
Доценти Массачусетського технологічного інституту (MIT) Джейкоб Андреас і Бретт Макгуайр отримали премію імені Гарольда Е. Еджертона за видатні досягнення викладачів 2026 року за новаторські роботи в галузі обробки природної мови та астрохімії. Новаторські дослідження Андреаса поєднують фундаментальну теорію з практичним впливом на вивчення мов та штучний інтелект.

Раннє залучення до роботи лабораторії штучного інтелекту MIT-IBM Watson стало вирішальним для таких викладачів Массачусетського технологічного інституту, як Джейкоб Андреас та Юн Кім, сприяючи формуванню їхніх дослідницьких груп та розвитку інноваційних проєктів у галузі обробки природної мови та розробки великих мовних моделей. Ця співпраця забезпечила інтелектуальну підтримку, обчислювальні ...
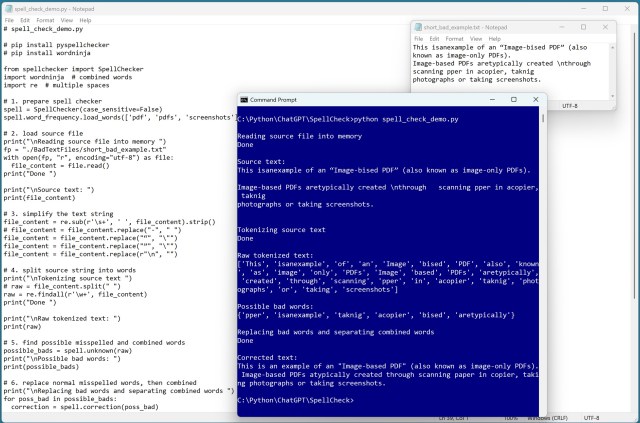
Проект з обробки природної мови передбачав вилучення тексту з необробленого PDF-файлу за допомогою PyMuPDF. Створено легкий інструмент корекції правопису для точної обробки тексту.
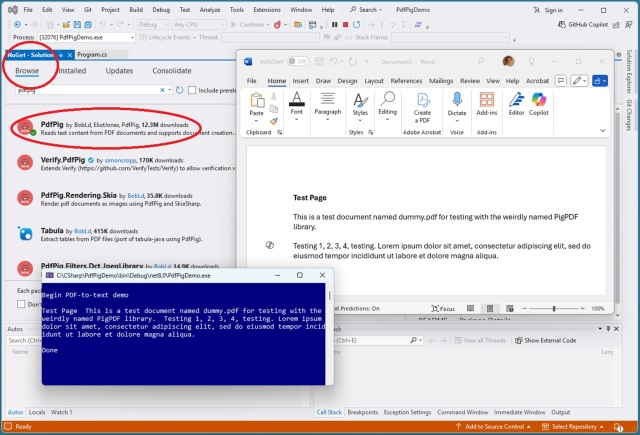
Витяг тексту з PDF-файлів може бути складним завданням через їх візуальний характер. Провідними бібліотеками C# для цього завдання є iText і PdfPig, а PyMuPDF для Python є найкращим вибором.

Amazon Bedrock Knowledge Bases спрощує взаємодію природної мови зі структурованими джерелами даних, забезпечуючи точні запити без вузьких місць в SQL. Рішення дозволяє організаціям швидко створювати діалогові інтерфейси даних, трансформуючи можливості доступу до даних та процеси прийняття рішень.
Qualtrics є піонером в управлінні досвідом (XM) з можливостями штучного інтелекту, машинного навчання та NLP, що покращує зв'язки з клієнтами та підвищує їхню лояльність. Платформа Socrates від Qualtrics, що працює на базі Amazon SageMaker, стимулює інновації в управлінні досвідом за допомогою передових технологій машинного навчання.

618-а авіаційна бригада Командування повітряної мобільності покращує планування місій за допомогою чат-інструментів на основі штучного інтелекту, розроблених Лінкольнською лабораторією. Обробка природної мови забезпечує швидкий аналіз тенденцій та інтелектуальний пошук для прийняття важливих рішень у ВПС США.
Yuewen Group розширює глобальний вплив за допомогою платформи WebNovel, адаптуючи веб-романи у фільми та анімацію. Оперативна оптимізація на Amazon Bedrock підвищує продуктивність великих мовних моделей для інтелектуальної обробки тексту в Yuewen Group, долаючи виклики в оперативній розробці та покращуючи можливості в конкретних випадках використання.

LettuceDetect, легкий детектор галюцинацій для трубопроводів RAG, перевершує попередні моделі, пропонуючи ефективність і доступність з відкритим вихідним кодом. Великі мовні моделі стикаються з проблемами галюцинацій, але LettuceDetect допомагає виявляти і усувати неточності, підвищуючи надійність у критичних областях.

Трансформери революціонізують НЛП завдяки ефективним механізмам самоуваги. Інтеграція трансформаторів у комп'ютерний зір стикається з проблемами масштабування, але багатообіцяючі прориви вже на горизонті.

Такі досягнення в науці про дані, як Transformer, ChatGPT та RAG, змінюють технології. Розуміння еволюції НЛП є ключовим для науковців-початківців.

Досягнення штучного інтелекту об'єднали НЛП і комп'ютерний зір, що призвело до появи моделей підписів до зображень, подібних до тієї, що використовується в «Покажи і розкажи». Ця модель поєднує CNN для обробки зображень і RNN для генерації тексту, використовуючи GoogLeNet і LSTM.

