
Юваль Ной Харари критикует способность машинного обучения манипулировать истиной в своей новой книге «Нексус», рассказывая об опасностях ИИ. Он предупреждает, что компьютеры могут манипулировать людьми без применения физической силы, вызывая опасения по поводу будущего влияния ИИ на общество.

Компания Roblox планирует запустить инструмент генеративного ИИ с открытым исходным кодом для создания 3D-окружения с текстовыми подсказками, что может упростить создание игр. Инструмент, основанный на «базовой 3D-модели», позволяет пользователям вводить такие подсказки, как «создать гоночную трассу» и «сделать пейзаж пустыней», чтобы сгенерировать соответствующие модели.
Прогресс в создании чат-ботов на основе LLM измеряется такими эталонами, как MMLU и HumanEval. Целенаправленный диалог, сфокусированный на многораундовых беседах с конкретными целями, может улучшить пользовательский опыт и сотрудничество с ИИ.

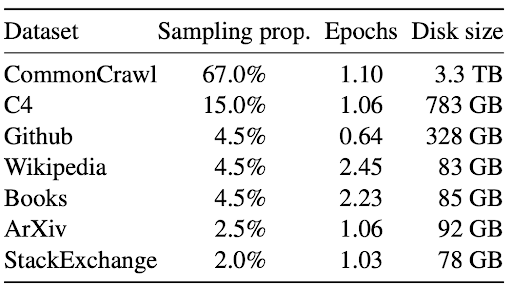
