
Клубничка OpenAI - значительное достижение, но вызывает дискуссию по поводу обнародования «цепочки мыслей». Академическая наука размышляет о последствиях ChatGPT для оценки эссе, подчеркивая необходимость адаптации к новым технологиям.

Системы искусственного интеллекта, например, использующие векторные вкрапления и LLM, по своей сути несовершенны из-за потери информации. Для решения этой проблемы включение структурированных процессов и метаданных может помочь смягчить потери и повысить точность системы.

Система искусственного интеллекта Magic Notes записывает и анализирует встречи, предлагает последующие действия для социальных работников в Англии. Инструмент составляет проекты писем и предлагает действия для советов Суиндона, Барнета, Кингстона и других.

ONVO от NIO представляет внедорожник L60 с системой NVIDIA DRIVE Orin, предлагающий передовые функции безопасности и умного вождения для массового рынка. ONVO L60 сочетает в себе инновационный дизайн и передовые технологии, предлагая впечатляющий запас хода и продвинутые возможности ассистированного вождения по доступной цене.

MIT запускает новую магистерскую программу по музыкальным технологиям и вычислениям с междисциплинарным сотрудничеством. В центре внимания - технические исследования в области музыкальных технологий с гуманистическими и художественными аспектами, подготовка высокоэффективных выпускников для академических и промышленных кругов.

Компании без согласия собирают личные данные для систем искусственного интеллекта. Технологическая индустрия жаждет данных для обучения систем искусственного интеллекта.
Компания Northpower, крупный инфраструктурный подрядчик в Новой Зеландии, использует искусственный интеллект для определения приоритетности рисков для общественной безопасности, сокращая трудозатраты и выбросы углекислого газа. Столкнувшись с проблемами при проверке столбов электропередач на предмет безопасности, компания Northpower объединила цифровые и сканированные данные, чтобы эффективно ...

Генеральный директор OpenAI Сэм Альтман вызвал споры в своем блоге, Google Gemini представляет обновления в мире ИИ.

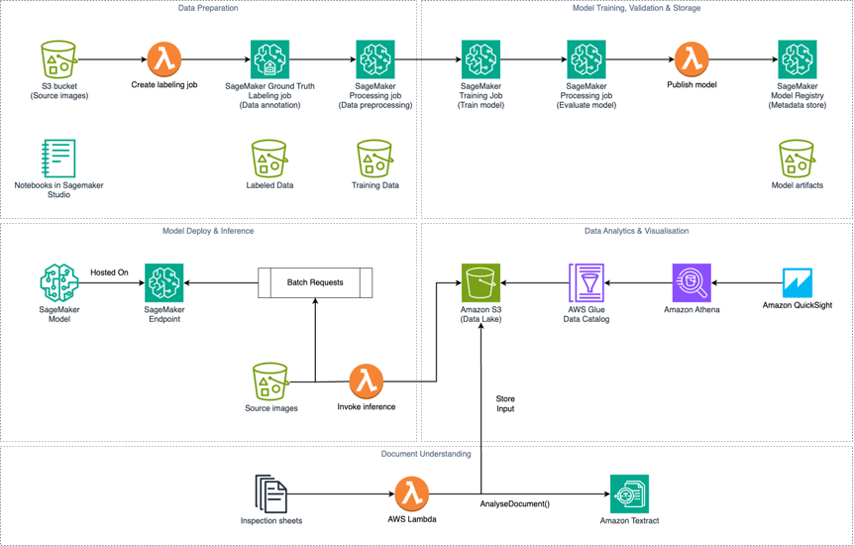
Модели Claude 3 от Anthropic на Amazon Bedrock позволяют обрабатывать изображения и тексты для улучшения взаимодействия с искусственным интеллектом. Генерируйте шаблоны AWS CloudFormation с использованием мультимодальных возможностей для оптимизации проектирования архитектуры.

Марк Цукерберг принимает ИИ и имперскую мономанию, избавляясь от старого имиджа ради нового девиза Aut Zuck Aut Nihil. Meta Connect раскрывает неапологетичную позицию Цукерберга в отношении прошлых ошибок, переключая внимание на волшебные очки и ИИ-спам.

ИИ-ассистент ChatGPT от OpenAI вводит расширенный голосовой режим, позволяющий пользователям творчески сотрудничать с ИИ в неожиданных формах. Архитектор-программист Эй Джей Смит демонстрирует музыкальный талант ИИ, исполняя дуэтом песню The Beatles «Eleanor Rigby» и получая похвалу от голоса ИИ.

Бывший сотрудник OpenAI Уильям Сондерс предупреждает, что переход компании в коммерческий статус может поставить под угрозу безопасность. Возникают опасения по поводу потенциального влияния Сэма Альтмана на заинтересованные стороны в реструктурированной компании.

Ars Technica и IBM проводят мероприятие «За пределами шумихи: инфраструктурное будущее с GenAI» в Сан-Хосе, где обсуждают перспективы и проблемы генеративного ИИ. Докладчики затронут вопросы сложности технологий, быстрого развития, требований к инфраструктуре, уязвимостей безопасности и воздействия на окружающую среду.

ИИ обнаруживает 303 новых геоглифа в районе перуанских линий Наска, что вдвое превышает количество известных рисунков на объекте 2000-летней давности. Совместная работа Университета Ямагата и IBM Research выявила изображения животных и людей, датируемые 200 годом до нашей эры.

ИИ-версия рецензии Брайана Сьюэлла лишена его подлинного голоса, что разочаровывает читателей. Шикарный голос и уникальный стиль Сьюэлла очень не хватает в попытке London Standard воссоздать его почерк.