Моделі генеративного ШІ, такі як DALL-E від OpenAI, можуть стати поштовхом до нових розробок. CSAIL з Массачусетського технологічного інституту використовував GenAI для створення роботів, які стрибають на 41% вище.

Массачусетський технологічний інститут та Стенфордський університет розробляють SketchAgent - систему штучного інтелекту, яка створює ескізи штрих за штрихом на основі підказок природною мовою. Інструмент має на меті докорінно змінити спосіб спілкування людини зі штучним інтелектом завдяки більш природному та ітеративному процесу малювання.

Google DeepMind представив AlphaEvolve - систему штучного інтелекту, яка еволюціонує код, відкриваючи нові алгоритми для кодування та аналізу даних. Використовуючи генетичні алгоритми та Gemini Llm, AlphaEvolve підказує, мутує, оцінює та створює код для оптимальних рішень.

GlitterGPT, яскравий стиліст GPT-4, привів до несподіваних висновків про поведінку LLM, ритуали спонукання та емоційний резонанс. Грайливий експеримент перетворився на дослідження того, як великі мовні моделі поводяться більше як істоти, ніж як інструменти, кидаючи виклик поняттю душевної взаємодії.

Deb8flow використовує ШІ-агентів, таких як «За» і «Проти», для автономних дебатів, з перевіркою фактів і модерацією в режимі реального часу. Удосконалена архітектура використовує LangGraph та GPT-4o, гарантуючи, що дебати залишаються заснованими на правді.

Дослідники Массачусетського технологічного інституту та NVIDIA розробили HART - гібридний інструмент генерації зображень, який поєднує авторегресійну та дифузійну моделі для створення високоякісних зображень у дев'ять разів швидше. Інноваційний підхід HART може зробити революцію у навчанні безпілотних автомобілів та створенні сцен у відеоіграх.

Професор Вандербільта вчить сина використовувати ChatGPT і Dall-E для практичного застосування ШІ, трансформуючи повсякденні завдання та навчання. Син Уайта тепер вправно інтегрує штучний інтелект у повсякденне життя - від створення ігор до перевірки фактів у Книзі рекордів Гіннеса.

Мультимодальність у штучному інтелекті змінює досвід користувачів. BLIP-2 від Salesforce покращує візуально-мовне узгодження для покращення завдань з міркування.

Дифузійні моделі, такі як Stable Diffusion і DALL-E, продемонстрували вражаючу якість генерації зображень. Такі технології, як Dreambooth і Lora, дозволяють налаштовувати моделі з мінімальними зусиллями, що дає змогу моделям швидко засвоювати нові концепції.

Дізнайтеся про ентропію в науці про дані, кількісну оцінку несподіванки та невизначеності, а також про практичні застосування - від прийняття рішень до різноманітності ДНК. Вивчайте веселі головоломки та підручники, які не потребують попередніх знань.

6-річний кейс Shopify розкриває тонкий баланс між фокусуванням на продукті та диверсифікацією для оптимального успіху в бізнесі. Дізнайтеся, як розуміння концентрації у вашому продуктовому портфелі впливає на прийняття важливих рішень, за допомогою практичних стратегій та інтерактивних візуалізацій.

Інструменти штучного інтелекту стали частиною нашого повсякденного життя з моменту появи програми перевірки орфографії в 1979 році. Сьогоднішня розмова про штучний інтелект - це лише наступний крок на довгому шляху, на якому вже є інструменти лівої півкулі, такі як НЛП і машинне навчання, і інструменти правої півкулі, такі як генеративний ШІ.

Частина 2 досліджує особливості програмування музичного інструменту на Raspberry Pi Pico PIO. Частина 5 розкриває проблеми з константами, закликаючи до творчих обхідних шляхів.

Практичні проекти машинного навчання показують, які труднощі виникають при переході до виробництва. Оптимізуйте продуктивність моделі, узгодивши функції втрат і метрики з бізнес-пріоритетами.

Стрімке зростання генеративного ШІ створює екологічні проблеми через високе споживання енергії та води. Експерти Массачусетського технологічного інституту працюють над тим, щоб зменшити вуглецевий слід ШІ та інші впливи.

Порогове значення є ключовим методом управління невизначеністю моделі в машинному навчанні, що дозволяє втручатися людині в складних випадках. У контексті виявлення шахрайства порогове значення допомагає збалансувати точність і ефективність, відкладаючи невизначені прогнози для перевірки людиною, що сприяє підвищенню довіри до системи.

