
Керолайн Улер обговорює революцію даних у біології та потенціал машинного навчання для відкриття нового розуміння біологічних систем. Такі досягнення, як секвенування ДНК та моделі зору, формують нову еру в біології, надихаючи на інноваційні дослідження в галузі машинного навчання.
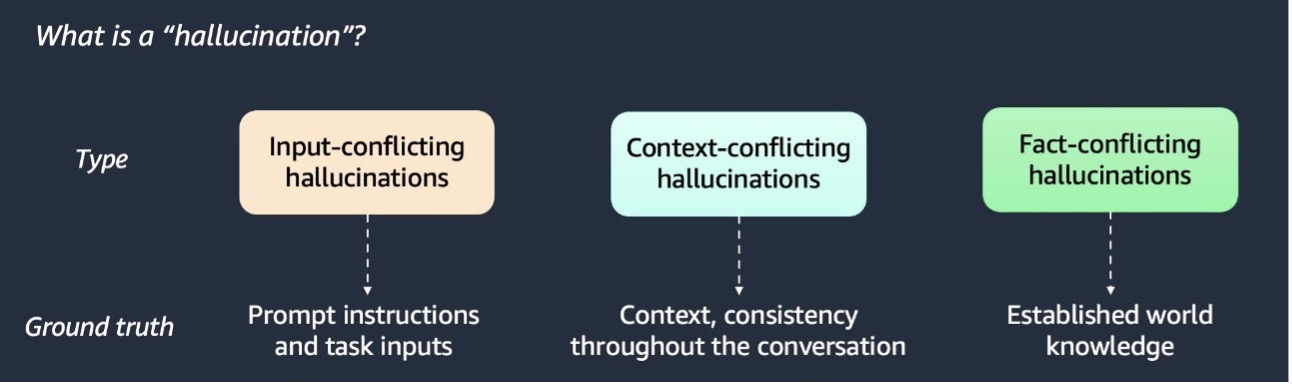
RAG покращує реакції ШІ завдяки включенню додаткових даних. Виявлення та пом'якшення галюцинацій ШІ має вирішальне значення для точності.

BERTopic, бібліотека python для трансформаційного моделювання тем, використовує 6 основних модулів, щоб швидше обробляти фінансові новини та виявляти зміну трендів у часі. Вона включає в себе вбудовування, зменшення розмірності, кластеризацію, векторизатори, c-TF-IDF та моделі представлення для ідентифікації ключових термінів у документах.
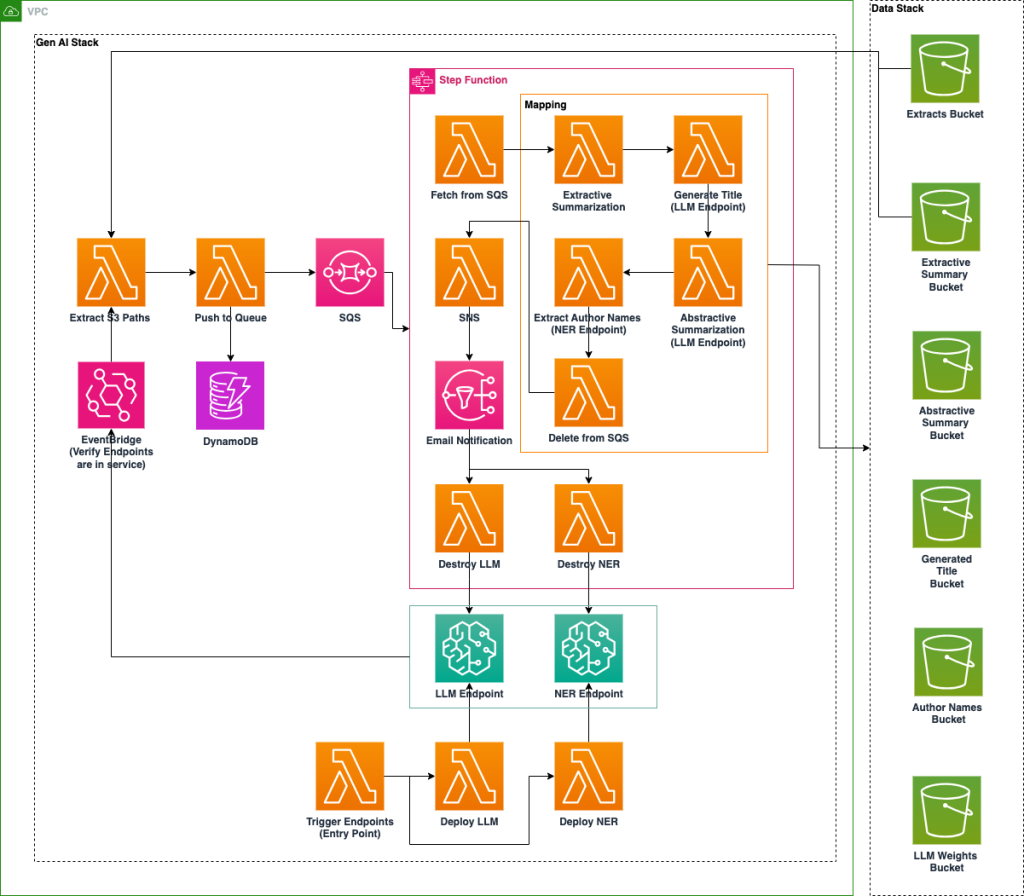
Національна лабораторія США впроваджує платформу штучного інтелекту на Amazon SageMaker для підвищення доступності архівних даних за допомогою технологій NER і LLM. Оптимізована за витратами система автоматизує збагачення метаданих, класифікацію документів та узагальнення для покращення організації та пошуку документів.