Мовні моделі чудово справляються з різними завданнями, але мають проблеми з художньою інтерпретацією та створенням ASCII. Токенізація заважає LLM зрозуміти загальну картину, що призводить до комічних помилок, таких як смайлик, прийнятий за математичне рівняння.
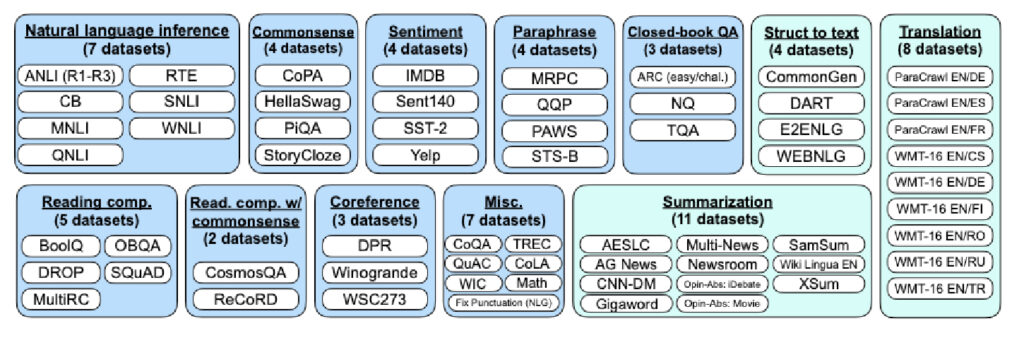
Сучасні найкращі практики навчання великих мовних моделей включають різноманітні методи оцінювання моделей у завданнях, таких як відповіді на запитання, переклад та логічне мислення. Методи оцінювання, такі як навчання з використанням невеликої кількості прикладів (n-shot learning) із підказками, є важливими для точної оцінки продуктивності моделі.

Мультимодальні вбудовування об'єднують текстові та графічні дані в єдину модель, уможливлюючи крос-модальні додатки, такі як підписи до зображень і модерація контенту. CLIP вирівнює представлення тексту і зображень для класифікації зображень з нульового кадру, демонструючи переваги спільного простору для вбудовування.
Медичні LLM-моделі John Snow Labs на Amazon SageMaker Jumpstart оптимізують завдання з медичної мови, перевершуючи GPT-4o в узагальненні та відповідях на запитання. Ці моделі підвищують ефективність і точність для медичних працівників, підтримуючи оптимальний догляд за пацієнтами та результати медичної допомоги.

Короткий зміст: Розробник ділиться досвідом застосування НЛП-моделі для обробки документів чеською мовою, зосереджуючись на ідентифікації об'єктів. Модель була навчена на 710 PDF-документах з використанням ручного маркування та уникненням підходів на основі обмежувальних рамок для підвищення ефективності.
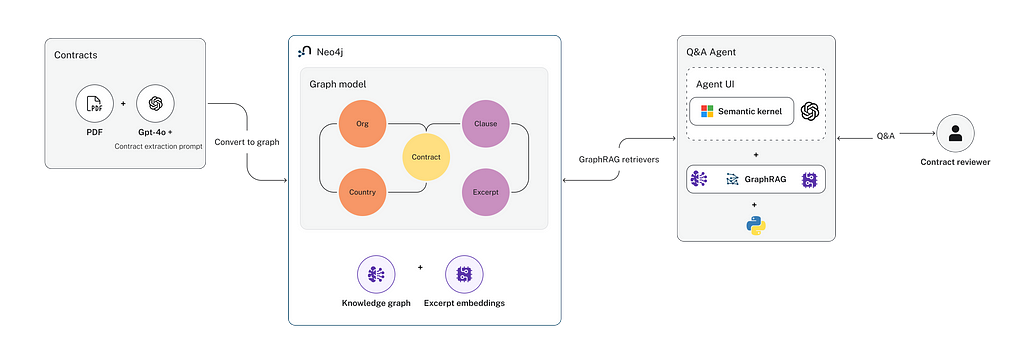
Короткий зміст: Представлення нового підходу GraphRAG для ефективного вилучення даних про комерційні контракти та побудови агентів Q&A. Зосередженість на цільовому вилученні інформації та організації графів знань підвищує точність і продуктивність, що робить його придатним для вирішення складних юридичних питань.

Вважається, що великі мовні моделі (ВММ) мають «емерджентні властивості», але визначення цього поняття варіюється. Дослідники НЛП сперечаються, чи є ці властивості вивченими або вродженими, що впливає на дослідження та суспільне сприйняття.

Google Colab, інтегрований з інструментами генеративного ШІ, спрощує програмування на Python. Вивчайте Python легко і без встановлення завдяки доступним функціям Google Colab.

