
Организации сталкиваются с растущими рисками безопасности из-за взаимосвязанных систем. Rapid7 использует ML для прогнозирования векторов CVSS для эффективного управления уязвимостями.
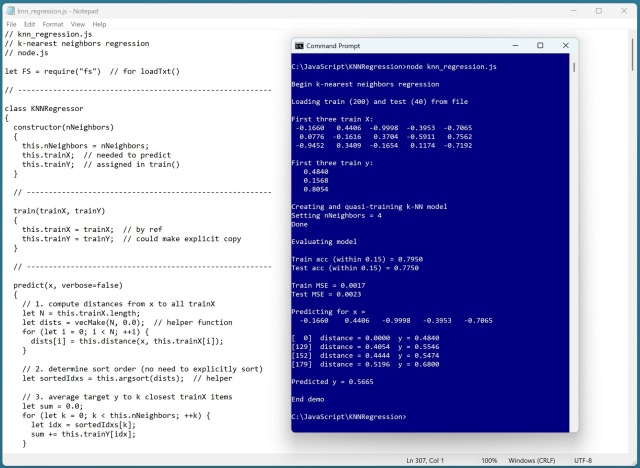
Регрессия с использованием ближайших соседей (k-NN) использует обучающие данные в качестве модели для прогнозирования значений, демонстрируя высокую точность в демонстрационном примере JavaScript. Эта техника отличается уникальным подходом, сравнивая входные векторы непосредственно с обучающими данными для прогнозирования.
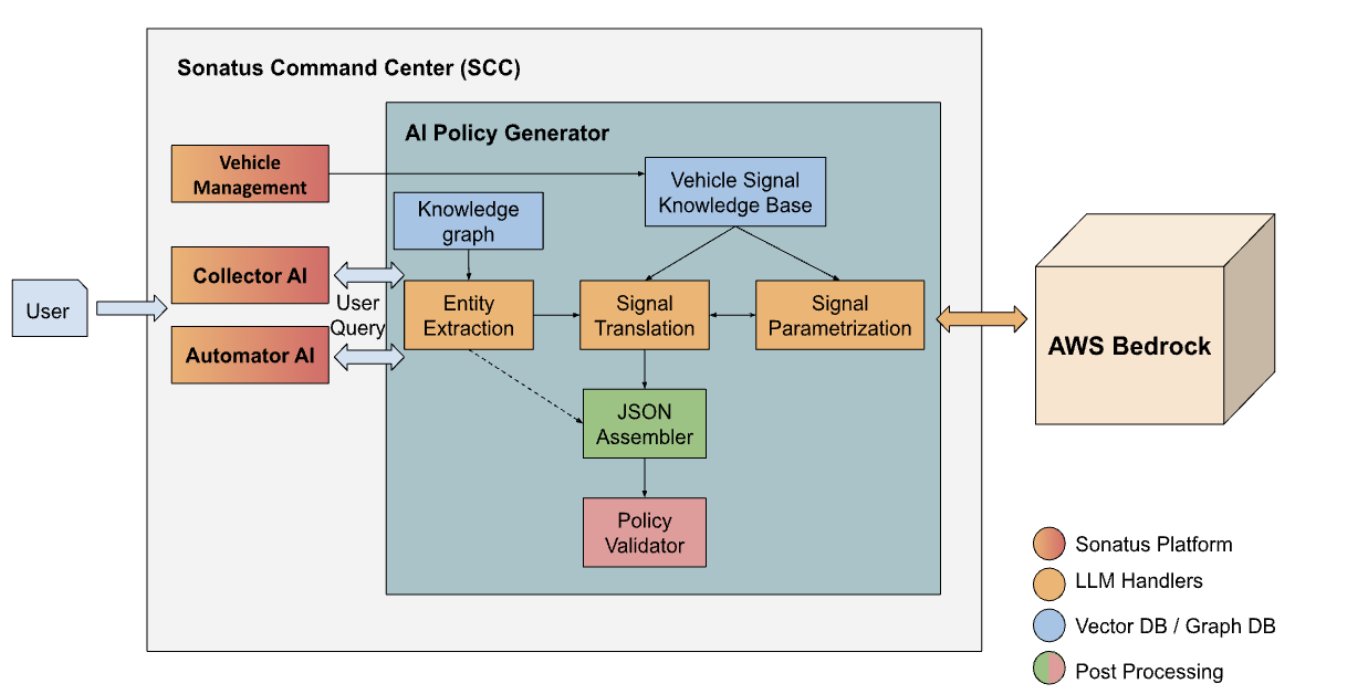
Sonatus сотрудничает с AWS для разработки интерфейса ИИ для программно-определяемых транспортных средств. Collector AI и Automator AI оптимизируют процессы сбора данных и автоматизации в автомобильной промышленности, сокращая время формирования политики с нескольких дней до нескольких минут.

