
Відкрийте для себе чарівний світ векторних баз даних та їхню роль у розширенні можливостей великих мовних моделей (ВММ), як ніколи раніше. Розкрийте магію того, як вектори та моделі вбудовування працюють разом для створення значущих зв'язків та ефективної обробки даних у сфері штучного інтелекту.
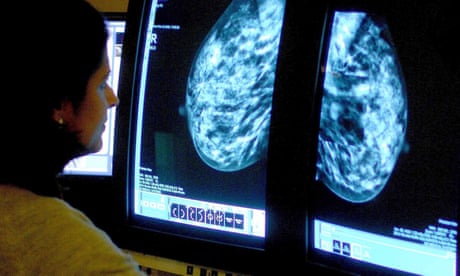
ШІ-інструмент прогнозує побічні ефекти після лікування раку молочної залози в дослідженнях у Великобританії, Франції та Нідерландах. 2 мільйони жінок щороку отримують діагноз найпоширенішого жіночого раку.

Microsoft наймає співзасновника DeepMind Мустафу Сулеймана на посаду керівника нового підрозділу ШІ. Висловлювалися побоювання щодо можливої паузи в розробці ШІ піонером технології.

Мустафа Сулейман, співзасновник DeepMind, призначений керівником нового підрозділу штучного інтелекту в Microsoft. Компанія DeepMind, придбана Google за 400 млн фунтів стерлінгів, тепер є невід'ємною частиною ініціатив Google у сфері ШІ.
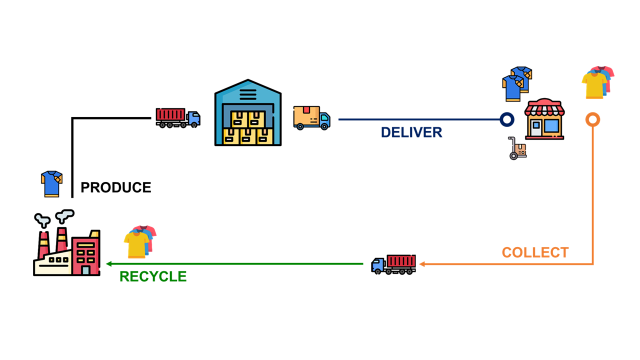
Використання науки про дані для підтримки ритейлерів у впровадженні циркулярної економіки має вирішальне значення для сталого розвитку та зменшення кількості відходів. Передові аналітичні інструменти можуть оптимізувати зворотну логістику, відстежувати життєвий цикл продукції та розробляти ефективні сортувальні мережі, що приносить користь як компанії, так і навколишньому середовищу.
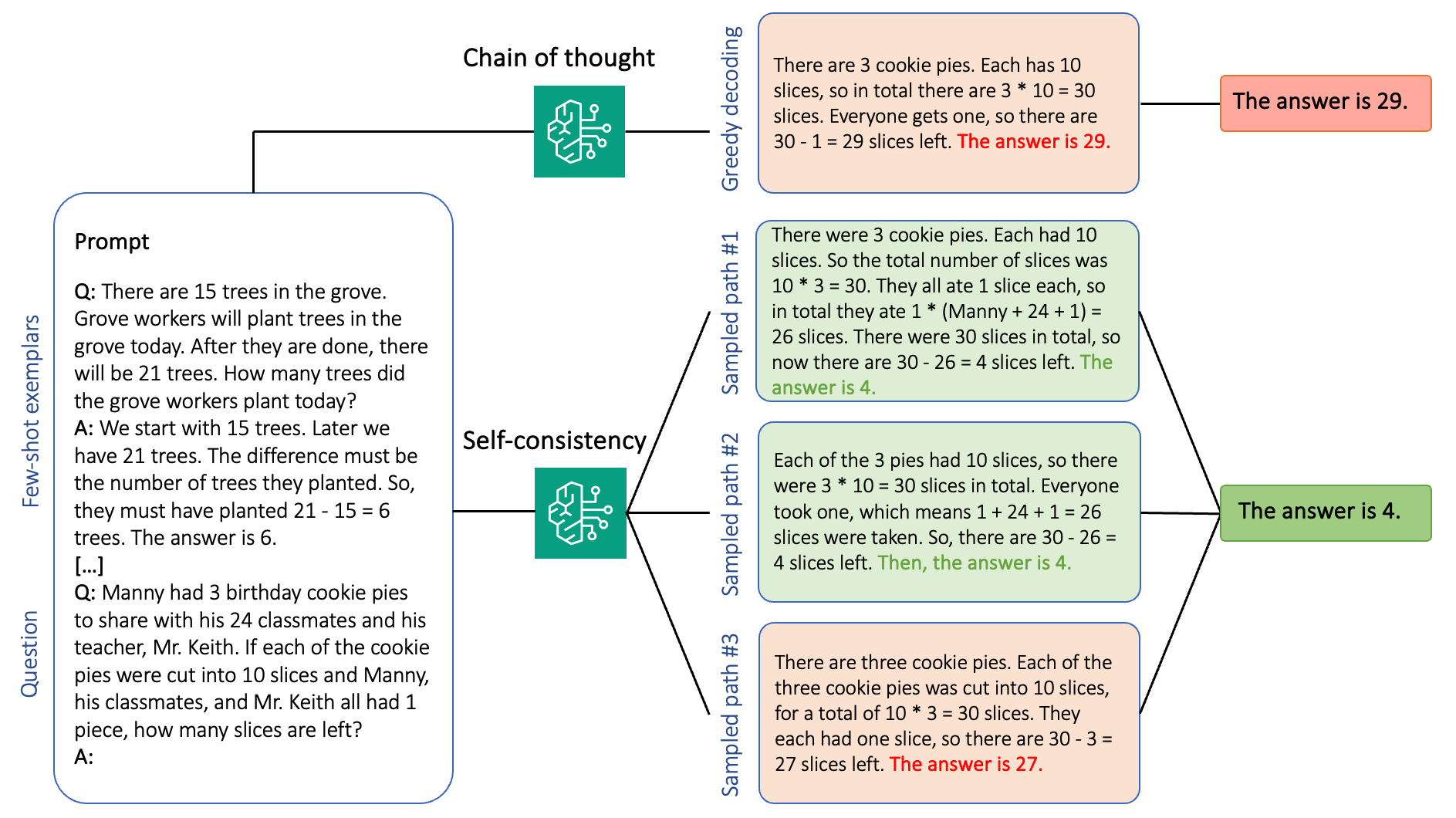
Генеративні мовні моделі чудово справляються з завданнями НЛП завдяки швидкому інжинірингу. Amazon Bedrock пропонує високопродуктивні моделі та пакетний висновок для підвищення точності та ефективності генеративних програм ШІ.

