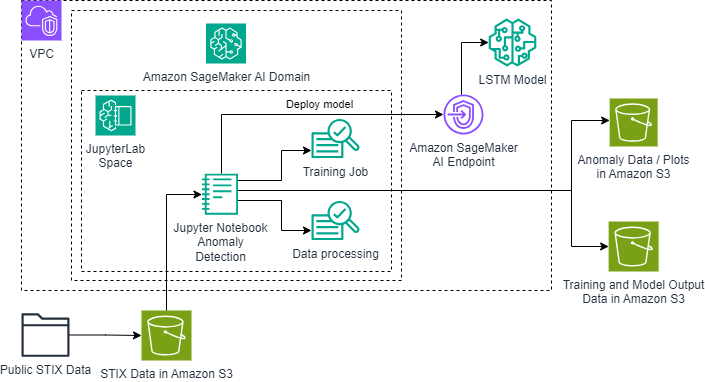
Sophisticated machine learning aids in detecting solar flares through analysis of X-ray emissions. Advanced deep learning models like LSTM networks enable robust anomaly detection in multi-channel X-ray data for comprehensive solar activity...
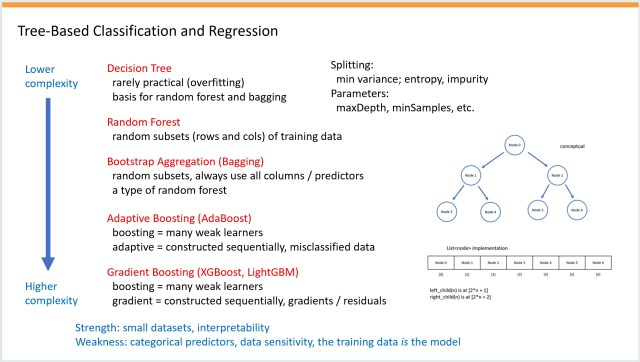
Summary: A detailed PowerPoint presentation on neural networks evolved to include tree-based techniques. Three sci-fi movie plots involving memory are also reviewed and...
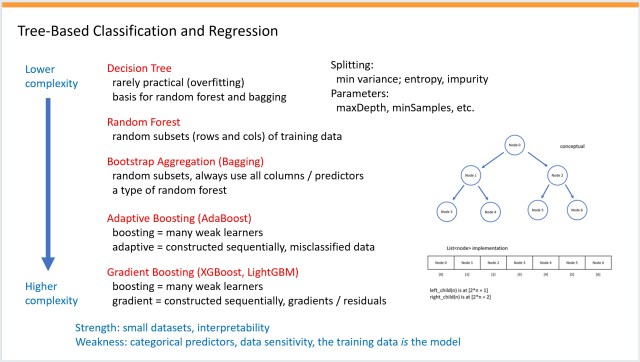
A comprehensive PowerPoint presentation on neural networks expanded to include tree-based techniques, named "KitchenSink." Science fiction movies with memory themes are creatively graded by the...

Advanced neural network architecture CPTR combines ViT encoder with Transformer decoder for image captioning, improving upon earlier models. CPTR model uses ViT for encoding images and Transformer for decoding captions, enhancing image captioning...

Transformers are revolutionizing NLP with efficient self-attention mechanisms. Integrating transformers in computer vision faces scalability challenges, but promising breakthroughs are on the...

AI advancements have merged NLP and Computer Vision, leading to image captioning models like the one in "Show and Tell." This model combines CNN for image processing and RNN for text generation, using GoogLeNet and...
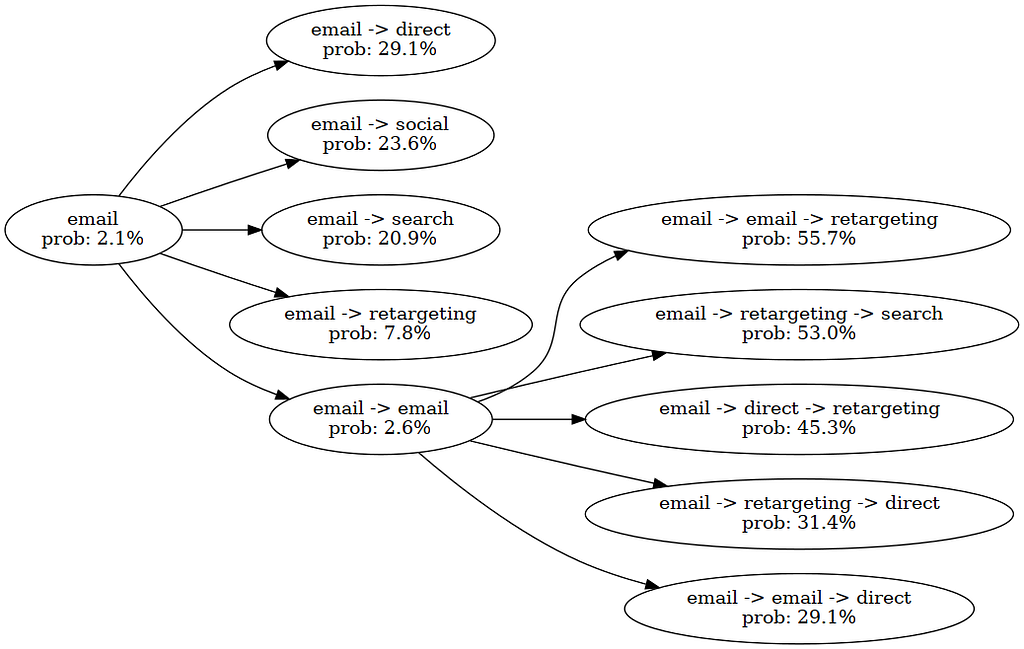
ML models can design optimal customer journeys by combining deep learning with optimization techniques. Traditional attribution models fall short due to position-agnostic attribution, context blindness, and static channel...

LSTMs, introduced in 1997, are making a comeback with xLSTMs as a potential rival to LLMs in deep learning. The ability to remember and forget information over time intervals sets LSTMs apart from RNNs, making them a valuable tool in language...