Paligemma VLM від Google поєднує в собі кодер технічного зору та мовну модель для таких завдань, як розпізнавання об'єктів. Paligemma може обробляти зображення з різною роздільною здатністю та ідентифікувати об'єкти без тонкого налаштування, але Google рекомендує тонке налаштування для специфічних завдань.

Короткий опис статті: Дослідження проблеми рюкзака в аналітиці продукту, від маркетингових кампаній до оптимізації торгових площ. Дізнайтеся про її вирішення за допомогою лінійного програмування для прийняття обґрунтованих рішень.

Воркшоп для керівників під керівництвом консультанта з науки про дані допомагає компаніям ефективно інтегрувати АІ. На воркшопі представлено план успішної стратегії, який може бути застосований у будь-якій галузі.

Дослідники з Массачусетського технологічного інституту розробили методику під назвою Score Distillation, яка дозволяє створювати високоякісні 3D-форми з 2D-моделей генерації зображень, покращуючи реалістичність без дорогого перенавчання. Цей прорив розширює потенціал ШІ для допомоги дизайнерам у створенні реалістичних 3D-моделей, представлений на Конференції з нейронних систем обробки інформації.

Короткий зміст: Розробник ділиться досвідом застосування НЛП-моделі для обробки документів чеською мовою, зосереджуючись на ідентифікації об'єктів. Модель була навчена на 710 PDF-документах з використанням ручного маркування та уникненням підходів на основі обмежувальних рамок для підвищення ефективності.

Розробка штучного інтелекту для гри в рулетку з оптимізованою швидкістю та ефективністю використання пам'яті. Створити універсальну систему оцінки рук для гри в рулетку, адаптовану до різних стратегій і комбінацій карт.

Розв'язки в замкненій формі досліджуються в дуелі між Python та італійською математикою епохи Відродження. Дізнайтеся, коли рівняння можна розв'язати і як обманути, використовуючи SymPy для знаходження виразів у замкненому вигляді. Дізнайтеся, які рівняння протистоять закритим розв'язкам, а також які комбінації слід уникати.

Трансформаторна архітектура покращує продуктивність моделі, вирішуючи проблеми довгострокових залежностей за допомогою механізму самоуваги. Позиційні вбудовування кодують структуру послідовності, покращуючи здатність моделі розуміти порядок у даних.

Анотація: Підхід GNN до прогнозування голосів і нот для гравіювання партитури вирішує проблему розділення нот на голоси і нотні знаки, що має вирішальне значення для створення зручних для читання нотних партитур. Система має на меті покращити читабельність транскрибованої музики, особливо складних фортепіанних творів, шляхом покращення розділення нот на ноти та голоси.
OpenAI випустила ранню версію програми ChatGPT для Windows для передплатників, позиціонуючи її як бета-тест. Користувачі можуть отримати доступ до різних моделей, генерувати зображення за допомогою DALL-E 3 та аналізувати файли.

Методологи - це міждисциплінарні фахівці, які використовують різні підходи для пошуку найкращих рішень. Вони мають допитливий склад розуму, швидко навчаються та творчо мислять, щоб вирішувати складні проблеми в інноваційний спосіб.

Дізнайтеся, як перенести проекти Rust у середовище nostd для вбудованих пристроїв, долаючи унікальні проблеми та обмеження. Дотримуйтесь дев'яти правил для спрощення процесу, включаючи використання функцій Cargo та попередньо розподілених типів даних.

Google Colab, інтегрований з інструментами генеративного ШІ, спрощує програмування на Python. Вивчайте Python легко і без встановлення завдяки доступним функціям Google Colab.

Дізнайтеся, як запускати Rust-код у браузері за допомогою WebAssembly, надаючи динамічним веб-сторінкам переваги конфіденційності. Дотримуйтесь дев'яти правил для перенесення коду на WASM у браузері, щоб забезпечити успішне впровадження та інтеграцію.

Мистецтво штучного інтелекту стрімко розвивається завдяки таким інструментам, як Dall-E 3 та Adobe's Creative Cloud, що дозволяють миттєво перетворювати текст на зображення. Люди залишаються центральним елементом мистецтва ШІ завдяки інноваційним іграм на кшталт Eat Poop You Cat, що демонструють творчий потенціал алгоритмів.

