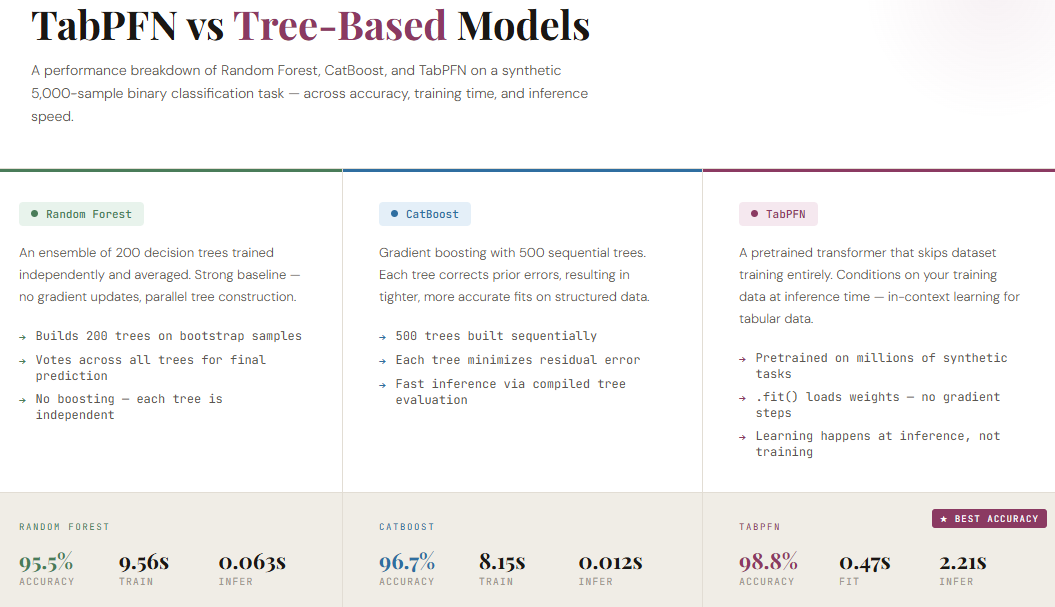
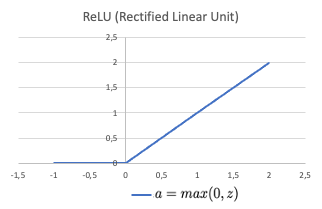
Табличні дані відіграють ключову роль у машинному навчанні, а деревоподібні моделі, такі як TabPFN, кидають виклик традиційним підходам, перевершуючи за ефективністю XGBoost та CatBoost. TabPFN-2.5 забезпечує кращу продуктивність, зменшує обсяг ручної роботи та прискорює процес інференції для практичного впровадження.
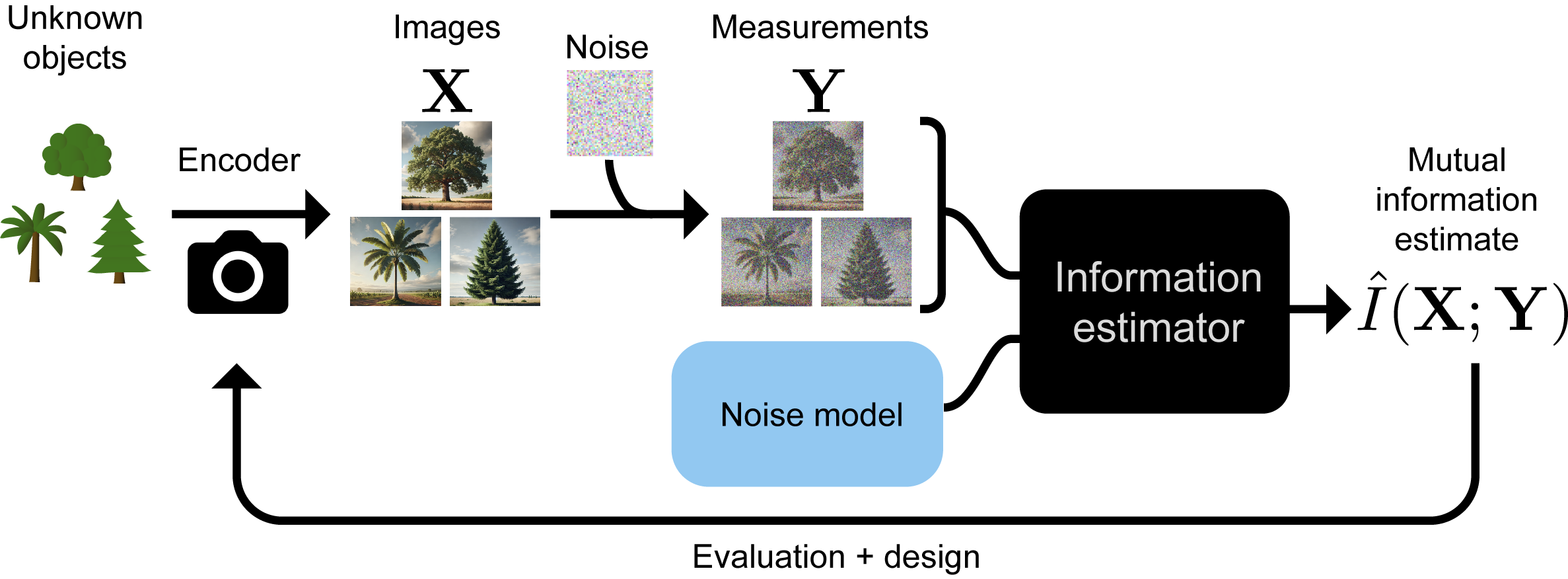
Кодер перетворює зображення об’єктів на зображення без шуму, кількісно оцінюючи, наскільки точно вимірювання дозволяють розрізнити об’єкти. Штучний інтелект здатний виокремлювати корисну інформацію навіть у тих випадках, коли вона закодована у формі, яку людина не може розтлумачити, оптимізуючи системи візуалізації з урахуванням їхнього інформаційного наповнення.
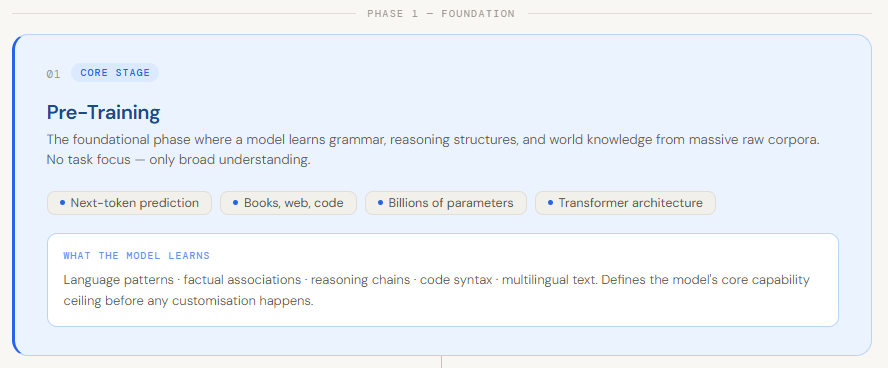
Навчання сучасної великої мовної моделі передбачає попереднє навчання загальним мовним шаблонам, а потім — контрольоване точне налаштування для виконання конкретних завдань. Такі методи, як LoRA та RLHF, дозволяють вдосконалити модель, що дає змогу впроваджувати її в реальні системи для досягнення оптимальної продуктивності та забезпечення максимальної користі.
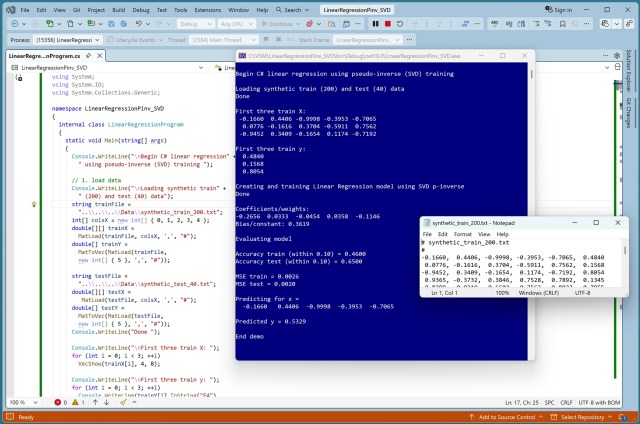
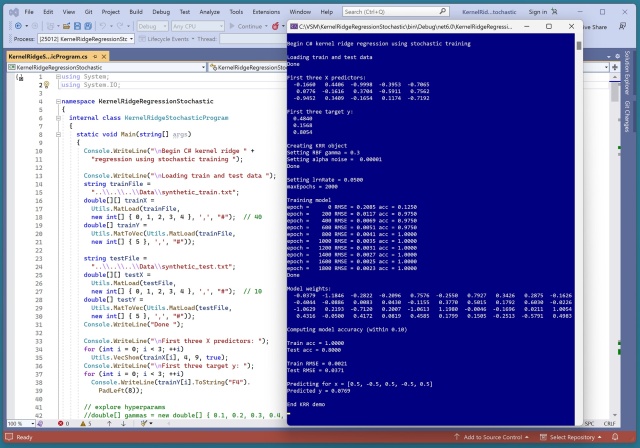
Порівняння методів псевдооберненої матриці Мура-Пенроуза для навчання лінійної регресії з акцентом на складність та стабільність алгоритму SVD Householder+QR. У демонстрації показано точність реалізації на C# при прогнозуванні значень синтетичного набору даних.
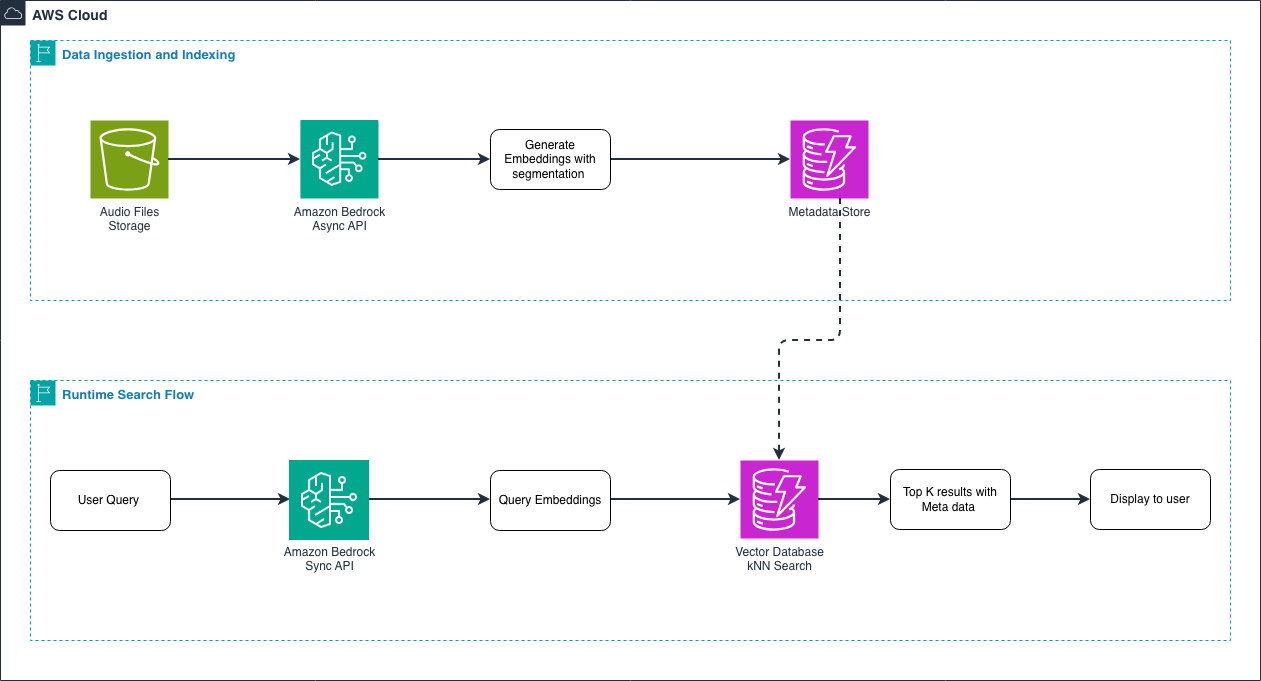
Мультимодальні вбудовані моделі Amazon Nova перетворюють аудіоконтент на дані, придатні для пошуку, фіксуючи інтонацію, емоції та навколишні звуки. Модель підтримує текст, зображення, відео та аудіо для міжмодального пошуку, пропонуючи практичні можливості пошуку для
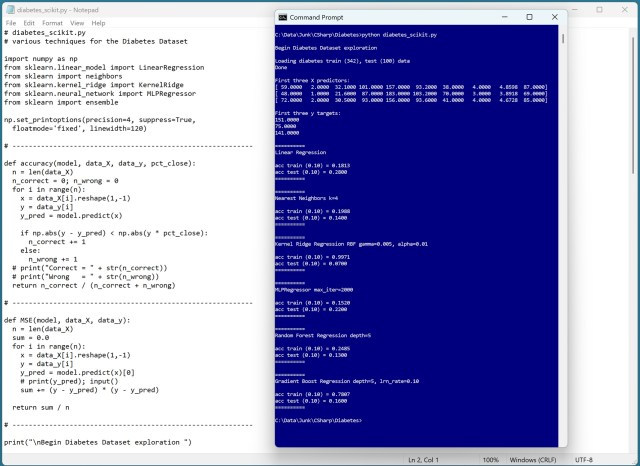
Цільове значення набору даних scikit Diabetes Dataset не піддається прогнозуванню, на відміну від інших змінних. Шість моделей не змогли точно передбачити діабет.
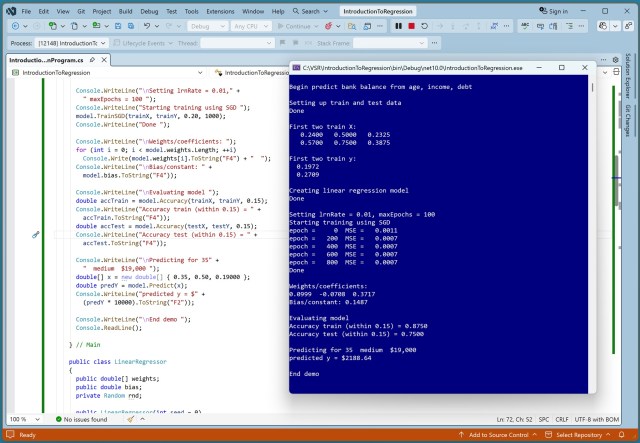
Автор працює над книгою про класичні методи регресійного аналізу з використанням C#. У демонстраційному прикладі лінійної регресії за допомогою машинного навчання точно прогнозується стан банківського рахунку.
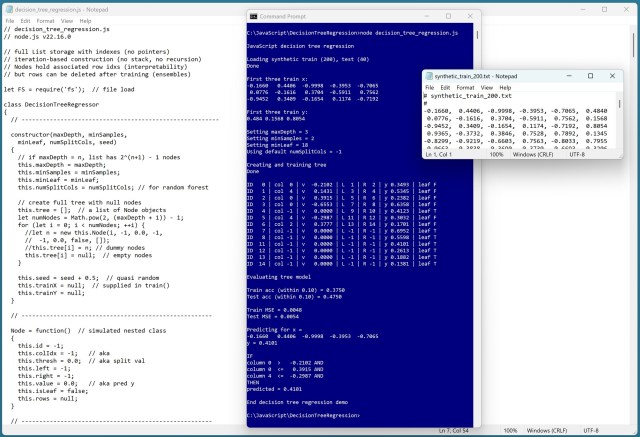
Регресія на основі дерева рішень прогнозує значення на основі правил «якщо-то» у вигляді деревоподібної структури. Ця реалізована на JavaScript модель мінімізує дисперсію та забезпечує високу точність прогнозування синтетичних даних.
Сучасні технології машинного навчання допомагають виявляти сонячні спалахи шляхом аналізу рентгенівського випромінювання. Сучасні моделі глибокого навчання, такі як мережі LSTM, забезпечують надійне виявлення аномалій у багатоканальних рентгенівських даних для всебічного моніторингу сонячної активності.
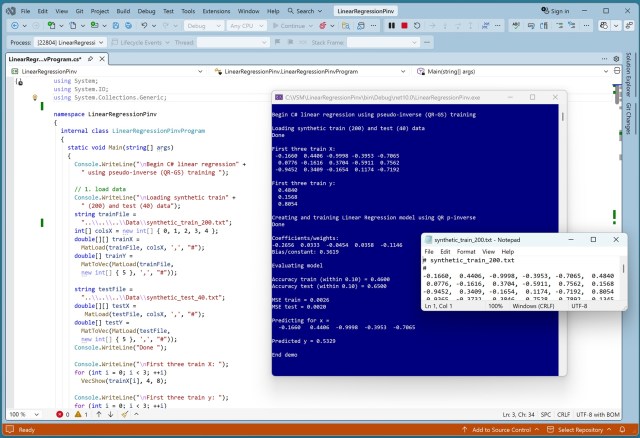
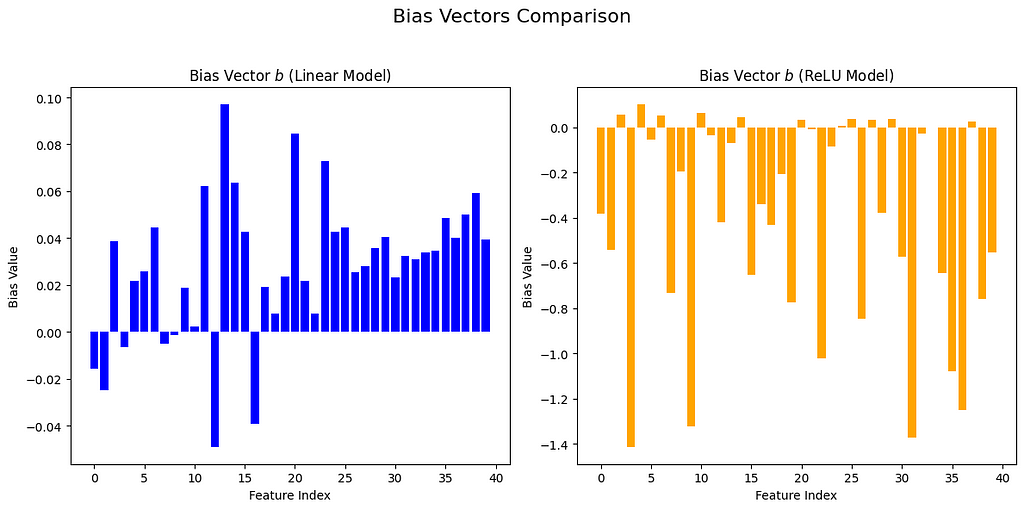
Лінійна регресія — це ключовий метод машинного навчання для прогнозування числових значень із використанням ваг та зміщення. Методи навчання включають стохастичний градієнтний спуск та псевдообернену матрицю, отриману за допомогою SVD або QR-розкладу, кожний із яких має різну складність та ефективність.
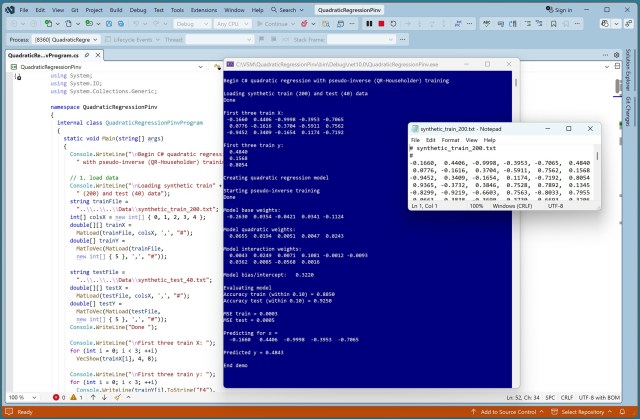
Регресія на основі машинного навчання має на меті прогнозування значень. Квадратична регресія з псевдооберненим навчанням є дуже ефективною без використання додаткових параметрів.

