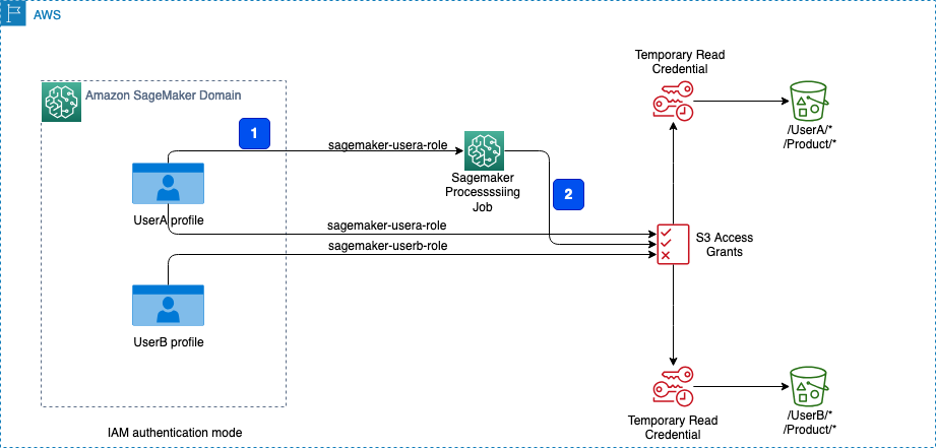
Amazon SageMaker Studio предлагает унифицированный интерфейс для специалистов по исследованию данных, инженеров ML и разработчиков для построения, обучения и мониторинга ML-моделей с использованием данных Amazon S3. S3 Access Grants упрощает управление доступом к данным без необходимости частого обновления ролей IAM, предоставляя гранулированные разрешения на уровне ведра, префикса или объекта.
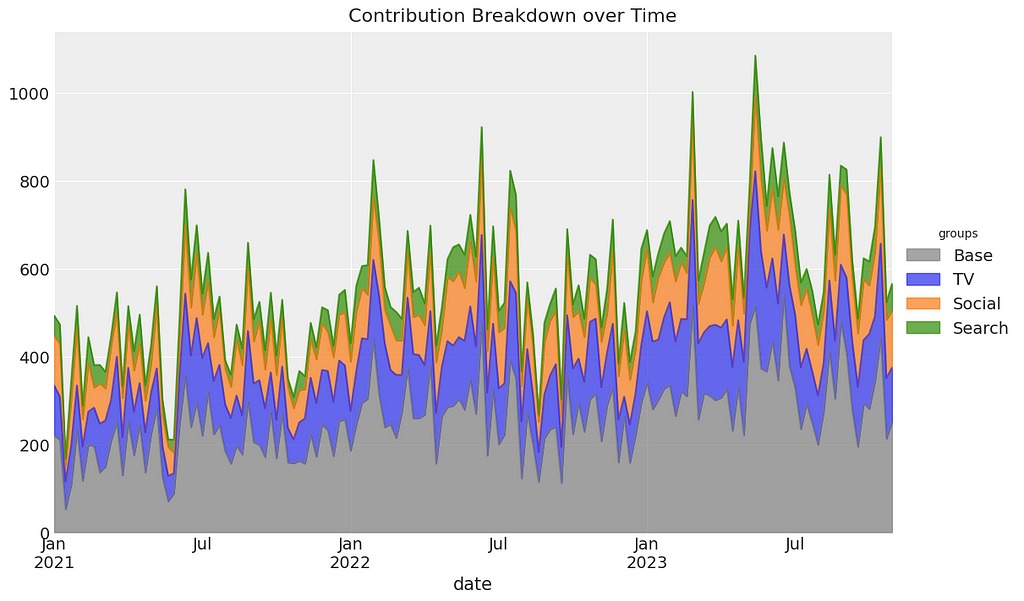
Освойте моделирование маркетингового микса (МММ) с помощью pymc-marketing в этой серии статей, посвященной обучению, проверке и калибровке моделей. Изучите байесовский МММ и преимущества использования pymc-marketing перед другими пакетами с открытым исходным кодом, такими как Robyn и Meridian.

Консалтинговая компания Reframe Джеффри Л. Боумана использует искусственный интеллект для вовлечения сотрудников в программы многообразия. В индустрии DEI стоимостью 10 млрд долларов сокращаются программы в университетах и таких компаниях, как Nordstrom.

Токенизация имеет решающее значение в НЛП, чтобы соединить человеческий язык и машинное понимание, позволяя компьютерам эффективно обрабатывать текст. Крупные языковые модели, такие как ChatGPT и Claude, используют токенизацию для преобразования текста в числовые представления для получения осмысленных результатов.

ФБР расследует глубокий фейк ИИ, имитирующий Дмитрия Кулебу, допрашивающего сенатора Бена Кардина, что вызывает опасения по поводу вмешательства в выборы. Инцидент с имитацией во время звонка в Zoom вызывает тревогу по поводу рисков политических манипуляций.
Статья: «Логистическая регрессия с пакетным обучением SGD и уменьшением веса с помощью C#». В ней рассказывается о том, как логистическая регрессия проста в реализации, хорошо работает с малыми и большими наборами данных и дает хорошо интерпретируемые результаты. В демонстрационной программе используется стохастический градиентный спуск с пакетным обучением и затуханием веса для получения точн...

Узнайте, как создать планировщик питания с помощью ChatGPT на языке Python, упрощающий принятие решений о питании и покупку продуктов. Используйте методы быстрого проектирования, чтобы максимально расширить возможности ChatGPT и сделать планирование питания более простым и эффективным.

GeForce NOW расширяется благодаря наградам GreedFall II и Guild Wars 2. Улучшена потоковая передача для ноутбуков Arm. Присоединяйтесь к захватывающим приключениям и эпическим сражениям в облаке.

Искусственный интеллект вызывает панику по поводу господства компьютеров, но истинная опасность кроется в шумихе. Навнит Аланг.

Проект Tor и компания Tails объединяются, чтобы укрепить усилия по обеспечению анонимности в Интернете. Tails получит преимущества от операционной структуры Tor, что позволит им сосредоточиться на совершенствовании своей ОС.

Остерегайтесь делиться в социальных сетях сообщениями, отрицающими доступ Meta к вашим данным. К этой тенденции присоединяются такие знаменитости, как Джеймс Макэвой и Том Брэди.

Платформа для хостинга ИИ Hugging Face достигла отметки в 1 миллион объявлений о продаже ИИ-моделей, предлагая кастомизацию для специализированных задач. Генеральный директор Деланг подчеркивает важность индивидуальных моделей для отдельных случаев использования, подчеркивая универсальность платформы.

Исследователи Массачусетского технологического института разработали квантовый протокол безопасности для облачных моделей глубокого обучения, обеспечивающий конфиденциальность данных без ущерба для точности. Протокол использует принцип отсутствия клонирования в квантовой механике для предотвращения перехвата информации злоумышленниками и обеспечивает точность 96 процентов в тестах.

Агентство по защите детей штата Виктория попало под огонь из-за того, что в своем отчете сотрудник назвал куклу «подходящей по возрасту игрушкой» для «сексуальных целей». Запрет на услуги генеративного ИИ был введен после того, как сотрудник ввел в ChatGPT личную информацию, включая имя ребенка.

Технический директор OpenAI Мира Мурати покидает свой пост после того, как возглавила компанию ChatGPT. Мурати называет причиной своего ухода из технологической компании личный опыт.