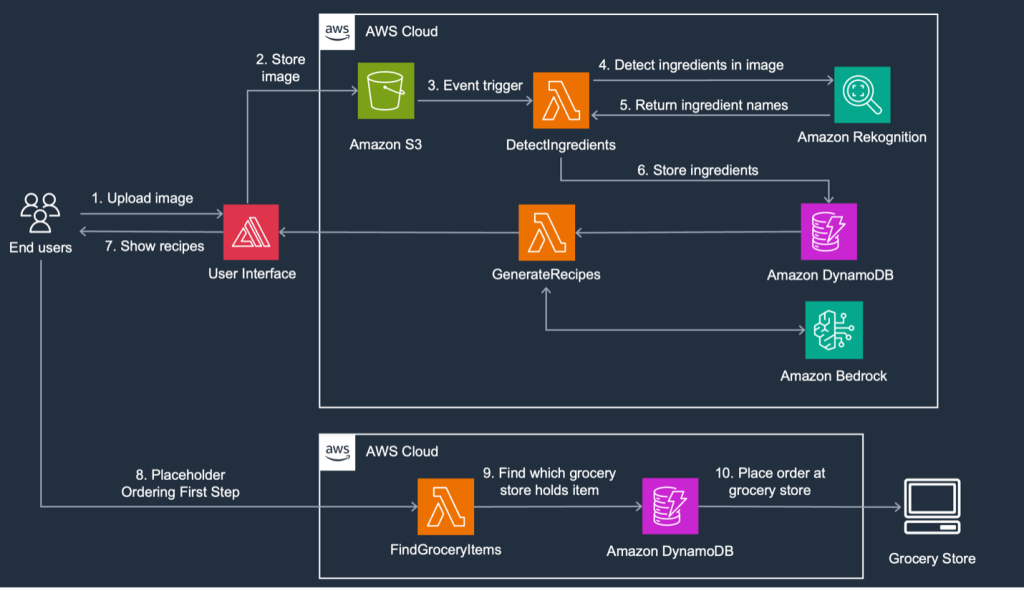
FoodSavr, a solution using generative AI on AWS, recommends recipes based on fridge contents and expiring items in local stores, reducing food waste and saving money. By utilizing Amazon Rekognition and Amazon Bedrock, users can upload fridge images to receive personalized recipes and nearby grocery store...

Transformers are revolutionizing NLP with efficient self-attention mechanisms. Integrating transformers in computer vision faces scalability challenges, but promising breakthroughs are on the...

Data science advancements like Transformer, ChatGPT, and RAG are reshaping tech. Understanding NLP evolution is key for aspiring data...
Meta SAM 2.1, a cutting-edge vision segmentation model, is now available on Amazon SageMaker JumpStart for various industries. This model offers state-of-the-art object detection and segmentation capabilities with enhanced accuracy and scalability, empowering organizations to achieve precise outcomes...

Kaiming He at MIT sees AI breaking down walls between scientific disciplines, creating a common language for progress and collaboration. From AlphaFold to ChatGPT, AI tools are propelling advancements in diverse fields like protein structure prediction and natural language...

Sara Beery applies computer vision and machine learning to monitor salmon migration, critical for ecosystem health and cultural significance in the Pacific Northwest. Accurate salmon counting essential for managing fisheries amid threats from human activity, habitat loss, and climate...

AI advancements have merged NLP and Computer Vision, leading to image captioning models like the one in "Show and Tell." This model combines CNN for image processing and RNN for text generation, using GoogLeNet and...

Build a vehicle documentation system using OpenAI's GPT-4, LangChain, and Pydantic for structured data extraction from images. Simplify complex workflows with LangChain and ensure output consistency with Pydantic for easy downstream...
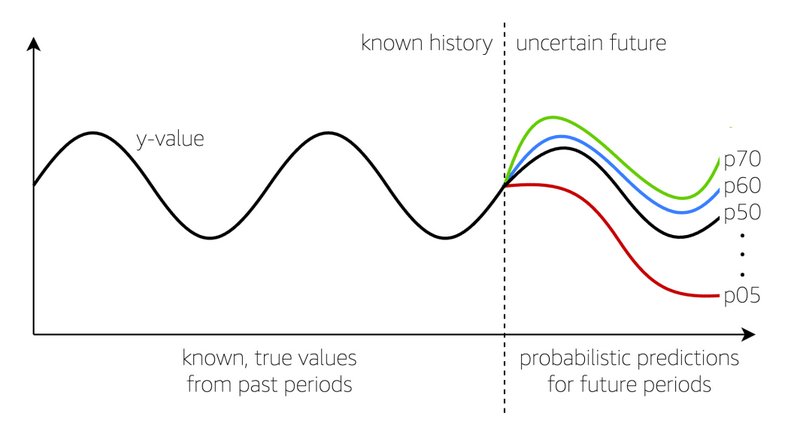
Supply chain forecasting is crucial for businesses facing volatile markets. Amazon Web Services' SageMaker Canvas offers no-code ML solutions for accurate forecasting in retail and consumer packaged goods...

MIT CSAIL researchers have created an AI system that mimics human vocal sounds with no training, inspired by cognitive science. This breakthrough could lead to more intuitive sound design interfaces, lifelike AI characters, and innovative language learning...

Nature image datasets, with millions of photos, aid ecologists in studying behaviors and responses to climate change. Multimodal vision language models can improve image retrieval for researchers, but need more domain-specific training data for complex...

MIT faculty and alumni named 2024 AI2050 Fellows by Schmidt Futures to tackle hard AI problems. David Autor and Sara Beery among honorees for innovative AI research...

CV VideoPlayer, a Python package for computer vision research, simplifies video visualization and debugging with interactive features. It allows easy customization of overlays and frame edits, enhancing the development process for...
Pixtral 12B, Mistral AI's cutting-edge vision language model, excels in text-only and multimodal tasks, outperforming other models. It features a novel architecture with a 400-million-parameter vision encoder and a 12-billion-parameter transformer decoder, offering high performance and speed for understanding images and...

Learn to chat with images using Llama 3.2-Vision, a cutting-edge multimodal LLM by Meta. Explore its OCR and reasoning skills on Colab notebook for local...
Nobel-winning economist Daron Acemoglu examines AI's impact on economic growth and productivity, estimating a modest increase of 1.1 to 1.6 percent in GDP over the next decade. Research shows about 20-23% of U.S. job tasks could be automated with AI, with potential cost savings of...
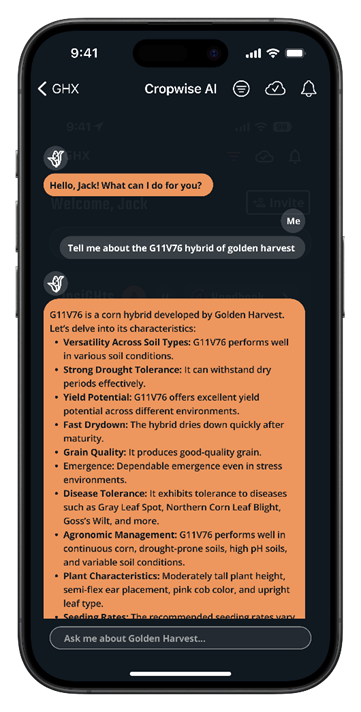
Syngenta and AWS collaborated to develop Cropwise AI, powered by Amazon Bedrock Agents, to streamline seed selection for farmers and sales reps. Generative AI transforms the decision-making process, offering personalized recommendations at scale for a more efficient and precise selection...