Системи ШІ, як і ті, що використовують векторні вбудовування та LLM, за своєю природою є недосконалими через втрату інформації. Щоб вирішити цю проблему, включення структурованих процесів і метаданих може допомогти зменшити втрати і підвищити точність системи.

Дізнайтеся, як запускати Rust-код в обмежених середовищах, таких як браузери або вбудовані системи, за допомогою WASM WASI. Дотримуйтесь дев'яти правил для успішного перенесення коду, включаючи розуміння цілей Rust, умовну компіляцію та навігацію в питаннях залежностей.

Дізнайтеся, як створити планувальник харчування за допомогою ChatGPT на Python, спростивши рішення щодо харчування та покупок продуктів. Використовуйте методи швидкого проектування, щоб максимізувати можливості ChatGPT, роблячи планування харчування простішим та ефективнішим.

Data Scientist ділиться інсайдами з реалізованих проектів, включаючи прогнозування використання сервісів за допомогою моделі Tabnet з налаштуванням гіперпараметрів за допомогою Optuna. Зосередьтеся на реальних прикладах для науковців-початківців та детальних інсайтах для досвідчених розробників.

Резюме: Аналіз моделей виступів у семиборстві та десятиборстві розкриває інтригуючу інформацію про важливість змагань і системи підрахунку очок. Дані показують значні відмінності в отриманих балах, проливаючи світло на вплив різних результатів на змаганнях елітного рівня.

2024: Поява агентів нового покоління, таких як MultiOn, LangGraph та LlamaIndex Workflows. Агенти другого покоління пропонують структуровані шляхи для більш потужних можливостей, відходячи від невдалих агентів ReAct.

Великі мовні моделі від Anthropic, OpenAI та Meta демонструють чітку стратегічну поведінку в змодельованому середовищі ризику, причому Claude Sonnet 3.5 має невелику перевагу. Здатність бакалаврів мислити і діяти стратегічно має вирішальне значення, оскільки ми інтегруємо їх у наше повсякденне життя, порушуючи важливі питання про їхні стратегічні можливості та майбутній розвиток.

Polars кидає виклик пандам в обробці даних на Python з чудовою продуктивністю, використовуючи Rust для паралельної обробки. Потенційно Polars може перевершити панди у 25 разів, але потребує більше vCPU для досягнення оптимальної швидкості.

ШІ може створювати зображення і звуки одночасно, наприклад, гавкіт коргі. Дослідники з Мічиганського університету вивчають цю революційну концепцію.

Синтетичні дані викликають занепокоєння щодо колапсу моделей при розробці ШІ, але дослідження можуть не відображати реальні практики та досягнення. Відсутність стандартних методів пом'якшення наслідків і контролю якості в дослідженні обмежує його застосовність до галузевих сценаріїв.

Black Forest Labs представляє моделі ШІ FLUX.1 для перетворення тексту в зображення після того, як інженери покинули компанію Stability AI через проблеми з продуктивністю. Компанія пропонує високоякісні, середні та швидкісні версії, заявляючи про чудову якість зображень і точність розпізнавання тексту.

Data Science Consulting: Подолання викликів у середовищі спільної роботи. Стратегії для успішної реалізації проектів. Усунення непорозумінь, браку розуміння та низької продуктивності.

LLM показують багатообіцяючі результати в оцінці генерації SQL, з оцінками F1 0.70-0.76 при використанні GPT-4 Turbo. Включення інформації про схему зменшує кількість помилкових спрацьовувань.

Правила форматування Master Cargo.toml, щоб уникнути розчарувань. Послідовність Rust у порівнянні з JavaScript, а також несподіванки у Cargo.toml, які пояснюються у 9 ватах та ватманах.