Токенізація має вирішальне значення в НЛП для з'єднання людської мови та машинного розуміння, дозволяючи комп'ютерам ефективно обробляти текст. Великі мовні моделі, такі як ChatGPT і Claude, використовують токенізацію для перетворення тексту в числове представлення для отримання змістовних результатів.
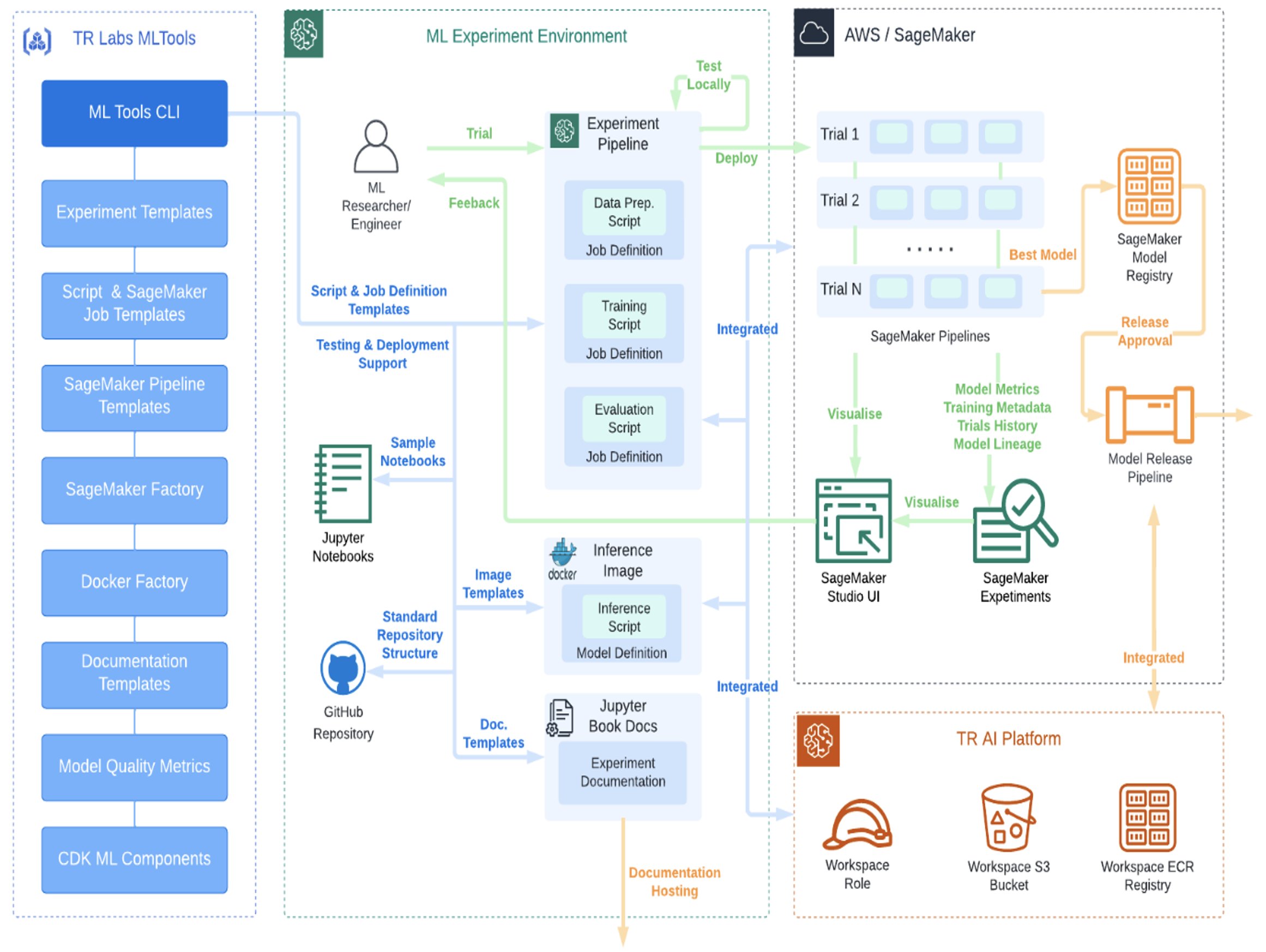
Thomson Reuters Labs розробила ефективний процес MLOps за допомогою AWS SageMaker, що прискорює інновації в галузі ШІ. TR Labs прагне стандартизувати MLOps для більш розумних та економічно ефективних інструментів машинного навчання.
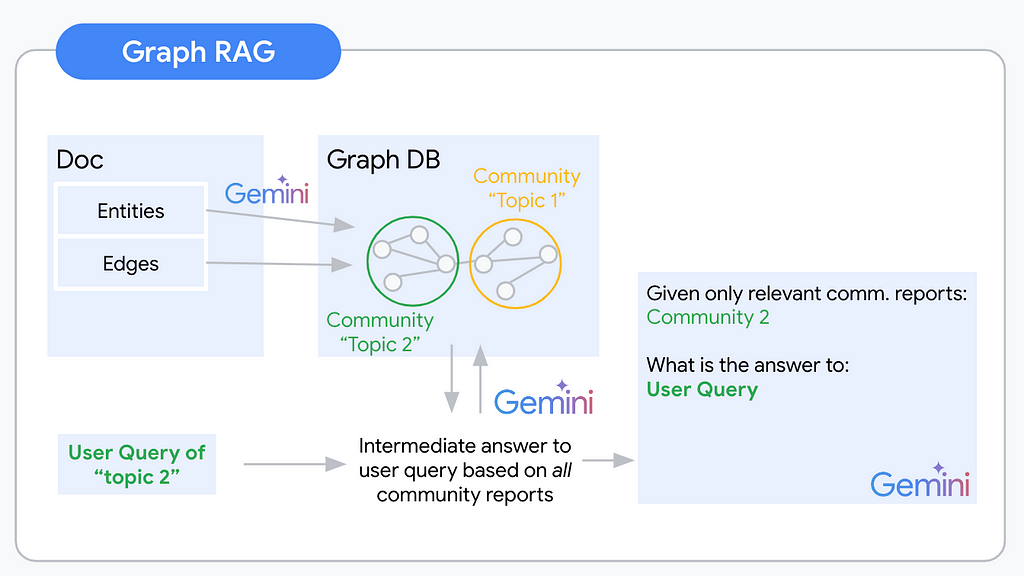
RAG розширює можливості застосунків ШІ, поєднуючи LLM з даними, специфічними для домену. Текстові вбудовування мають обмеження у відповідях на складні, абстрактні питання в документах.
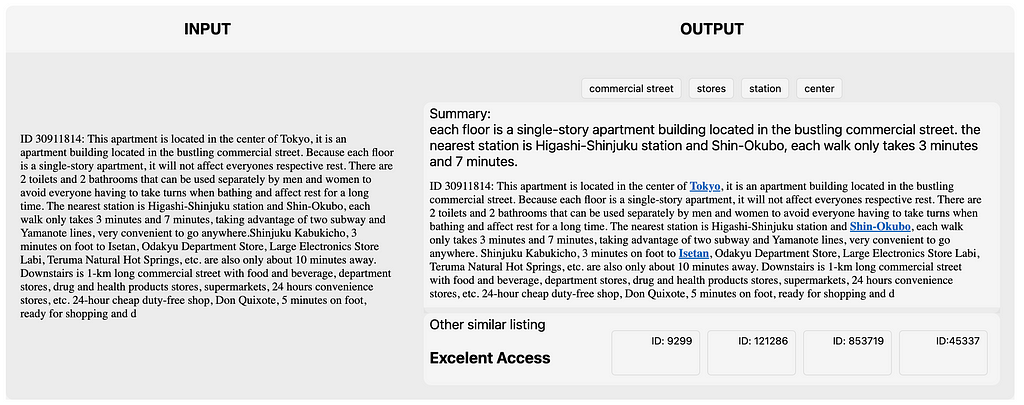