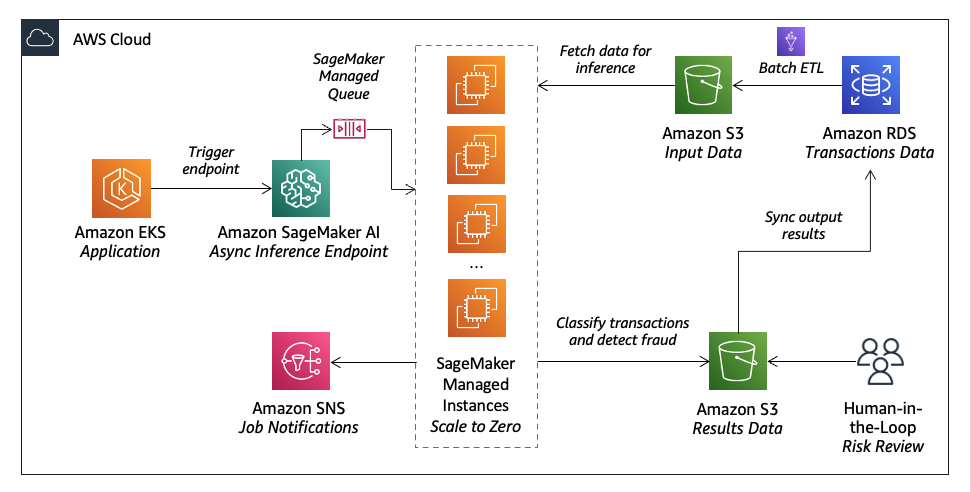
Lumi, австралійський фінтех-кредитор, використовує Amazon SageMaker AI для надання швидких кредитних рішень з точною кредитною оцінкою. Вони поєднують машинне навчання з людськими судженнями для ефективного і точного управління ризиками.

Мультимодальні вбудовування об'єднують текстові та графічні дані в єдину модель, уможливлюючи крос-модальні додатки, такі як підписи до зображень і модерація контенту. CLIP вирівнює представлення тексту і зображень для класифікації зображень з нульового кадру, демонструючи переваги спільного простору для вбудовування.
Метаморфози ML, процес, що об'єднує різні моделі разом, може значно покращити якість моделей, виходячи за рамки традиційних методів навчання. Дистиляція знань переносить знання з великої моделі в меншу, більш ефективну, що призводить до швидших і легших моделей з покращеною продуктивністю.