Машинне навчання чудово підходить для прогнозування, але не для пояснення причинно-наслідкових зв'язків. Причинно-наслідкові зв'язки мають вирішальне значення для розуміння та впливу на результати.
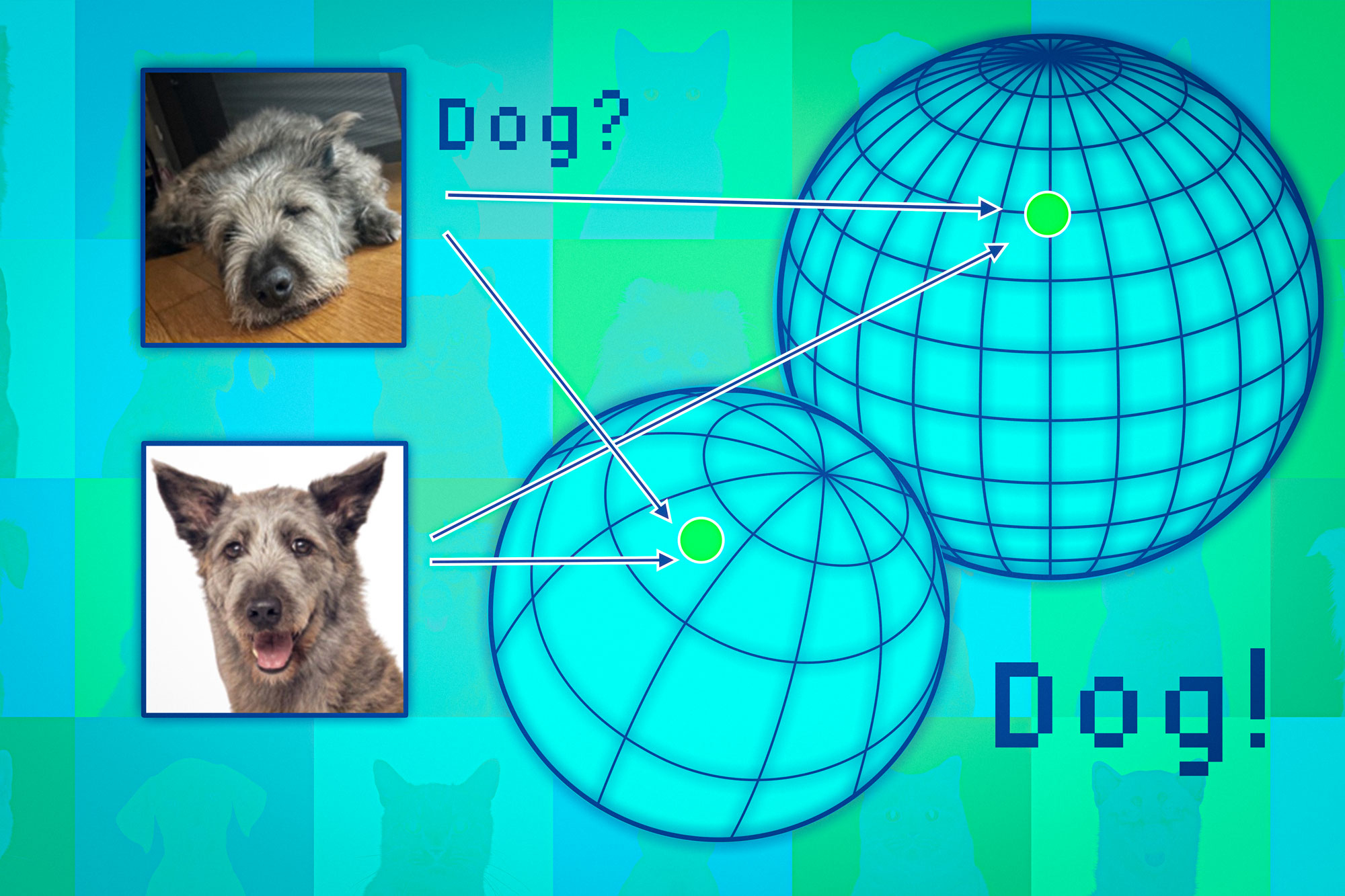
Дослідники з Массачусетського технологічного інституту та лабораторії штучного інтелекту MIT-IBM Watson AI Lab розробили методику оцінки надійності фундаментальних моделей, таких як ChatGPT і DALL-E, перед розгортанням. Навчивши набір дещо різних моделей і оцінивши їхню узгодженість, вони можуть ранжувати моделі на основі показників надійності для різних завдань.

Проривний DQN Мегаакорд "Веселка" поєднує в собі 6 потужних варіантів DQN для оптимальної продуктивності в глибокому навчанні з підкріпленням. Бібліотека Stoix розбиває компоненти Rainbow, включаючи алгоритм DQN та реалізацію нейронної мережі.

Дізнайтеся про метадинаміку та PLUMED в обчислювальній хімії. Вивчіть передові методи відбору проб для дослідження рідкісних подій та повільних процесів у молекулярних системах.