Multimodal embeddings merge text and image data into a single model, enabling cross-modal applications like image captioning and content moderation. CLIP aligns text and image representations for 0-shot image classification, showcasing the power of shared embedding...
Meta Llama 3.1 LLMs with 8B and 70B inference support now on AWS Trainium and Inferentia instances. SageMaker JumpStart offers secure deployment of pre-trained models for customization and...
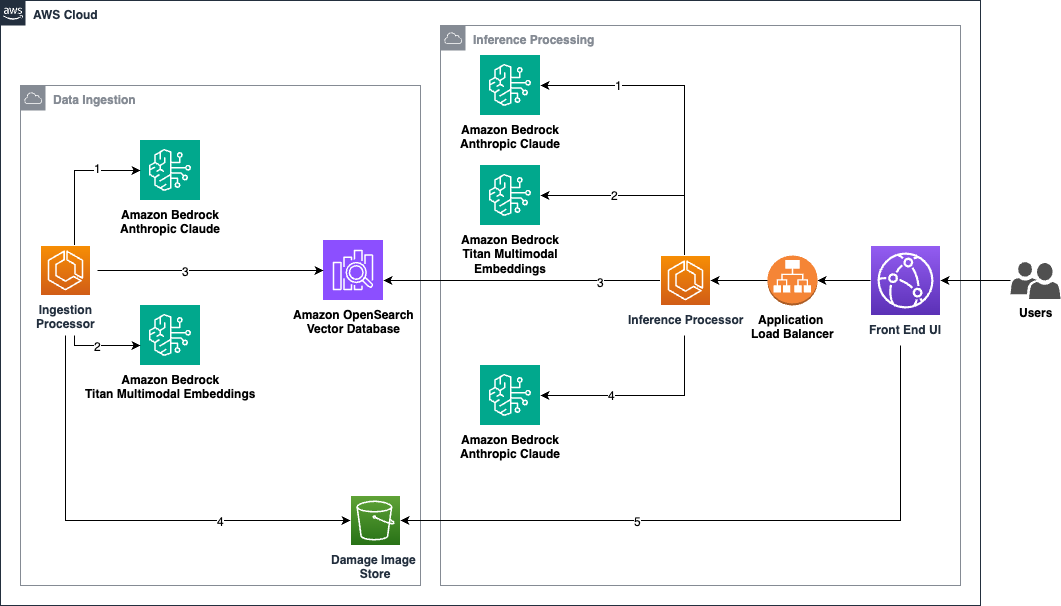
A solution using AWS generative AI like Amazon Bedrock and OpenSearch simplifies vehicle damage appraisals for insurers, repair shops, and fleet managers. By converting image and metadata to numerical vectors, this approach streamlines the process and provides valuable insights for informed decision-making in the automotive...
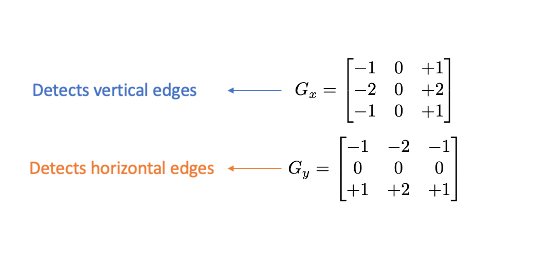
Histogram of Oriented Gradients (HOG) is a key feature extraction algorithm for object detection and recognition tasks, utilizing gradient magnitude and orientation to create meaningful histograms. The HOG algorithm involves calculating gradient images, creating histograms of gradients, and normalizing to reduce lighting...
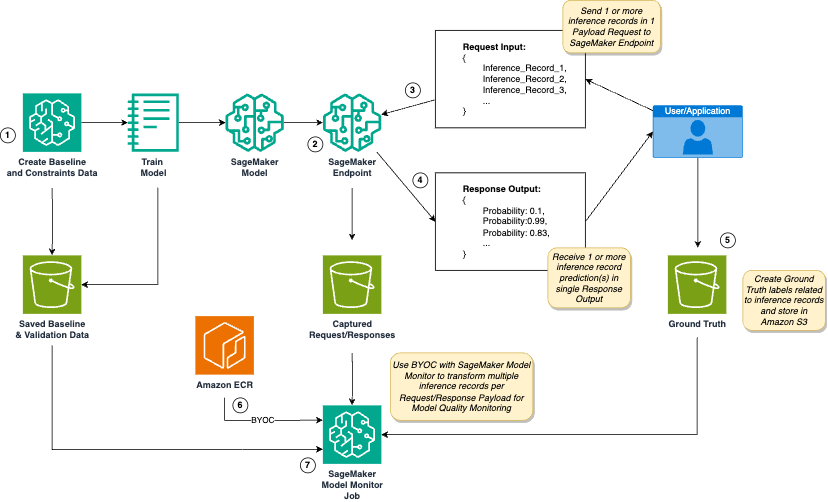
Customized model monitoring with Amazon SageMaker is crucial for real-time AI/ML scenarios. SageMaker Model Monitor offers advanced capabilities for monitoring model quality and handling multi-payload requests, accelerating customized model monitoring...

Engage in Relational Deep Learning (RDL) by directly training on your relational database, transforming tables into a graph for efficient ML tasks. RDL eliminates feature engineering steps by learning from raw relational data, enhancing model performance and...

MIT researchers propose Diffusion Forcing, a new training technique that combines next-token and full-sequence diffusion models for flexible, reliable sequence generation. This method enhances AI decision-making, improves video quality, and aids robots in completing tasks by predicting future steps with varying noise...

Florence-2 by Microsoft, a compact Vision-Language Model, excels in image annotation tasks with zero-shot capabilities. Pre-trained on FLD-5B, it supports tasks like captioning, object detection, segmentation, and OCR in a single...
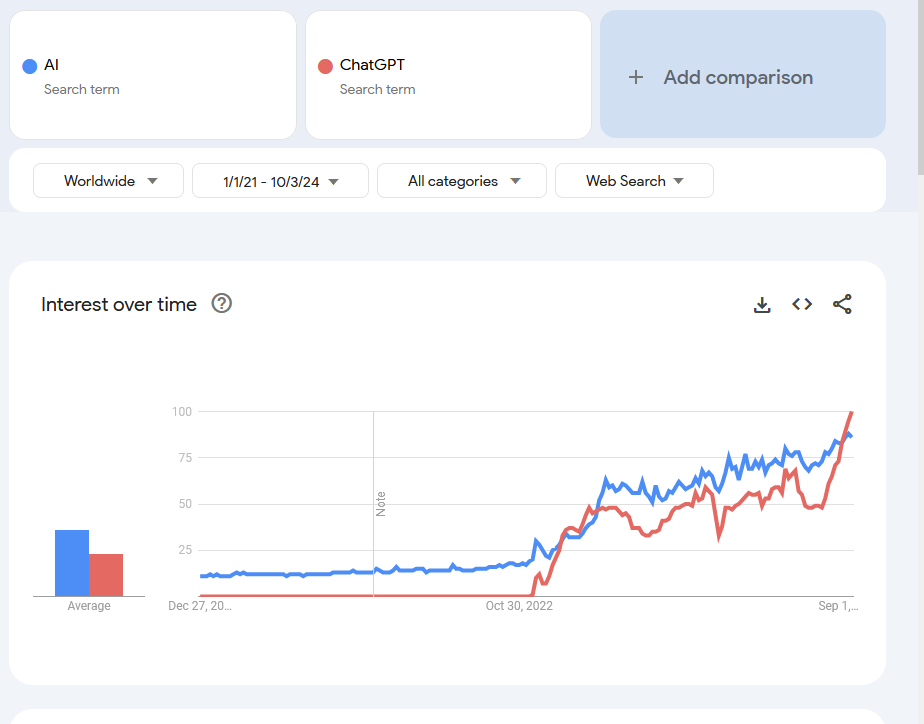
AI models like ChatGPT are ubiquitous and beneficial, but Generative AI poses challenges with misinformation and ethical concerns. Hype around AI, exemplified by NVIDIA's stock surge, raises questions about its societal impact and potential...
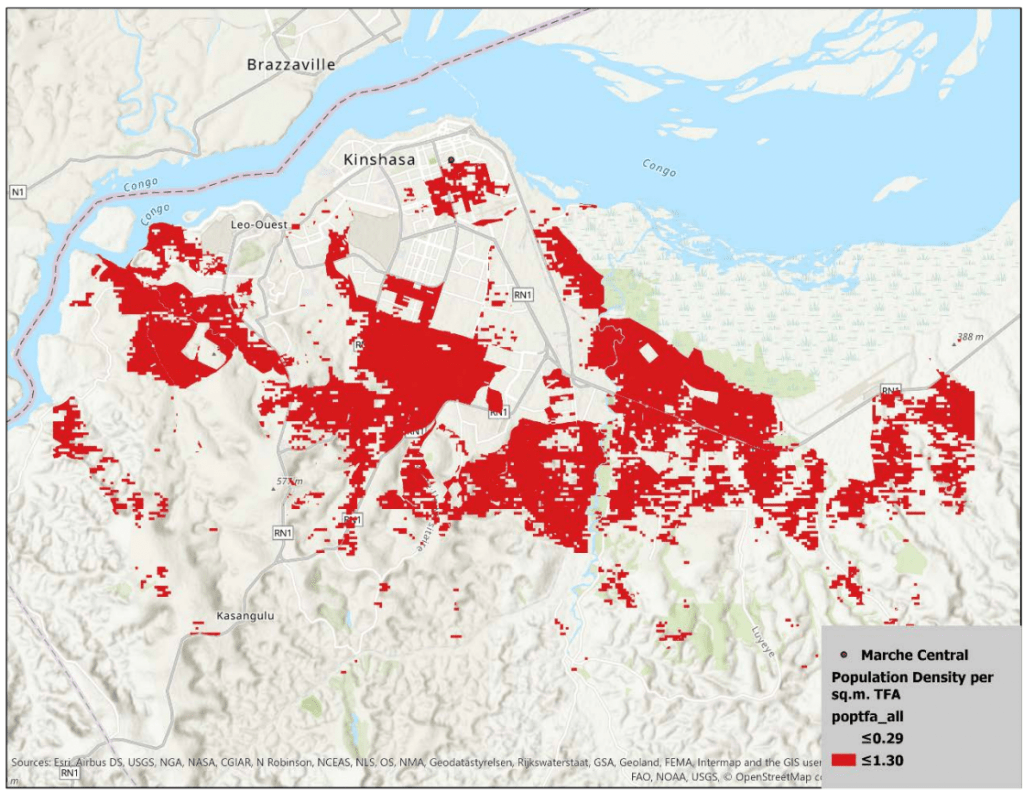
Meta's Data for Good program is open-sourcing AI-powered population maps on GitHub, aiding climate adaptation and disaster response projects worldwide. By providing training data and code, Meta hopes to improve global disaster preparedness and climate adaptation efforts through accurate population...