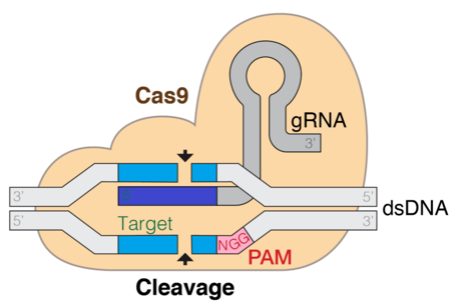
Технологія CRISPR трансформує редагування генів, використовуючи обчислювальну біологію для прогнозування ефективності гРНК за допомогою великих мовних моделей, таких як DNABERT. Методи точного налаштування за параметрами, такі як LoRA, є ключовими в оптимізації LLM для задач молекулярної біології.
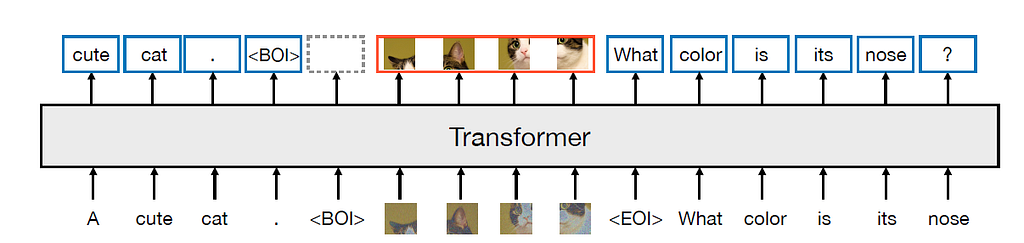
Meta та Waymo представляють модель Transfusion, що поєднує трансформатор та дифузію для мультимодального прогнозування. Модель Transfusion використовує двонаправлену увагу трансформатора для маркерів зображень та завдання для попереднього навчання для тексту та зображень.
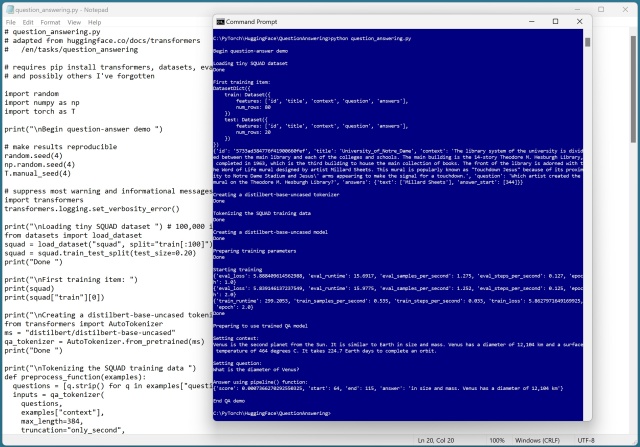
HuggingFace пропонує велику бібліотеку попередньо навчених мовних і графічних моделей для завдань з природною мовою. Незважаючи на деякі помилки, система контролю якості демонструє простоту та ефективність використання функції pipeline().
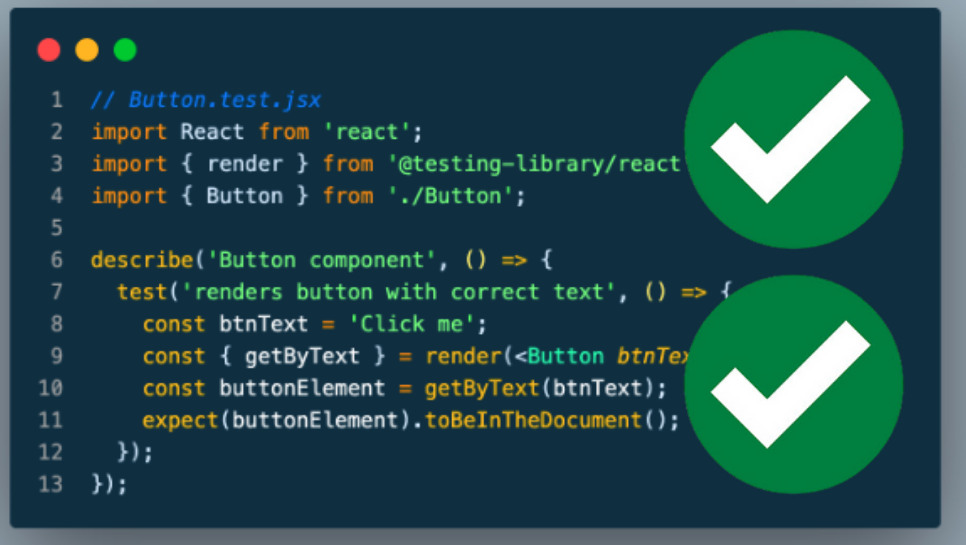
Дізнайтеся, як тестувати проекти машинного навчання за допомогою Pytest та Pytest-cov. Посібник зосереджується на BERT для класифікації тексту з використанням стандартних галузевих бібліотек.