Методи НЛП покращують оголошення про оренду житла на Airbnb у Токіо, виділяючи ключові слова та покращуючи досвід користувачів. У другій частині ви дізнаєтеся про моделювання тем і прогнозування текстів для оголошень про оренду нерухомості.
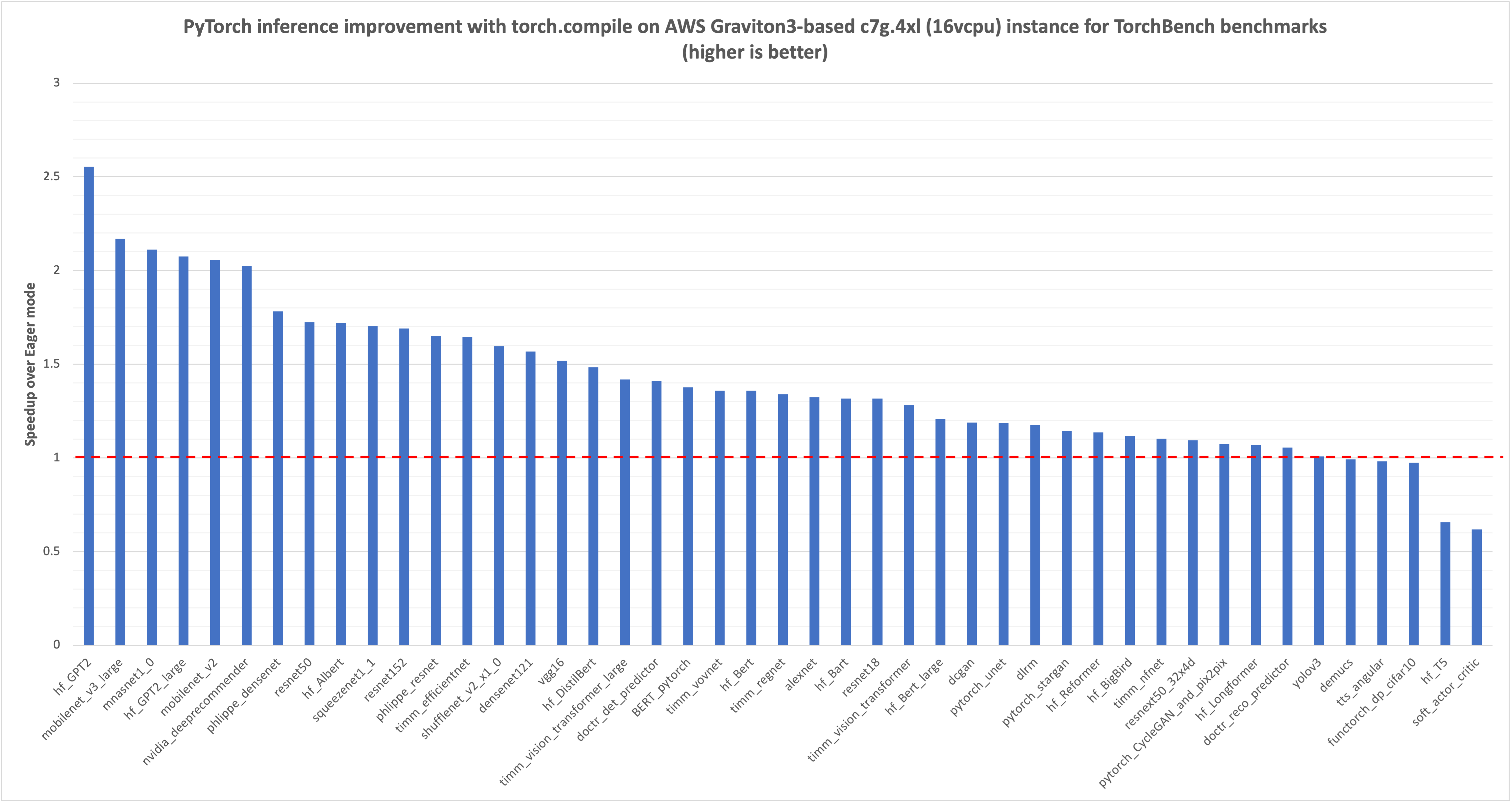
PyTorch 2.0 представив torch.compile для швидшого виконання коду. AWS оптимізувала torch.compile для процесорів Graviton3, що призвело до значного покращення продуктивності для NLP, CV та рекомендаційних моделей.
Використання LLMs та GenAI може покращити процеси дедуплікації, підвищуючи точність з 30% до майже 60%. Цей інноваційний метод корисний не лише для даних клієнтів, але й для виявлення дублікатів записів в інших сценаріях.
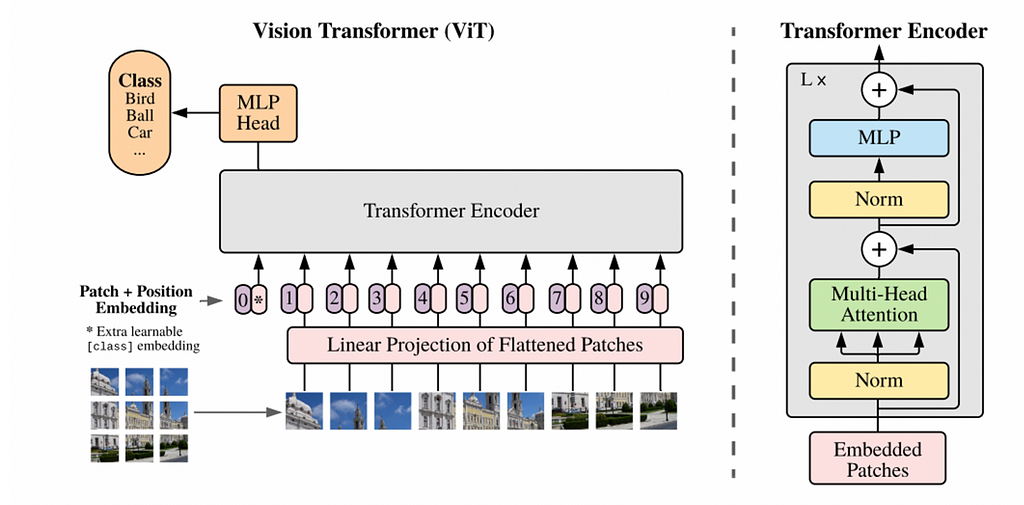
Трансформатори, відомі своєю революцією в НЛП, тепер чудово справляються із завданнями комп'ютерного зору. Дослідіть архітектури Vision Transformer та Masked Autoencoder Vision Transformer, які уможливили цей прорив.