За допомогою предиктивного скорингу лідів компанії можуть прискорити зростання доходів на понад 300% порівняно з традиційними методами. Визначення пріоритетів завдяки машинному навчанню є ключовим для ефективного управління лідами та підвищення коефіцієнта конверсії.

Навчіться легко інтегрувати pyFlink, Kafka та PostgreSQL за допомогою Docker. Долайте виклики та створюйте конвеєр обробки даних в реальному часі для даних з датчиків IoT.

Ефективність продажів часто вимірюється неправильно, що призводить до неточних оцінок. Якість лідів є вирішальним фактором для точної оцінки ефективності роботи торгових агентів.

Нещодавні мультимодальні мережі-трансформери, такі як CLIP і LLaVA, порівнюють з мозком з точки зору уваги. Трансформатори зору виконують попередню візуальну обробку подібно до мозку, але мають проблеми зі складними завданнями. Двонаправлена активність мозку забезпечує свідому увагу зверху вниз і автоматичний зворотній зв'язок, покращуючи сприйняття і пізнання.

Модель синтезу зображень SD3 Medium AI від Stability AI висміяли в мережі за те, що вона генерує анатомічно неправильні зображення людини. Користувачі Reddit критикують невдачі SD3 у відтворенні людських кінцівок, що є кроком назад порівняно з іншими сучасними моделями.

Створення MishnahBot, унікальної RAG-системи для інтерактивного вивчення рабинських текстів. Використання великих мовних моделей для економічно ефективного та модульного пошуку знань.

Штучний інтелект трансформує систему освіти, змінюючи методи оцінювання та сприяючи прозорості для забезпечення навчання, орієнтованого на учня. Продукти генеративного штучного інтелекту, такі як DALL-E і ChatGPT, революціонізують методи викладання, роблячи інформацію більш доступною та полегшуючи ефективне навчання.

На Google I/O 2024 компанія Google представила Veo - нову модель відеосинтезу зі штучним інтелектом, подібну до Sora від OpenAI, яка створює відео у форматі HD з тексту, зображень або відеопідказок. Veo може створювати 1080p-відео тривалістю понад хвилину, редагувати відео за письмовими інструкціями та підтримувати візуальну послідовність між кадрами.

Битва за домінуючий дизайн у технології генеративного штучного інтелекту розпалюється, і тут лідирує ChatGPT. Організації наввипередки інвестують у можливості, які можуть революціонізувати галузі та покращити клієнтський досвід. Розуміння концепції домінуючого дизайну має вирішальне значення для навігації у сфері генеративного ШІ, що швидко розвивається, та прийняття стратегічних рішень щодо т...

Магістри права вдосконалюють свої здібності до міркування, що дозволяє їм планувати та діяти, що призводить до створення захоплюючих шаблонів підказок для агентів, таких як у документі Voyager Paper. Voyager фокусується на тому, щоб спонукати LLMs до виконання відкритих завдань, таких як гра в Minecraft, використовуючи автоматичну навчальну програму, ітеративні підказки та бібліотеку навичок.

LLM, такі як GPT-4 і Claude 3, тестувалися на виявлення аномалій у даних часових рядів, розширюючи межі своїх можливостей. Дослідження мало на меті визначити, чи можуть ці моделі ефективно виявляти рухи в патернах даних.

Уникайте збоїв машинного навчання, дотримуючись найкращих практик одночасного кодування. Одномоментне кодування перетворює категоріальні змінні в двійкові стовпці, покращуючи продуктивність моделі та сумісність з алгоритмами.

Покращене вилучення зв'язків за допомогою Llama3-8B, доопрацьоване з синтетичним набором даних від Llama3-70B. Моделі Llama3 пропонують вражаюче підвищення продуктивності в задачах обробки природної мови.

Нова технологія штучного інтелекту, розроблена компанією Google, революціонізує спосіб взаємодії з комп'ютерами. Революційна система здатна розуміти людські емоції та реагувати на них.

Дізнайтеся, як компанія Х зробила революцію в індустрії завдяки своєму революційному продукту, що мав зруйнувати ринок. Дізнайтеся про дивовижні результати останнього дослідження, проведеного компанією Y щодо передових технологій.

Дізнайтеся, як компанія XYZ зробила революцію в технологічній індустрії завдяки своїй революційній технології штучного інтелекту. Дізнайтеся про вражаючі результати та майбутні наслідки їхнього інноваційного продукту.