Training computer vision models with Ultralytics' YOLOv8 is now easier using Python, CLI, or Google Colab. YOLOv8 is known for accuracy, speed, and flexibility, offering local-based or cloud-based training options, such as Google Colab for enhanced computation...

MIT engineers have developed Clio, a method enabling robots to make intuitive, task-relevant decisions by identifying and remembering only relevant elements in a scene. Clio's capabilities, showcased in real experiments, could be crucial for search and rescue missions, domestic robots, and factory automation, according to...

In 1994, Diana Duyser auctioned a grilled cheese with the Virgin Mary's image for $28,000. MIT's study on pareidolia reveals human-machine perception differences and a possible evolutionary link to survival...
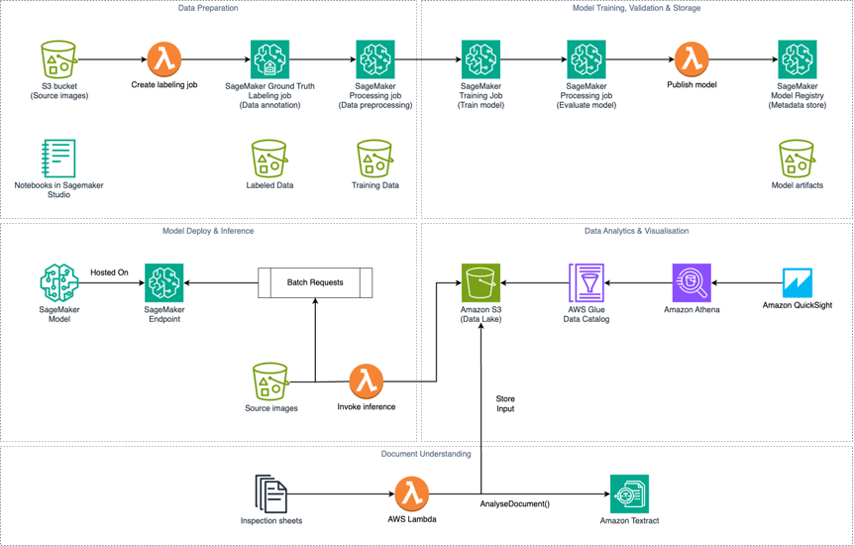
Northpower, a major infrastructure contractor in New Zealand, utilizes AI to prioritize public safety risks, reducing effort and carbon emissions. Facing challenges in inspecting power poles for safety, Northpower combines digital and scanned data to efficiently identify and address potential...

Tesla and others face challenges infusing robots with AI. Boston Dynamics' Atlas robot raises hopes for a multipurpose domestic...
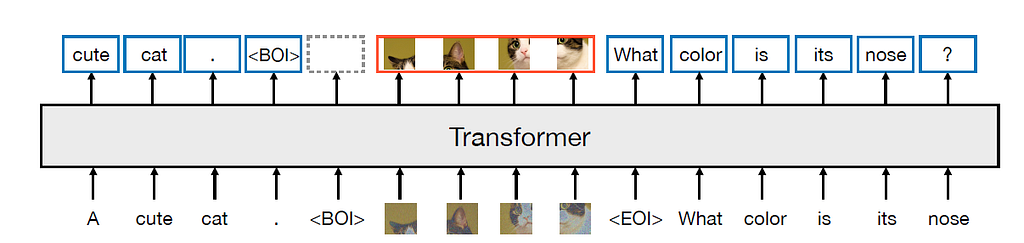
Meta and Waymo introduce Transfusion model combining transformer and diffusion for multi-modal prediction. Transfusion model uses bi-directional transformer attention for image tokens and pre-training tasks for text and...
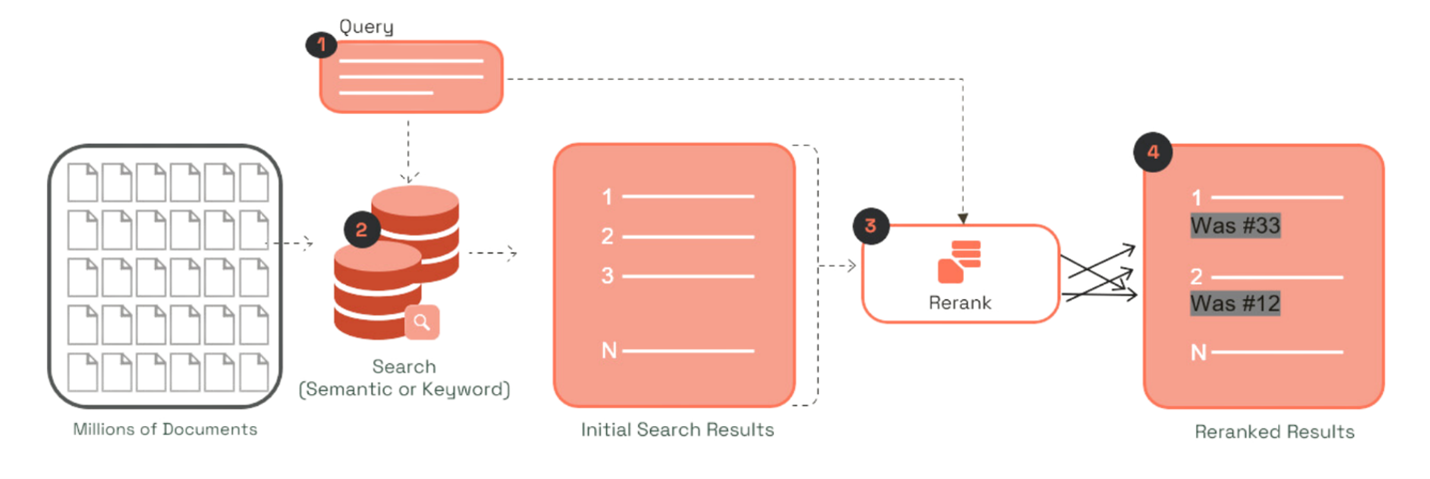
Cohere Rerank 3 Nimble FM enhances enterprise search systems, improving speed and accuracy by reordering relevant documents efficiently. Amazon SageMaker JumpStart provides access to pre-trained models like Cohere Rerank 3 Nimble, enabling customization for specific use cases without starting from...
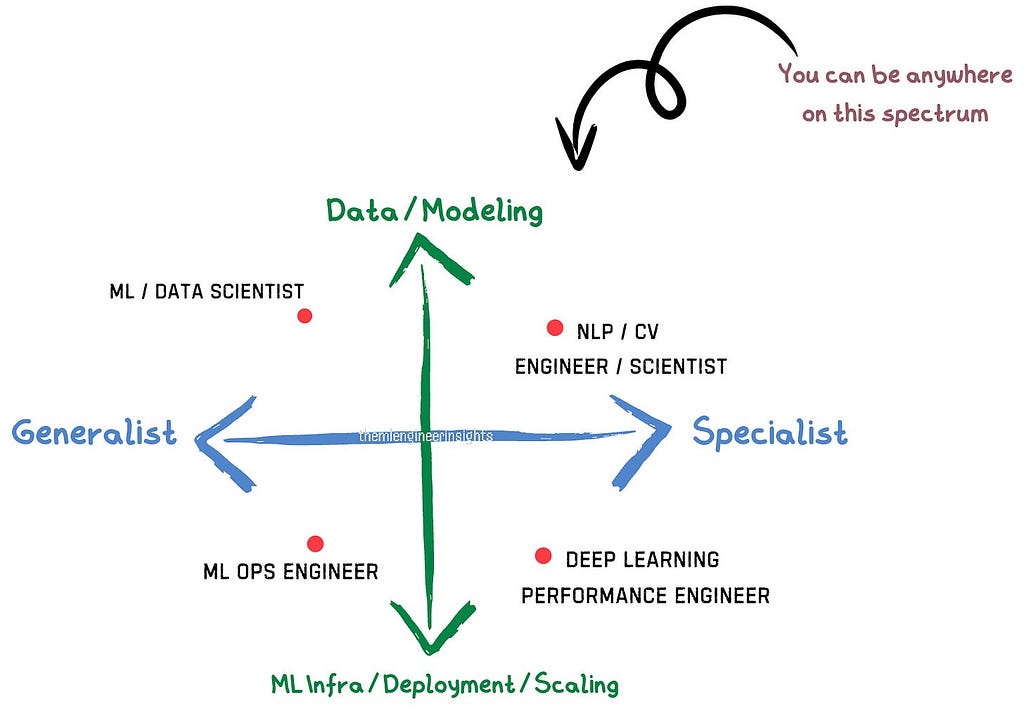
Decoding ML job roles is key to interview success. Understanding spectrum of roles can refine strategy and boost...