Amazon Bedrock використовує модель Anthropic Claude 3 Haiku для розширеної обробки документів, пропонуючи масштабоване вилучення даних за допомогою найсучасніших можливостей NLP. Рішення оптимізує робочий процес, обробляючи більші файли та багатосторінкові документи, забезпечуючи високу якість результатів завдяки налаштованим правилам та людській перевірці.
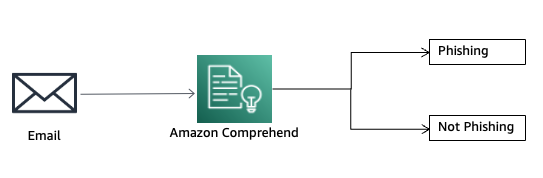
Фішинг - це отримання конфіденційної інформації через електронну пошту. Amazon Comprehend Custom допомагає виявляти спроби фішингу за допомогою ML-моделей.

Короткий зміст: У цій серії блогів ви дізнаєтеся про адаптацію доменів для LLM. Дізнайтеся про тонке налаштування для розширення можливостей моделей і підвищення продуктивності.
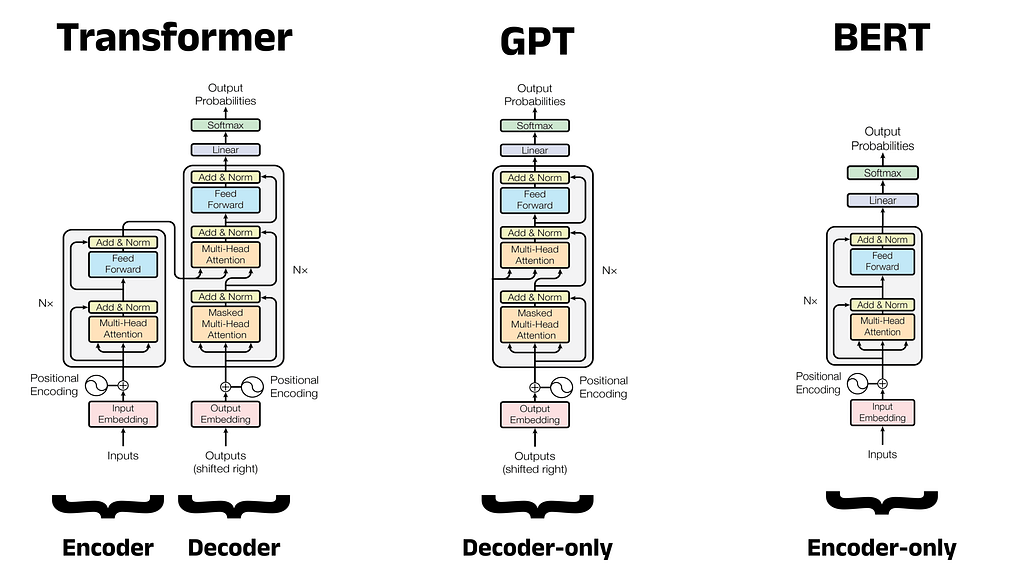
BERT, розроблений Google AI Language, є революційною моделлю великої мови для обробки природної мови. Її архітектура та фокус на розумінні природної мови змінили ландшафт NLP, надихнувши такі моделі, як RoBERTa та DistilBERT.

ONNX Runtime на AWS Graviton3 прискорює ML-виведення на 65% завдяки оптимізованим ядрам GEMM. Бекенд MLAS прискорює роботу оператора глибокого навчання для підвищення продуктивності.
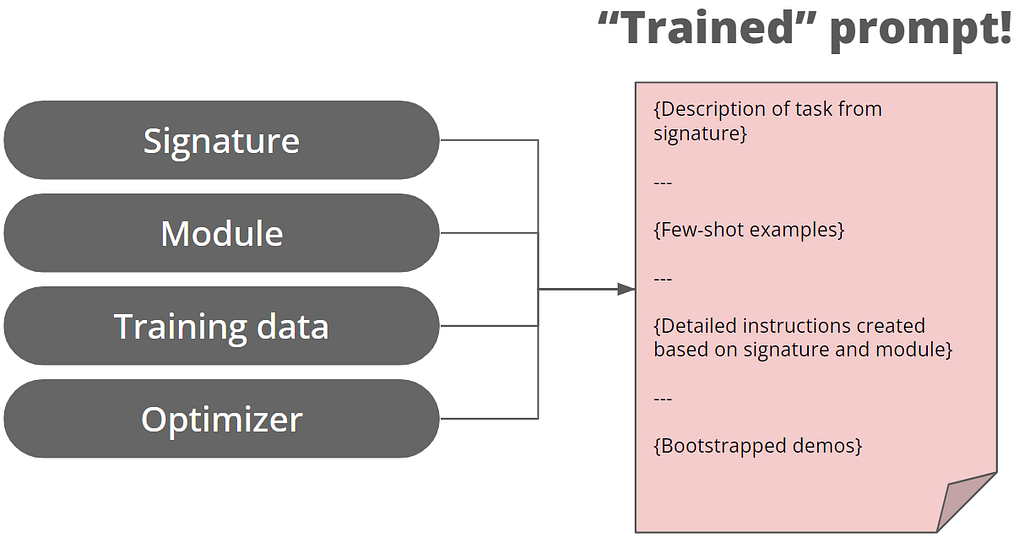
Стенфордський НЛП впроваджує DSPy для розробки підказок, переходячи від ручного написання підказок до модульного програмування. Новий підхід має на меті оптимізувати підказки для LLM, підвищуючи надійність та ефективність.
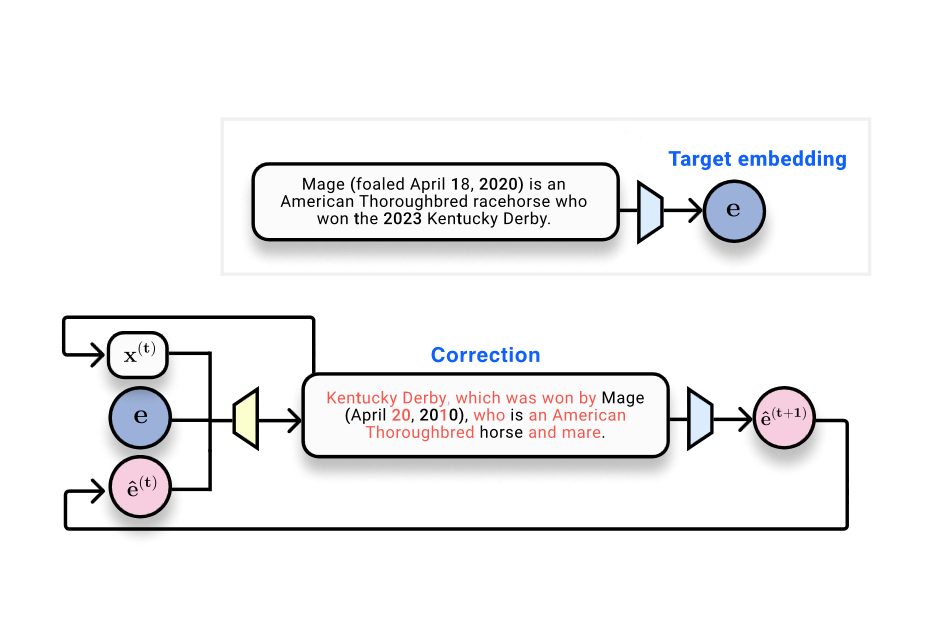
Стаття висвітлює зростання ролі векторних баз даних в інтеграції штучного інтелекту, зосереджуючись на системах розширеного пошуку (RAG). Компанії зберігають текстові вставки у векторних базах даних для ефективного пошуку, що викликає занепокоєння щодо потенційного витоку даних і несанкціонованого використання.
Аліда використала модель Claude Instant від Anthropic на Amazon Bedrock, щоб покращити ствердження теми в 4-6 разів у відповідях на опитування, подолавши обмеження традиційного НЛП. Amazon Bedrock дозволив Аліді швидко створити масштабований сервіс для дослідників ринку, який збирає нюансовані якісні дані, що виходять за рамки запитань з декількома варіантами відповідей.