Розпізнавання іменних об'єктів (NER) витягує об'єкти з тексту, традиційно вимагаючи точного налаштування. Нові великі мовні моделі уможливлюють NER з нуля, як-от Amazon Bedrock's LLMs, революціонізуючи виокремлення сутностей.
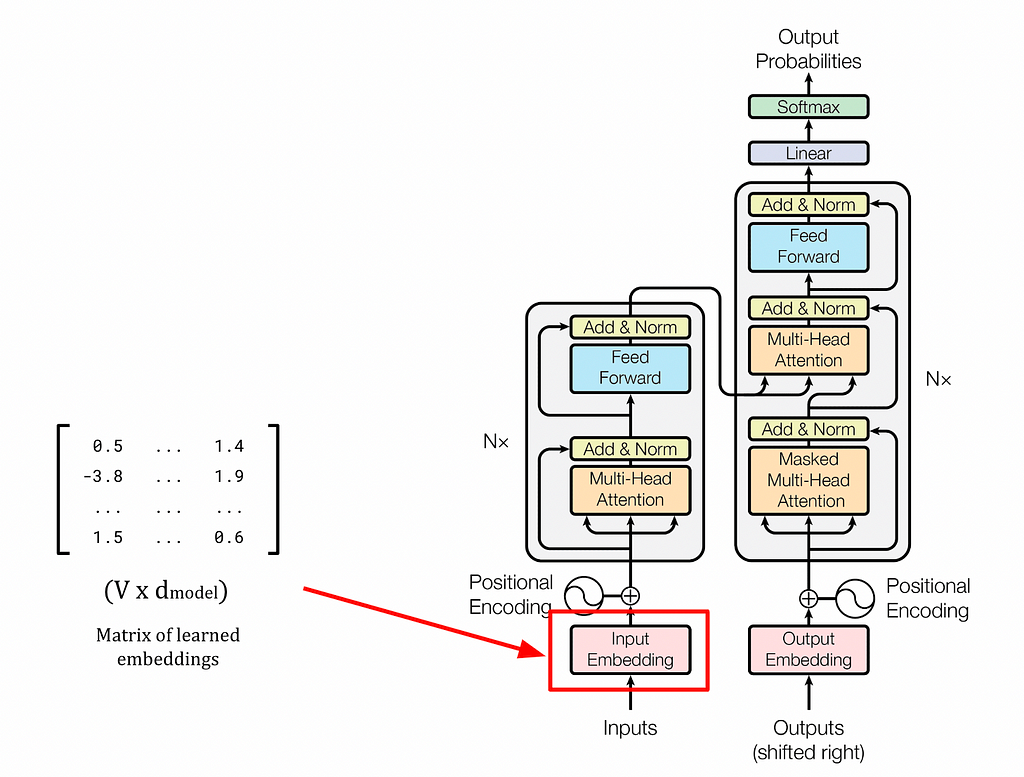
Великі мовні моделі, такі як GPT та BERT, покладаються на архітектуру трансформатора та механізм самоуваги для створення контекстуально багатих вбудовувань, що революціонізувало НЛП. Статичні вставки, такі як word2vec, не здатні вловити контекстну інформацію, що підкреслює важливість динамічних вставок у мовних моделях.