У статті VSM «Регресія методом випадкового лісу на C#» пояснюється, як система на основі методу випадкового лісу може підвищити точність прогнозування завдяки навчанню на різних підмножинах даних. У демонстраційному прикладі показано цей процес, підкреслюючи точність системи та її потенціал для прогнозування складних структур у синтетичних даних.
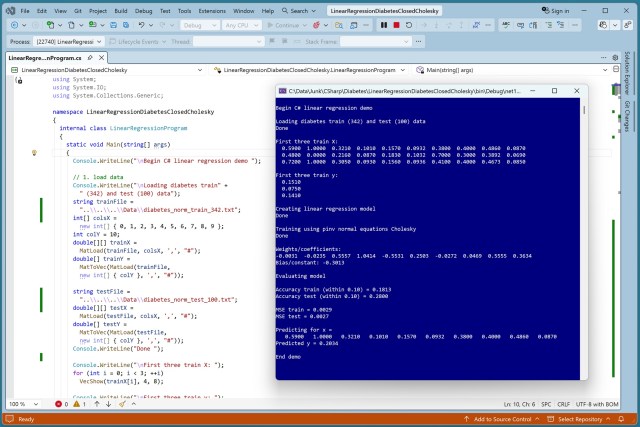
До набору даних про діабет було застосовано модель лінійної регресії з низькою точністю, яка послужила базовим показником для порівняння з іншими методами регресії. Ця модель, реалізована на мові C#, продемонструвала точність лише 18,13 % на навчальних даних і 28,00 % на тестових даних.
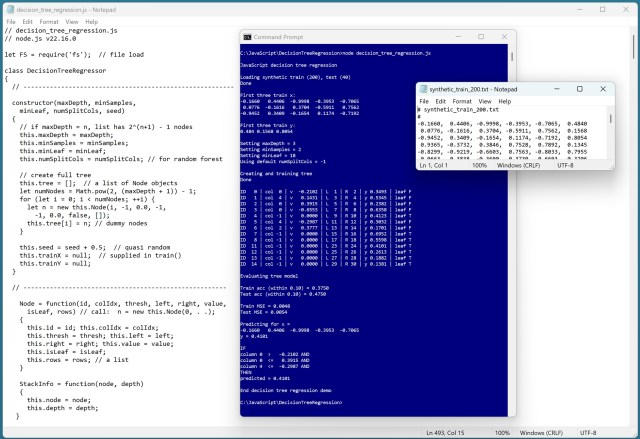
Регресія на основі дерева рішень дозволяє прогнозувати числові значення за допомогою правил «якщо-то». Демонстрація реалізації на JavaScript показує високу точність прогнозування синтетичних даних.

Короткий зміст: У березневому випуску журналу Microsoft Visual Studio Magazine за 2026 рік розглядається квадратична регресія, яка є розширенням лінійної регресії, та демонструється її простота, інтерпретованість і навчання за допомогою стохастичного градієнтного спуску з використанням JavaScript. Демонстрація ілюструє точність моделі та прогнози в рамках набору даних, згенерованого нейронною ...
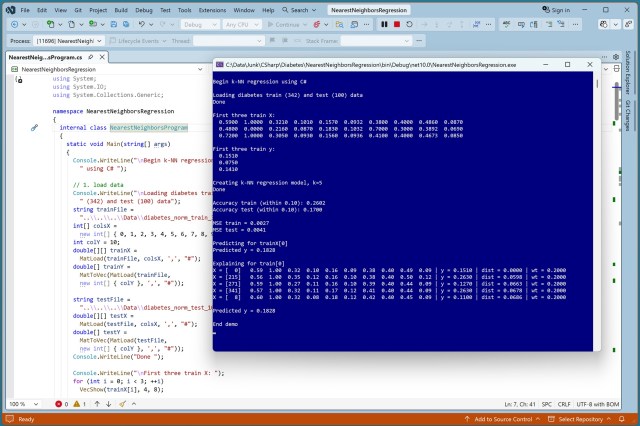
Модель регресії найближчих сусідів, застосована до набору даних про діабет для базового порівняння з передовими методами регресії. Проста, але зрозуміла реалізація на C# з докладними поясненнями прогнозів.

Дослідження, що базуються на цікавості, сприяють розвитку штучного інтелекту в галузі фізики та хімії. MIT є лідером в інтеграції AI+MPS для майбутніх проривів.

Дізнайтеся про регресію на основі дерева рішень, реалізовану з нуля за допомогою C# без покажчиків або рекурсії, у журналі Visual Studio Magazine. Дерева рішень забезпечують інтерпретованість і можуть використовуватися окремо або в ансамблях для завдань регресії.
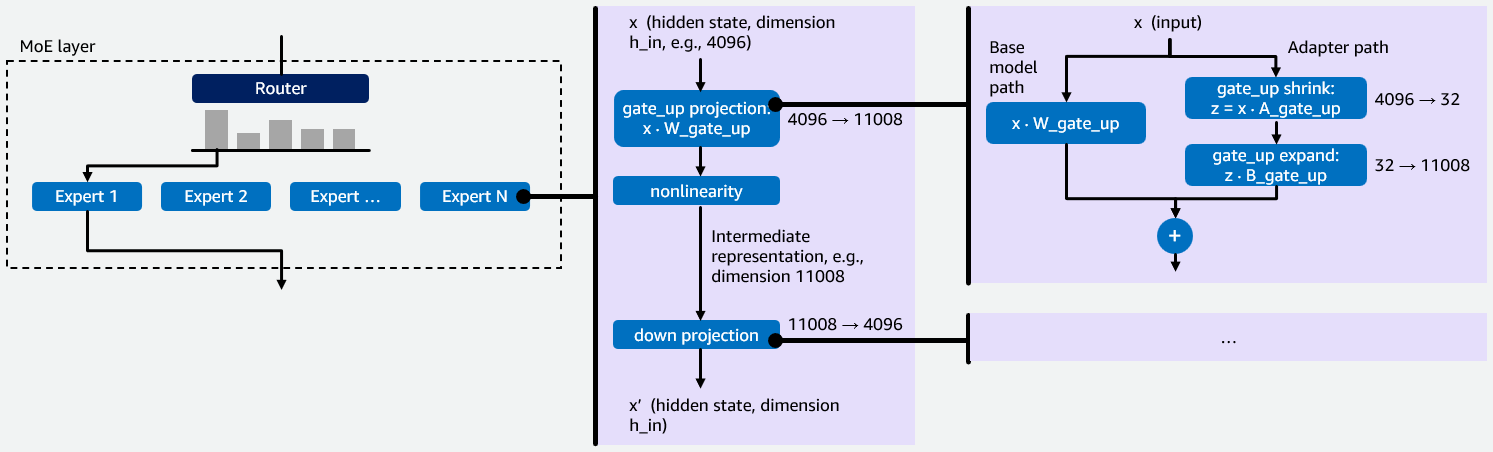
Ефективно розподіляйте потужність графічного процесора за допомогою Multi-LoRA для моделей MoE, таких як GPT-OSS. Оптимізації Amazon покращують продуктивність для хостингу щільних моделей.
Стаття «Лінійна регресія з псевдоінверсним навчанням за допомогою JavaScript» пояснює реалізацію псевдоінверсного навчання за методом Мура-Пенроуза для точних прогнозів. Ця техніка дозволяє подолати труднощі у визначенні ваг і зміщення для моделей лінійної регресії.

Доцент Массачусетського технологічного інституту Рафаель Гомес-Бомбареллі є піонером у використанні штучного інтелекту для трансформації наукових досліджень, розробляючи нові матеріали з реальним застосуванням, такі як батареї та OLED-дисплеї. Його робота поєднує фізичні симуляції з машинним навчанням з метою створення наукової платформи надрозуму для таких галузей, як біологічні науки та

Короткий зміст: У січневому випуску журналу Microsoft Visual Studio Magazine за 2026 рік розглядається квадратична регресія з тренуванням SGD за допомогою C#. Квадратична регресія покращує лінійну регресію для обробки складних даних, забезпечуючи кращу інтерпретованість моделі, незважаючи на дещо нижчу точність прогнозування порівняно з нейронними мережами.
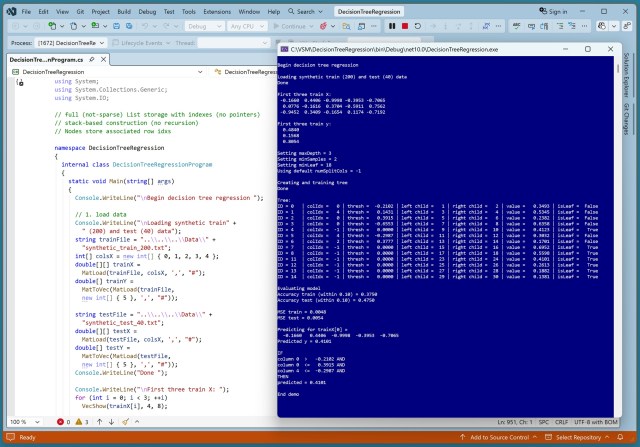
Регресія дерева рішень прогнозує значення за допомогою правил «якщо-то» в C#. Нейронна мережа генерувала синтетичні дані для навчання та тестування.
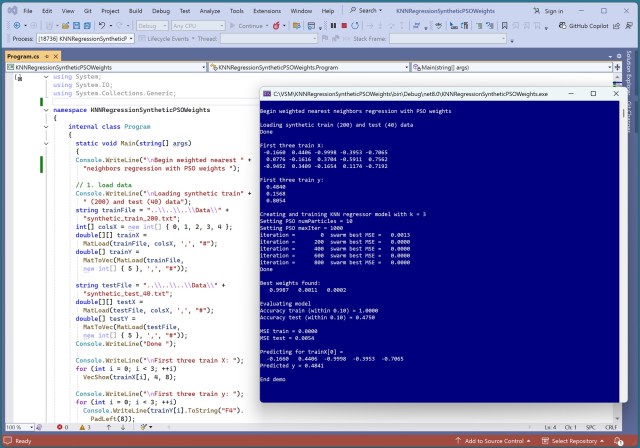
Невдала спроба оптимізації ваг у регресії найближчих сусідів за допомогою алгоритму PSO. Надмірне пристосування навчальних даних, неякісні прогнози щодо нових даних.
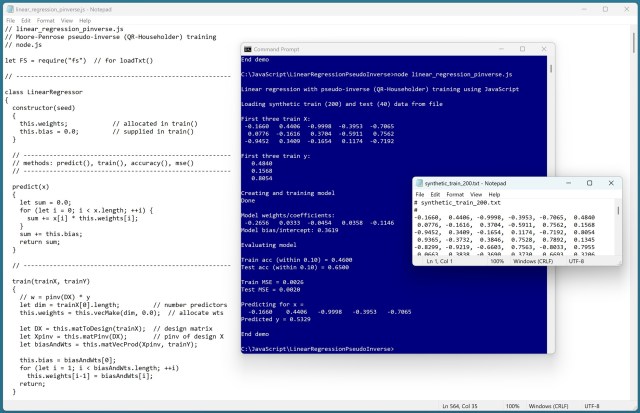
Пояснення рівняння лінійної регресії з використанням методів навчання, таких як стохастичний градієнтний спуск і матрична псевдообернена матриця. Демо-версія демонструє низьку точність через складність даних, але лінійна регресія є надійною відправною точкою для порівняння з просунутими техніками, такими як нейронні мережі.
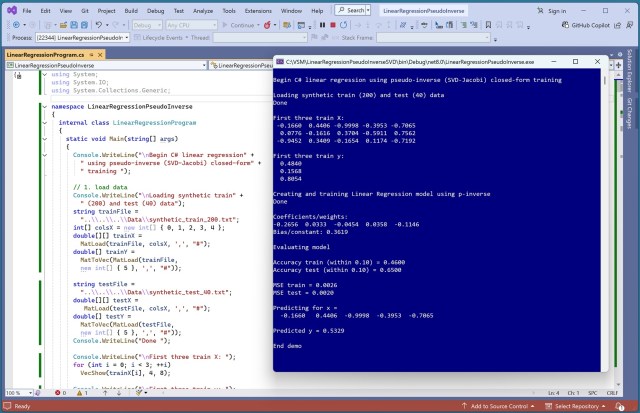
Пояснення рівняння лінійної регресії на прикладі. Демонстрація таких методів навчання моделей, як SGD і SVD.
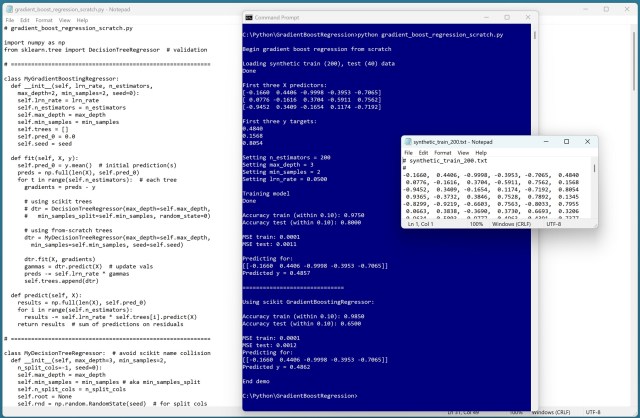
Регресія з градієнтним підсиленням (GBR) використовує дерева рішень для прогнозування числових значень. Демонстраційна версія GBR на Python, створена з нуля, досягає високої точності порівняно з реалізацією scikit.

