
Технологии AI и ML улучшают качество обслуживания в контакт-центрах благодаря ботам самообслуживания, аналитике звонков в реальном времени и аналитике после звонка. Интеграция Amazon Lex и Genesys Cloud упрощает процесс разработки ботов, превращая контакт-центры в центры прибыли.

ИИ может повысить эффективность и удовлетворенность работников, но также может привести к потере работы и слежке. Работники Amazon уволены ботами ИИ, а другие сталкиваются с жесткими ограничениями на время работы в туалете.

Википедия понизила рейтинг надежности CNET из-за контента, созданного искусственным интеллектом. Репутация CNET пошатнулась после обнаружения плагиата и ошибок в статьях, написанных искусственным интеллектом.

SEC проверяет внутреннюю переписку генерального директора OpenAI Сэма Альтмана. Расследование потенциального обмана инвесторов. Повестка в суд была выдана в декабре.
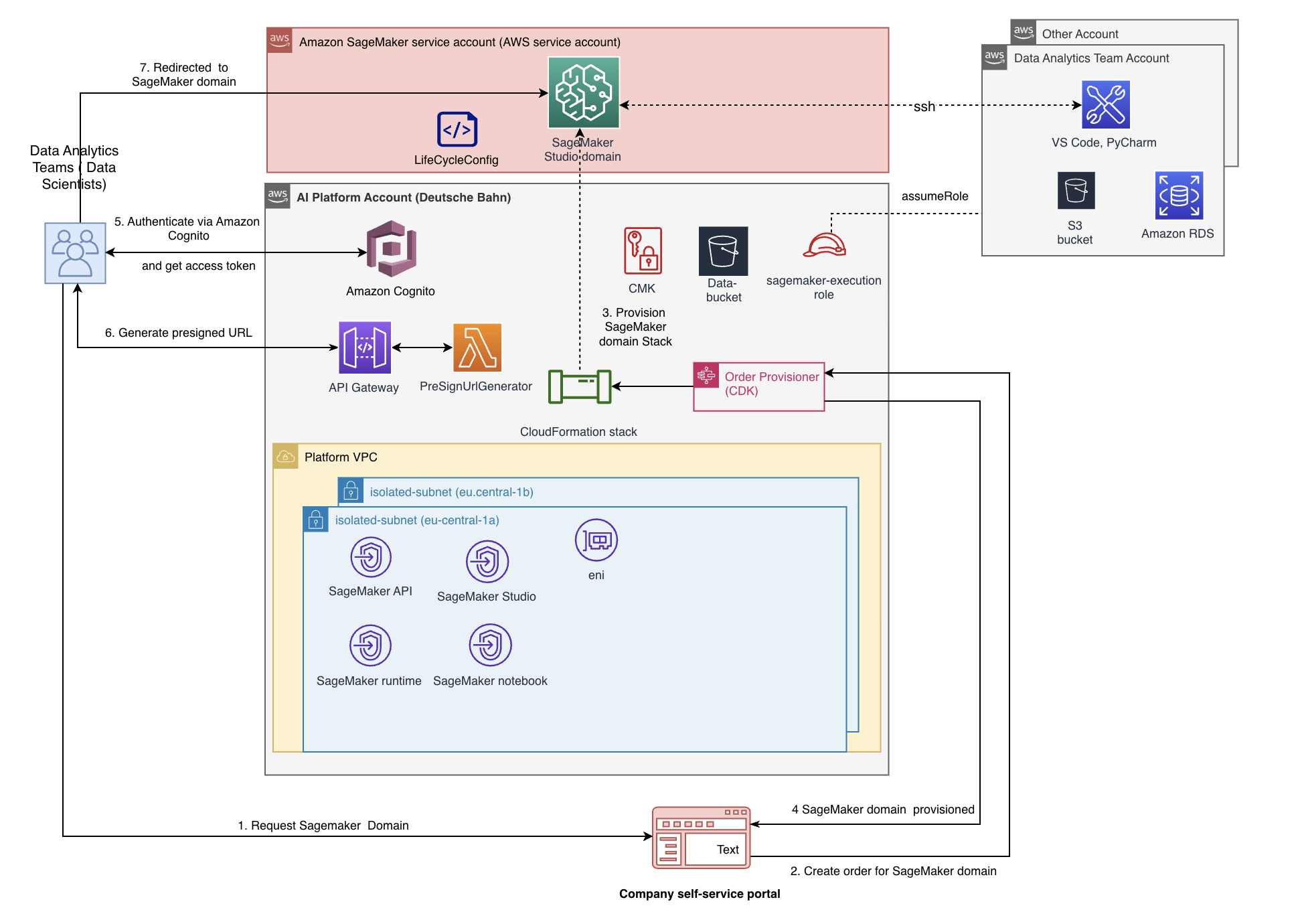
Проблемы с платформами ИИ в крупных организациях включают соблюдение требований, безопасность и масштабируемость. Deutsche Bahn использует Amazon SageMaker Studio для проектов ИИ, что дает такие преимущества, как совместная работа, масштабируемость и экономическая эффективность.