Современные модели искусственного интеллекта растут в размерах, что приводит к увеличению спроса на вычислительные мощности. Установки Amazon EC2 P5e на базе графических процессоров NVIDIA H200 обеспечивают высокую производительность для глубокого обучения и HPC-нагрузок благодаря более быстрой памяти GPU и пропускной способности сети.
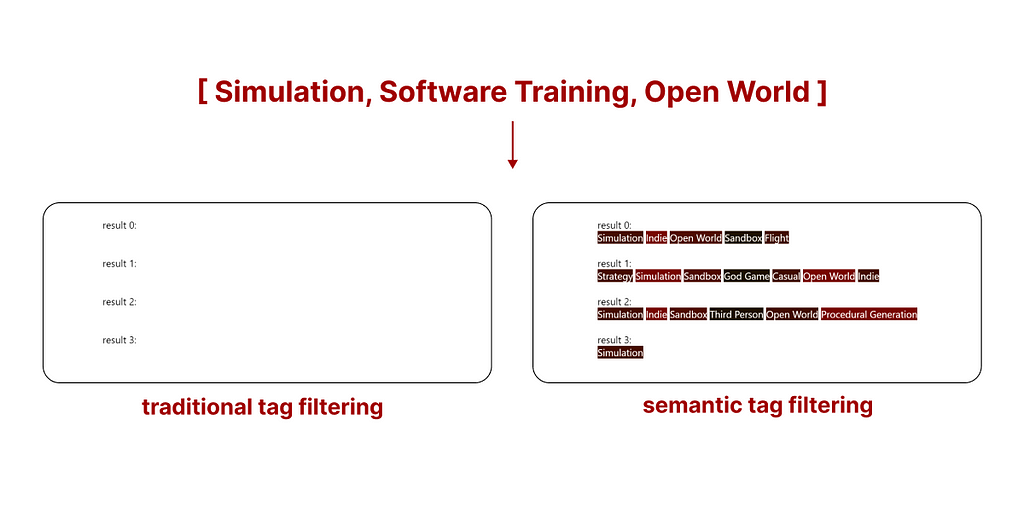
Семантическая фильтрация тегов представляет новый алгоритм, объединяющий семантический поиск и системы фильтрации тегов. Традиционному поиску по тегам не хватает гибкости, но этот новый подход нацелен на расширение результатов за счет неидеальных совпадений.
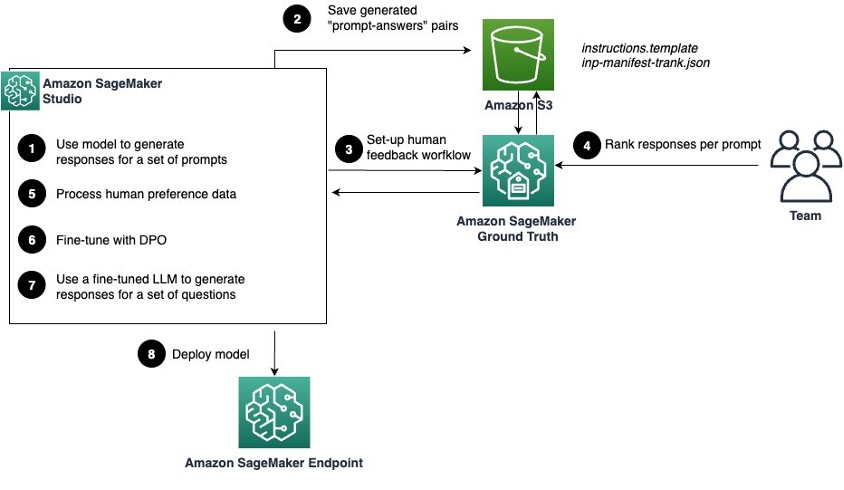
Используйте DPO с Amazon SageMaker, чтобы привести ответы модели Meta Llama 3 8B Instruct в соответствие с ценностями вашей организации. Повысьте полезность, честность и уменьшите предвзятость модели, используя данные о предпочтениях людей для тонкой настройки.
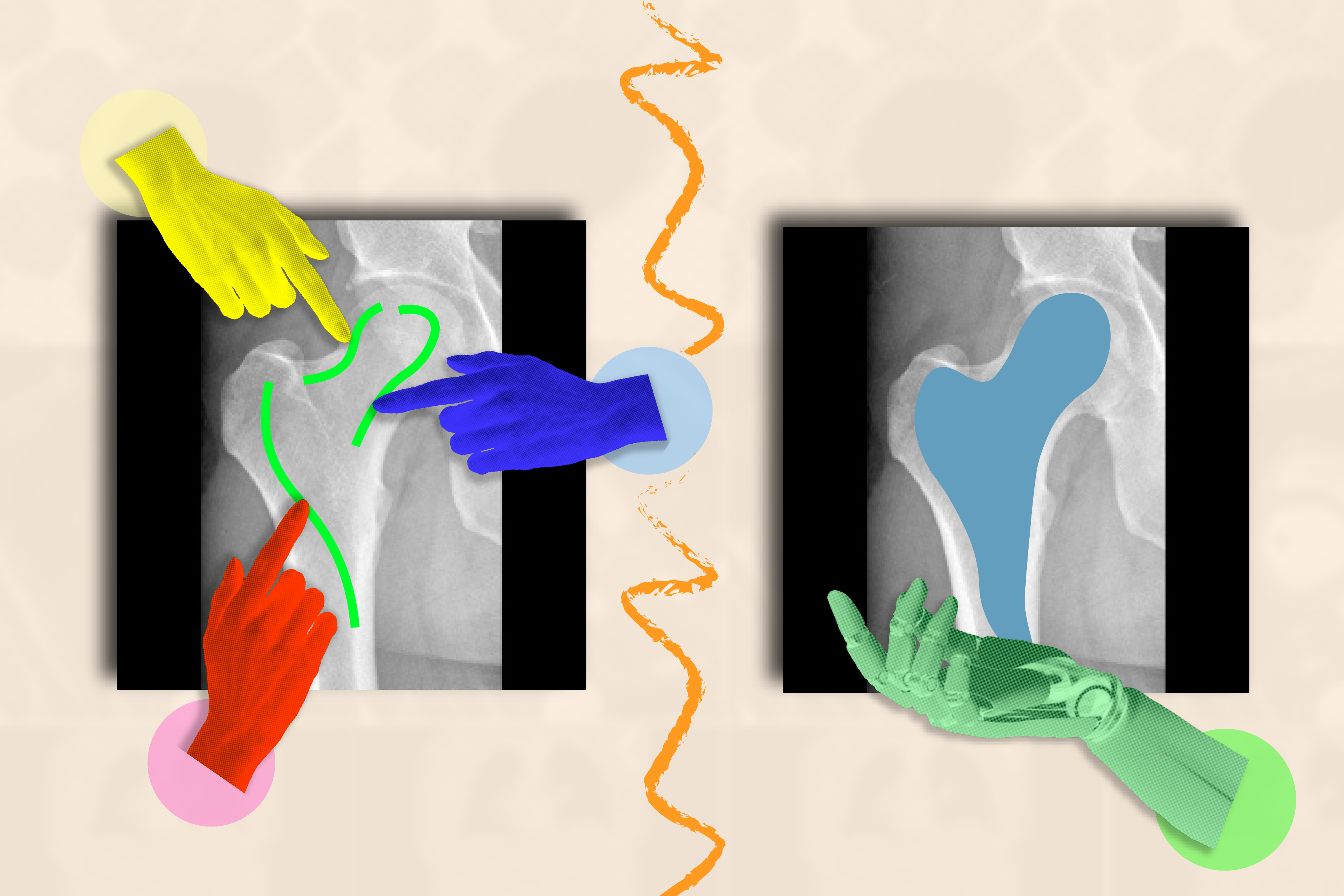
ИИ-система ScribblePrompt от MIT, MGH и Harvard ускоряет сегментацию медицинских изображений, сокращая время аннотирования на 28 %. Пользователи могут легко аннотировать структуры на различных медицинских изображениях, повышая эффективность работы врачей и исследователей.