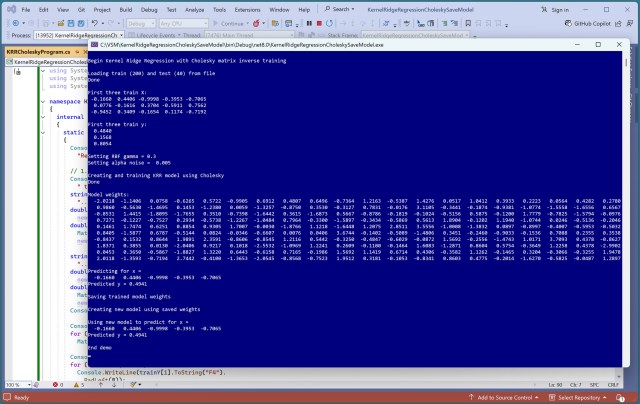
У статті розглядається регресія ядра в JavaScript, демонструється навчання моделі та точність за допомогою оберненої матриці Холеського. Демонстраційна програма висвітлює функцію ядра RBF та дві основні техніки навчання: обернену матрицю та стохастичний градієнтний спуск.
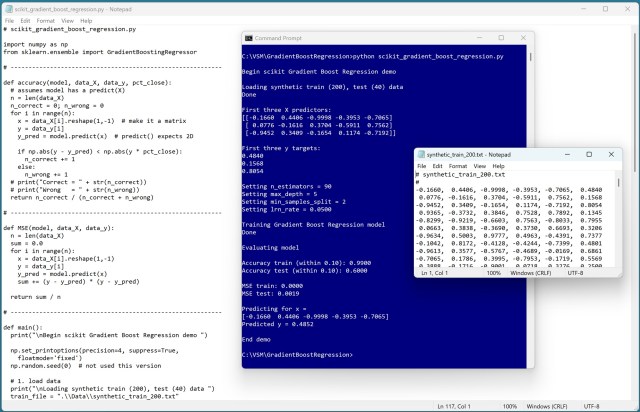
Для прогнозування числових значень використовуються методи регресії, такі як регресія дерева рішень і градієнтне підсилення, причому останній створює набір дерев рішень для прогнозування залишків. Незважаючи на високу точність в навчальних даних, перенавчання залишається основною слабкістю, як показано в демонстраційній програмі регресії scikit AdaBoost.
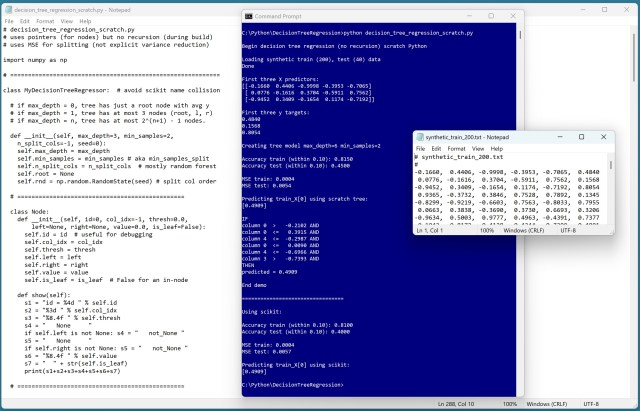
Демонстрація регресії дерева рішень Python, перероблена без рекурсії, з використанням стека. Алгоритм був налаштований для зменшення дисперсії, а не MSE, відповідно до модуля scikit.
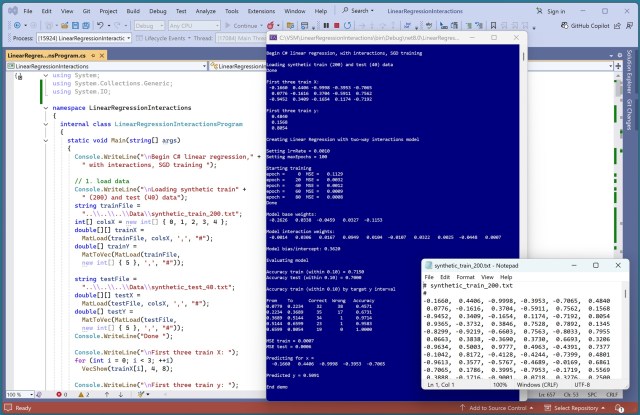
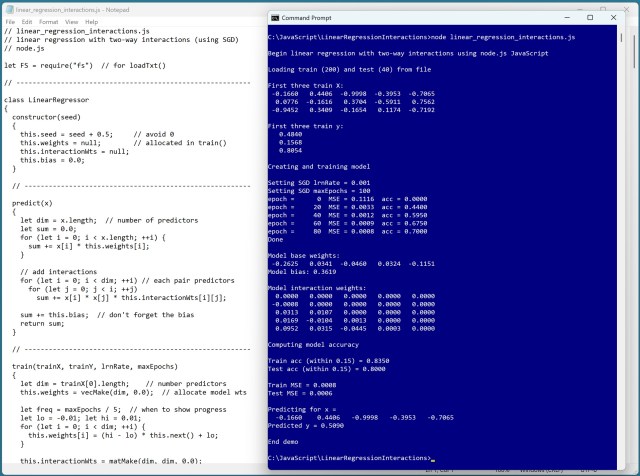
Лінійна регресія C# з двосторонніми взаємодіями досягла точності 71,50%, що варіюється залежно від цільових груп y. Модель включала 6 додаткових ваг для двосторонніх взаємодій, що підвищило прогнозну здатність.
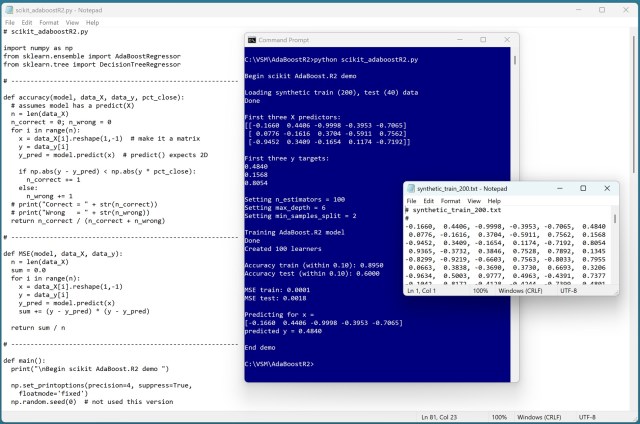
Завдання регресії полягають у прогнозуванні окремого числового значення за допомогою таких методів, як регресія на основі дерев рішень та ансамблеві методи, такі як випадковий ліс та градієнтне підсилення. Демонстрація AdaBoost.R2 у бібліотеці scikit-learn мови Python показує підвищену точність прогнозування за допомогою зважених дерев рішень.
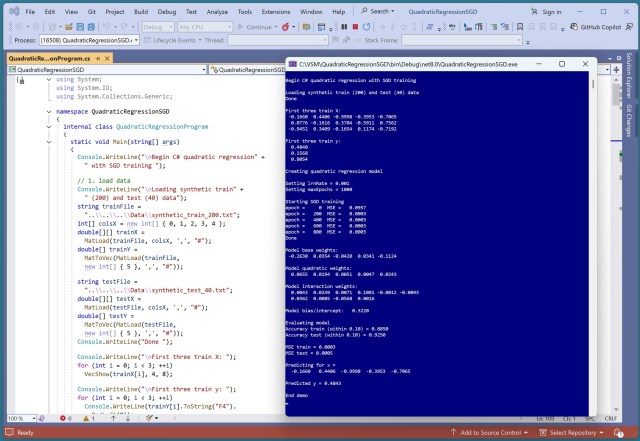
Лінійна регресія є базовою, але не справляється з нелінійними даними; квадратична регресія розширює її можливості для обробки складних даних. Демонстрація на C# показує точність квадратичної регресії з використанням синтетичних даних і генерації нейронних мереж.
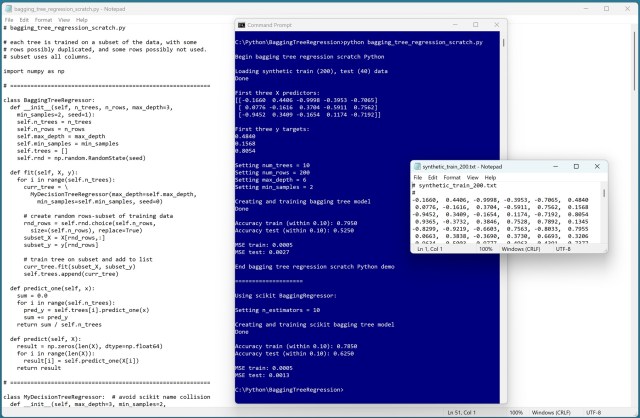
Наївні регресійні моделі з деревом рішень надмірно пристосовуються до навчальних даних. Техніки багінгу та випадкового лісу борються з надмірним пристосуванням, використовуючи підмножини для навчання.

Дослідники MIT CSAIL виявили, що короткострокове керівництво може значно покращити продуктивність нейронних мереж, які раніше вважалися «неефективними», шляхом узгодження внутрішніх представлень. На відміну від дистиляції знань, керівництво безпосередньо передає структурні знання, використовуючи архітектурні упередження ненавчених мереж для ефективного навчання.

Дев'ять співробітників MIT, серед яких Зонгі Лі та Тесс Смідт, отримали звання AI2050 Fellows від Schmidt Sciences. Вони зосереджуються на прискоренні наукових проривів у галузі штучного інтелекту, астрофізики, біологічних наук тощо. Лі досліджує методи нейронних операторів для наукових обчислень, а Смідт працює над алгоритмами для фізичних систем на стику фізики, геометрії та машинного навчання.

Однорукі роботи компанії Pickle Robot Company самостійно розвантажують причепи, що дозволяє зменшити кількість травм на складі та підвищити ефективність роботи. Засновники компанії, Мейер та Айзенштейн, перейшли від консалтингу до робототехніки, використовуючи штучний інтелект та машинне навчання для революціонізації автоматизації ланцюгів постачання.

Нові моделі міркування, такі як ChatGPT, чудово справляються зі складними завданнями, наприклад, з математичними задачами та кодуванням. Дослідники MIT виявили, що вони обробляють інформацію подібно до людей, що відкриває перспективи для подальшого розвитку штучного інтелекту.
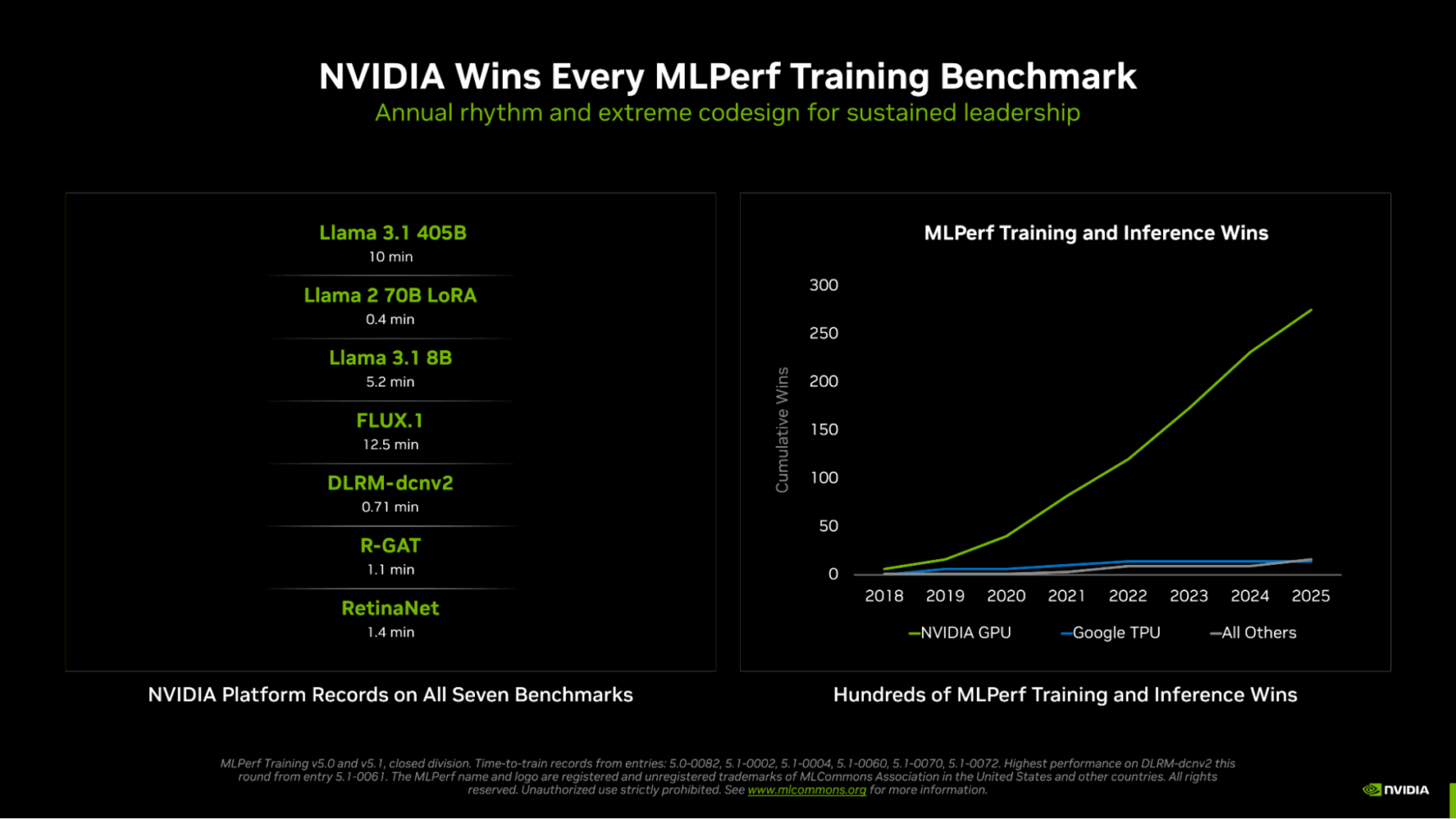
NVIDIA домінує в MLPerf Training v5.1, продемонструвавши найшвидший час навчання різних моделей штучного інтелекту. Архітектура графічного процесора Blackwell Ultra забезпечує рекордну продуктивність із точністю FP4, встановлюючи новий стандарт у галузі обчислень штучного інтелекту.
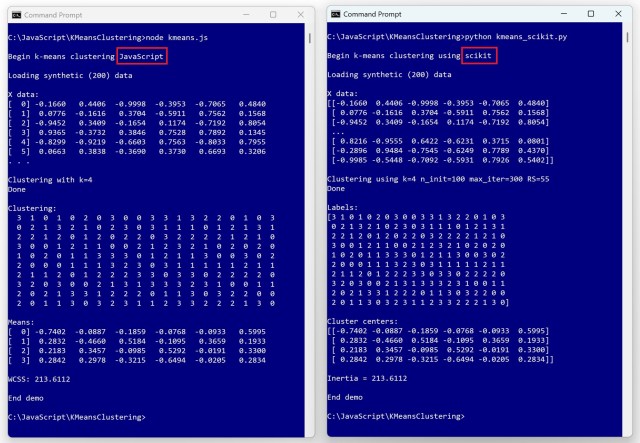
Демонстрація кластеризації JavaScript k-means з використанням синтетичних даних у порівнянні з модулем scikit-learn. Ідентичні результати, отримані за допомогою коду scikit після коригування параметрів.

Студенти MIT-IBM Watson AI Lab підвищують надійність штучного інтелекту за допомогою інноваційних методів і технологій, забезпечуючи більш надійні та стійкі моделі. Їхні дослідження зосереджені на розумінні та покращенні невизначеності великих навчальних моделей, що має вирішальне значення для таких додатків, як сімейство Granite Guardian від IBM.
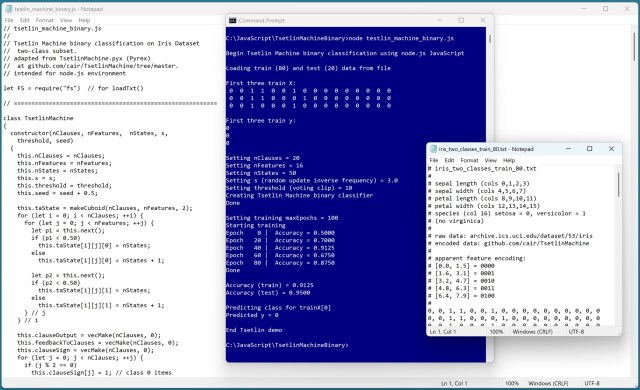
Нова технологія бінарної класифікації Tsetlin Machine з високою точністю прогнозує види за допомогою унікального алгоритму. Демо-версія демонструє сильні та слабкі сторони бінарного кодування в машинному навчанні.
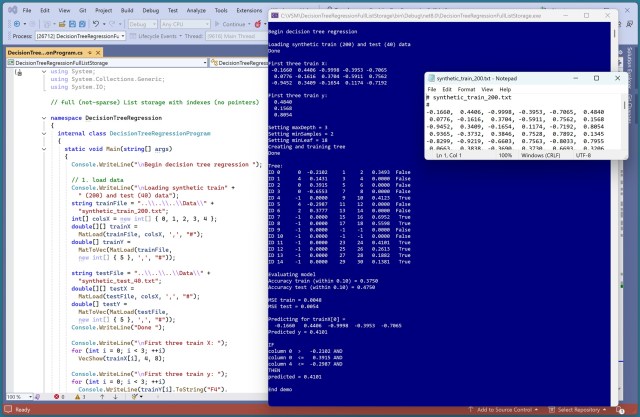
Регресія машинного навчання прогнозує числові значення за допомогою регресійних моделей дерева рішень. Для боротьби з перенавчанням використовуються ансамблеві методи, такі як випадковий ліс.
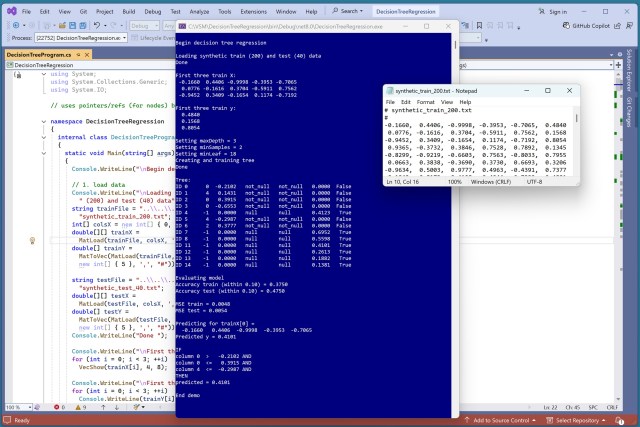
Регресія машинного навчання прогнозує значення; методи включають регресію дерева рішень. Вибір дизайну впливає на продуктивність і точність системи.
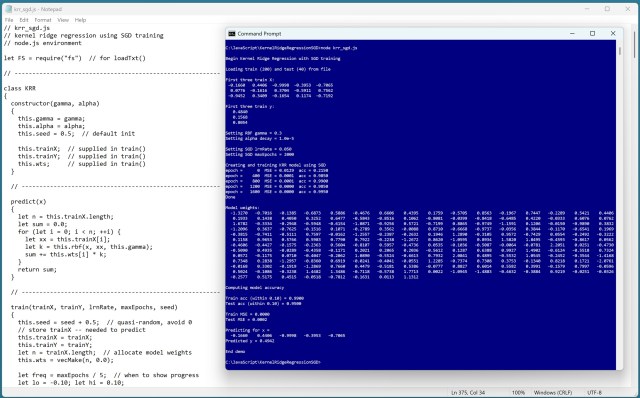
Регресія з використанням ядра та хребта (KRR) прогнозує значення за допомогою функції ядра та техніки хребта. RBF є поширеною функцією ядра в моделях KRR, для якої доступні різні техніки навчання.