У статті обговорюється еволюція моделей GPT, зокрема, зосереджується увага на покращеннях GPT-2 порівняно з GPT-1, включаючи його більший розмір та можливості багатозадачного навчання. Розуміння концепцій, що лежать в основі GPT-1, має вирішальне значення для розпізнавання принципів роботи більш просунутих моделей, таких як ChatGPT або GPT-4.

Рекомендаційні системи приносять значний дохід, оскільки Amazon і Netflix значною мірою покладаються на рекомендації щодо продуктів. У цій статті досліджується використання контрольованих словників і LLM для покращення моделей подібності в рекомендаційних системах і виявляється, що контрольований словник покращує результати, а створення списку жанрів за допомогою LLM є простим, але створення д...
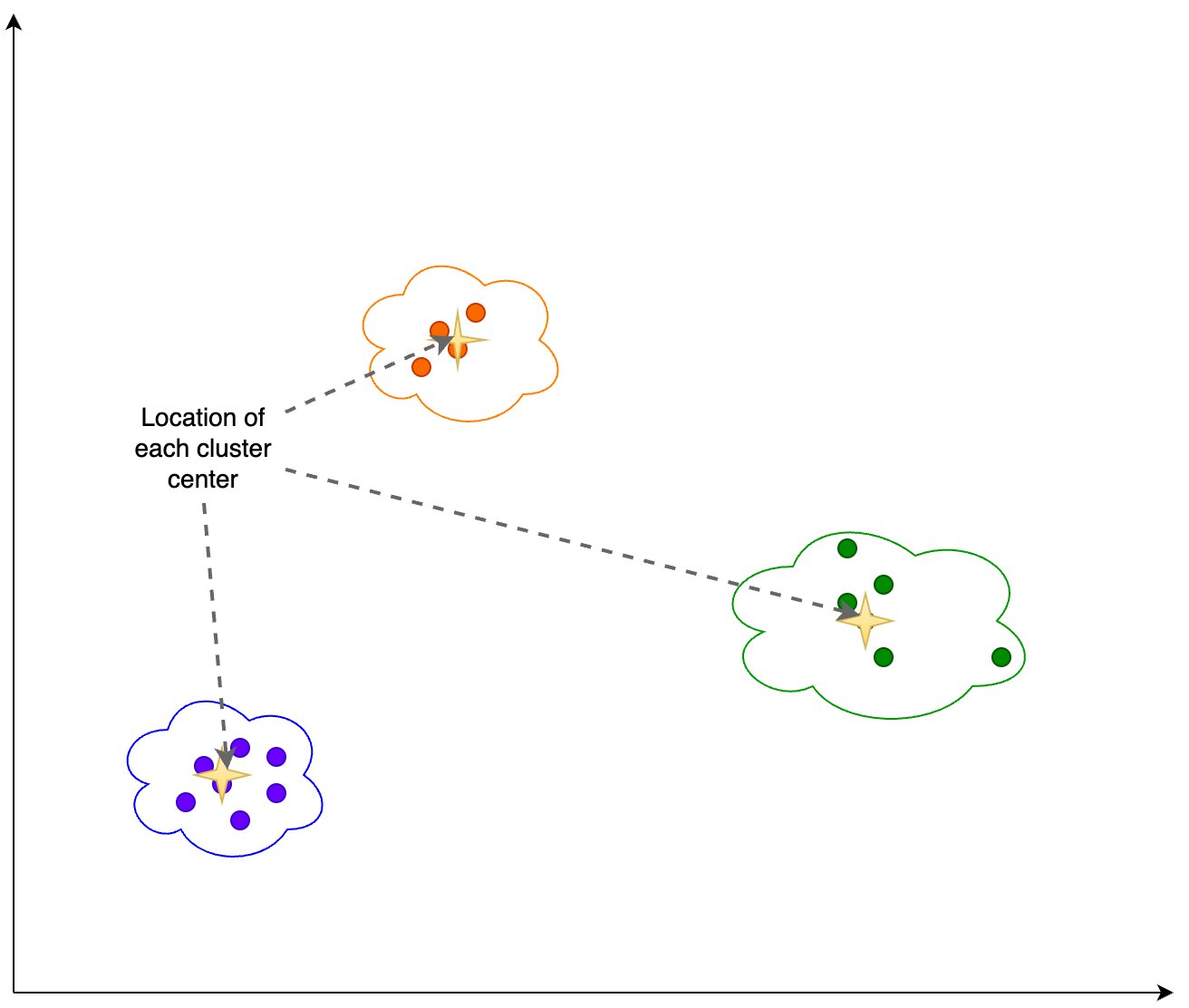
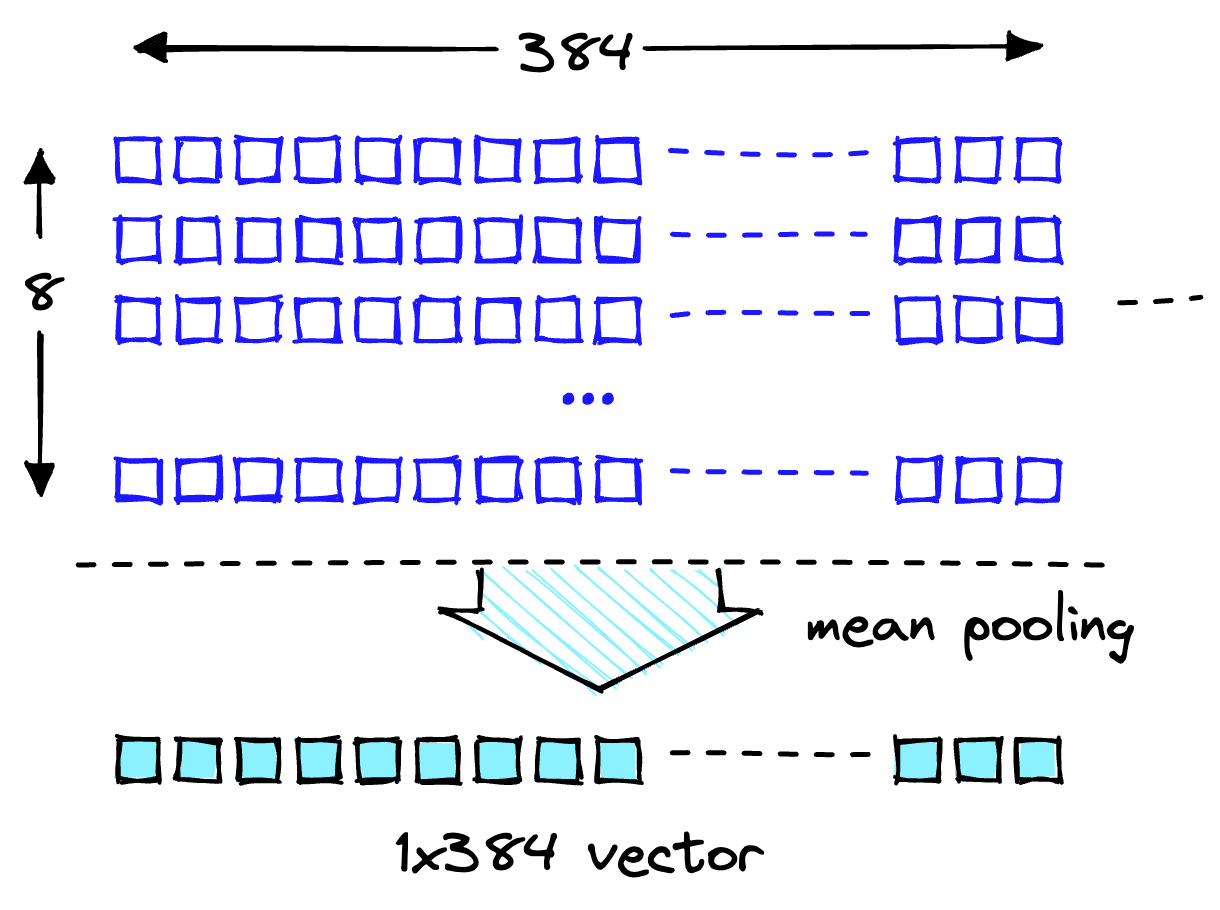
У статті розглядається патерн Retrieval Augmented Generation (RAG) для генеративних робочих навантажень ШІ, з акцентом на аналізі та виявленні дрейфу вбудовування. Досліджується, як вектори вбудовування використовуються для отримання знань із зовнішніх джерел і доповнення підказок інструкцій, а також пояснюється процес виконання аналізу дрейфу цих векторів за допомогою аналізу головних компоне...