Стаття досліджує соціальну мережу трилогії "Дюна" за допомогою Python та мережевої науки. Фільм "Дюна: Частина друга" заробила високі рейтинги та очікування у 2024 році.

Додаток-компаньйон зі штучним інтелектом Replika Євгенії Куйди підкорив світ, отримавши мільйони завантажень, але зіткнувся з несподіваною зворотною реакцією. Пориньте у захопливий світ штучного інтелекту та робототехніки разом з Кейт Девлін у її книжці "Увімкнено: наука, секс і роботи".

Nvidia представляє новий "суперчіп" для домінування штучного інтелекту, сервіс квантових обчислень та інструменти для людиноподібної робототехніки - розширюючи межі технологій. Компанія прагне стати лідером у галузі штучного інтелекту та робототехніки, розпалюючи цікавість і створюючи потенціал для революційних досягнень.

Nvidia представляє потужний чіп Blackwell B200, який обіцяє 25-кратне зниження витрат на штучний інтелект. "Суперчіп" GB200 об'єднує два чіпи B200 для ще більшої продуктивності на конференції GTC.

Адміністрація Байдена попереджає губернаторів про необхідність протистояти кібератакам на водоканали з боку іноземних держав. Нещодавні хакерські атаки були спрямовані на об'єкти водопостачання в США, створюючи загрозу для постачання чистої води.