Лекція Джона Сірла 1984 року поставила під сумнів концепцію мислення штучного інтелекту. Сьогодні дослідники продовжують вивчати значення та навчання в штучному інтелекті.
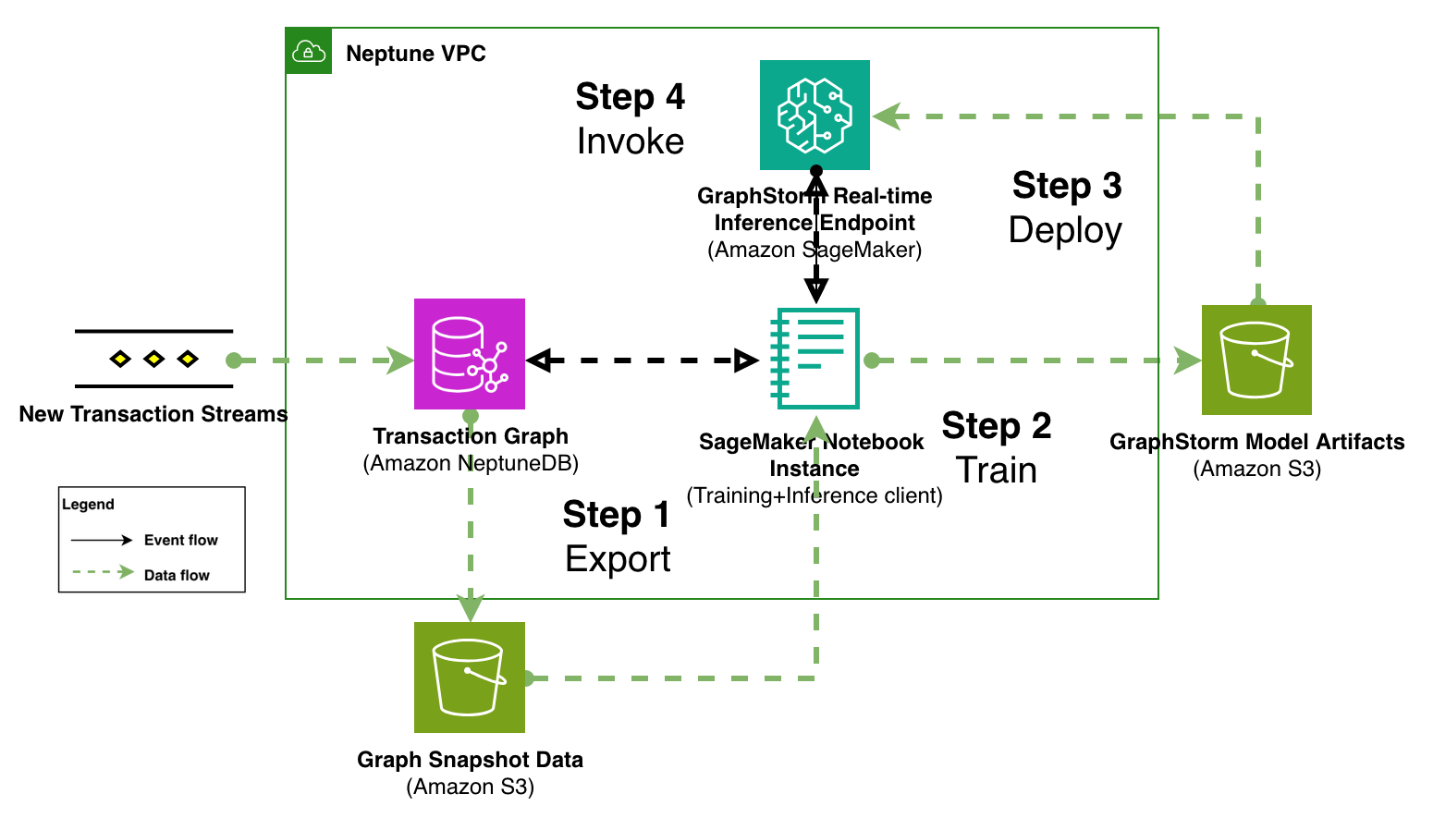
Шахраї стають все більш витонченими, що призводить до 25% зростання збитків споживачів у США. GraphStorm v0.5 пропонує запобігання шахрайству GNN у режимі реального часу з оптимізованим розгортанням та стандартизованим корисним навантаженням для ефективної інтеграції клієнтів.
Реалізація регресії ядра в JavaScript тепер включає коефіцієнт детермінації R2 для оцінки моделі, демонструючи вражаючі результати в точності та MSE. Демо-версія із синтетичними даними демонструє ефективність оновленої моделі KRR, досягаючи високої точності та значень R2.
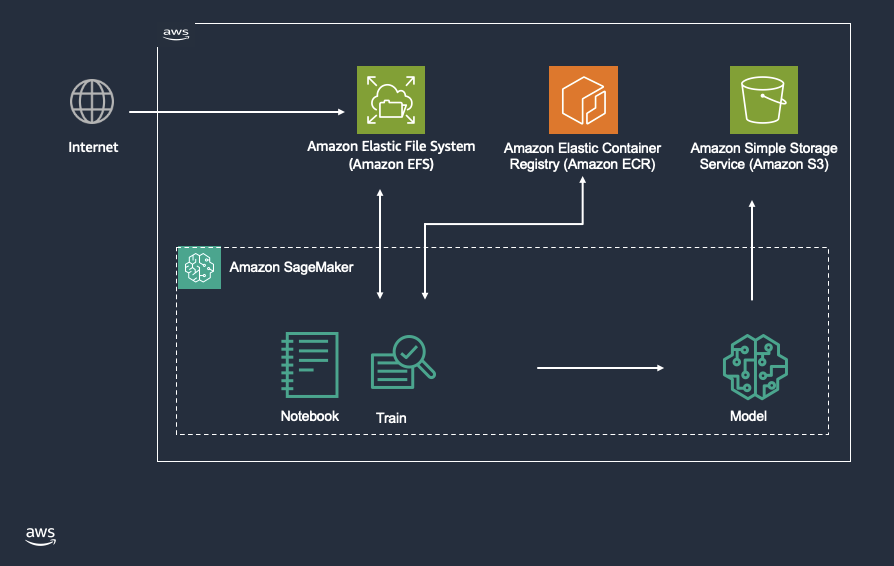
Використовуйте весь потенціал контейнерів AWS Deep Learning за допомогою MLflow на Amazon SageMaker
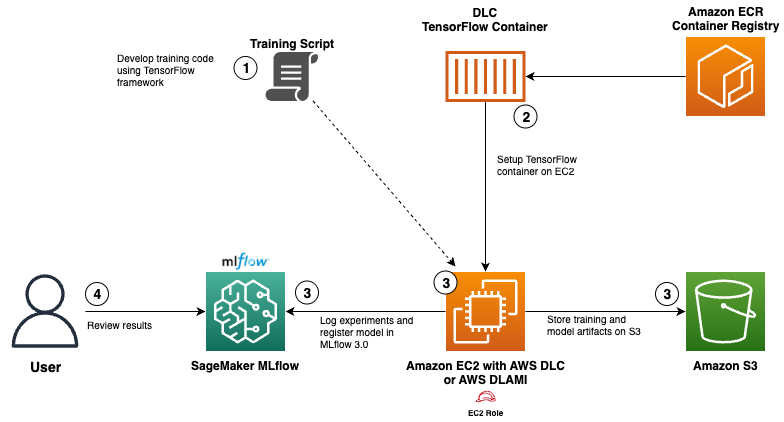
AWS Deep Learning Containers (DLC) та керований MLflow на Amazon SageMaker AI пропонують рішення для організацій із спеціалізованими вимогами до машинного навчання. DLC надають попередньо налаштовані контейнери Docker з оптимізованими фреймворками, а керований SageMaker MLflow оптимізує управління життєвим циклом завдяки розширеним можливостям.
Лінійна регресія з двосторонніми взаємодіями може обробляти складні дані, забезпечуючи кращу інтерпретованість, ніж передові методи. Демонстрація з використанням даних, згенерованих нейронною мережею в середовищі node.js, продемонструвала високу точність.
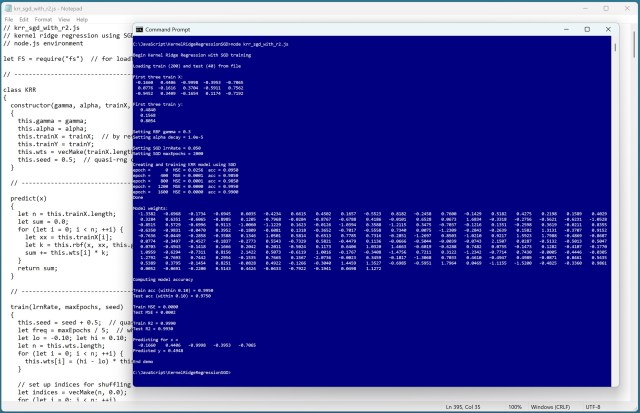
Регресія з використанням ядра (KRR) прогнозує значення за допомогою функцій ядра для нелінійних даних. Ітеративна техніка, що використовує стохастичний градієнтний спуск, дозволяє ефективно навчати моделі KRR для великих наборів даних.
Короткий зміст: Детальна презентація PowerPoint про нейронні мережі, що еволюціонували до включення деревних методів. Також розглядаються та оцінюються три сюжети науково-фантастичних фільмів, пов'язані з пам'яттю.

У статті висвітлюється метод регресії ядра (KRR) для прогнозування числових значень. KRR використовує функцію ядра для вимірювання схожості даних, з опціями навчання, що включають обернену матрицю ядра та стохастичний градієнтний спуск (SGD).
Комплексна презентація PowerPoint про нейронні мережі, розширена для включення деревних методів, під назвою «KitchenSink». Науково-фантастичні фільми на тему пам'яті творчо оцінені автором.
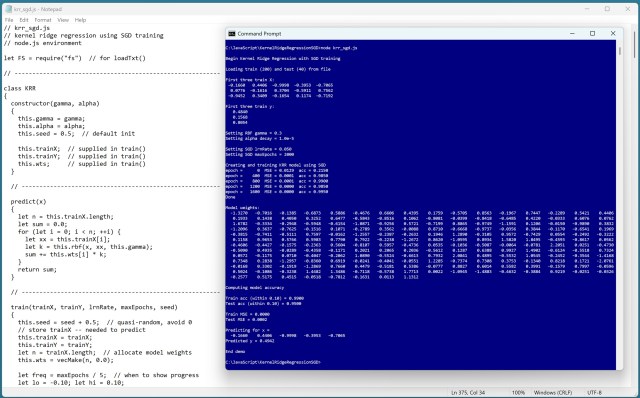
Регресія з використанням ядра (KRR) прогнозує значення за допомогою функції ядра, обробляючи складні дані. Досвід кодера з налаштування KRR в JavaScript демонструє потужність цієї техніки.
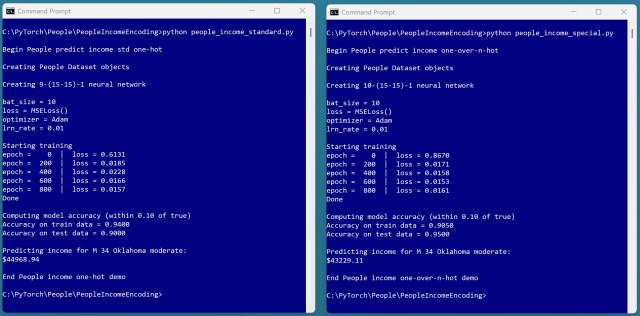
Використання кодування «one-over-n-hot» у нейронній мережі для категоріальних змінних показало багатообіцяючі результати з точністю 95%. Однак для остаточних висновків необхідні додаткові випробування.
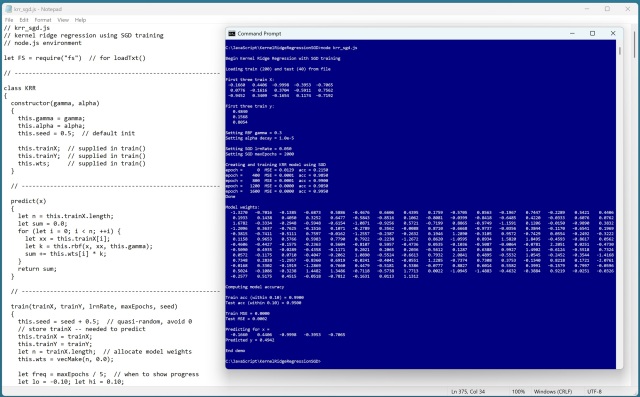
Регресія з використанням ядра (KRR) прогнозує значення за допомогою функцій ядра. Вона добре обробляє складні нелінійні дані, але вимагає ретельних методів навчання, таких як стохастичний градієнтний спуск.
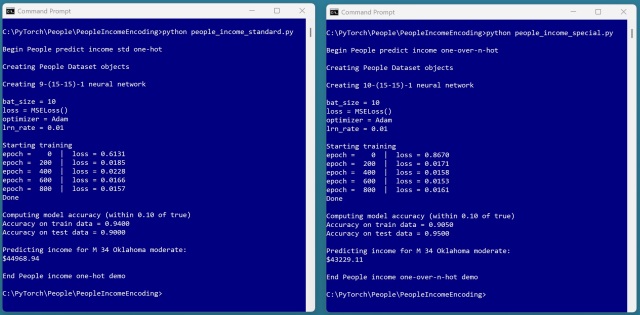
Використання кодування «one-over-n-hot» для категоріальних змінних у нейронній мережі дає багатообіцяючі результати, з кращою генералізацією (95% проти 90% точності), але висновки не є остаточними. Цей підхід додає інформацію до змінних-прогнозувальників, що потенційно підвищує точність прогнозування в завданнях аналізу даних.

Короткий зміст статті: У статті журналу Microsoft Visual Studio Magazine за серпень 2025 року йдеться про реалізацію регресії k-найближчих сусідів за допомогою JavaScript, простої, але дуже зрозумілої техніки, з демонстрацією її точності. Ця техніка передбачає пошук k-найближчих елементів до вхідного вектора для прогнозування числового значення, що робить її цінним інструментом у машинному нав...
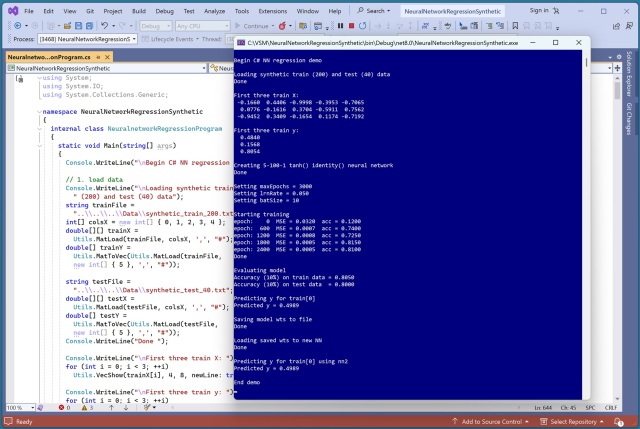
Рефакторований дизайн регресії нейронної мережі C# підвищує ефективність шляхом переміщення значення початкового значення в метод Train() для кращої ініціалізації. Демо-версія демонструє підвищену точність і можливості прогнозування моделі після рефакторингу.
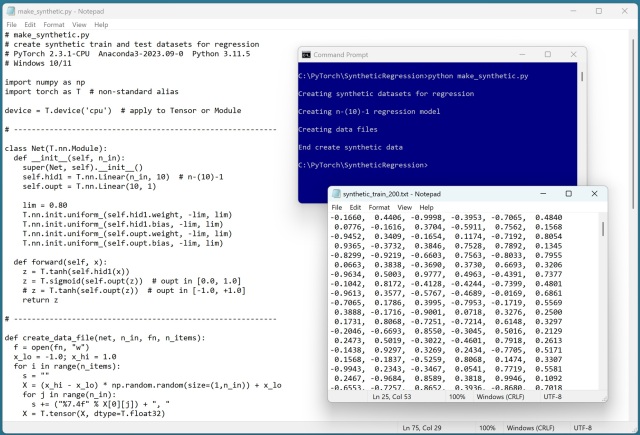
Нейронна мережа може генерувати синтетичні дані для регресії машинного навчання, що дозволяє прогнозувати структуровані дані. За допомогою PyTorch складні нейронні мережі можуть апроксимувати будь-яку неперервну функцію, спрощуючи процес створення навчальних і тестових даних.

Регуляризація L2 та згасання ваги є по суті еквівалентними в нейронних мережах, оскільки обидва обмежують вагу моделі, щоб запобігти перенавчанню. Наукові статті показують математику, що лежить в основі еквівалентності, на прикладах від класичних конструкцій ракетних кораблів до сучасних прототипів SpaceX.

Kernel ridge regression (KRR) predicts numeric values using a kernel function. It uses stochastic gradient descent (SGD) for training, preventing model overfitting.

Створення зображень за допомогою штучного інтелекту - це бурхливо розвиваюча індустрія, яка до кінця десятиліття досягне мільярда доларів. Дослідники з Массачусетського технологічного інституту та Facebook вивчають нові методи створення зображень за допомогою штучного інтелекту без традиційних генераторів і представлять свої висновки на конференції ICML 2025.
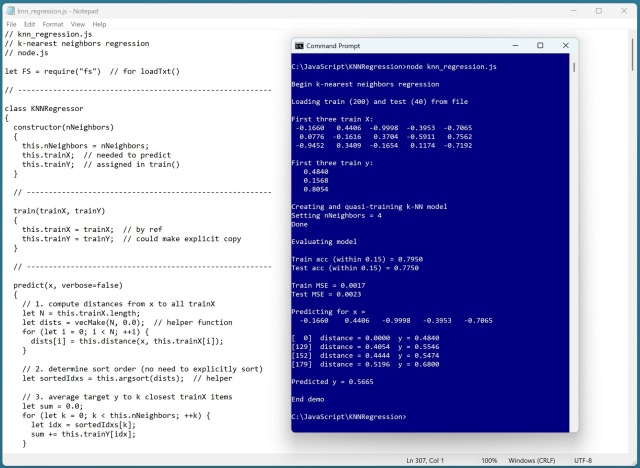
Регресія K-найближчих сусідів (k-NN) використовує навчальні дані як модель для прогнозування значень, демонструючи високу точність у демонстраційній програмі на JavaScript. Цей метод вирізняється своїм унікальним підходом, порівнюючи вхідні вектори безпосередньо з навчальними даними для прогнозування.

Новий інструмент штучного інтелекту CellLENS поєднує РНК, білки та просторові дані для групування ракових клітин на основі біологічних особливостей, що допомагає розробляти таргетовану терапію. Співпраця між Массачусетським технологічним інститутом, Гарвардом, Єльським, Стенфордським та Пенсильванським університетами призвела до прориву в розумінні поведінки імунних клітин при раку.

У статті журналу Microsoft Visual Studio Magazine за липень 2025 року розглядається лінійна регресія з використанням JavaScript, яка демонструє базову техніку прогнозування машинного навчання. Лінійна регресія забезпечує інтерпретованість моделі, незважаючи на дещо нижчу точність прогнозування порівняно з іншими методами регресії.

Дослідники з Массачусетського технологічного інституту та Університету Вісконсіна пропонують використовувати штучний інтелект для розробки більш ефективних підводних планерів, що імітують різноманітні морські форми. Цей інноваційний підхід може призвести до створення нових апаратів, які допоможуть океанографам відстежувати наслідки зміни клімату.

Дослідники з Массачусетського технологічного інституту виявили позиційне зміщення у великих мовних моделях, що впливає на пошук інформації. Їхні напрацювання можуть призвести до створення більш надійних систем штучного інтелекту, таких як чат-боти та медичні асистенти.
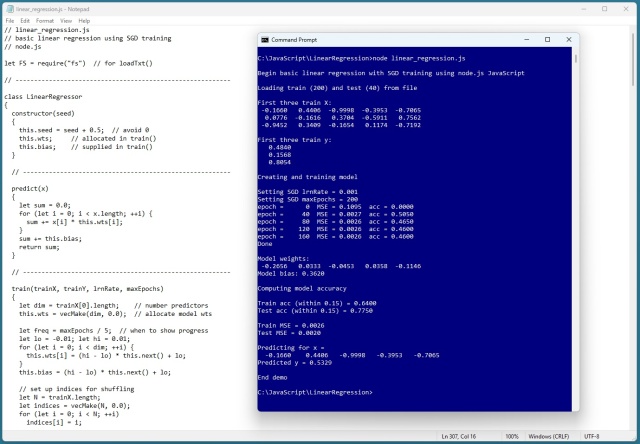
Демонстрація лінійної регресії на JavaScript використовує SGD для навчання. Прогнозує дохід від віку, зросту, освіти з точністю 64%.
Стаття демонструє лінійну регресію опорних векторів за допомогою C# з навчанням рою частинок для оцінки точності прогнозування моделі. Демонстрація розкриває проблеми прогнозування нелінійних даних, підкреслюючи важливість спеціалізованих алгоритмів оптимізації, таких як рій частинок.