Дізнайтеся, як компанія XYZ зробила революцію в галузі завдяки своєму революційному продукту. Дізнайтеся про новітні технології, які змінюють наше уявлення про традиційні методи.

Захоплюючий прорив у технології штучного інтелекту від компанії XYZ революціонізує аналіз даних. Надсучасний алгоритм прогнозує ринкові тенденції з безпрецедентною точністю.

Відкрийте для себе останній прорив у технології штучного інтелекту з новим безпілотним автомобілем Tesla. Революційна для автомобільної індустрії, ця інновація обіцяє безпечніший та ефективніший транспорт.

Дізнайтеся, як інноваційні технологічні компанії, такі як Tesla та SpaceX, революціонізують індустрію, створюючи передові продукти та технології. Дослідіть вплив їхніх досягнень на сталий розвиток, освоєння космосу та транспорт.

У статті "Надзвичайно великі нейронні мережі" представлено шар з малою кількістю воріт (Sparely-Gated Mixture-of-Experts Layer) для підвищення ефективності та якості нейронних мереж. Експерти на рівні токенів з'єднуються за допомогою воріт, що зменшує обчислювальну складність і підвищує продуктивність.

Моделі штучного інтелекту, такі як GPT-4, повинні точно виокремлювати ключові моменти з телефонних дзвінків про прибутки компаній, відображаючи аналіз провідних журналістів. Автоматизація аналізу прибутку може демократизувати розуміння для всіх інвесторів, вирівнявши ігрове поле.

Останні досягнення в галузі штучного інтелекту, включаючи GenAI та LLM, революціонізують галузі завдяки підвищенню продуктивності та можливостей. Архітектури трансформаторів зору, такі як ViTs, змінюють комп'ютерний зір, пропонуючи чудову продуктивність і масштабованість порівняно з традиційними CNN.

Основні LLM, протестовані на числових оцінках, виявляють невідповідності. Шаблони підказок можуть суттєво вплинути на результати, ставлячи під сумнів реальну зручність використання.

Використання ШІ для класифікації макроекономічних настроїв за допомогою CentralBankRoBERTa. Модель визначає емоційний зміст комунікацій центрального банку, виділяючи 5 макроекономічних агентів.

Захід "Шоколадні пригоди Віллі" в Глазго закрився після того, як не зміг виконати пишні обіцянки, згенеровані штучним інтелектом. Відвідувачі залишилися розчаровані скупими декораціями та мінімальною кількістю частувань.

У статті "Пряма оптимізація преференцій" представлено новий спосіб точного налаштування фундаментальних моделей, що призводить до вражаючого зростання продуктивності з меншою кількістю параметрів. Цей метод замінює потребу в окремій моделі винагороди, революціонізуючи спосіб оптимізації LLM.

Stability AI представляє Stable Diffusion 3, передову модель синтезу зображень, яка обіцяє підвищену якість і точність генерації тексту. Сімейство моделей з відкритими вагами охоплює від 800 мільйонів до 8 мільярдів параметрів, що дозволяє локально розгортати їх на різних пристроях і кидати виклик пропрієтарним моделям, таким як DALL-E 3 від OpenAI.

Дізнайтеся, як розв'язувати задачі бінарної класифікації за допомогою байєсівських методів у Python, зосередившись на побудові моделі байєсівської логістичної регресії за допомогою Pyro. Використовуючи набір даних для прогнозування серцевої недостатності з Kaggle, стаття охоплює EDA, інженерію ознак, побудову моделі та оцінювання, висвітлюючи наявність викидів у даних та використання стандарти...

Дізнайтеся, як створювати власні команди IPython Jupyter Magic для покращення роботи з ноутбуком. Використовуйте бібліотеку Hamilton як приклад для покращення ергономіки розробки. Вивчіть можливості лінійної та клітинної магії для динамічної функціональності ноутбука.
Виявлення прихованих дорогоцінних каменів: Оцінка систем RAG за допомогою тесту "голка в стозі сіна

Системи генерації з розширеним пошуком (RAG) мають вирішальне значення для реальних додатків, і тест "Голка в стозі сіна" оцінює їхню ефективність у визначенні конкретної інформації у великому масиві тексту. Відмінності в підказках і моделях можуть суттєво вплинути на результати, що підкреслює необхідність ретельної оцінки під час розробки та розгортання.