Тамара Бродерик, преподаватель Массачусетского технологического института, использует байесовский вывод для количественной оценки неопределенности в методах анализа данных. Сотрудничая в разных областях, она помогает разрабатывать такие инструменты, как модель машинного обучения для океанских течений и инструмент для людей с нарушением двигательных функций.
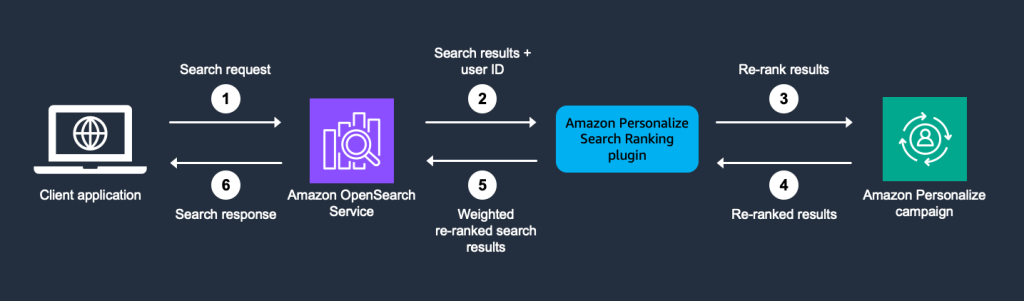
OpenSearch - это универсальный программный пакет с открытым исходным кодом для поиска, аналитики и мониторинга, а Amazon Personalize предлагает сложные возможности персонализации, не требующие специальных знаний в области ML. Предприятия могут повысить вовлеченность пользователей и конверсию, используя эти технологии для улучшения релевантности поиска и создания персонализированных рекомендаций.
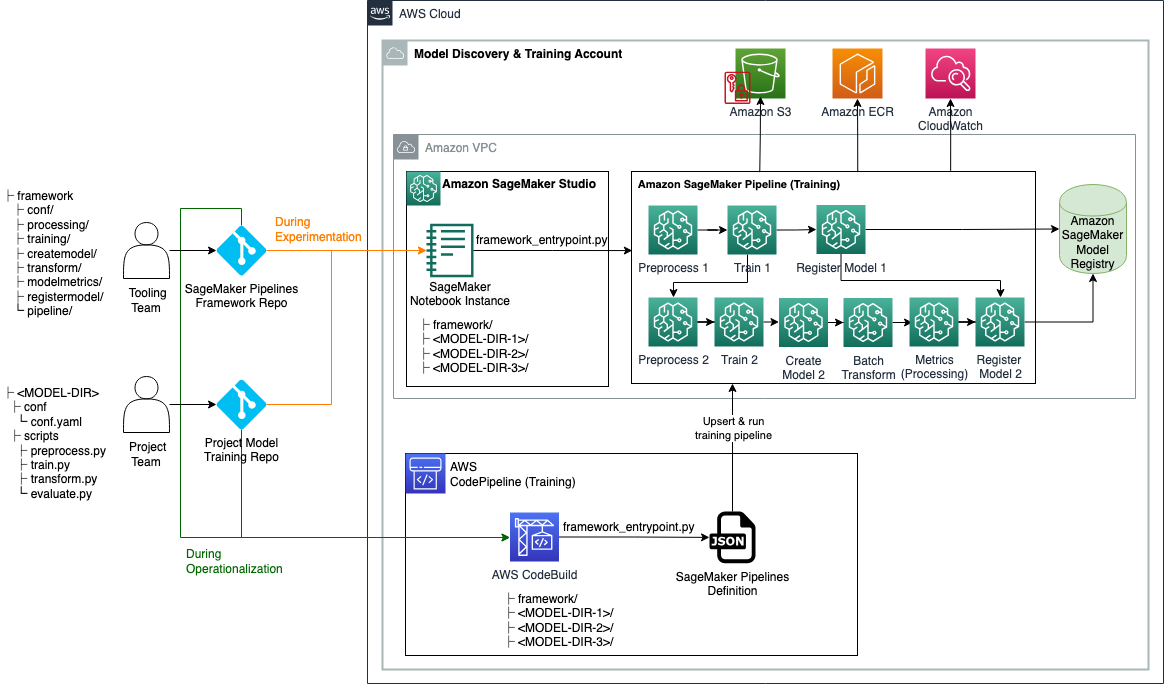
Автоматизируйте рабочие процессы ML с помощью динамической структуры для конвейеров Amazon SageMaker Pipelines, обеспечивающей воспроизводимость, масштабируемость и гибкость. Управление моделями улучшено благодаря интеграции реестра моделей для отслеживания версий и уверенного продвижения в производство.
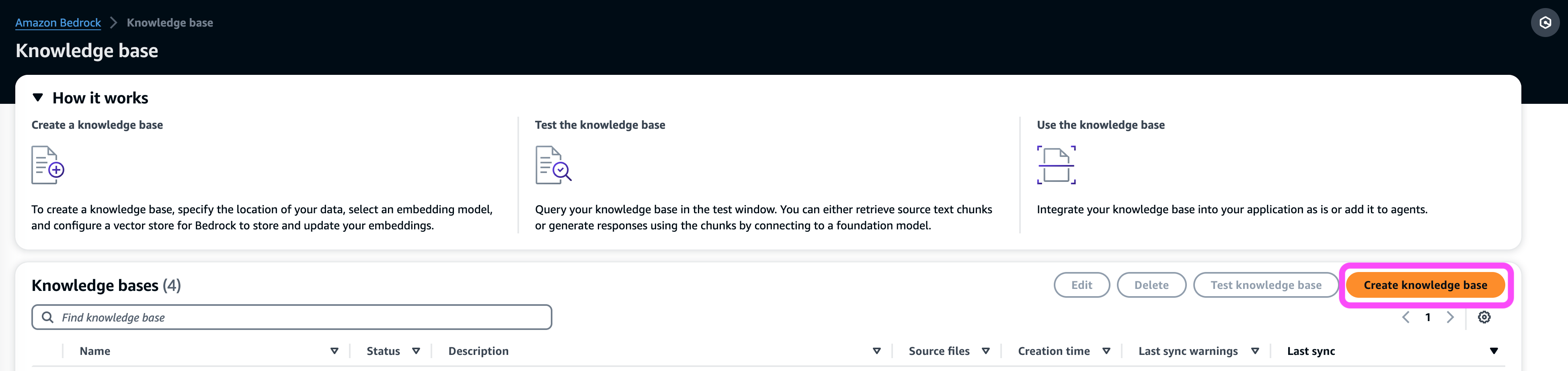
Amazon Bedrock предлагает широкий спектр моделей от ведущих поставщиков, таких как Anthropic и Cohere, для генерации текстов и изображений, создания чат-ботов и многого другого. Базы знаний автоматизируют стратегии синхронизации и поиска данных для специализированных приложений RAG, упрощая построение и управление сложными рабочими процессами.