Дослідники Массачусетського технологічного інституту розробили революційний апаратний прискорювач ШІ для обробки бездротових сигналів, який працює зі швидкістю світла, пропонуючи у 100 разів швидшу та енергоефективнішу альтернативу цифровим прискорювачам ШІ. Ця технологія може революціонізувати майбутні бездротові додатки 6G та уможливити ШІ-висновки в режимі реального часу для різних високопр...
Європейські телекомунікаційні компанії використовують NVIDIA для розробки 6G, інтегруючи ШІ для інновацій та сталого розвитку. Співпраця з урядом Великобританії та провідними університетами, цифровий двійник мережі реального часу у Фінляндії та партнерство з OAI у Франції підкреслюють передові досягнення в бездротових мережах на основі ШІ.
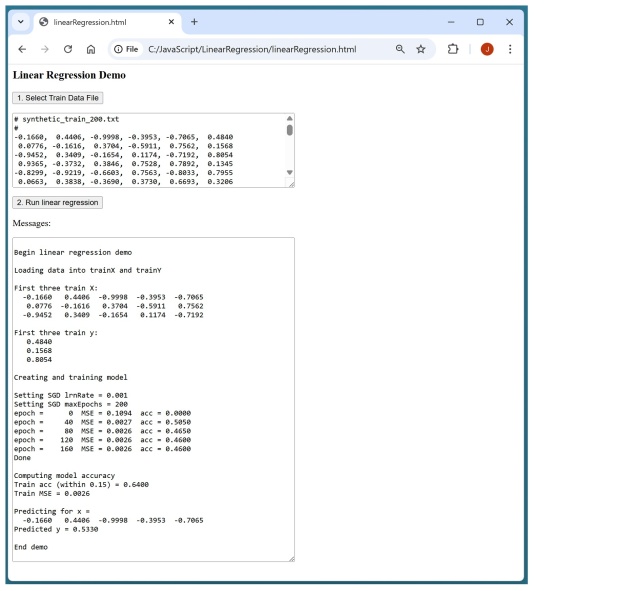
Система лінійного регресійного прогнозування демонструється з використанням JavaScript на стороні клієнта для простоти. Навчена модель досягла точності 64.00% завдяки нелінійній структурі даних. Нещодавно помер відомий художник Роберт МакГінніс, відомий своїми культовими обкладинками книг та кіноплакатами.
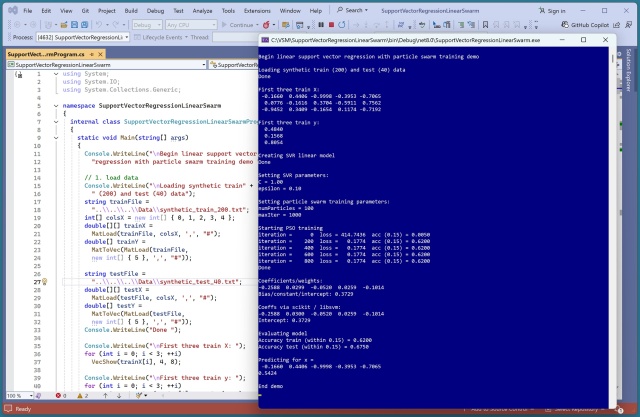
Навчання лінійної регресії опорних векторів (SVR) викликає труднощі через те, що функція втрат не піддається обчисленню. Використання оптимізації рою частинок (PSO) виявилося більш ефективним, ніж еволюційні алгоритми для навчання лінійних SVR-моделей.

Стаття на Pure AI спрощує процес трансформації великих мовних моделей ШІ, використовуючи заводську аналогію, що робить його доступним для неінженерів і бізнес-професіоналів. Аналогія розбиває процес на такі етапи, як завантаження док-станції, сортувальники матеріалів і остаточна збірка, пропонуючи чітке розуміння того, як працюють трансформери.

Навчання лінійного SVR є складним завданням через його недиференційовану функцію втрат, що призвело до вивчення PSO замість еволюційних алгоритмів. Використання PSO для навчання лінійного SVR дало чудові результати, демонструючи важливість налаштування параметрів для оптимізації прогнозуючих моделей.

Стиснення моделей має важливе значення в епоху великих мовних моделей. Дізнайтеся про обрізання, квантування, низькорангову факторизацію та методи дистиляції знань у машинному навчанні.

Резюме: Перша частина книги Саттона і Барто охоплює фундаментальні методи навчання з підкріпленням, тоді як друга частина зосереджена на використанні глибоких нейронних мереж для наближених рішень. У наступній серії буде проведено бенчмаркінг алгоритмів у середовищі Gridworld для визначення найбільш ефективних методів.

Резюме: Ця стаття прояснює хибні уявлення про зворотне поширення, пояснюючи повну похідну та вводячи правило векторного ланцюжка для спрощення складних обчислень у нейронних мережах. Впровадження векторних обчислень у рівняннях зворотного поширення оптимізує обчислення градієнтів для всіх ваг у шарі одночасно, підвищуючи ефективність навчання моделей.
Дослідники з Массачусетського технологічного інституту розробили LinOSS, стабільну модель ШІ, натхненну нейронними коливаннями, яка перевершує існуючі моделі в аналізі довгих послідовностей. LinOSS пропонує ефективні прогнози для різних сфер, від аналітики в галузі охорони здоров'я до фінансового прогнозування, поєднуючи біологічне натхнення з обчислювальними інноваціями.

DeepType використовує нейронні мережі для кластеризації, виділяючи значущу структуру з даних для більш глибокого аналізу та прогнозування. Навчаючись на релевантних для задачі представленнях, DeepType підвищує точність кластеризації та виявляє цінні ідеї, як, наприклад, при групуванні пацієнтів на основі генетичних даних для покращення кореляції показників виживання.
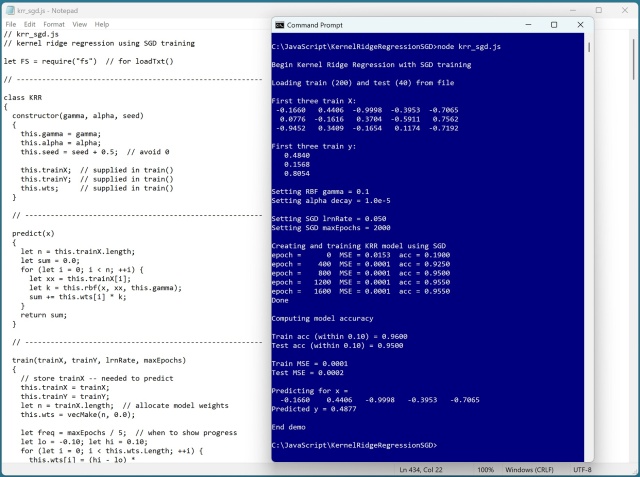
Ядерна регресія (Kernel ridge regression, KRR) використовує функцію ядра для прогнозування значень і запобігання надмірної підгонки. Реалізація KRR в JavaScript - це складна, але корисна головоломка, яка пропонує точні прогнози та різні методи навчання, такі як стохастичний градієнтний спуск.

Універсальна теорема про апроксимацію розкриває можливості нейронної мережі з одним прихованим шаром. Hugging Face демонструє понад мільйон попередньо навчених моделей, підкреслюючи потребу в різноманітних мережевих архітектурах.

Прогнозування зв'язків - популярна тема в соціальних мережах, електронній комерції та біології. Методи варіюються від простих евристик до просунутих моделей на основі GNN, таких як SEAL.

618-а авіаційна бригада Командування повітряної мобільності покращує планування місій за допомогою чат-інструментів на основі штучного інтелекту, розроблених Лінкольнською лабораторією. Обробка природної мови забезпечує швидкий аналіз тенденцій та інтелектуальний пошук для прийняття важливих рішень у ВПС США.
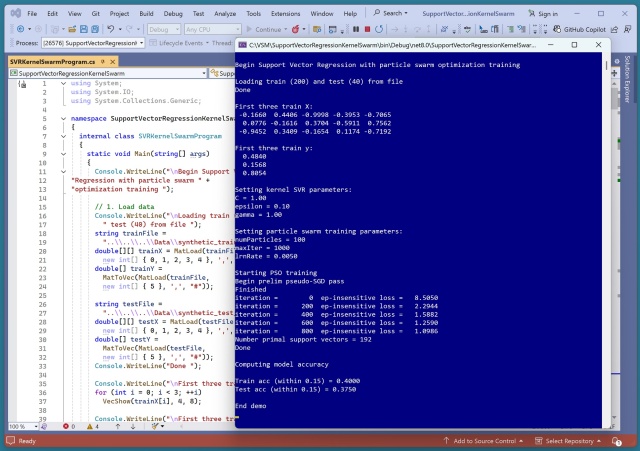
Ядерний SVR, навчений PSO, обробляє нелінійні дані за допомогою RBF. Епсилон-нечутливі втрати та PSO створюють складну, але багатообіцяючу систему.

Фізично-інформовані нейронні мережі (PINN) застосовують закони фізики до фінансових моделей, наприклад, рівняння Блека-Шоулза. Таке поєднання ШІ та фізики може покращити прогнози та фінансові стратегії.
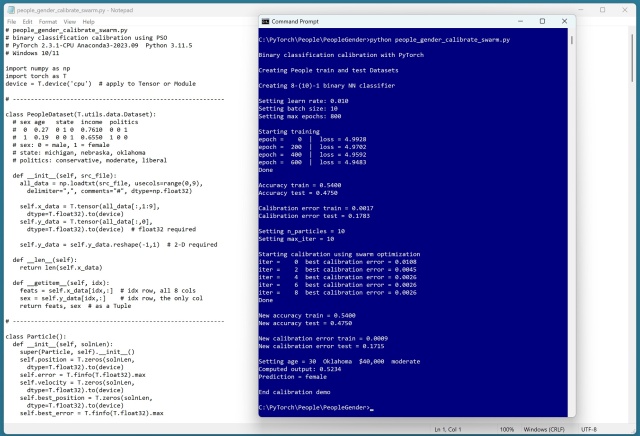
Похибка калібрування в моделях прогнозування має вирішальне значення. Демонстрація з використанням PyTorch та PSO показує, як її ефективно покращити.
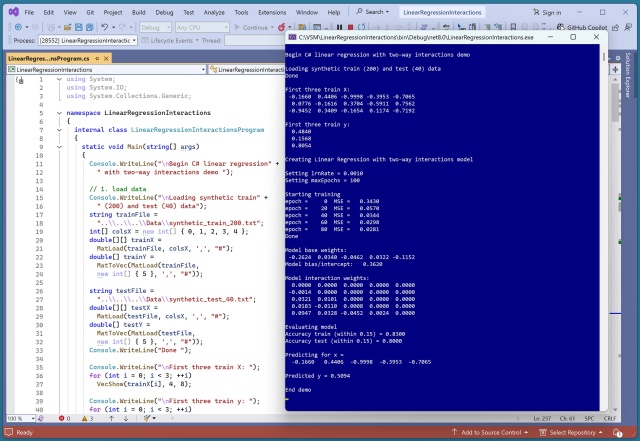
Застосування лінійної регресії з двосторонніми взаємодіями значно підвищило точність прогнозування. Модель досягла 83% точності на навчальних даних і 80% на тестових даних, що свідчить про її ефективність.

Моделі штучного інтелекту, такі як CNN, імітують людську візуальну обробку, але мають проблеми з причинно-наслідковими зв'язками. Незважаючи на те, що вони перевершують людину в деяких завданнях, їм не вдається узагальнювати класифікацію зображень, виділяючи обмеження.

Стаття в журналі Microsoft Visual Studio Magazine за квітень 2025 року демонструє лінійну векторну регресію з використанням C# з еволюційним навчанням. Лінійна SVR карає викиди і зберігає значення моделі малими, але простіші методи, такі як L1 і L2 регресія, є більш популярними.

Трансформаторні LLM просунулися у виконанні завдань, але залишаються чорними скриньками. Нова стаття Anthropic про трасування ланцюгів має на меті розкрити внутрішню логіку LLM для інтерпретації.

Навчання еволюційної оптимізації для Kernel Ridge Regression є перспективним, але обмежується точністю 90-93% через проблеми з масштабуванням. Традиційна матрична інверсна техніка перевершує за точністю та швидкістю.
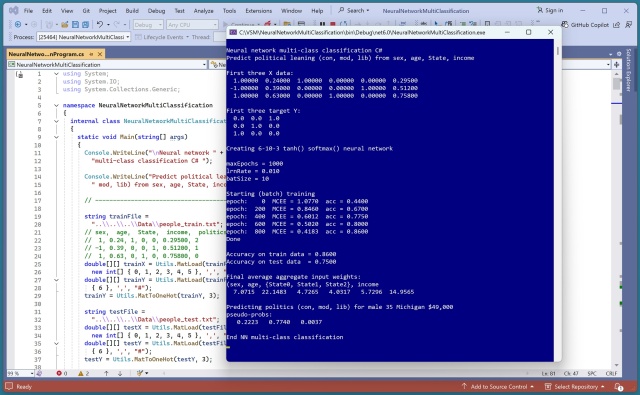
Інтерпретація моделі машинного навчання може бути складним завданням. Експеримент показав, що вік і дохід мають найбільший вплив на прогнозування політичних уподобань.

Модель дифузії, вперше запропонована Солом-Дікштейном та ін. і розвинута Хо та ін., була адаптована OpenAI та Google для створення DALLE-2 та Imagen, здатних генерувати високоякісні зображення. Модель працює шляхом перетворення шуму в зображення за допомогою процесів прямої та зворотної дифузії, зберігаючи розмірність оригінального зображення в латентному просторі.
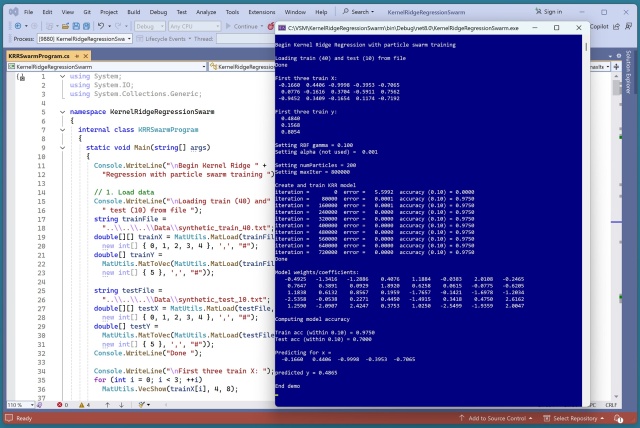
Алгоритм, що поєднує PSO з EO, EPSO, працює аналогічно PSO та EO, не значно краще. Повільний для практичного використання, але перспективний для навчання системи прогнозування КРР.

Згорткові мережі графів (GCN) та мережі уваги до графів (GAT) мають обмеження для великих графів та мінливих структур. GraphSAGE пропонує рішення шляхом вибірки сусідів та використання функцій агрегування для швидшого та масштабованого навчання.

Емі розмірковує про свій шлях від безробіття до пошуку нових ідентичностей. Перейшовши від науки про дані до інженерії машинного навчання, вона ділиться цінними уроками та ідеями щодо адаптації до мінливих вимог ринку праці.

Механізм уваги, що має вирішальне значення для машинного перекладу, допомагає ШНМ долати труднощі, що призвело до появи трансформерів. Самоувага в трансформерах включає вектори ключів, значень і запитів, щоб зосередитися на важливих елементах послідовності.
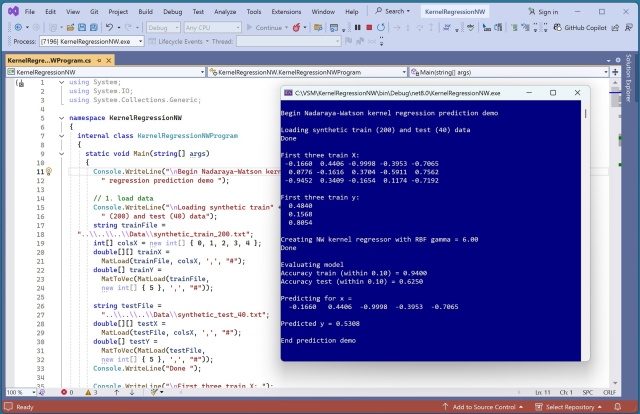
У блозі обговорюється ядерна регресія Надарайї-Вотсона з використанням ядра радіальної базисної функції, підкреслюється важливість нормалізації значень предикторів. Ключове рівняння ядерної регресії NW включає в себе середньозважене значення цільових значень y на основі значень ядерної функції RBF.

Стаття: «Нейромережева квантильна регресія з використанням C#». Унікальним підходом до регресії машинного навчання є квантильна регресія, особливо корисна для сценаріїв зі значними наслідками недопрогнозування. Використовуючи спеціальну функцію втрат, нейромережева квантильна регресія має на меті передбачити значення до заданого квантиля, пропонуючи перспективний метод точного прогнозування.