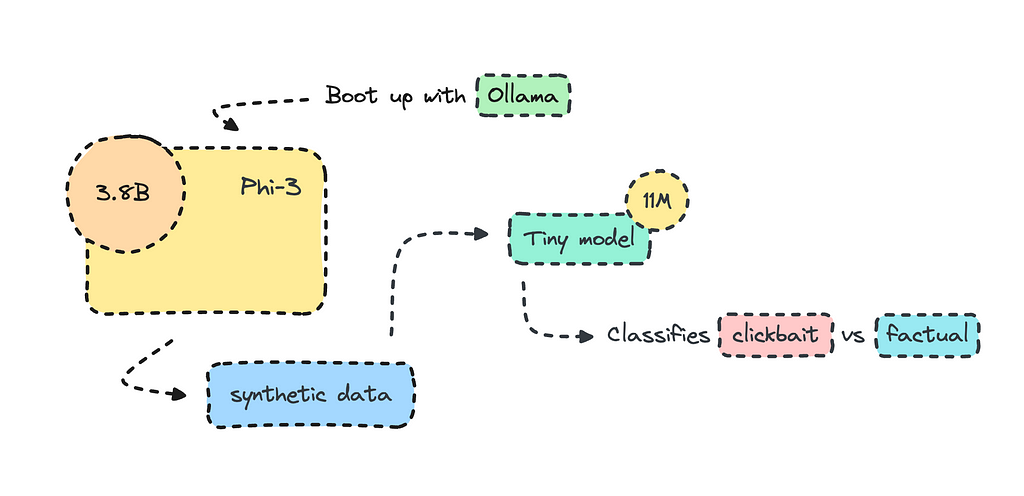
Phi-3 від Microsoft створює менші, оптимізовані моделі класифікації тексту, перевершуючи більші моделі, такі як GPT-3. Генерація синтетичних даних за допомогою Phi-3 через Ollama покращує робочі процеси ШІ для конкретних випадків використання, пропонуючи розуміння класифікації клікбейтів та фактичного контенту.
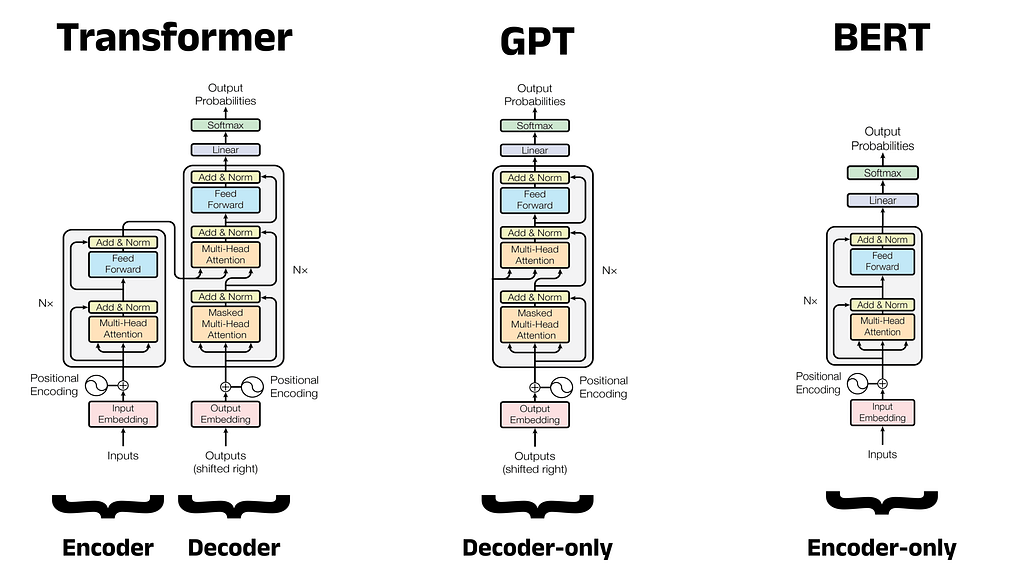
BERT, розроблений Google AI Language, є революційною моделлю великої мови для обробки природної мови. Її архітектура та фокус на розумінні природної мови змінили ландшафт NLP, надихнувши такі моделі, як RoBERTa та DistilBERT.