Створіть чат-додаток, використовуючи LangChain, LLMs та Streamlit для взаємодії зі складною базою даних SQL. Розширте можливості чат-бота робити SQL-запити та забезпечте зручний інтерфейс з функціями пам'яті за допомогою Streamlit.

У статті обговорюються практичні уроки, отримані під час модернізації біоінформатичної бібліотеки Bed-Reader для читання даних ДНК безпосередньо з хмари. Автор наводить дев'ять правил для додавання підтримки хмарних файлів до програм, включаючи використання об'єкта object_store і створення нового об'єкта під назвою cloud-file.
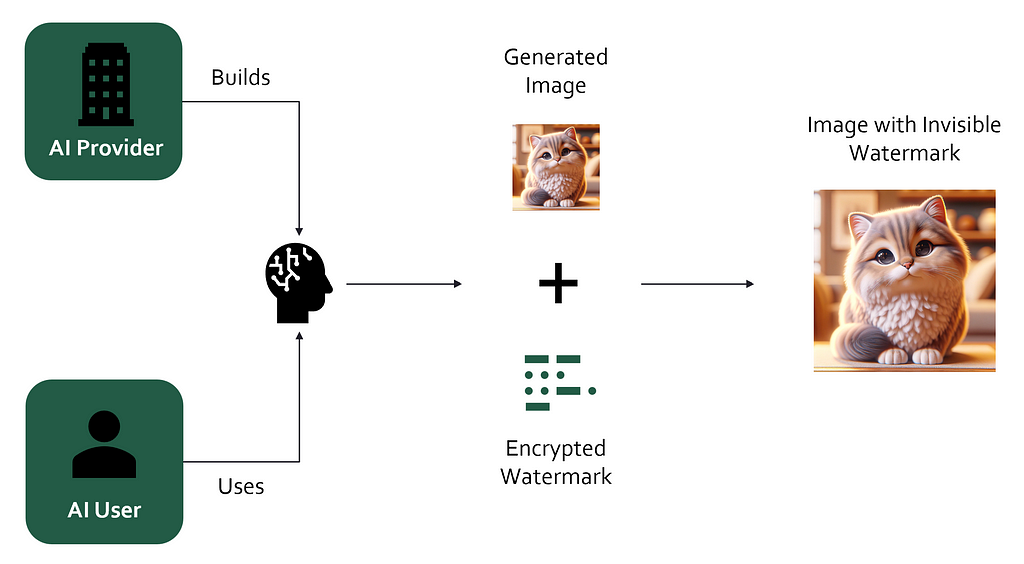
Непомітні водяні знаки пропонують спосіб захистити цифровий контент без шкоди для якості, дозволяючи авторам відстоювати право власності та виявляти контент, створений штучним інтелектом. Такі технологічні компанії, як Meta і Google, розробляють проривні системи водяних знаків, щоб зменшити потік небезпечного контенту, створеного штучним інтелектом, в інтернеті.

У статті обговорюються переваги доповненої генерації пошуку (RAG) для підвищення точності та релевантності моделей ШІ. Підкреслюється важливість моніторингу показників пошуку та оцінки відповіді для усунення несправностей у системах LLM.

У статті обговорюється важливість розуміння контекстних вікон у навчанні та використанні трансформерів, особливо з появою власних LLM і методів, таких як RAG. Досліджується, як різні фактори впливають на максимальну довжину контексту, яку може обробити трансформантна модель, і ставиться питання, чи завжди більше - це краще.

У статті досліджується використання легких ієрархічних трансформаторів зору в автономній робототехніці, підкреслюється ефективність концепції спільної магістралі для багатозадачного навчання. У ній також обговорюється поява великих мультимодальних моделей та їхній потенціал у створенні уніфікованої архітектури для наскрізних рішень автономного водіння.

У цій статті автори обговорюють теорію та архітектуру графових нейронних мереж (ГНМ) і висвітлюють появу графових трансформаторів як тенденцію в графовому МН. Вони досліджують зв'язок між ГНМ і трансформаторами, показуючи, що ГНМ з віртуальним вузлом може імітувати трансформатор, і обговорюють переваги та обмеження цих архітектур з точки зору виразності.

У 2023 році домінували геометричні методи та програми ML, а також помітні прориви в структурній біології, включаючи відкриття двох нових антибіотиків за допомогою GNN. Зростає тенденція до конвергенції методів ML та експериментальних методів в автономному відкритті молекул, а також використання Flow Matching для швидшого та детермінованого відбору зразків.