PawMatchAI на основі штучного інтелекту може ідентифікувати 124 породи собак, аналізуючи структуровані ознаки, такі як пропорції тіла та текстура шерсті, на основі людських методів експертного розпізнавання. На відміну від традиційних CNN, ця модель відокремлює ключові характеристики для більш чіткої інтерпретації, революціонізуючи ідентифікацію порід на основі АІ.
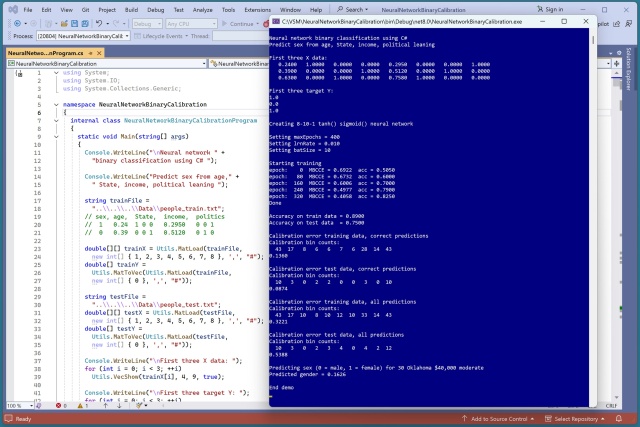
Функція похибки калібрування псевдовипадкових ймовірностей нейромережевого бінарного класифікатора для прогнозування статі дає багатообіцяючі результати. Точність на тестових даних становить 0,75, з похибкою калібрування менше 0,20, що свідчить про хорошу відповідність моделі.
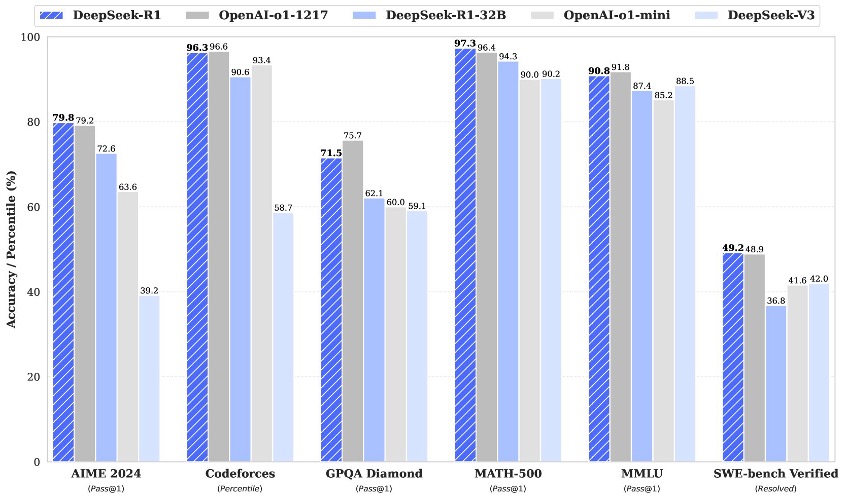
DeepSeek-R1 від DeepSeek AI інтегрує навчання з підкріпленням для покращення результатів. Варіанти моделі, такі як DeepSeek-V3, використовують архітектуру MoE для ефективного масштабування.

Оглядові статті необхідні для того, щоб залишатися в курсі подій у галузі фізично-інформованих нейронних мереж (PINN), яка швидко розвивається. Обов'язкова до прочитання стаття «Наукове машинне навчання за допомогою фізично-інформованих нейронних мереж» охоплює ключові теми, набори інструментів та майбутні напрямки, пропонуючи всебічний аналіз основ PINN та їх практичних застосувань.
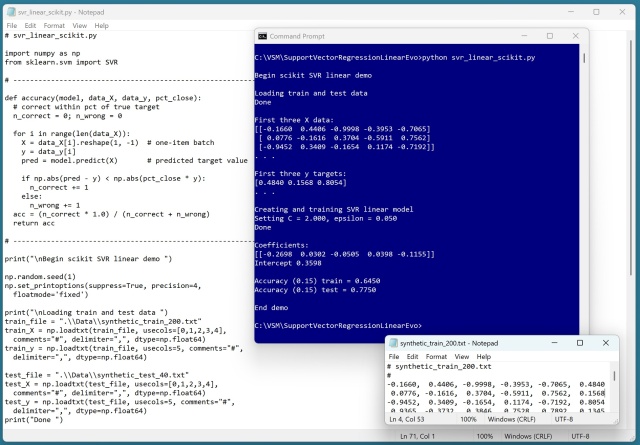
Регресія опорних векторів (SVR) з лінійним ядром карає викиди більше, ніж близькі точки даних, що контролюються параметрами C та епсилон. SVR, хоч і складна, але дає результати, подібні до звичайної лінійної регресії, що робить її менш практичною для лінійних даних.

GPT-3 викликав інтерес до великих мовних моделей (LLM), таких як ChatGPT. Дізнайтеся, як LLM обробляють текст за допомогою токенізації та нейронних мереж.

ШІ важко розрізняти схожі породи собак через переплутані ознаки. PawMatchAI використовує унікальний екстрактор морфологічних ознак, щоб імітувати те, як люди-експерти розпізнають породи, зосереджуючись на структурованих ознаках.
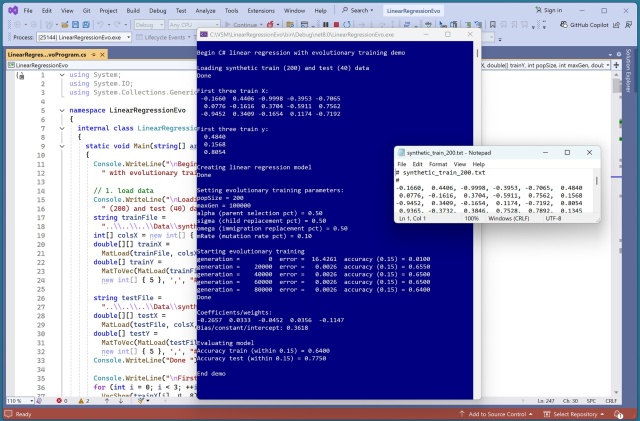
Демонструє еволюційне навчання лінійної регресії за допомогою C#. Використовує нейронну мережу для генерації синтетичних даних. Еволюційний алгоритм перевершує традиційні методи навчання за точністю.

Удосконалена нейромережева архітектура CPTR поєднує кодер ViT з декодером Transformer для створення підписів до зображень, покращуючи попередні моделі. Модель CPTR використовує ViT для кодування зображень і Transformer для декодування підписів, що підвищує продуктивність підписів до зображень.

Дослідники Массачусетського технологічного інституту та NVIDIA розробили новий фреймворк, який дозволяє користувачам коригувати поведінку роботів у режимі реального часу без перенавчання. Цей інтуїтивно зрозумілий метод перевершує альтернативні на 21%, потенційно дозволяючи неспеціалістам керувати роботами, навченими на заводі, у виконанні домашніх завдань.
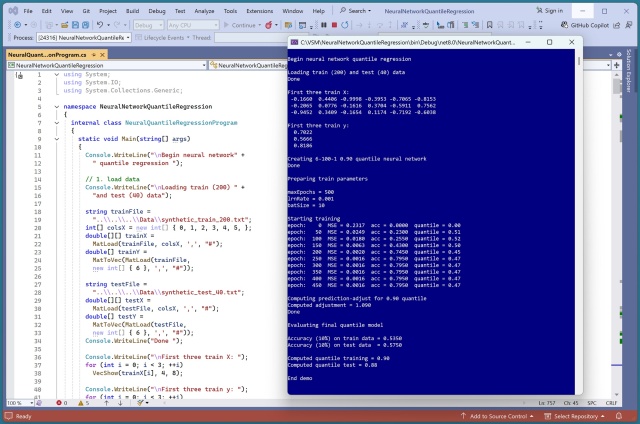
Реалізація нейромережевої квантильної регресії в PyTorch була складним завданням. Вивчення C# для цієї ж задачі виявилося ще складнішим через проблеми з калібруванням.

Трансформери революціонізують НЛП завдяки ефективним механізмам самоуваги. Інтеграція трансформаторів у комп'ютерний зір стикається з проблемами масштабування, але багатообіцяючі прориви вже на горизонті.
Автор експериментував з нейронними мережами PyTorch та C#, щоб створити успішну систему квантильної регресії, пояснюючи концепцію та виклики. Нейромережева квантильна регресія пропонує потужну альтернативу класичним методам, дозволяючи точно калібрувати прогнози.

Короткий зміст: Дізнайтеся, як будуються та навчаються великі мовні моделі (ВММ), демістифікуючи цей процес. Вивчіть попереднє навчання, токенізацію та навчання нейронних мереж у GPT4.

Інженер з машинного навчання розповідає про свій шлях від студента-фізика до фахівця з аналізу даних, який отримав першу роль після подачі заявок на 300+ вакансій. Зацікавився штучним інтелектом після перегляду документального фільму AlphaGo від DeepMind, який підкреслює важливість наполегливої праці та завзятості.
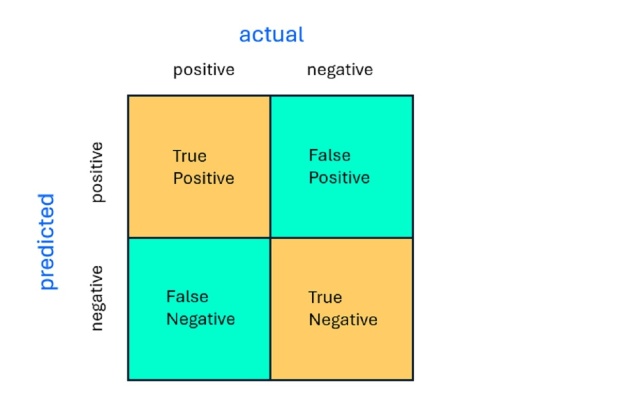
Проблеми бінарної класифікації можуть бути складними для інтерпретації через неоднозначність матриці плутанини, де визначення TP, TN, FP і FN можуть відрізнятися. Розуміння цих термінів має вирішальне значення для точного аналізу. Будьте обережні при інтерпретації матриць розбіжностей, щоб уникнути плутанини в результатах машинного навчання.

Такі досягнення в науці про дані, як Transformer, ChatGPT та RAG, змінюють технології. Розуміння еволюції НЛП є ключовим для науковців-початківців.

DeepSeek R1 LLM перевершує конкурентів, таких як OpenAI o1, за меншу ціну. Дистиляція моделей, ключова для успіху R1, може сигналізувати про зсув до комерціалізації LLM.
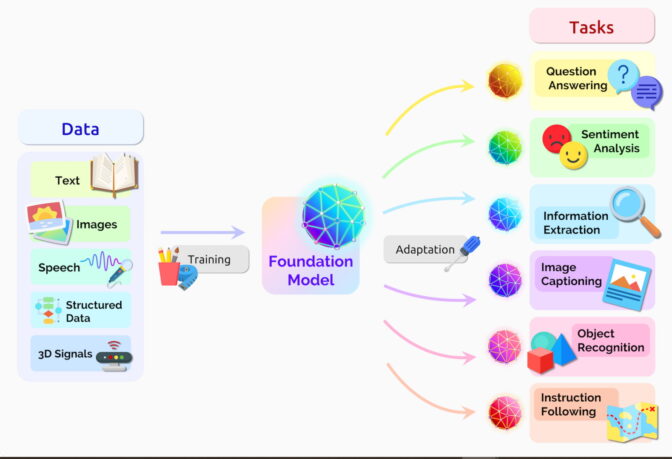
Дослідники швидко розробляють базові моделі ШІ: у 2023 році їх було опубліковано 149, що вдвічі більше, ніж у попередньому році. Ці нейронні мережі, подібно до трансформаторів і великих мовних моделей, пропонують величезний потенціал для виконання різноманітних завдань і мають велику економічну цінність.
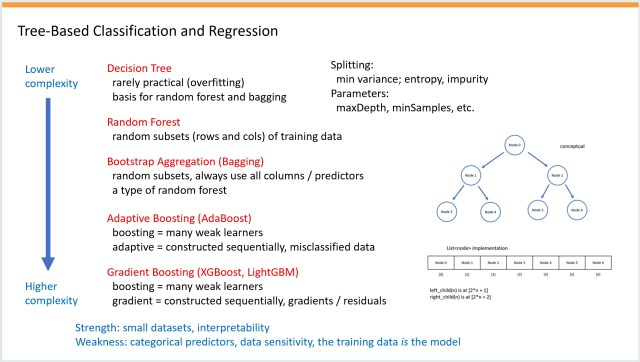
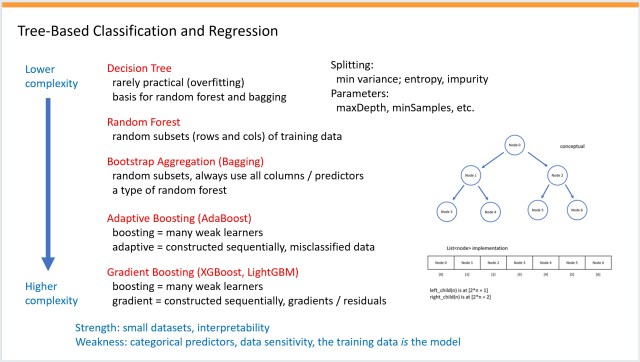
Основні методи регресії: лінійний, k-найближчих сусідів, ядрового хребта, гауссового хребта, нейронної мережі, випадкового лісу, AdaBoost та градієнтного бустингу. Ефективність кожного методу залежить від розміру та складності набору даних.
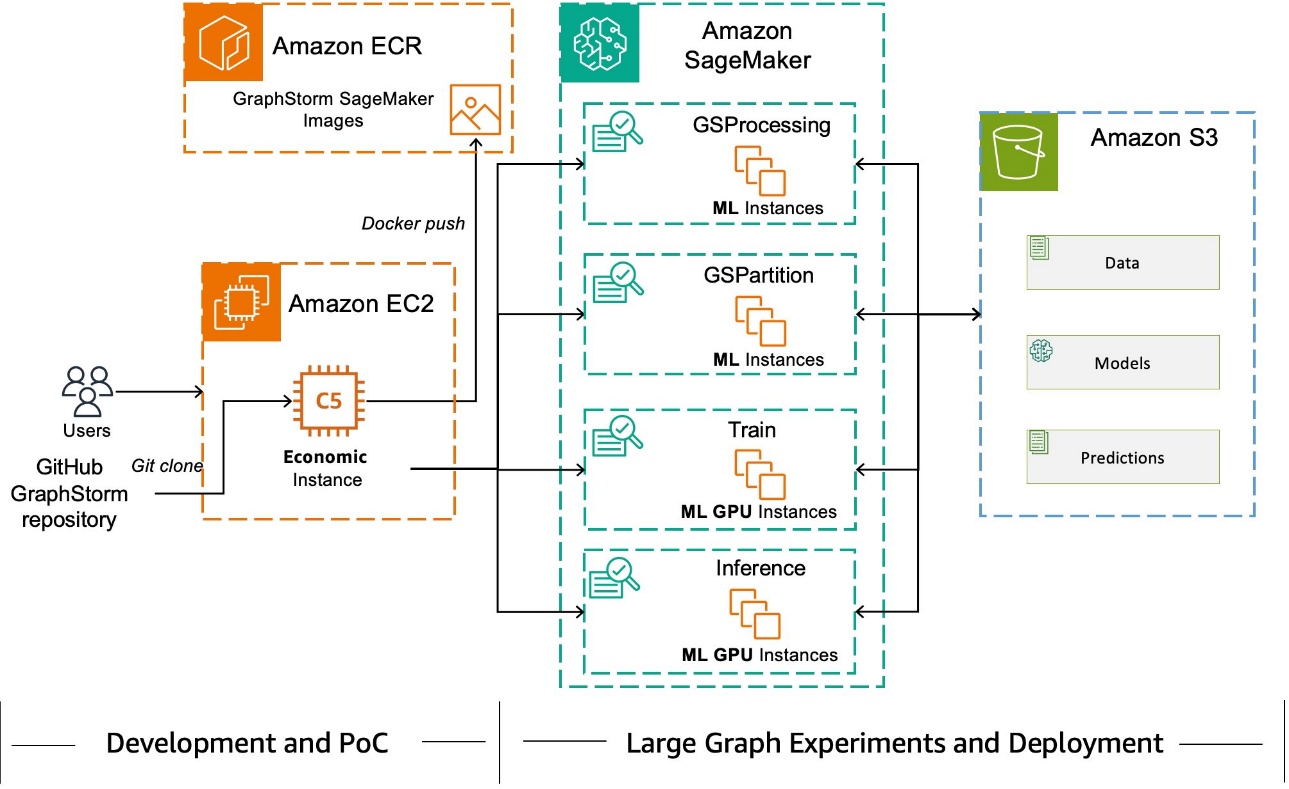
GraphStorm v0.4 від AWS AI впроваджує інтеграцію з DGL-GraphBolt для швидшого навчання ШНМ та висновків на великомасштабних графах. Структура графів fCSC GraphBolt зменшує витрати пам'яті на 56%, підвищуючи продуктивність у розподілених середовищах.

Каймінг Хе з Массачусетського технологічного інституту бачить, як ШІ руйнує стіни між науковими дисциплінами, створюючи спільну мову для прогресу та співпраці. Від AlphaFold до ChatGPT, інструменти ШІ сприяють прогресу в різних галузях, таких як прогнозування структури білків та обробка природної мови.

LLM-додатки вимагають навмисного налаштування температури для контролю випадковості. Значення температури впливають на результати моделі, роблячи їх більш випадковими або цілеспрямованими. Функція Softmax перетворює необроблені результати в чистий розподіл ймовірностей для точних прогнозів.

Дослідження нейронних мереж, натхненних людським мозком, включаючи навчання зворотного поширення. Розуміння суті штучного інтелекту.
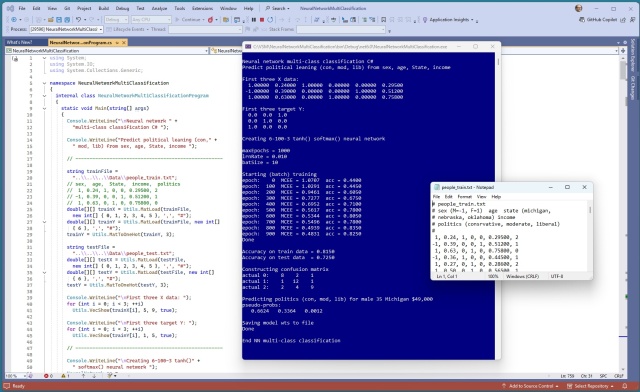
Доповідач представить доповідь «Вступ до нейронних мереж з використанням C#» на конференції 2025 Visual Studio Live у Лас-Вегасі. Демонстрація включає багатокласову систему класифікації, що прогнозує політичні уподобання на основі синтетичного набору даних.