Аватар известного нейрохирурга Уорфа обучает хирургов по всему миру тонким техникам операций на мозге с помощью виртуальной реальности. Инновационный проект EDUCSIM, поддерживаемый MIT.nano, устраняет пробелы в медицинском образовании, расширяя возможности таких хирургов, как Васконселос в Бразилии.
Откройте для себя возможности анализа главных компонент (PCA) с помощью разложения по сингулярным значениям (SVD) на C#. Преобразуйте наборы данных для визуализации или прогнозирования, используя всего девять элементов данных. PCA - это ключевая техника для уменьшения размерности и анализа данных, которая находит применение в машинном обучении и обнаружении аномалий.
ThirdAI Corp. впервые предлагает экономически эффективное глубокое обучение на стандартных CPU, отменяя необходимость использования дорогостоящих GPU-ускорителей. AWS Graviton3 демонстрирует многообещающее ускорение при обучении нейронных моделей, революционизируя экономику ИИ.

Ванкуверский адвокат Чонг Ке попал под следствие за использование ChatGPT для цитирования поддельных судебных решений в деле об опеке над детьми. Опасности непроверенного искусственного интеллекта в зале суда раскрыты.

Компания Lightmatter, основанная выпускниками Массачусетского технологического института, совершает революцию в области вычислений, создавая чипы, использующие свет и электроны для операций искусственного интеллекта. Привлекла $300 млн в 2023 году для решения проблемы энергопотребления в центрах обработки данных и моделях искусственного интеллекта.

Новые австралийские стандарты безопасности могут помешать генеративному искусственному интеллекту обнаруживать в Интернете материалы, связанные с насилием над детьми и терроризмом, предупреждают технологические компании. Microsoft подчеркивает потенциальное влияние на выявление проблемного контента.