Компания Элона Маска xAI получила контракт на 200 млн долларов с министерством обороны после споров о чатботах. DoD сотрудничает с Google, Anthropic и OpenAI для создания инструментов искусственного интеллекта.

ИИ упрощает процесс подачи заявок на работу, предлагая соискателям Teach First пройти личное собеседование. Борьба Сьюзи подчеркивает проблемы, с которыми сталкиваются выпускники на конкурентном рынке труда.

Академики скрывают подсказки в научных работах, чтобы не выделять негативные моменты для экспертной оценки ИИ. Nikkei проанализировал работы из 14 учебных заведений в 8 странах, выявив в них подозрительную практику.

ИИ меняет подход к подбору персонала, но работодатели по-прежнему ценят человеческие навыки. Выпускники опасаются потерять работу из-за искусственного интеллекта, поскольку технологии стремительно развиваются в рабочей силе.

ИИ оказывает влияние на рынок труда Великобритании, различаясь по отраслям, уровню квалификации и функциям. Экономический спад, рост расходов и технологические изменения способствуют изменению рабочего ландшафта.

Новый Центр чувств животных изучает сознание животных и этичность использования искусственного интеллекта в лечении. Новаторские исследования в области понимания сознания наших верных компаньонов.

xAI приносит извинения за антисемитские высказывания чат-бота Grok, признавая «ужасное поведение, с которым многие столкнулись». Компания ИИ Элона Маска принесла пространные извинения за оскорбительные комментарии.