Дослідники з Массачусетського технологічного інституту розробили автоматизовану систему для зменшення енергоспоживання в моделях штучного інтелекту за рахунок використання надлишковості даних. Система підвищила швидкість обчислень майже в 30 разів і може оптимізувати алгоритми для різних застосувань.
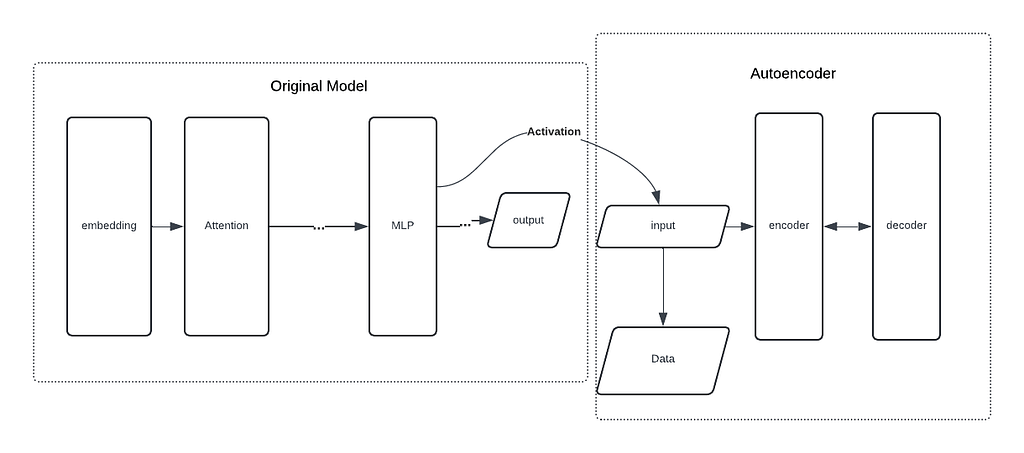
Розбирайте складні нейронні мережі за допомогою Sparse Autoencoder, щоб виявити особливості, які можна інтерпретувати, долаючи проблеми суперпозиції у великих мовних моделях. Sparse Autoencoder вносить розрідженість у приховані шари, щоб розкласти нейронні мережі на більш зрозумілі для людини представлення.

Генерація, доповнена пошуком (RAG), покращує генеративний ШІ з конкретними джерелами даних, підвищуючи точність і достовірність. RAG допомагає моделям надавати достовірні відповіді, прояснювати неоднозначність і запобігати неправильним відповідям, революціонізуючи довіру користувачів.
Цифрова патологія трансформує діагностику раку за допомогою обчислювальної патології на основі ШІ. Французький стартап Bioptimus випустив H-optimus-0, найбільший у світі FM для патології, встановивши новий стандарт у медичній діагностиці.
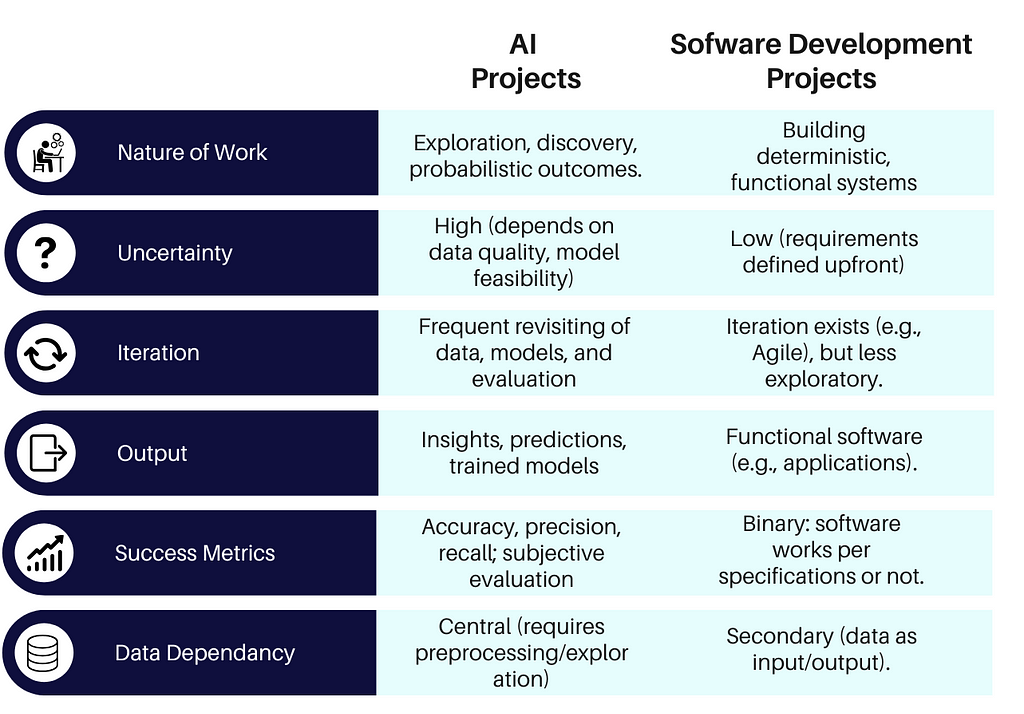
Проекти зі створення штучного інтелекту відрізняються від традиційної розробки програмного забезпечення своїм ітеративним підходом, в якому акцент робиться на відкритті та адаптації. Життєвий цикл розробки ШІ включає визначення проблеми, підготовку даних, розробку моделі, оцінку, розгортання та моніторинг.
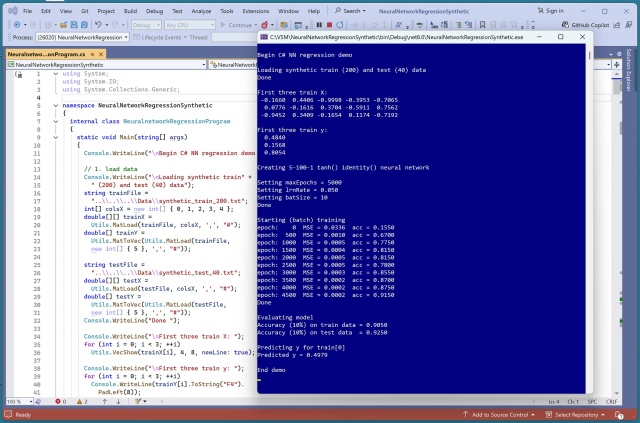
Реалізації машинного навчання на C# мають на меті імітувати дизайн API scikit-learn для забезпечення узгодженості. Виникають суперечки щодо передачі всіх параметрів конструкторам чи лише навчальних даних методам.

Машинне навчання стимулює мобільну рекламу та ігрову індустрію завдяки нейронним мережам для прогнозування кліків. Провідні гравці, такі як Applovin, інвестують мільярди в залучення користувачів, переходячи на глибоке навчання для підвищення ефективності.
Нобелівська робота Джеффрі Хінтона про обмежені машини Больцмана (Restricted Boltzmann Machines, RBM) пояснюється та реалізується в PyTorch. Обмежені Больцманівські машини - це некеровані моделі навчання для вилучення значущих ознак без вихідних міток, використовуючи енергетичні функції та розподіли ймовірностей.
Прогнозування ланцюгів поставок має вирішальне значення для бізнесу, який стикається з нестабільними ринками. SageMaker Canvas від Amazon Web Services пропонує безкодові ML-рішення для точного прогнозування в роздрібній торгівлі та виробництві споживчих товарів.
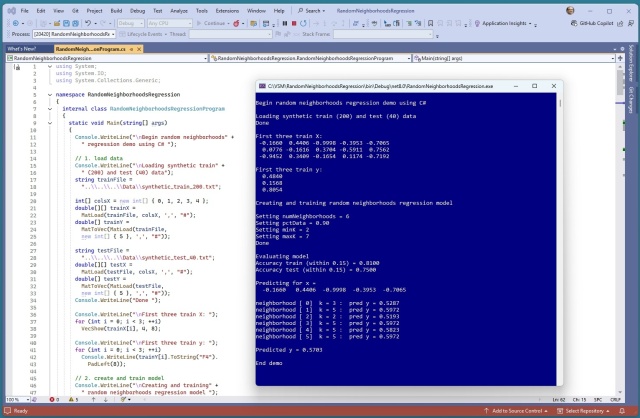
Ідея алгоритму регресії випадкових сусідів створює ансамбль регресорів k-найближчих сусідів для вирішення проблем перенастроювання та спроб і помилок у базовій регресії k-найближчих сусідів. Успішна демонстрація з використанням C# продемонструвала підвищення точності прогнозування за допомогою віртуальних колекцій регресорів.
Дизайн матеріалів пройшов шлях від алхімії до машинного навчання. Дослідження під керівництвом Джу Лі представляє новий метод, що використовує теорію зв'язаних кластерів для підвищення точності та швидкості проектування матеріалів.
Дослідники Массачусетського технологічного інституту з Інституту досліджень мозку Макговерна виявили життєво важливу роль точного визначення часу в слухових нейронах для розпізнавання голосів і визначення місцезнаходження звуків. Використовуючи машинне навчання, моделі команди надають інформацію для вивчення порушень слуху та розробки інтервенцій.

Лінійна регресія з двосторонніми взаємодіями може значно підвищити точність прогнозування. Модель була успішно реалізована за допомогою C# і досягла високого рівня точності.
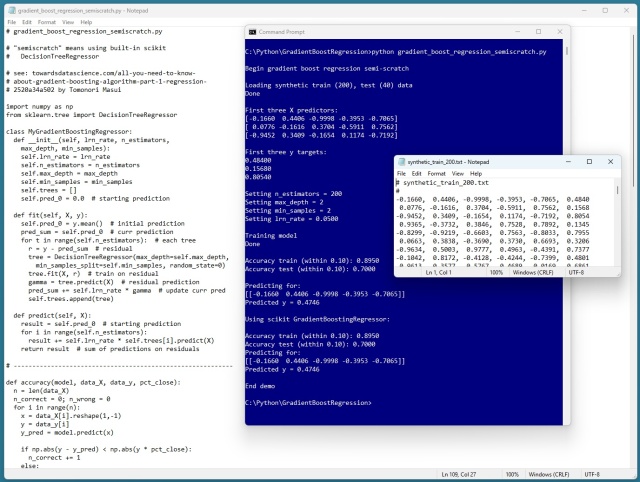
Регресія з градієнтним підсиленням (GBR) використовує дерева рішень для прогнозування значень. Демонстрація на Python демонструє точність GBR у прогнозуванні синтетичних даних, порівнюючи результати з бібліотекою scikit. XGBoost та LightGBM - популярні бібліотеки GBR для ентузіастів машинного навчання.

Deep Instinct пропонує DSX, передове рішення для кібербезпеки, що використовує глибоке навчання та генеративний ШІ для захисту від шкідливого програмного забезпечення та програм-вимагачів у режимі реального часу. Їхній інструмент DIANNA, що працює на базі Amazon Bedrock, розширює можливості SOC-команд, забезпечуючи швидкий аналіз відомих і невідомих загроз, вирішуючи ключові проблеми в мінливо...
Глибоке навчання відмінно справляється з виявленням викидів для зображень, відео та аудіо даних, але має проблеми з табличними даними. Традиційні методи все ще переважають у виявленні відхилень у табличних даних, проте глибоке навчання дає надію на подальший прогрес.
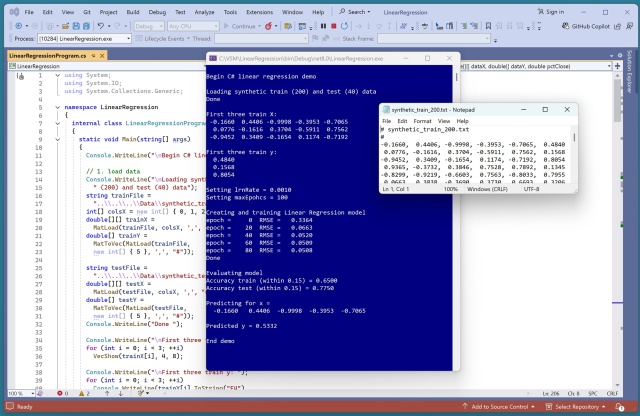
Співробітник технологічної компанії створює демонстрацію лінійної регресії, використовуючи дані, згенеровані нейронною мережею, щоб отримати уявлення про узгодженість дизайну API.
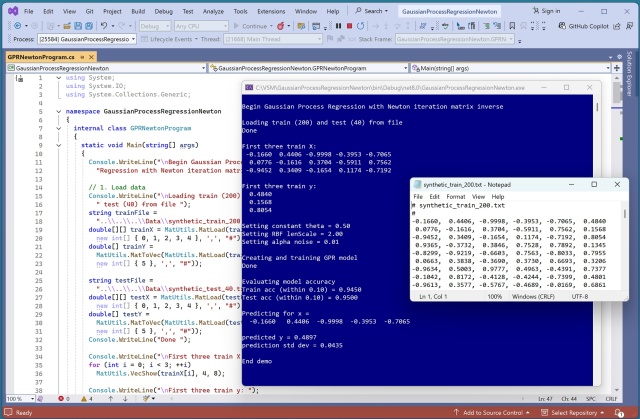
Обернена матриця ітерацій Ньютона була успішно використана в регресії гауссівського процесу для підвищення ефективності, точності та робастності. Демонстрація продемонструвала високий рівень точності прогнозування цільових значень для синтетичних даних зі складною базовою структурою.
Нейронні мережі стикаються з проблемами суперпозиції, коли один нейрон представляє декілька ознак. Нелінійність та розрідженість ознак відіграють ключову роль у виникненні суперпозиції.
Лінійна регресія може обробляти нелінійні дані, використовуючи скінченні нормальні суміші. Цей підхід забезпечує гнучкість та інтерпретованість, що робить його потужним інструментом машинного навчання. Моделювання моделі суміші для регресії з вибіркою MCMC показує, як відновлювати компоненти за допомогою байєсівського висновку.
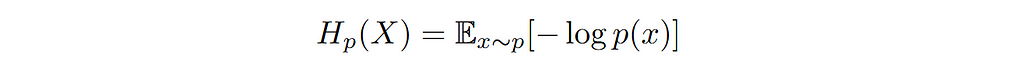
Розуміння функцій втрат має вирішальне значення для навчання нейронних мереж. Перехресна ентропія допомагає кількісно оцінити відмінності в розподілі ймовірностей, що допомагає у виборі моделі.

AdaBoost.R2 модифікує AdaBoost для регресії, створюючи послідовність дерев рішень для кращих прогнозів. Зважена медіана підвищує точність, підкреслюючи прогнози дерев з високим ступенем достовірності.

Corvus Robotics використовує автономні дрони для ефективного управління складськими запасами, підвищуючи швидкість і точність роботи. Співзасновник компанії Мохаммед Кабір розробив безпілотну платформу для навігації по складах без GPS, що зробило революцію у відстеженні запасів.
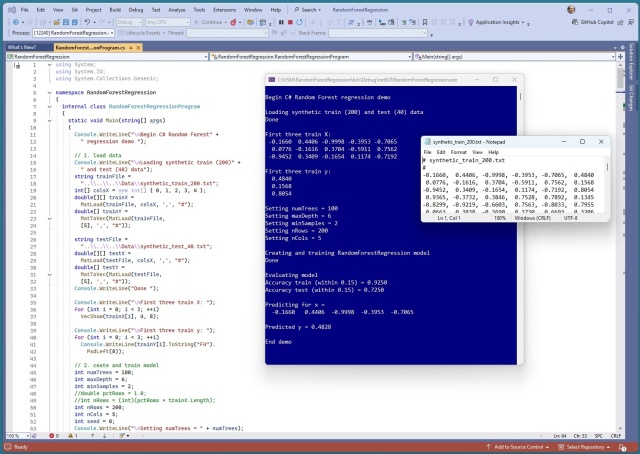
Машинне навчання регресії випадкового лісу прогнозує значення за допомогою дерев рішень. Демонстраційний приклад на C# показує точність прогнозування синтетичних даних на рівні 0,9250 для навчання та 0,7250 для тесту.
DDPG покращує медичну робототехніку, керовану штучним інтелектом, вирішуючи проблему безперервного управління діями. Фреймворк Actor-Critic в DDPG поєднує в собі DPG і DQN для підвищення стабільності та продуктивності в середовищах з безперервними діями.

Нова модель OpenAI o1 перевершує ChatGPT-40. Експеримент з генерацією коду на Python за допомогою ChatGPT-o1 дає 90% точності.

Даніела Рус з Массачусетського технологічного інституту отримала премію Джона Скотта 2024 року за новаторські дослідження в галузі робототехніки, які переосмислюють можливості роботів за межами традиційних норм. Робота Рус зосереджена на розробці зрозумілих алгоритмів для створення колаборативних роботів, здатних вирішувати реальні проблеми, підкреслюючи синергію між тілом і мозком для інтелек...
Профілювання клієнтів розвивається завдяки векторним рекомендаціям на основі зразків, як-от Pinterest's Pinnersage, що пропонують користувачеві індивідуальний вибір. Ці алгоритми спрощують рекомендації, перетворюючи зразки на вектори, покращуючи залучення користувачів.
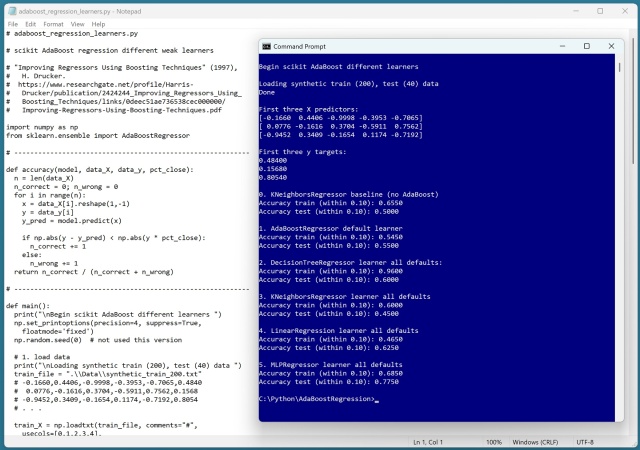
Регресія AdaBoost поєднує в собі слабкі методи навчання, такі як дерево рішень, k-NN та лінійна регресія. Результати показують, що нейронна мережа є найкращою за точністю прогнозування.
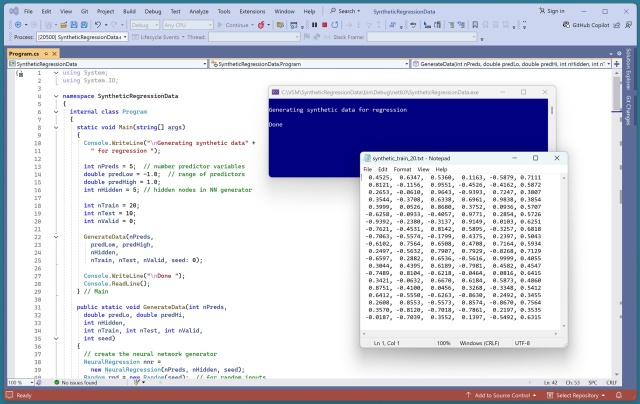
Генеруйте синтетичні дані для регресії машинного навчання за допомогою нейронної мережі із заданими параметрами. Спростіть генерацію складних даних за допомогою настроюваної функції на C#.