Integrating Batch Normalization in a ViT architecture reduces training and inference times by over 60%, maintaining or improving accuracy. The modification involves replacing Layer Normalization with Batch Normalization in the encoder-only transformer...

MIT CSAIL researchers developed RialTo, a system that creates digital twins for training robots in specific environments faster and more effectively. RialTo improved robot performance by 67% in various tasks, handling disturbances and distractions with...
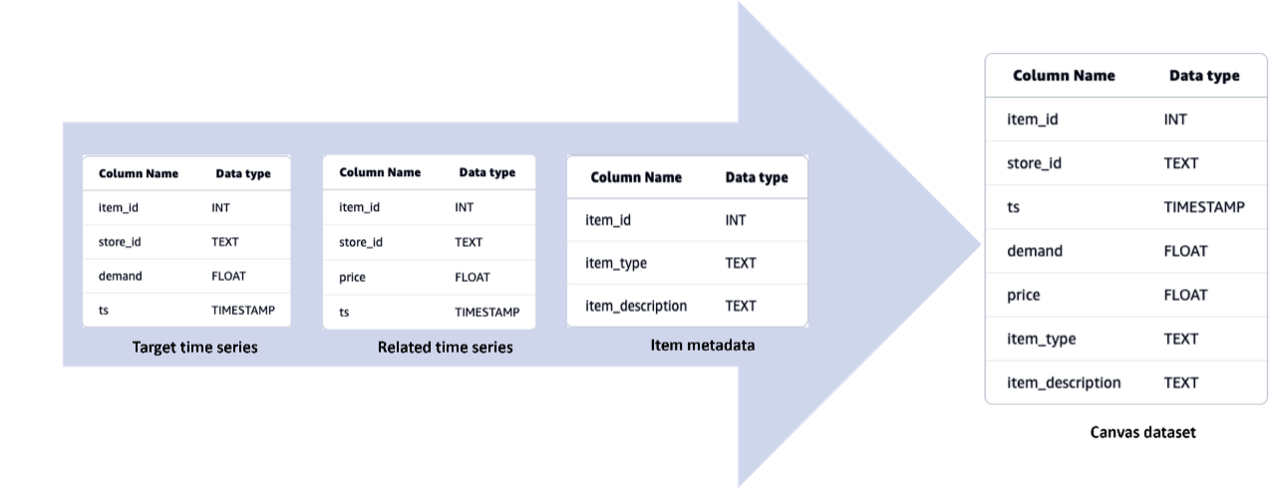
Amazon Forecast, launched in 2019, offers accurate time series forecasts. SageMaker Canvas provides faster model building, cost-effective predictions, and enhanced transparency for ML models, including time series...
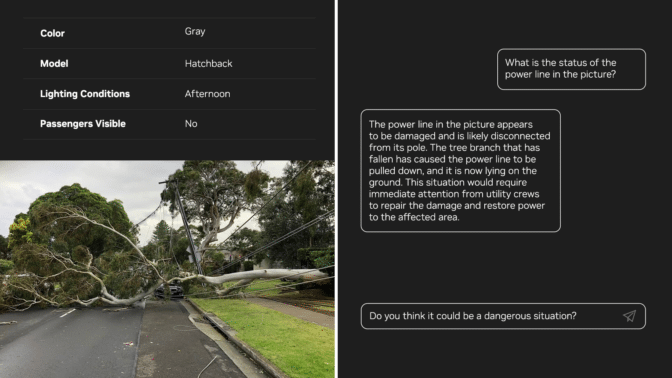
NVIDIA unveils generative physical AI advancements at SIGGRAPH, including NIM microservices for building interactive visual AI agents and training physical machines. The technology transforms industries like manufacturing and healthcare, enabling robots and automation to navigate their surroundings more...
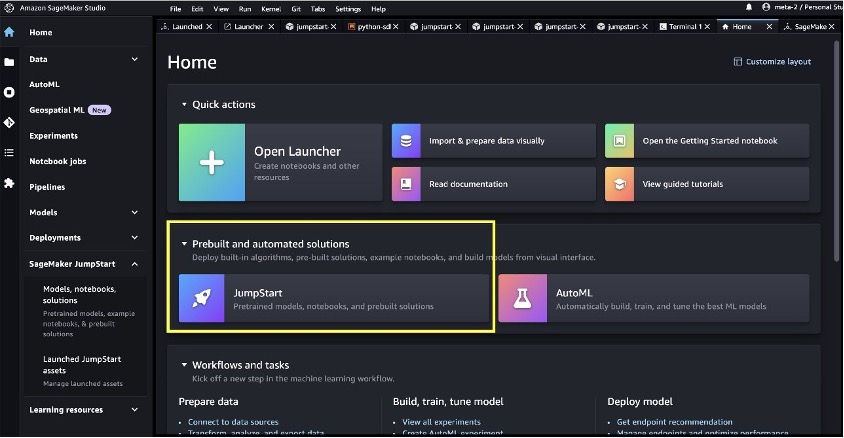
Llama 3.1's multilingual LLMs, available on Amazon SageMaker JumpStart, offer optimized generative AI models for developers and businesses. SageMaker JumpStart provides access to pre-trained foundation models, allowing for customization and secure deployment in a dedicated VPC...

Satellite imagery enhances monitoring of Earth's changes, but cloud segmentation is crucial. Algorithms like Random Forest and YOLO are compared for cloud removal in Sentinel-2 images. Access data through Copernicus Open Access Hub, Google Earth Engine, or Python package...
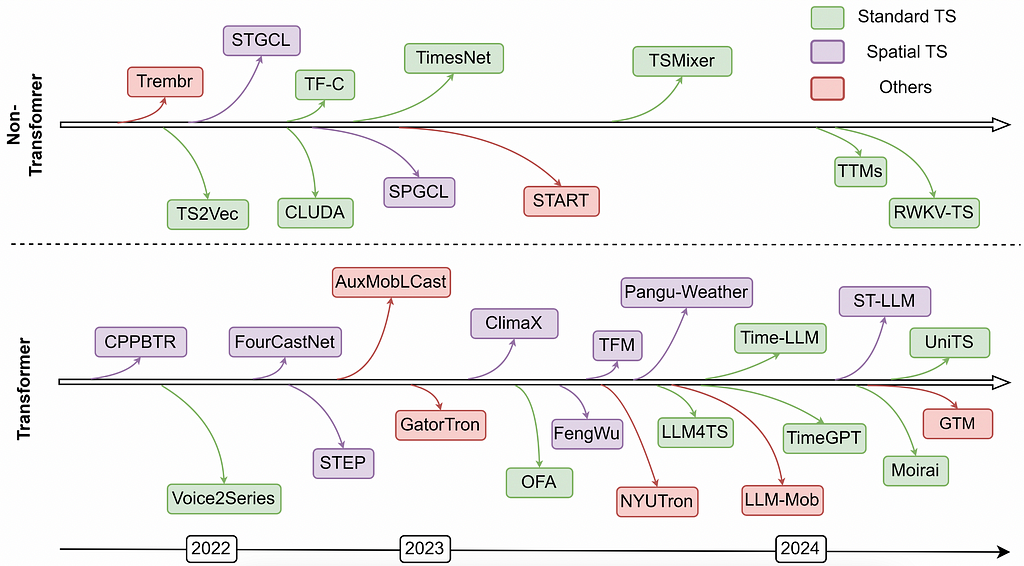
Foundation models, like Large Language Models (LLMs), are being adapted for time series modeling through Large Time Series Foundation Models (LTSM). By leveraging sequential data similarities, LTSM aims to learn from diverse time series data for tasks like outlier detection and classification, building on the success of LLMs in computational linguistic...