Ознайомтеся з останніми революційними дослідженнями щодо застосування штучного інтелекту в охороні здоров'я. Дізнайтеся, як такі компанії, як IBM і Google, революціонізують догляд за пацієнтами за допомогою інноваційних технологій.

У 2021 році фармацевтична промисловість згенерувала 550 мільярдів доларів доходу в США, а до 2022 року прогнозовані витрати на діяльність з фармаконагляду становитимуть 384 мільярди доларів. Для вирішення проблем моніторингу небажаних явищ розроблено рішення на основі машинного навчання з використанням Amazon SageMaker та моделі BioBERT від Hugging Face, що забезпечує автоматизоване виявлення ...
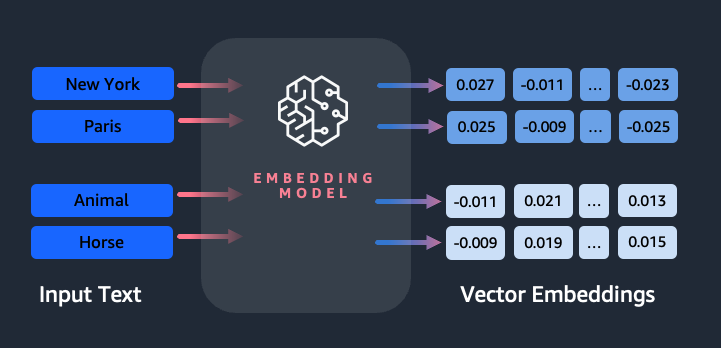
Amazon Titan Text Embeddings - це модель вбудовування тексту, яка перетворює текст природною мовою в числові представлення для пошуку, персоналізації та кластеризації. Вона використовує алгоритми вбудовування слів і великі мовні моделі для фіксації семантичних зв'язків і покращення подальших завдань NLP.
