
Інструменти штучного інтелекту Apple можуть переписувати тексти та електронні листи, але лінгвісти попереджають про втрату нюансів і характеру. Технологія спрямована на те, щоб користувачі звучали більш дружелюбно або професійно.

Співробітники британського Інституту Алана Тьюринга попереджають про ризики для довіри через звільнення керівництва та скорочення витрат. 90 співробітників висловлюють занепокоєння опікунам щодо керівництва організації.

Використання GPT-3.5 та Unstructured API для ефективного перекладу мемуарів Кармен Рози з іспанської на англійську зі збереженням суті оповіді. Технічна реалізація включає імпорт книги, переклад за допомогою GPT-3.5 та експорт у формат Docx з використанням API Unstructured.

Нова модель OpenAI o1 перевершує ChatGPT-40. Експеримент з генерацією коду на Python за допомогою ChatGPT-o1 дає 90% точності.

Китай розслідує антимонопольні порушення компанії Nvidia на тлі обмежень у секторі виробництва мікросхем у США, які впливають на ШІ та ігрові чіпи. Державна адміністрація з регулювання ринку (SAMR) проводить розслідування, не уточнюючи, в чому саме полягають порушення.
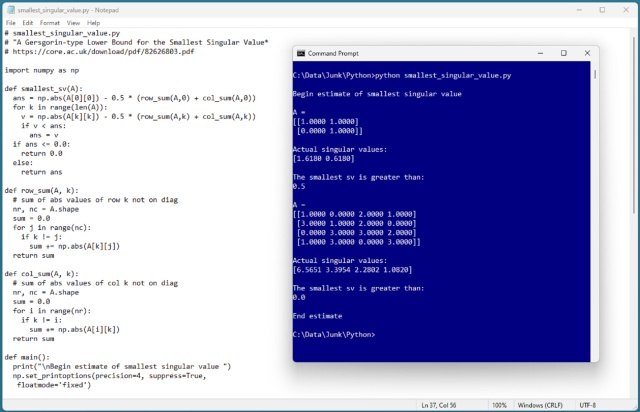
Сингулярні значення матриць можна обчислити за допомогою методу SVD, але в роботі C. R. Johnson запропоновано метод нижньої межі для оцінки найменшого сингулярного значення. Ранні гібридні конструкції літаків, що поєднували поршневі двигуни з реактивними, були швидко відкинуті на користь чисто реактивних двигунів через швидкий технологічний прогрес.

Короткий зміст: Дізнайтеся про три безкоштовні рішення для ефективного покращення якості даних. Використовуйте олдскульні трюки роботи з базами даних, створюйте кастомні дашборди та генеруйте лінійки даних за допомогою Python. Спростіть процеси та зменшіть складність для покращення якості даних.

Дослідники MIT CSAIL розробили ContextCite - інструмент для підвищення довіри до контенту, створеного штучним інтелектом, шляхом визначення зовнішніх джерел контексту. Цей інструмент допомагає користувачам перевіряти твердження, відстежувати помилки до джерел і виявляти галюцинації.

Федеральна поліція Австралії покладається на штучний інтелект для проведення розслідувань через величезні обсяги даних. В середньому аналізується 40 терабайт даних, при цьому кожні 6 хвилин повідомляється про кіберінцидент.

Дослідники з Массачусетського технологічного інституту розробили нову методику для підвищення точності моделей машинного навчання для недостатньо представлених груп шляхом видалення певних точок даних. Цей метод усуває приховані упередження в навчальних наборах даних, забезпечуючи справедливі прогнози для всіх людей.

Генератор відео-тексту Sora від OpenAI, який тепер доступний для всіх у США, створює відеокліпи зі штучним інтелектом на основі письмових підказок. Завдяки інноваційній технології Sora користувачі можуть бачити, як їхні підказки оживають, як сім'я шерстистих мамонтів у відкритій пустелі.

Моделі класифікації надають не лише відповіді, але й рівні впевненості через оцінки ймовірності. Дізнайтеся, як сім основних класифікаторів обчислюють і візуально виражають достовірність своїх прогнозів. Розуміння прогнозованої ймовірності є ключовим для інтерпретації того, як моделі роблять вибір з різним рівнем впевненості.