TDS celebrates milestone with engaging articles on cutting-edge computer vision and object detection techniques. Highlights include object counting in videos, AI player tracking in ice hockey, and a crash course on autonomous driving...
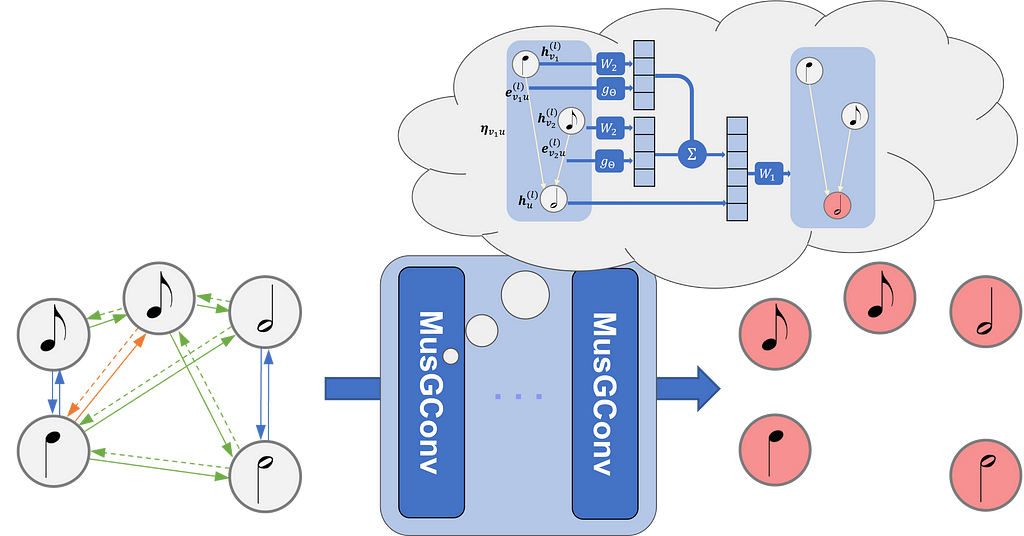
MusGConv introduces a perception-inspired graph convolution block for processing music score data, improving efficiency and performance in music understanding tasks. Traditional MIR approaches are enhanced by MusGConv, which models musical scores as graphs to capture complex, multi-dimensional music...
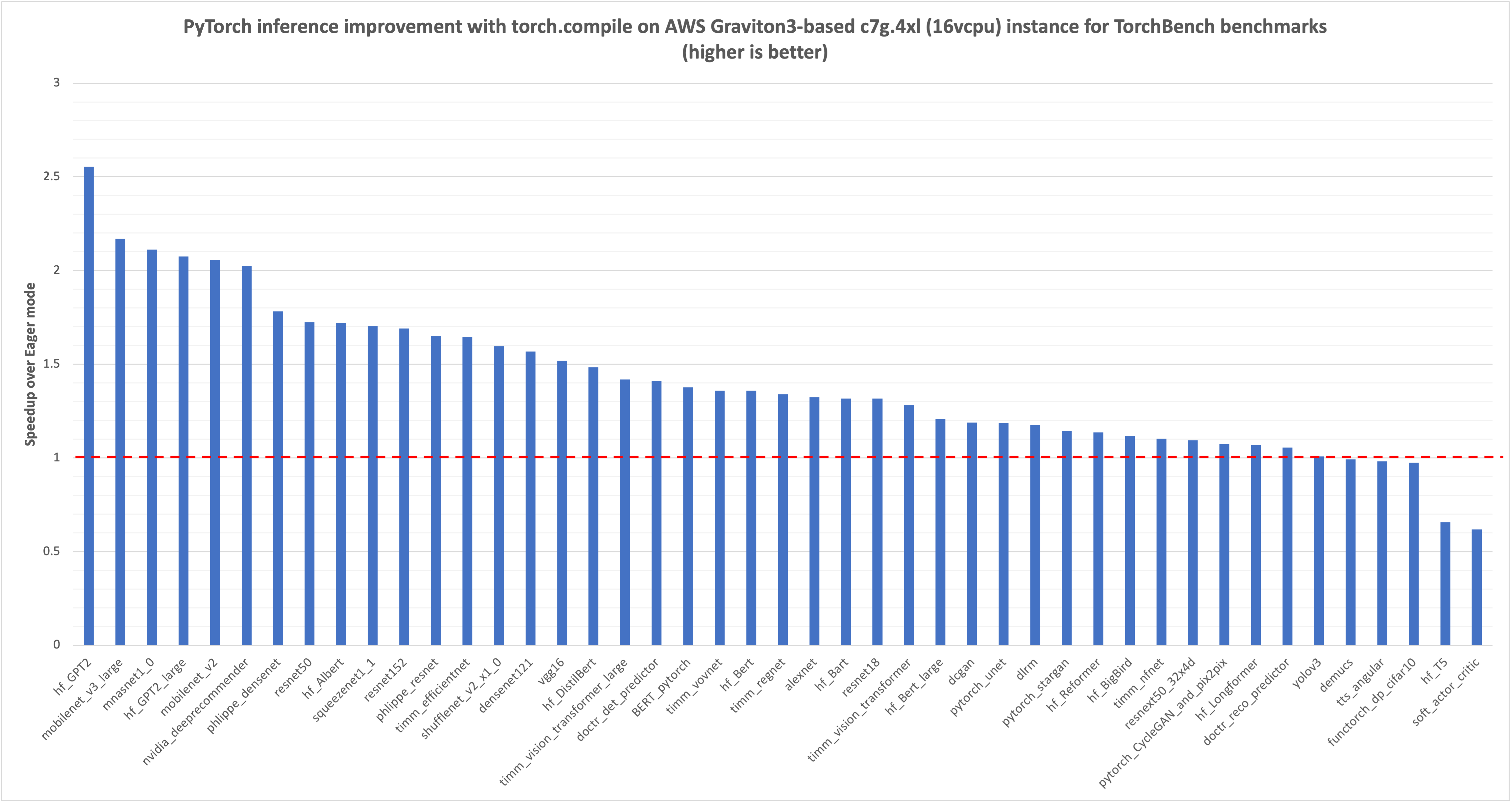
PyTorch 2.0 introduced torch.compile for faster code execution. AWS optimized torch.compile for Graviton3 processors, resulting in significant performance improvements for NLP, CV, and recommendation...
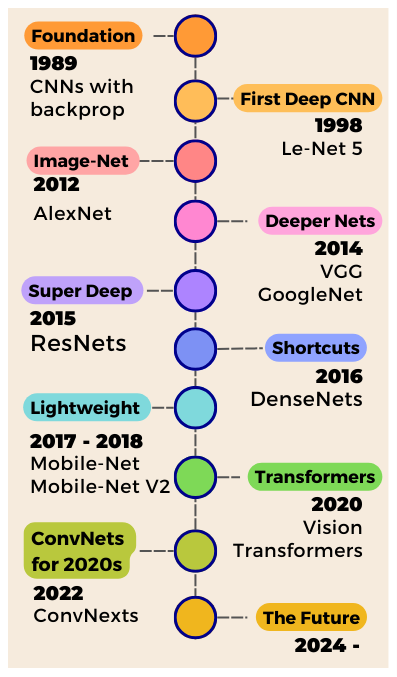
Yann LeCun's 1989 breakthrough with Convolutional Neural Networks preserved spatial image data, revolutionizing Computer Vision research. CNNs use filters to extract feature maps, stacking layers to create powerful image...
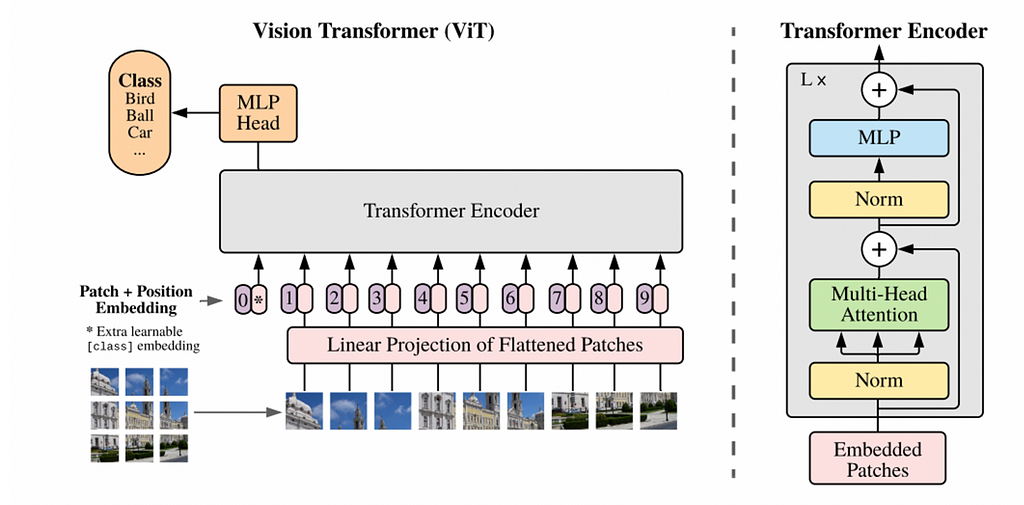