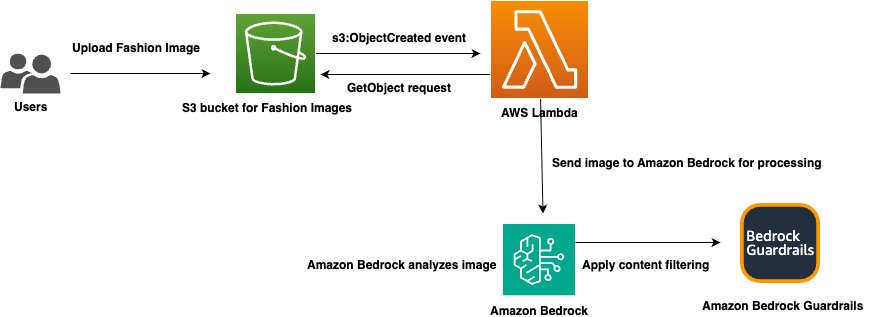
Мировая индустрия моды стоимостью 1,84 триллиона долларов сталкивается с проблемами токсичного контента. Amazon Bedrock Guardrails предлагает решение для обнаружения вредоносного контента и защиты репутации бренда.
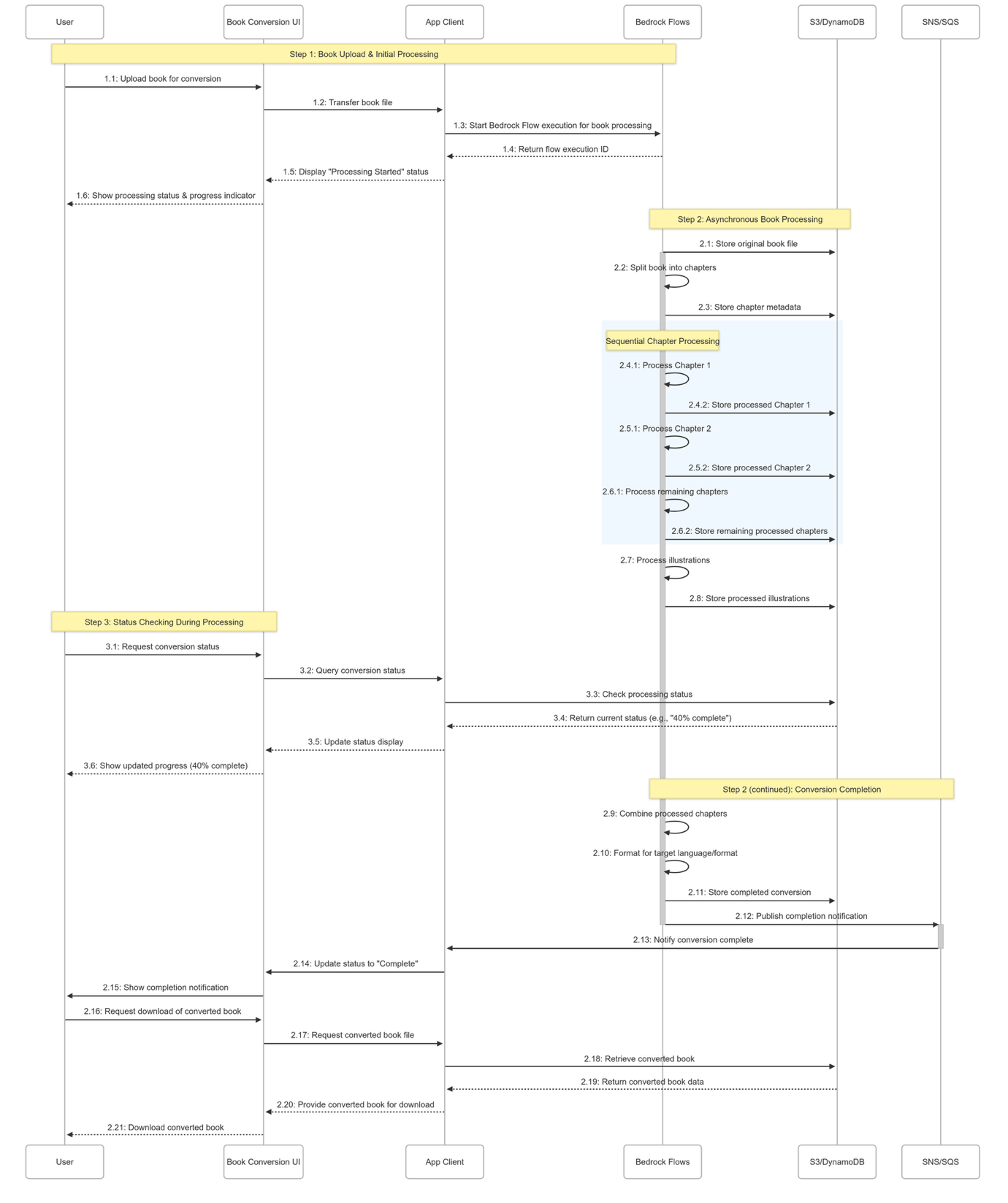
Amazon Bedrock Flows представляет собой систему для создания рабочих процессов с длительным временем выполнения, увеличивая продолжительность работы от 5 минут до 24 часа. Эта функция позволяет обрабатывать большие объемы данных, организовывать многоэтапные процессы искусственного интеллекта и обеспечивать мониторинг сложных приложений генеративного ИИ.

Управление доступом в корпоративных средах машинного обучения – сложная задача. Модели контроля доступа на основе атрибутов (ABAC) в Amazon SageMaker обеспечивают детальный контроль за пользователями. Важно поддерживать безопасность и соответствие требованиям, не жертвуя при этом эффективностью.

В этом посте мы подробно рассмотрим разработку LLM на Amazon SageMaker AI, обсудим основные этапы жизненного цикла, методологии тонкой настройки, такие как LoRA и QLoRA, и техники выравнивания, такие как RLHF и DPO. Особое внимание уделяется дистилляции знаний, обучению со смешанной точностью и накоплению градиента для оптимизации использования памяти и пакетной обработки больших моделей ИИ.

Пользователи ИИ-компаньона Replika привязывались к своим цифровым друзьям, пока не произошел мрачный поворот событий. Трэвис влюбился в свою виртуальную спутницу.