ШІ нового покоління змінить процес розробки додатків, що призведе до появи нових компаній, які розробляють штучний інтелект, і зменшить залежність від програмного забезпечення, написаного людиною. Зростає популярність великих мовних моделей (LLM) з відкритим вихідним кодом, що дозволяє невеликим фірмам і приватним особам створювати спеціалізовані моделі та революціонізувати програмну інженерію.

OpenAI визнала необхідність використання захищених авторським правом матеріалів при розробці таких інструментів ШІ, як ChatGPT, заявивши, що без цього було б "неможливо". Практика вилучення контенту без дозволу опинилася під пильною увагою, оскільки такі моделі ШІ, як ChatGPT і DALL-E, покладаються на велику кількість навчальних даних із загальнодоступного Інтернету.

Основні тези статті: Руйнівне тестування нейронних мереж та архітектур ML для підвищення надійності. Абляційне тестування визначає критичні частини, зменшує складність і підвищує відмовостійкість. Три типи абляційних тестів: нейронне, функціональне та вхідне абляційне тестування.
У статті обговорюється зростаючий розрив між клінічною практикою і дослідженнями ШІ в охороні здоров'я, підкреслюється недостатня участь і співпраця клініцистів. Вона підкреслює необхідність практичного підходу до виявлення актуальних проблем і оцінки того, чи може ШІ розробити кращі рішення в охороні здоров'я.

Нещодавнє дослідження вивчає, як дерева рішень і випадкові ліси, що широко використовуються в машинному навчанні, страждають від упередженості через припущення про безперервність ознак. У дослідженні пропонуються прості методи для зменшення цієї похибки, а результати показують погіршення продуктивності на 0,2 відсоткових пункти, коли атрибути відображаються дзеркально.
Відкриваємо правду: тестування показників ефективності машинного навчання за допомогою mlscorecheck

У статті розглядається, як за допомогою пакета Python mlscorecheck можна перевірити відповідність результатів машинного навчання та експериментальних налаштувань. Пакет mlscorecheck надає чисельні методи для визначення того, чи можуть отримані результати бути результатом заявленого експерименту.

2024 рік може стати переломним для музичного ШІ завдяки проривам у перетворенні тексту на музику, музичному пошуку та чат-ботам. Однак ця сфера все ще відстає від мовленнєвого ШІ, і для того, щоб революціонізувати музичну взаємодію за допомогою ШІ, необхідний прогрес у гнучкому і природному розділенні джерел.

У цій статті основна увага приділяється створенню аналітичної системи на базі LLM і навчанню її взаємодії з базами даних SQL. Автор також представляє ClickHouse як варіант бази даних з відкритим вихідним кодом для роботи з великими даними та аналітичних задач.

Pandera, потужна бібліотека Python, сприяє підвищенню якості та надійності даних завдяки вдосконаленим методам валідації, включаючи застосування схем, настроювані правила валідації та безперешкодну інтеграцію з Pandas. Вона забезпечує цілісність та узгодженість даних, що робить її незамінним інструментом для науковців з даних.

Провідні голоси в області експериментів пропонують тестувати все, але незручна правда про A/B-тестування розкриває його недоліки. Такі компанії, як Google, Amazon і Netflix, успішно впровадили A/B-тестування, але сліпе дотримання їхніх правил може призвести до плутанини і катастрофи для інших бізнесів.

Ця стаття містить вступ до розробки неангломовних систем RAG, зокрема поради щодо завантаження даних, сегментації тексту та моделей вбудовування. RAG змінює те, як організації використовують дані для інтелектуальних чат-ботів, але існує прогалина для менших мов.

У цій статті пояснюється, як проводити бенчмаркінг за допомогою критеріального ящика і як проводити бенчмаркінг з різними налаштуваннями компілятора, надається інформація про вплив на продуктивність і порівняння між процесорами. Ящик range-set-blaze використовується як приклад для вимірювання налаштувань SIMD, рівнів оптимізації та різної довжини вхідних даних.

Підвищення швидкості надходження даних в заданий діапазон в 7 разів за рахунок делегування обчислень маленьким крабам. Правило 7: Використовуйте критеріальний бенчмаркінг, щоб вибрати алгоритм і виявити, що LANES має (майже) завжди бути 32 або 64.