Transformers, known for revolutionizing NLP, now excel in computer vision tasks. Explore the Vision Transformer and Masked Autoencoder Vision Transformer architectures enabling this...
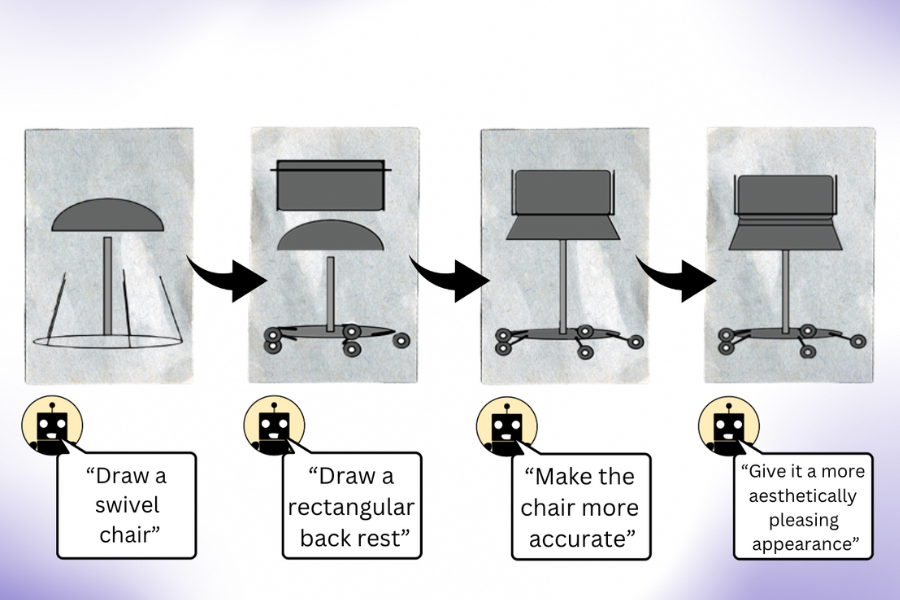
MIT researchers found that large language models can understand the visual world and generate complex scenes. By querying LLMs to self-correct code for images, they improved simple drawings and trained a vision system without using visual...
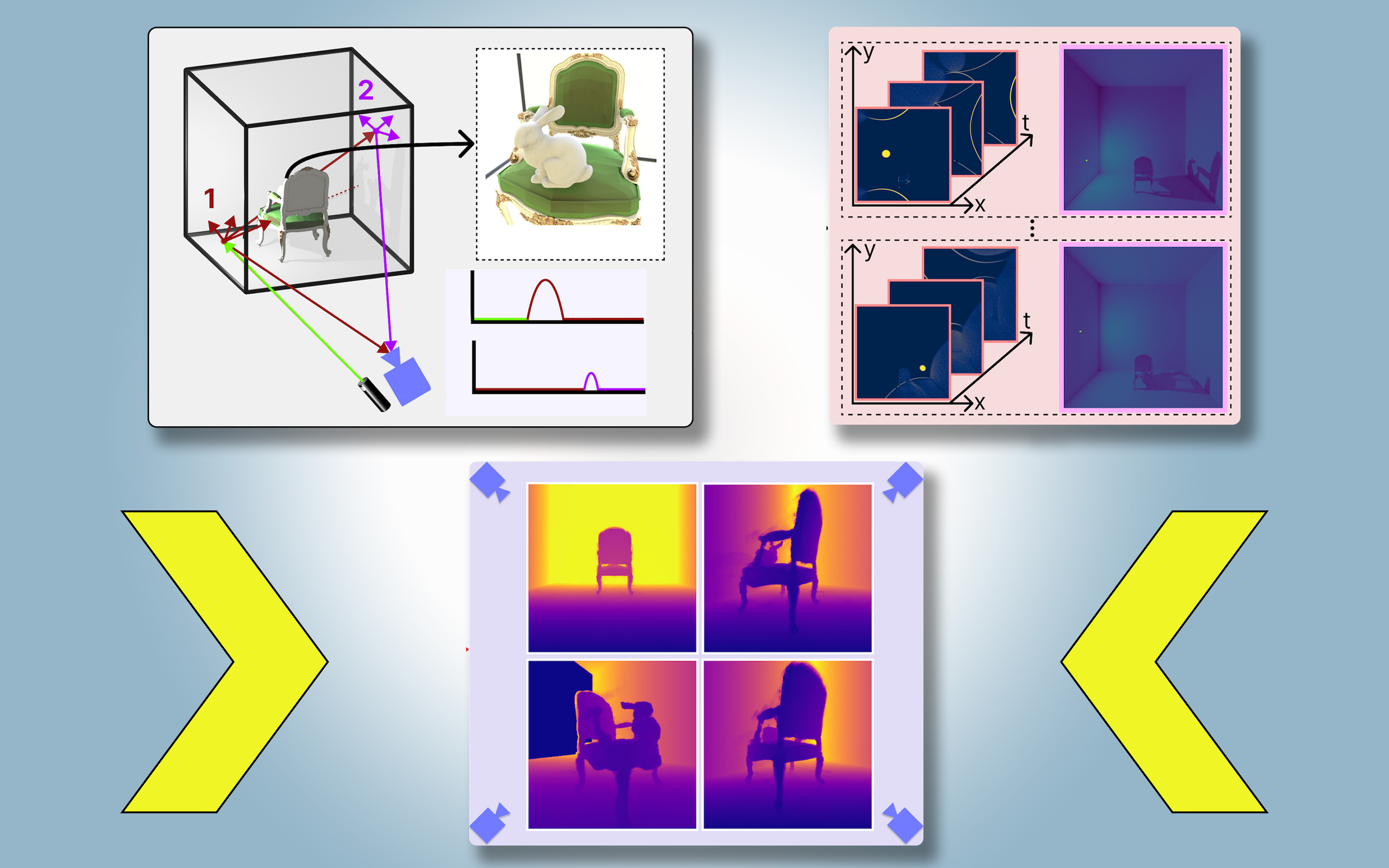
MIT and Meta researchers develop PlatoNeRF, a computer vision technique using shadows and machine learning to create accurate 3D models of scenes, improving autonomous vehicles and AR/VR efficiency. Combining lidar and AI, PlatoNeRF offers new opportunities for reconstructions and will be presented at the Conference on Computer Vision and Pattern...
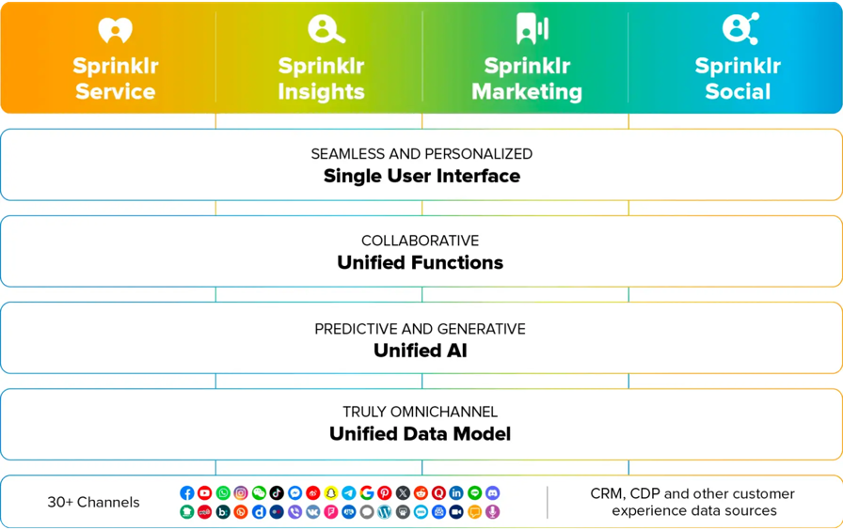
Sprinklr utilizes AI to enhance customer experience, achieving 20% throughput improvement with AWS Graviton3 for cost-effective ML inference. Thousands of servers fine-tune and serve over 750 AI models across 60+ verticals, processing 10 billion predictions...