Технологія штучного інтелекту здатна перетворювати зображення їжі на рецепти, що дозволяє надавати персоналізовані рекомендації щодо їжі, адаптувати їх до культурних особливостей та автоматизувати процес приготування. Цей інноваційний метод поєднує комп'ютерний зір і обробку природної мови для створення вичерпних рецептів на основі зображень їжі, долаючи розрив між візуальними зображеннями стр...
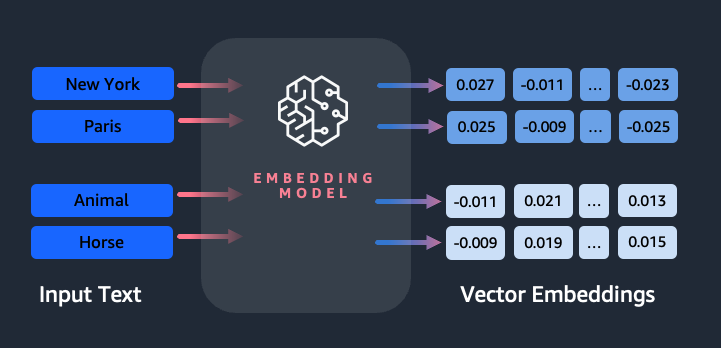
Amazon Titan Text Embeddings - це модель вбудовування тексту, яка перетворює текст природною мовою в числові представлення для пошуку, персоналізації та кластеризації. Вона використовує алгоритми вбудовування слів і великі мовні моделі для фіксації семантичних зв'язків і покращення подальших завдань NLP.

Фахівці з науки про дані використали методи НЛП для аналізу дискусій на Reddit про депресію, досліджуючи гендерні табу щодо психічного здоров'я. Вони виявили, що класифікація за нульовим знімком дає кращі результати, ніж класифікація за навчальним планом. Вони виявили, що класифікація з нульового пострілу може легко давати результати, подібні до традиційного аналізу настроїв, спрощуючи процес ...
У 2017 році Google Brain представив Transformer - гнучку архітектуру, яка перевершила існуючі підходи до глибокого навчання, і тепер використовується в таких моделях, як BERT і GPT. GPT, модель декодера, використовує завдання мовного моделювання для генерації нових послідовностей і дотримується двоетапної схеми попереднього навчання та точного налаштування.

