
Теория игр изучает действия и вероятности игроков, вводя смешанные стратегии для более сложного анализа. Равновесие Нэша определяет оптимальные стратегии в играх со случайностью.

Передовая нейросетевая архитектура CPTR объединяет кодер ViT и декодер Transformer для создания титров к изображениям, улучшая предыдущие модели. Модель CPTR использует ViT для кодирования изображений и Transformer для декодирования титров, что повышает производительность создания титров к изображениям.
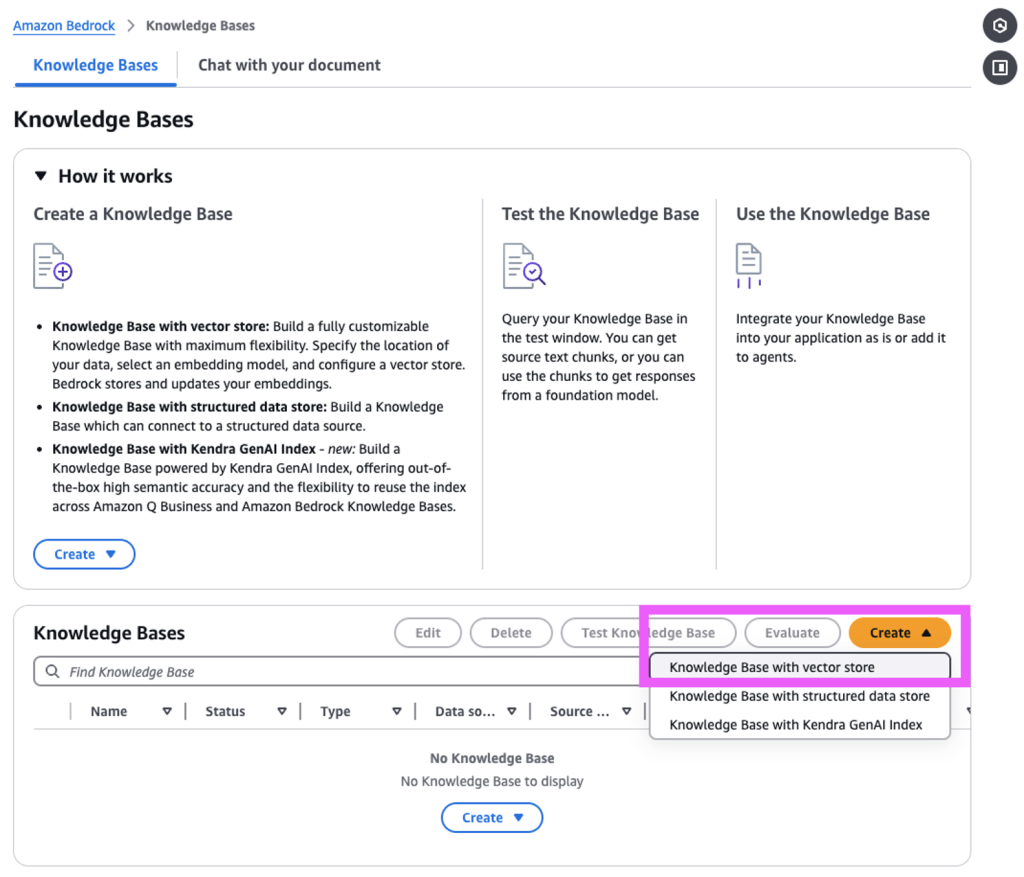
Amazon Web Services (AWS) запускает GraphRAG в Amazon Bedrock Knowledge Bases, что позволяет повысить эффективность генеративных приложений ИИ с помощью графических данных для получения более полных ответов. GraphRAG автоматически создает графики для повышения точности и релевантности в разговорах ИИ, обеспечивая более полезное и надежное взаимодействие.

Исследователи MIT и NVIDIA разработали новую схему, позволяющую пользователям корректировать поведение робота в реальном времени без повторного обучения. Этот интуитивный метод превосходит альтернативные на 21 %, что в перспективе позволит непрофессионалам направлять роботов, обученных на фабрике, при выполнении бытовых задач.