Scientists are using AI to identify advanced materials for solar cells. MIT engineers develop a computer vision technique to speed up material characterization by 85 times, aiming for fully automated materials...
Choosing the right AI use case is crucial for success. AI can be valuable even with moderate performance, offering unique solutions. Examples include Sensor Fusion and Generative AI in everyday...

Scientists at MIT and the MIT-IBM Watson AI Lab have developed a new approach to teach computers to pinpoint actions in videos using only transcripts. This method, called spatio-temporal grounding, improves accuracy in identifying actions in longer videos and could have applications in online learning and...
Discover the groundbreaking research by XYZ Company on the development of a new AI technology that can revolutionize the healthcare industry. Learn how this innovation is set to improve patient care and diagnosis...

New study reveals groundbreaking AI technology developed by Google, revolutionizing data analysis in healthcare. Findings show significant increase in accuracy and efficiency of diagnosing rare...

Discover the groundbreaking collaboration between Tesla and SpaceX, revolutionizing electric vehicles and space travel. Explore how their innovative technologies are shaping the future of...
Discover how Tesla's new self-driving technology is revolutionizing the automotive industry. With advanced AI algorithms and cutting-edge sensors, Tesla is paving the way for autonomous...
Discover how Company X revolutionized the tech industry with its groundbreaking AI technology. Find out how their product has disrupted traditional business models and set new standards for...
Discover how innovative startups are revolutionizing the tech industry with cutting-edge products. From AI-powered solutions to sustainable technologies, these companies are reshaping the...

Discover the groundbreaking collaboration between Tesla and SpaceX in developing innovative renewable energy solutions. Explore how Elon Musk's vision is revolutionizing the future of transportation and space...

Discover the latest groundbreaking research on AI technology by leading companies like Google and IBM. Learn about the potential impact on various industries and the future of artificial...

3D Gaussian splatting, a new method for novel view synthesis, is challenging NeRFs as the predominant technique for 3D scene representation. This technique utilizes anisotropic Gaussians to render crisp 3D models in real-time, providing a unique approach to scene representation and image...

Recent advancements in AI, including GenAI and LLMs, are revolutionizing industries with enhanced productivity and capabilities. Vision transformer architectures like ViTs are reshaping computer vision, offering superior performance and scalability compared to traditional...

Access Sun RGB-D dataset for 3D understanding from 2D images. Dataset includes indoor scenes with 2D and 3D annotations from various 3D scanners. Explore Python code to access this valuable resource for deeper ML...

MIT researchers developed a dataset to simulate peripheral vision in AI models, improving object detection. Understanding peripheral vision in machines could enhance driver safety and predict human behavior, bridging the gap between AI and human...

Article highlights deploying ML models in the cloud, combining CS and DS fields, and overcoming memory limitations in model deployment. Key technologies include Detectron2, Django, Docker, Celery, Heroku, and AWS...
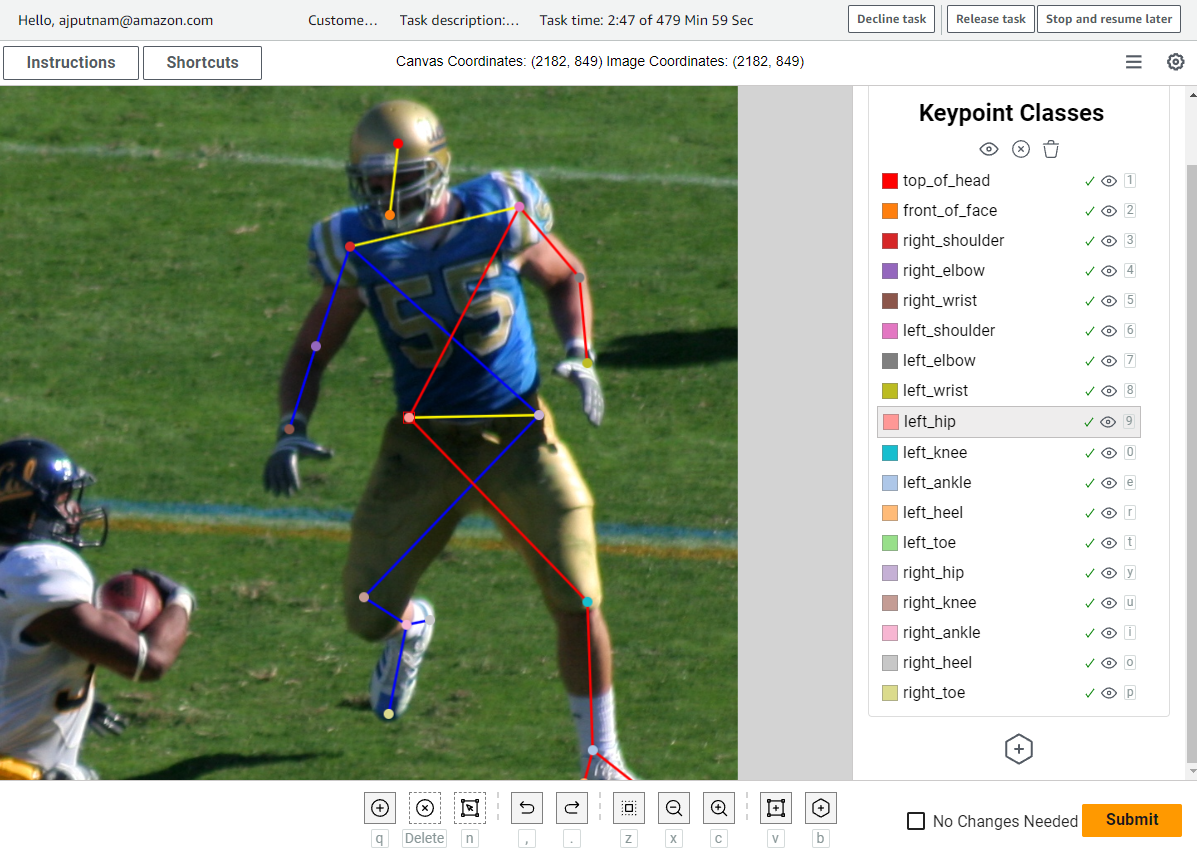
This article discusses the importance of high-quality data and reducing labeling errors in pose estimation models. It demonstrates how a custom labeling workflow in Amazon SageMaker Ground Truth can streamline the labeling process and minimize errors, ultimately reducing the cost of obtaining accurate pose...
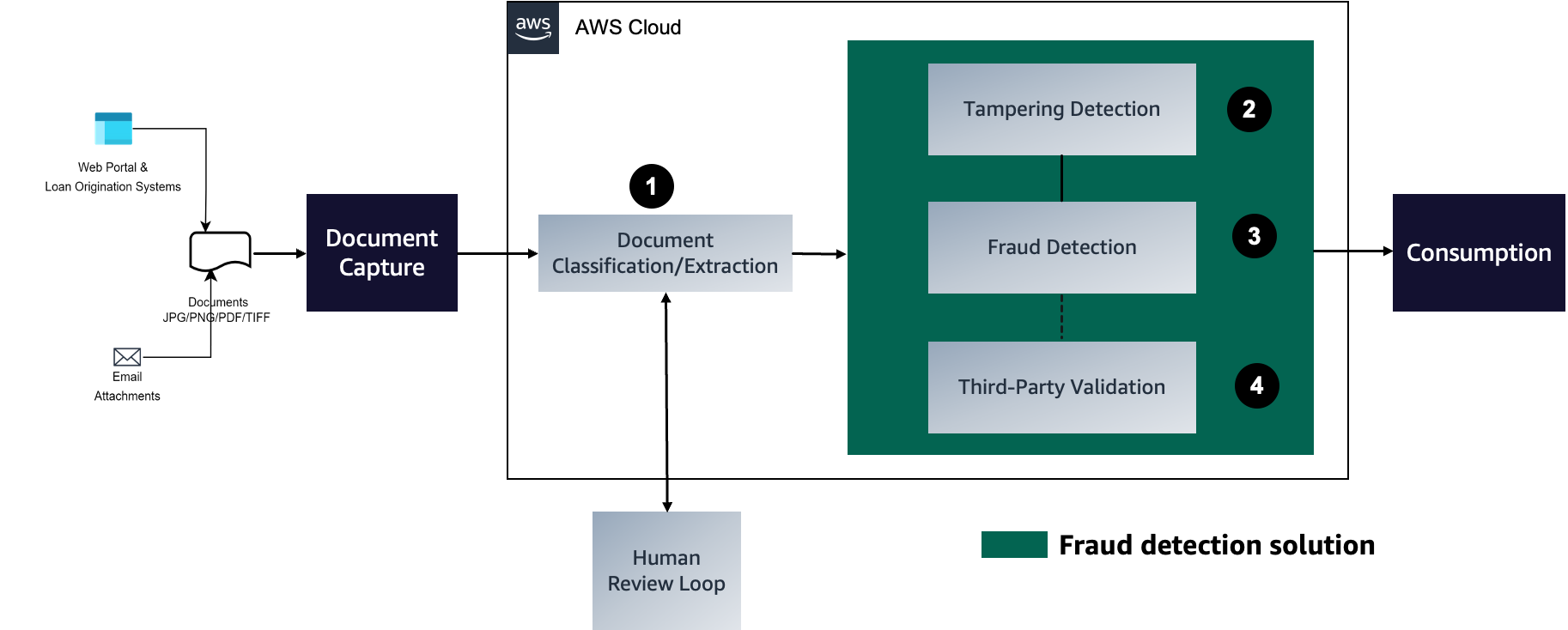
Automate mortgage document fraud detection using ML models and business-defined rules with Amazon Fraud Detector, a fully managed fraud detection service. Upload historical data, train the model, review performance, and deploy the API to make predictions for improved fraud detection and underwriting...
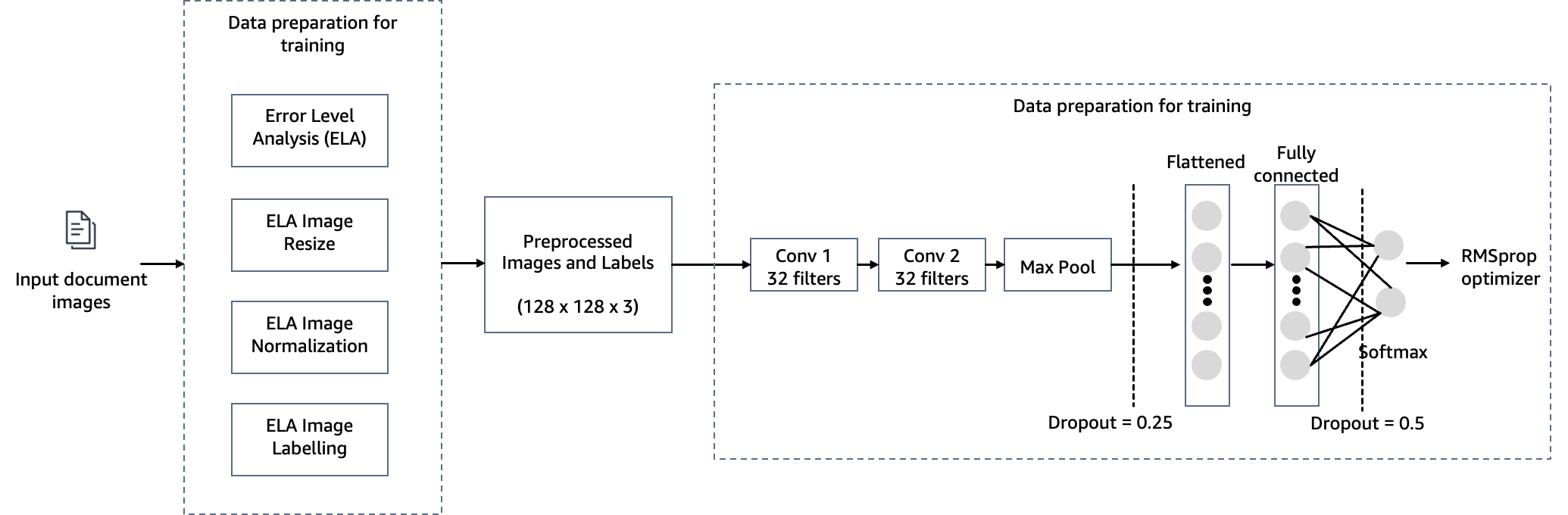
Automate detecting document tampering and fraud at scale using AWS AI and machine learning services for mortgage underwriting. Develop a deep learning-based computer vision model to detect and highlight forged images in mortgage underwriting using Amazon...