BP сотрудничает с компанией Palantir, чтобы использовать искусственный интеллект для ускорения принятия решений инженерами, анализируя данные для подготовки выводов.

Резюме: Автор представляет методологию оптимизации рабочих процессов ИИ, выделяя 5 ключевых составляющих. Основное внимание уделяется оптимизации на основе метрик и интерактивному опыту разработчиков при создании готовых к производству ИИ-проектов.

Оценка Nvidia упала на $279 млрд за один день - что ждет гиганта по производству чипов с искусственным интеллектом? Знаковое исследование выявило коррупцию в британских правительственных контрактах Covid на сумму 15 млрд фунтов стерлингов.

Руководство Apple представило iPhone 16, сделав акцент на функциях искусственного интеллекта, таких как редактирование текста и распознавание объектов в новой модели. Компания обещает новые цвета и пользовательские эмодзи, стремясь к доминированию на конкурентном рынке технологий.

Более 4 000 художников призывают правительство ввести налог на смартфоны для поддержки изобразительного искусства в условиях сокращения расходов. Сэр Джон Акомфрах, дама Соня Бойс - среди подписавших открытое письмо министру культуры.

Python - самый популярный язык для проектов в области искусственного интеллекта и науки о данных. Изучите основы Python для разработки ИИ с помощью краткого руководства для начинающих. Кодирование проектов в области искусственного интеллекта является обязательным, даже с такими инструментами, как ChatGPT, что делает его изучение более простым, чем когда-либо.
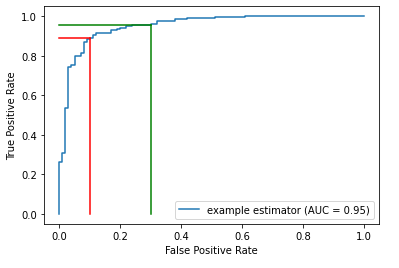
Инструмент на языке python под названием ClassificationThesholdTuner автоматизирует настройку порогов для задач классификации, предоставляя визуализацию и поддержку многоклассовой классификации. Он упрощает процесс и повышает качество модели, оптимизируя выбор порога.
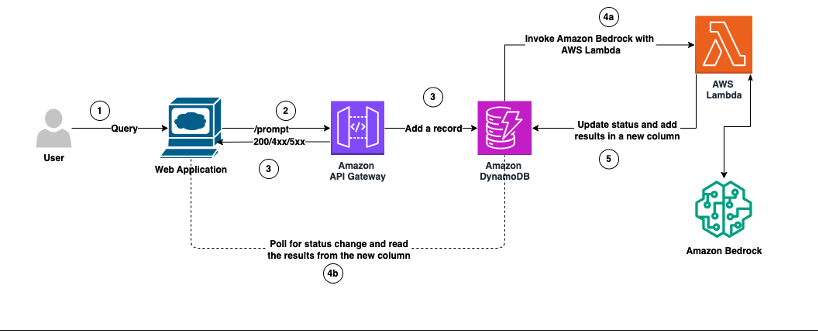
Генеративный ИИ улучшает маркетинг с помощью персонализированного контента и предиктивной аналитики. Vidmob сотрудничает с AWS GenAIIC для анализа креативных данных с помощью Amazon Bedrock, что революционизирует креативную аналитику.