Компания Verisk впервые применяет генеративный искусственный интеллект в страховании с помощью Mozart, сократив время внедрения изменений с нескольких дней до нескольких минут с помощью Amazon Bedrock. Это приложение, работающее на основе искусственного интеллекта, сравнивает юридические документы по страхованию, предоставляя основные различия в удобном формате.
Аманда Гудолл призывает следующего руководителя NHS England расширить возможности лучших врачей для улучшения результатов здравоохранения. Клиники Майо и Кливленда добились успехов под руководством врачей, что подчеркивает преимущества лидерства врачей.

Настройка обучающего конвейера обнаружения объектов с помощью репозиториев Ultralytics, YOLOx, DAMO-YOLO, RT-DETR и D-FINE для реализации модели реального времени SoTA. Фокус на обработке, дополнении и преобразовании наборов данных для достижения оптимальных результатов.

Энтузиаст моды использует искусственный интеллект для превращения хаотичного гардероба в курируемые наряды с помощью многоступенчатой настройки GPT, создавая Pico Glitter. Модный советник на базе GPT помогает управлять гардеробом, предлагая цельные наряды на основе личных правил стиля пользователя и конкретных вещей, которыми он владеет.

BBC News планирует использовать искусственный интеллект для персонализированного контента, чтобы адаптироваться к меняющимся привычкам потребления новостей, ориентируясь на молодых людей в возрасте до 25 лет на таких платформах, как TikTok. Главный исполнительный директор Дебора Тернесс намерена ускорить рост охвата аудитории, создав новый отдел, занимающийся инновациями и искусственным интелл...
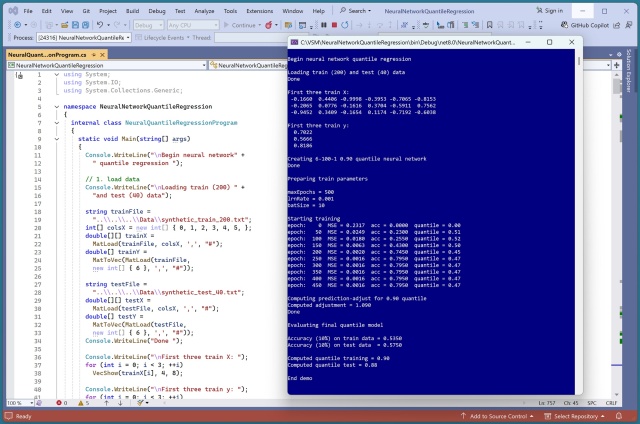
Реализация нейросетевой системы квантильной регрессии в PyTorch оказалась непростой задачей. Изучение C# для той же задачи оказалось еще более сложным, с проблемами калибровки.

Генеративный искусственный интеллект революционизирует розничную торговлю, повышая качество обслуживания клиентов, оптимизируя управление товарами и обеспечивая персонализированный маркетинг благодаря адаптируемому взаимодействию и автоматизации. Ритейлеры используют эту технологию для удовлетворения потребностей клиентов, повышения эффективности и сохранения конкурентоспособности на цифровом ...

Участники GeForce NOW теперь могут охотиться на монстров в Monster Hunter Wilds и погрузиться в захватывающие приключения Split Fiction. Наслаждайтесь высокопроизводительными играми в облаке с технологиями NVIDIA.

Исследователи NVIDIA награждены за новаторский вклад в киноиндустрию. Ziva VFX, ML Denoiser от Disney и Intel Open Image Denoise революционизируют визуальные эффекты.

Технологические компании полагаются на машинное обучение в критически важных приложениях, но незамеченный дрейф моделей может привести к финансовым потерям. Эффективный мониторинг моделей имеет решающее значение для раннего выявления проблем и обеспечения стабильности и надежности моделей в производстве.

Научный фотограф Фелис Френкель в своей недавней статье для журнала Nature обсуждает влияние генеративного искусственного интеллекта на научную коммуникацию. Она подчеркивает важность этичного визуального представления и необходимость обучения исследователей визуальной коммуникации для обеспечения точности и прозрачности.