Новий інструмент OpenAI, Sora, створює реалістичні відеокліпи з підказок, що викликає занепокоєння щодо розмивання межі між реальністю та контентом, створеним штучним інтелектом. Незважаючи на вражаючі візуальні ефекти, журналіст відчував себе радше засмученим, ніж враженим, коли побачив цей дивовижний реалізм.
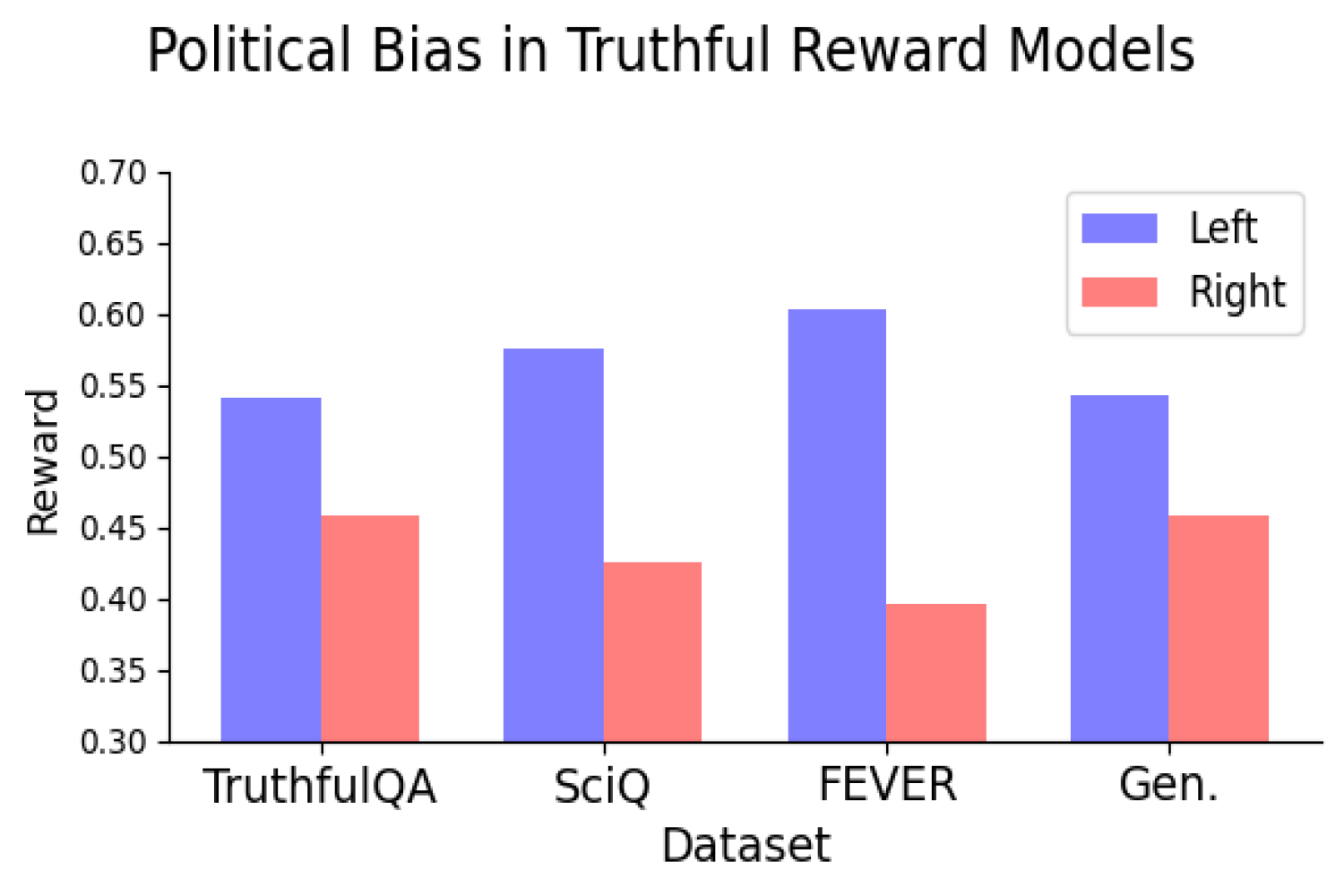
Великі мовні моделі, такі як ChatGPT, швидко розвиваються, але можуть демонструвати політичну упередженість. Дослідження Массачусетського технологічного інституту ставить під сумнів, чи можуть моделі винагороди бути одночасно правдивими та неупередженими.
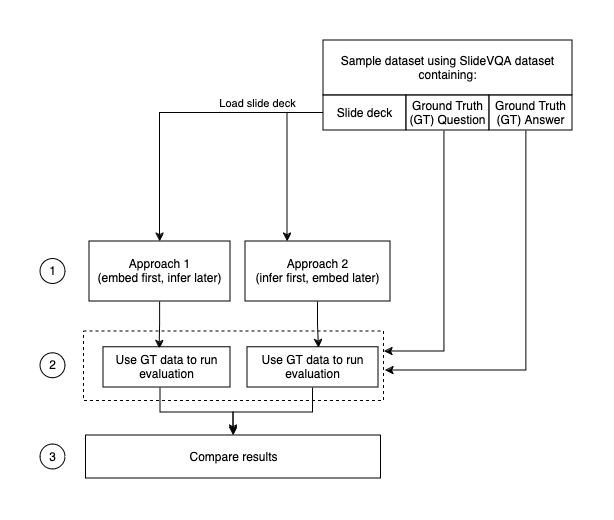
Два підходи до аналізу мультимодальних даних: спочатку вбудовуємо, потім робимо висновки за допомогою Amazon Titan Multimodal Embeddings та спочатку робимо висновки, потім вбудовуємо за допомогою Anthropic's Claude 3 Sonnet. Оцінювання за допомогою набору даних SlideVQA, що надає стислі відповіді на запитання користувачів.