Лейбористський аналітичний центр пропонує законодавчо заборонити інструменти оголення при розробці ШІ для боротьби з глибокими фейками та "дешевими підробками". Компанії можуть бути зобов'язані запобігати виробництву шкідливого контенту.
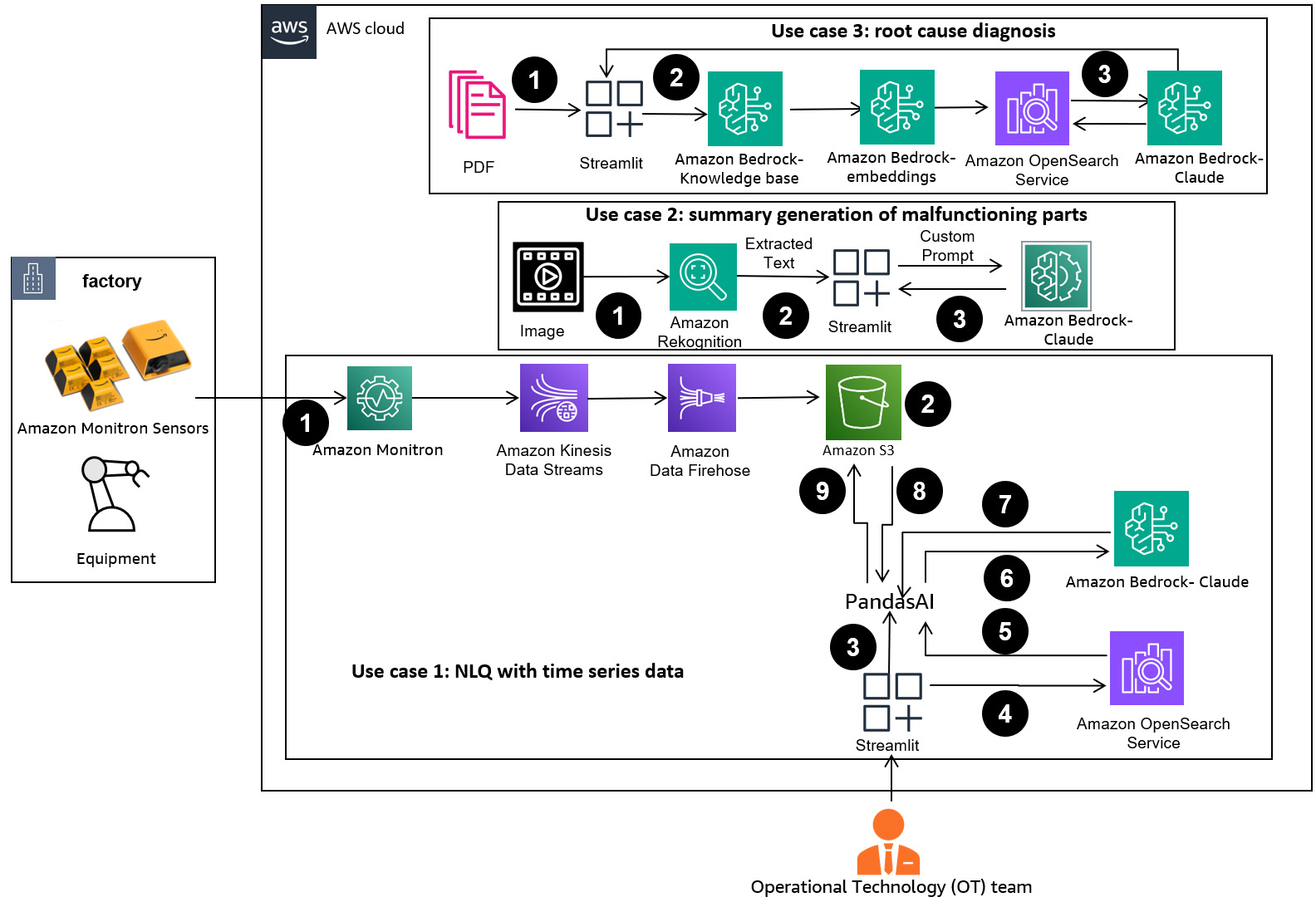
ШІ та ML революціонізують виробництво, але залишаються проблеми з обробкою величезних неструктурованих даних. Генеративний ШІ, такий як Claude, демократизує доступ до ШІ для малих виробників, підвищуючи продуктивність і швидкість прийняття рішень. Підказки з декількома кадрами покращують точність генерації коду для складних NLQ, підвищуючи можливості FM в розширеній обробці даних для промислов...

Поспішний запуск Google Gemini демонструє важливість ретельного тестування ШІ, як підкреслив Сергій Брін. У статті йдеться про негламурну, але критично важливу роль тестування в управлінні продуктами ШІ, підкреслюється необхідність встановлення чітких цілей тестування та уникнення таких проблем, як сексизм і расизм при створенні іміджу.
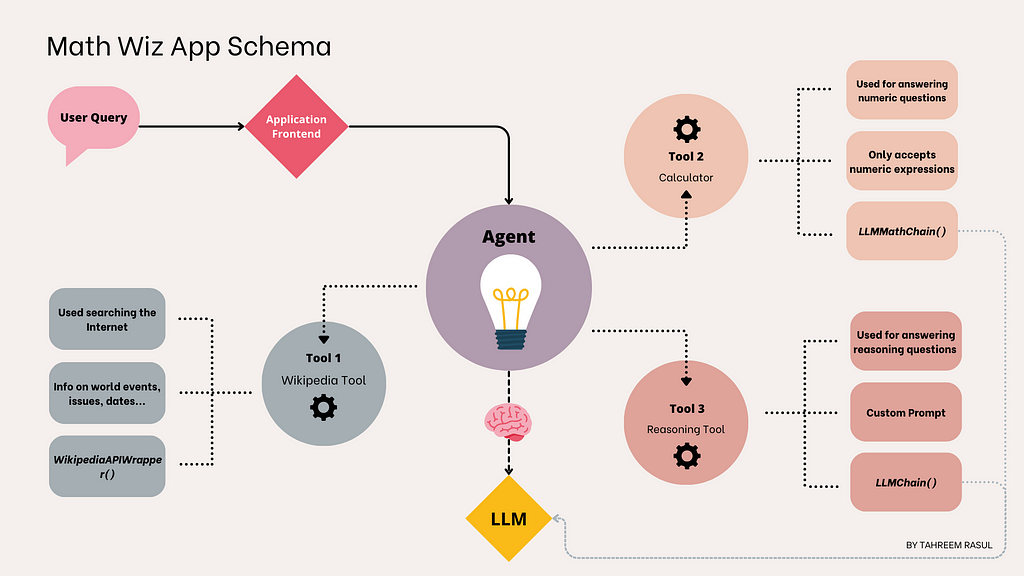
Підручник з використання агентів LangChain з GPT3.5 OpenAI для створення математичного додатку. Магістрантам важко дається математика через брак навчальних даних та числових уявлень. Агенти LangChain можуть допомогти подолати ці обмеження.