У 2017 році Google Brain представив Transformer - гнучку архітектуру, яка перевершила існуючі підходи до глибокого навчання, і тепер використовується в таких моделях, як BERT і GPT. GPT, модель декодера, використовує завдання мовного моделювання для генерації нових послідовностей і дотримується двоетапної схеми попереднього навчання та точного налаштування.
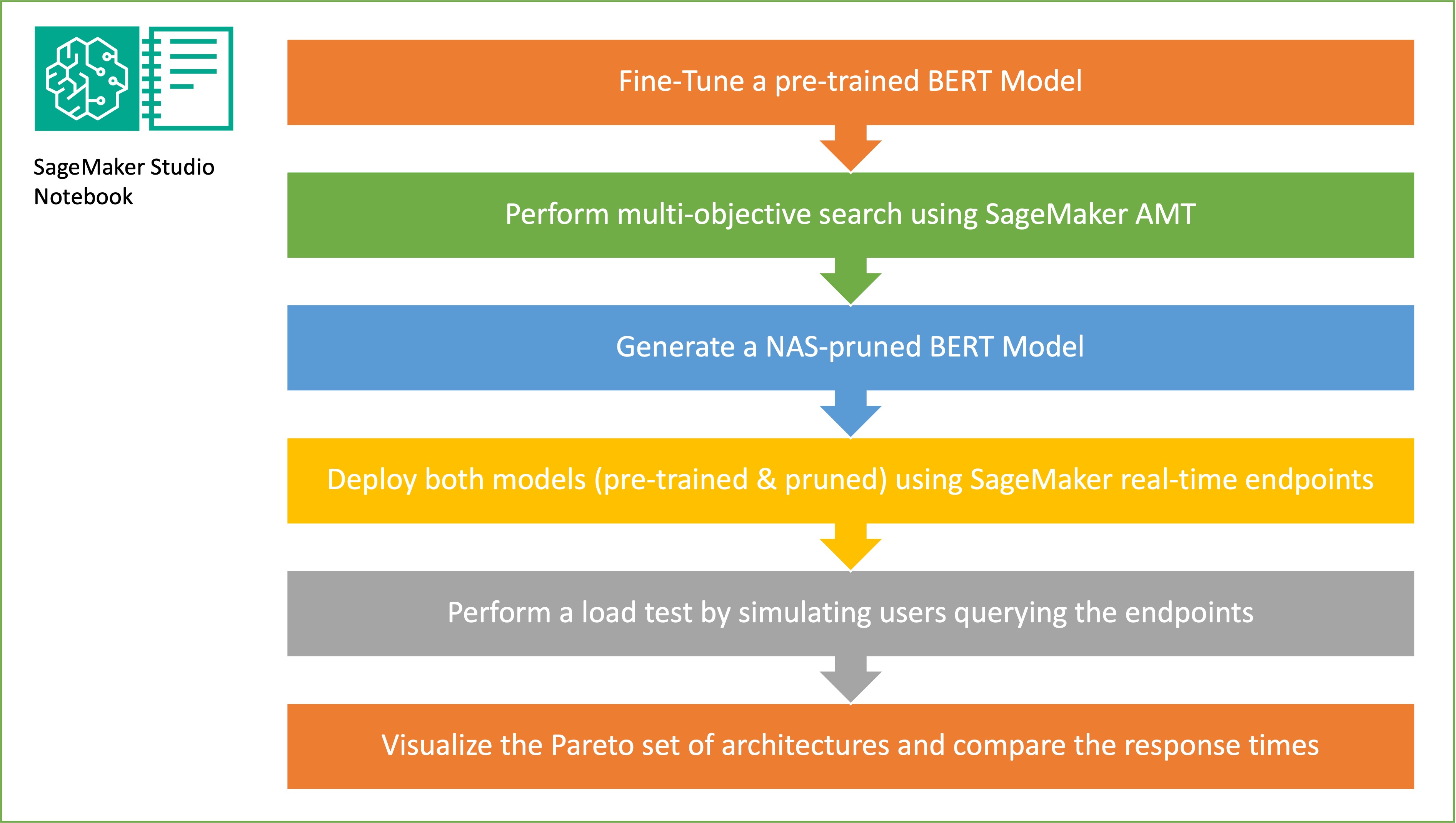
Ця стаття демонструє, як пошук нейронної архітектури може бути використаний для стиснення точно налаштованої BERT-моделі, покращуючи продуктивність і скорочуючи час виведення. Застосовуючи структурне обрізання, можна зменшити розмір і складність моделі, що призведе до швидшого часу відгуку і підвищення ефективності використання ресурсів.
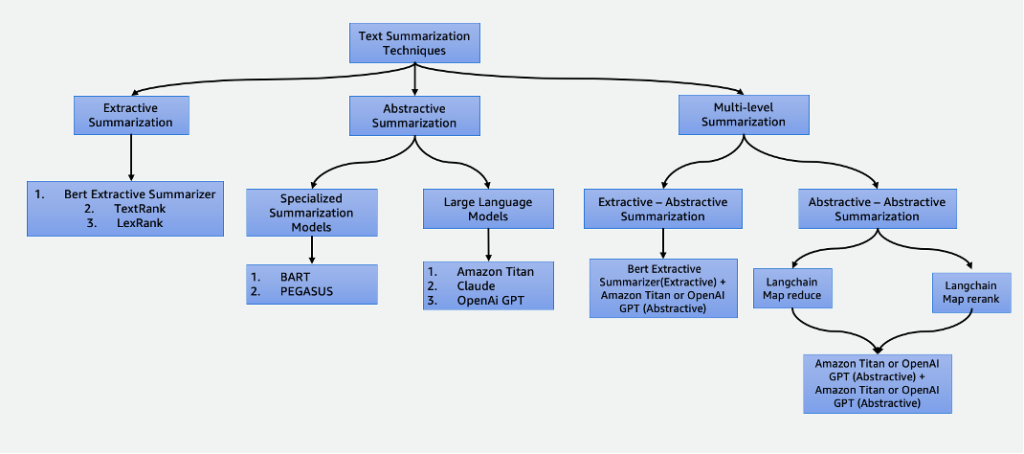
У нашому світі, де панують дані, узагальнення має важливе значення, заощаджуючи час і покращуючи процес прийняття рішень. Він має різні застосування, включаючи агрегацію новин, узагальнення юридичних документів і фінансовий аналіз. З розвитком НЛП і штучного інтелекту такі методи, як екстрактивне та абстрактне узагальнення, стають все більш доступними та ефективними.