AI technology has the ability to transform food images into recipes, allowing for personalized food recommendations, cultural customization, and automated cooking execution. This innovative method combines computer vision and natural language processing to generate comprehensive recipes from food images, bridging the gap between visual depictions of dishes and symbolic...
MIT's Improbable AI Lab has developed a multimodal framework called HiP, which uses three different foundation models to help robots create detailed plans for complex tasks. Unlike other models, HiP does not require access to paired vision, language, and action data, making it more cost-effective and...
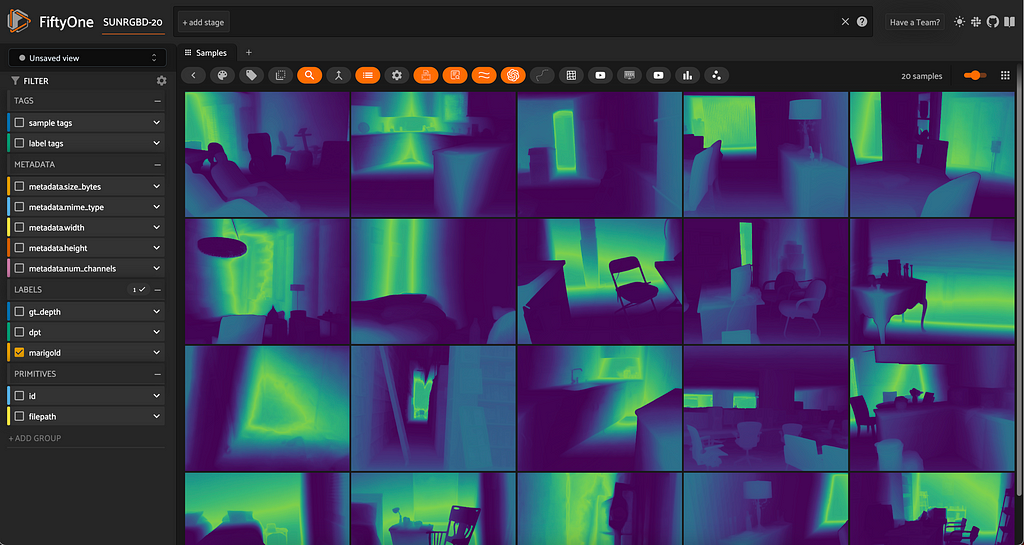
This article explores monocular depth estimation (MDE) and its importance in computer vision applications. It provides a walkthrough on loading and visualizing depth map data, running inference with Marigold and DPT, and evaluating depth predictions using the SUN RGB-D...

The article explores the use of lightweight hierarchical vision transformers in autonomous robotics, highlighting the effectiveness of a shared trunk concept for multi-task learning. It also discusses the emergence of large multimodal models and their potential to create a unified architecture for end-to-end autonomous driving...

Computer vision has evolved from small pixelated images to generating high-resolution images from descriptions, with smaller models improving performance in areas like smartphone photography and autonomous vehicles. The ResNet model has dominated computer vision for nearly eight years, but challengers like Vision Transformer (ViT) are emerging, showing state-of-the-art performance in computer...

The PGA TOUR is developing a next-generation ball position tracking system using computer vision and machine learning techniques to locate golf balls on the putting green. The system, designed by the Amazon Generative AI Innovation Center, successfully tracks the ball's position and predicts its resting...

2024 could be the tipping point for Music AI, with breakthroughs in text-to-music generation, music search, and chatbots. However, the field still lags behind Speech AI, and advancements in flexible and natural source separation are needed to revolutionize music interaction through...
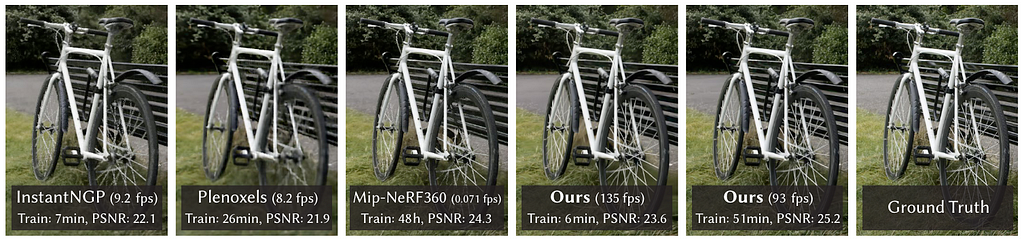
Gaussian splatting is a fast and interpretable method for representing 3D scenes without neural networks, gaining popularity in a world obsessed with AI models. It uses 3D points with unique parameters to closely match renders to known dataset images, offering a refreshing alternative to complex and opaque methods like...

Autonomous machines in robotics showcased their capabilities in 2023, with notable mentions including Glüxkind's AI-powered smart stroller, Soft Robotics' mGripAI system for food packing, and Quanta's TM25S robot for product inspection, all utilizing NVIDIA...

ICL, a multinational manufacturing and mining corporation, developed in-house capabilities using machine learning and computer vision to automatically monitor their mining equipment. With support from the AWS Prototyping program, they were able to build a framework on AWS using Amazon SageMaker to extract vision from 30 cameras, with the potential to scale to...