Генеративний ШІ розкрив потенціал ШІ, включаючи генерацію тексту і коду. Одним з напрямків розвитку є використання NLP для створення SQL-запитів, що робить аналіз даних більш доступним для нетехнічних користувачів.

2024 рік може стати переломним для музичного ШІ завдяки проривам у перетворенні тексту на музику, музичному пошуку та чат-ботам. Однак ця сфера все ще відстає від мовленнєвого ШІ, і для того, щоб революціонізувати музичну взаємодію за допомогою ШІ, необхідний прогрес у гнучкому і природному розділенні джерел.
Велика мовна модель Mixtral-8x7B від Mistral AI тепер доступна на Amazon SageMaker JumpStart для легкого розгортання. Завдяки багатомовній підтримці та чудовій продуктивності Mixtral-8x7B є привабливим вибором для додатків NLP, пропонуючи швидший висновок і нижчі обчислювальні витрати.
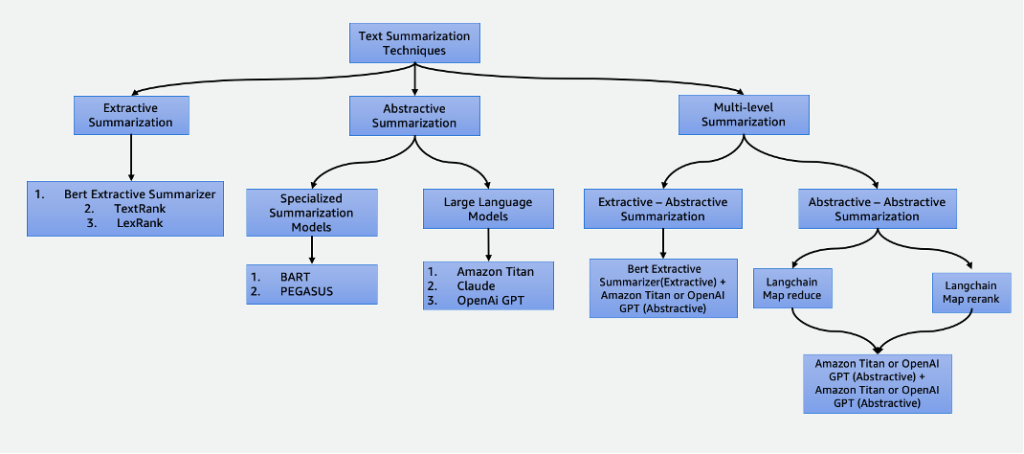
У нашому світі, де панують дані, узагальнення має важливе значення, заощаджуючи час і покращуючи процес прийняття рішень. Він має різні застосування, включаючи агрегацію новин, узагальнення юридичних документів і фінансовий аналіз. З розвитком НЛП і штучного інтелекту такі методи, як екстрактивне та абстрактне узагальнення, стають все більш доступними та ефективними.
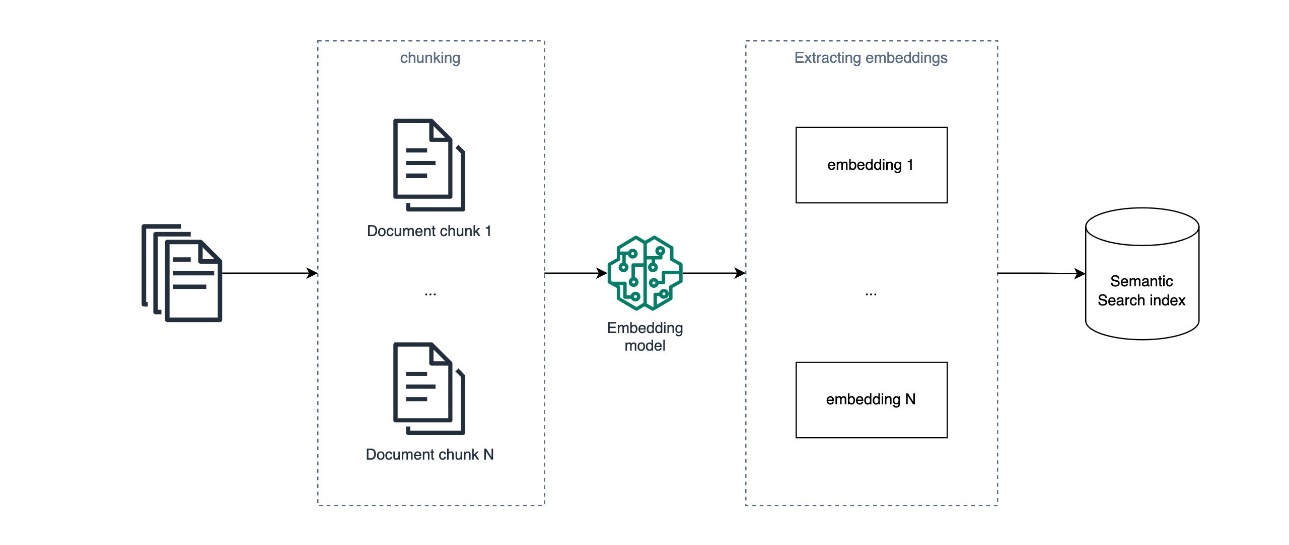
Розмовний ШІ розвинувся завдяки генеративному ШІ та великим мовним моделям, але йому бракує спеціалізованих знань для точних відповідей. Retrieval Augmented Generation (RAG) пов'язує загальні моделі з внутрішніми базами знань, що дозволяє створювати помічників ШІ, орієнтованих на конкретну галузь. Amazon Kendra і OpenSearch Service пропонують зрілі векторні пошукові рішення для реалізації RAG,...
Магістри LLM, такі як Llama 2, Flan T5 і Bloom, необхідні для розмовних кейсів використання ШІ, але оновлення їхніх знань вимагає перепідготовки, що займає багато часу і коштує дорого. Однак завдяки Retrieval Augmented Generation (RAG) з використанням Amazon Sagemaker JumpStart і векторної бази даних Pinecone, LLM можна розгортати і підтримувати в актуальному стані відповідну інформацію, щоб з...