Вчені Массачусетського технологічного інституту розробляють фотонний чіп для глибоких нейромережевих обчислень, досягаючи високої швидкості та точності. Чіп може революціонізувати глибоке навчання для таких застосувань, як лідар та високошвидкісні телекомунікації.

Розробники re:Invent 2024 стикаються з унікальними викликами фізичних перегонів AWS DeepRacer. Перехід від віртуальних до фізичних перегонів становить значний виклик через різницю у середовищі та можливостях автомобілів.

Мультимодальні вбудовування об'єднують текстові та графічні дані в єдину модель, уможливлюючи крос-модальні додатки, такі як підписи до зображень і модерація контенту. CLIP вирівнює представлення тексту і зображень для класифікації зображень з нульового кадру, демонструючи переваги спільного простору для вбудовування.

Нейроморфні обчислення переосмислюють апаратне забезпечення та алгоритми ШІ, натхненні мозком, щоб зменшити споживання енергії та вивести ШІ на новий рівень. Угода OpenAI з Rain AI на суму 51 мільйон доларів за нейроморфні чіпи свідчить про перехід до більш екологічного ШІ в центрах обробки даних.
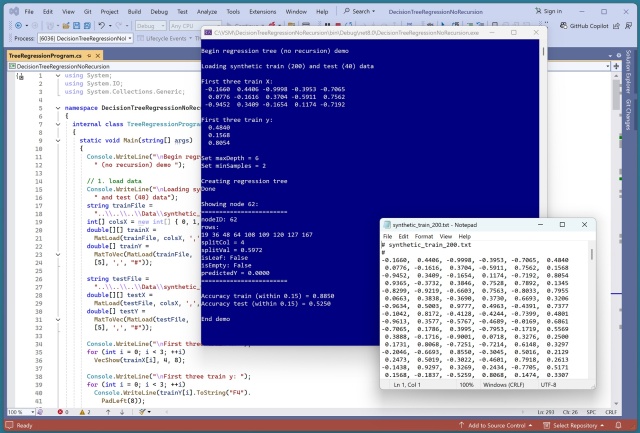
Інженер-програміст Джеймс МакКафрі розробив систему регресії дерева рішень на C# без рекурсії та вказівників. Він видалив індекси рядків з вузлів для економії пам'яті, що полегшило налагодження і зробило прогнози більш зрозумілими.

Короткий зміст: Компроміс між зміщенням та дисперсією впливає на прогнозні моделі, балансуючи між складністю та точністю. На реальних прикладах показано, як недостатнє та надмірне пристосування впливає на продуктивність моделі.

Марзіє Гассемі поєднує свою любов до відеоігор та здоров'я у роботі в Массачусетському технологічному інституті, зосереджуючись на використанні машинного навчання для покращення справедливості у сфері охорони здоров'я. Дослідницька група Гассемі в LIDS вивчає, як упередженість даних про стан здоров'я може вплинути на моделі машинного навчання, підкреслюючи важливість різноманітності та інклюзи...

Короткий зміст: У випуску журналу Microsoft Visual Studio Magazine за листопад 2024 року наведено демонстрацію k-NN регресії з використанням мови C#, відомої своєю простотою та інтерпретованістю. Метод прогнозує числові значення на основі найближчих навчальних даних, а демонстрація демонструє точність і процес прогнозування.

Розробка CNN для задач перевірки автомобільної електроніки з використанням PyTorch. Вивчення згорткових шарів і того, як ШНМ приймають рішення при візуальному огляді.
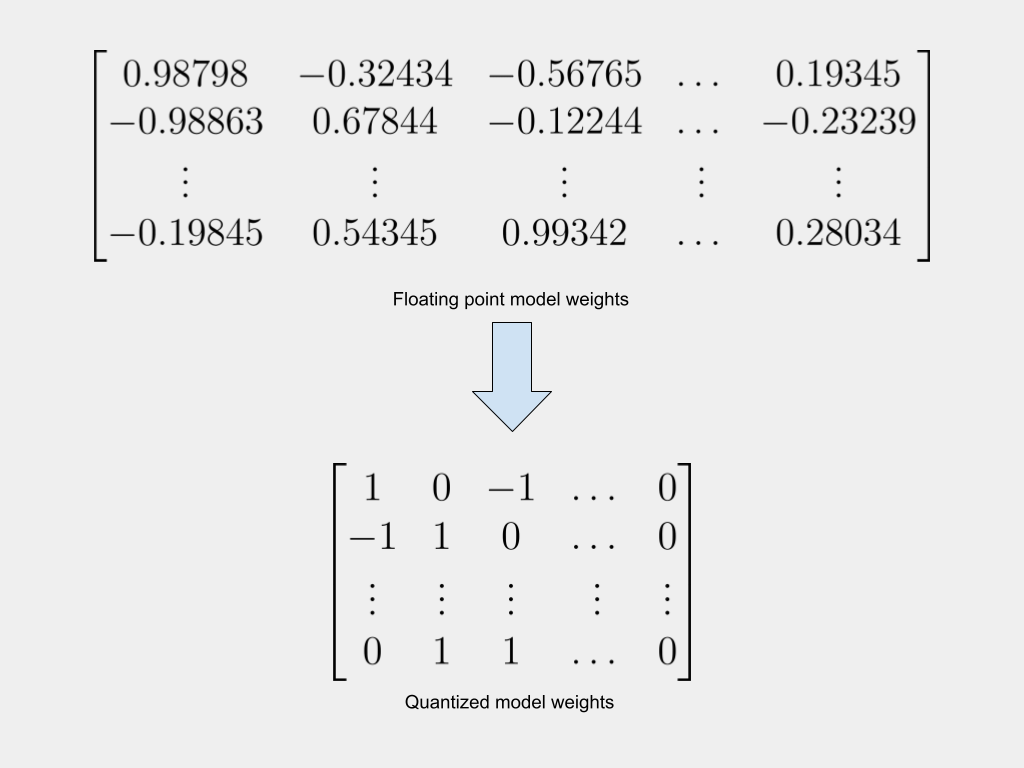
Великі моделі ШІ дорогі у використанні та навчанні, тому основна увага приділяється квантуванню для зменшення розміру моделі при збереженні точності. Два ключові підходи, що обговорюються, - це квантування після навчання (PTQ) і навчання з урахуванням квантування (QAT), кожен з яких має свої власні методи мінімізації втрати точності.

Математика в сучасному машинному навчанні розвивається. Зрушення в бік масштабування розширює сферу застосовних математичних галузей, впливаючи на вибір дизайну.
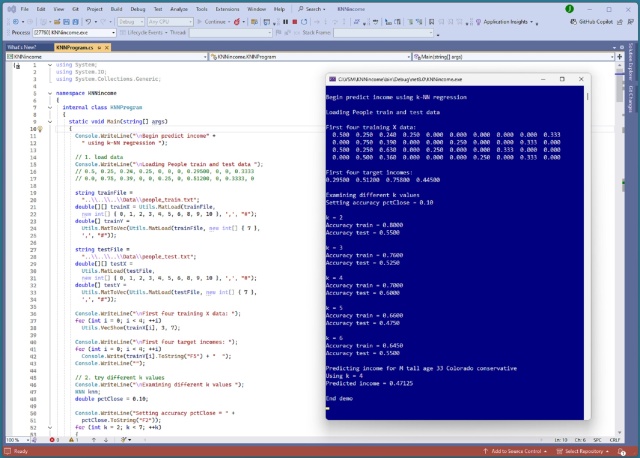
Реалізація k-NN регресії на C# для прогнозування доходу за демографічними даними. Кодування, нормалізація та тестування точності при різних значеннях k.
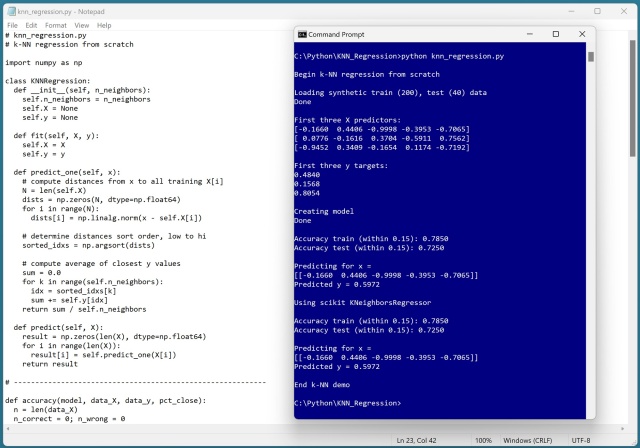
Реалізація регресії k-найближчих сусідів з нуля за допомогою Python на синтетичних даних, демонструючи точність прогнозування в межах 0,15. Валідація з модулем scikit-learn KNeighborsRegressor для зіставлення результатів, що демонструє простоту та ефективність алгоритму.
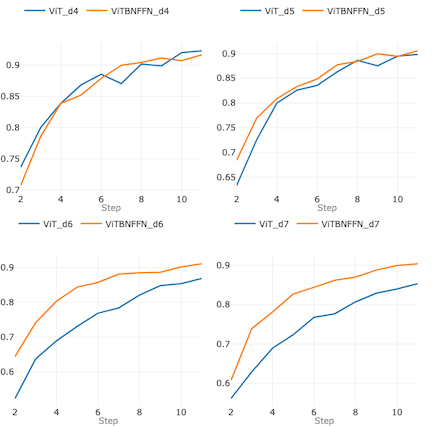
Інтеграція BatchNorm у Vision Transformer призводить до швидшої конвергенції та стабільності. ViTBNFFN перевершує ViT завдяки більшій глибині та вищій швидкості навчання.
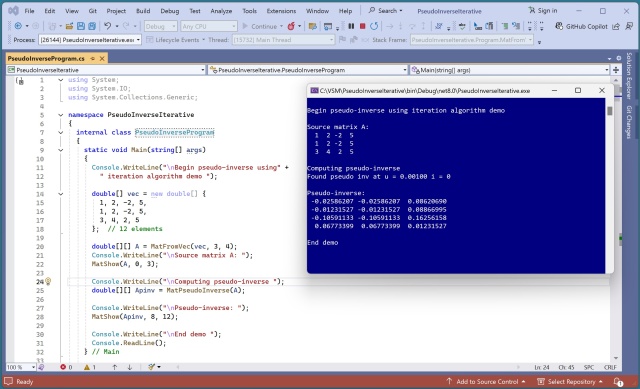
У статті представлено нову елегантну ітераційну техніку для обчислення псевдооберненої матриці Мура-Пенроуза. Метод використовує градієнт обчислення та ітераційні цикли для наближення до істинної псевдооберненої, що нагадує методи навчання нейронних мереж.

Генеративний ШІ від Stability AI трансформує створення візуального контенту для медіа, реклами та індустрії розваг. Нові моделі Amazon Bedrock пропонують покращені можливості перетворення тексту на зображення, підвищуючи креативність та ефективність маркетингу та сторітелінгу.
Моделі ШІ, такі як LLaMA 3.1, вимагають великої пам'яті графічного процесора, що ускладнює доступ до них на споживчих пристроях. Дослідження квантування пропонує рішення для зменшення розміру моделі та уможливлення локального запуску ШІ-моделі.
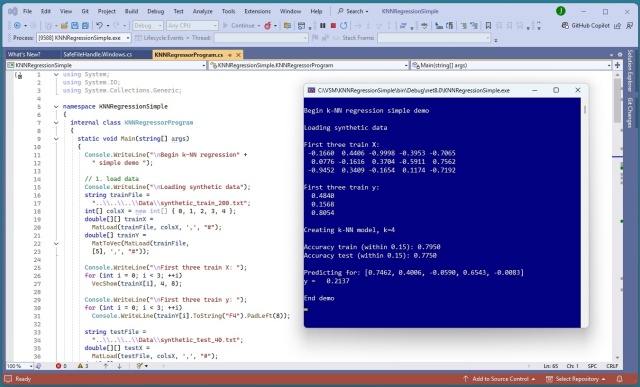
Регресія k-найближчих сусідів прогнозує значення, знаходячи найближчих сусідів у навчальних даних, досягаючи точності 79,50% у демо-версії. На відміну від інших методів, k-NN регресія не створює математичну модель, використовуючи навчальні дані як саму модель.
Стаття пояснює внутрішню роботу великих мовних моделей (ВММ) від базової математики до просунутих моделей ШІ, таких як GPT та трансформаторна архітектура. Детальний розбір охоплює вбудовування, увагу, softmax та багато іншого, що дозволяє відтворювати сучасні LLM з нуля.
Метаморфози ML, процес, що об'єднує різні моделі разом, може значно покращити якість моделей, виходячи за рамки традиційних методів навчання. Дистиляція знань переносить знання з великої моделі в меншу, більш ефективну, що призводить до швидших і легших моделей з покращеною продуктивністю.

Беріть участь у реляційному глибокому навчанні (RDL), безпосередньо навчаючись на реляційній базі даних, перетворюючи таблиці на графік для ефективного виконання завдань ML. RDL усуває етапи функціональної інженерії, навчаючись на необроблених реляційних даних, підвищуючи продуктивність та деталізацію моделі.

Бібліотека GraphMuse Python використовує графові нейронні мережі для аналізу музики, з'єднуючи ноти в партитурі для створення безперервного графіка. Побудована на PyTorch та PyTorch Geometric, GraphMuse перетворює музичні партитури на графіки до x300 швидше, ніж попередні методи, революціонізуючи музичний аналіз.

Дослідники з Массачусетського технологічного інституту пропонують Diffusion Forcing - нову методику навчання, яка поєднує моделі дифузії наступного елемента та повної послідовності для гнучкої та надійної генерації послідовностей. Цей метод покращує прийняття рішень штучним інтелектом, підвищує якість відео та допомагає роботам у виконанні завдань, передбачаючи майбутні кроки з різним рівнем ш...

Джеффрі Хінтон і Джон Хопфілд отримали Нобелівську премію 2024 року за створення штучних нейронних мереж, натхненних роботою мозку. Їхня робота революціонізувала можливості штучного інтелекту завдяки функціям зберігання пам'яті та навчання, що імітують людське пізнання.
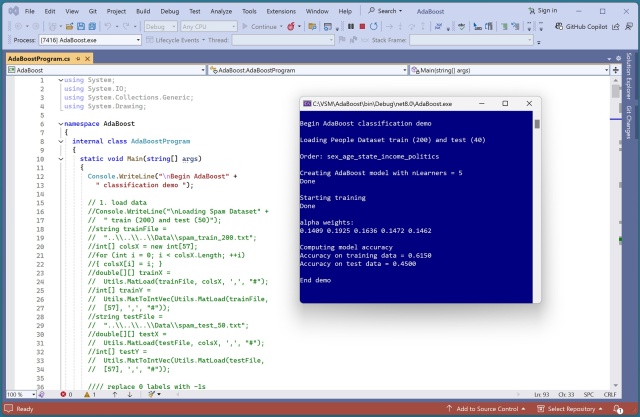
Навчання AdaBoost є детермінованим, на нього не впливає порядок даних. Результати залишаються ідентичними, що є рідкістю для алгоритмів ML.

Навчати моделі комп'ютерного зору за допомогою YOLOv8 від Ultralytics тепер простіше за допомогою Python, CLI або Google Colab. YOLOv8 відомий своєю точністю, швидкістю та гнучкістю, пропонуючи локальні або хмарні варіанти навчання, такі як Google Colab для підвищення обчислювальної потужності.
Дослідники MIT CSAIL розробили підхід на основі штучного інтелекту з використанням графових нейронних мереж для підвищення точності моделювання за рахунок більш рівномірного розподілу точок даних у просторі. Їхній метод, Монте-Карло з передачею повідомлень, покращує моделювання в таких галузях, як робототехніка та фінанси, що має вирішальне значення для точних обчислень.
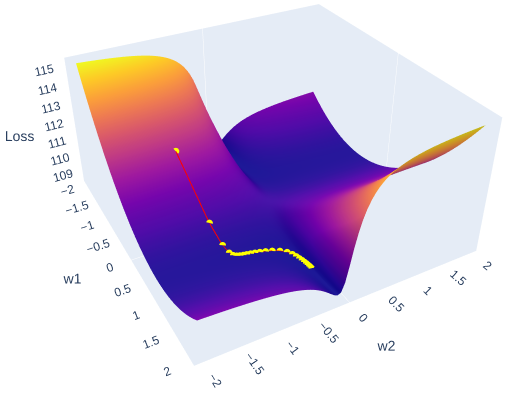
Дослідження нейронних мереж у гідрометеорології: Унікальний підхід до оптимізації поверхонь помилок у 3D за допомогою PyTorch. Дізнайтеся, як візуалізувати та інтерактивно проілюструвати кроки стохастичного градієнтного спуску за допомогою графічної бібліотеки Python.

Платформа хостингу штучного інтелекту Hugging Face налічує 1 мільйон списків моделей штучного інтелекту, пропонуючи кастомізацію для спеціалізованих завдань. Генеральний директор Delangue підкреслює важливість адаптованих моделей для окремих випадків використання, підкреслюючи універсальність платформи.
AdaBoost - це потужний метод бінарної класифікації, продемонстрований у демо-версії для виявлення спаму в електронній пошті. Хоча AdaBoost не вимагає нормалізації даних, він може бути схильний до перенастроювання моделі порівняно з новими алгоритмами, такими як XGBoost та LightGBM.

ШІ-генератор зображень Flux відтворює почерк, викликаючи етичні питання та емоційні зв'язки. Унікальний спосіб зберегти особисті спогади та вшанувати близьких.
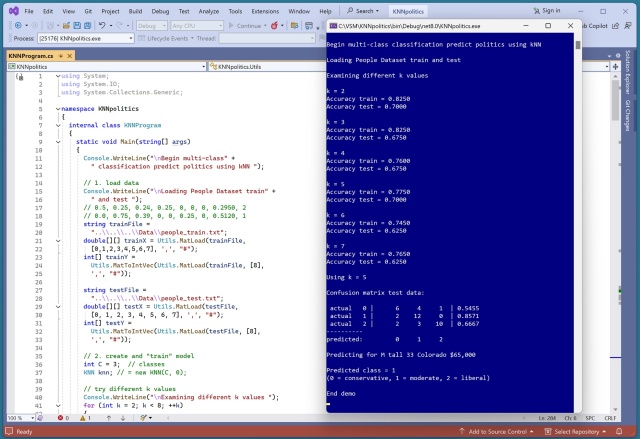
Реалізація багатокласової класифікації k-найближчих сусідів з нуля на синтетичному наборі даних. Кодування та нормалізація вихідних даних для отримання точних прогнозів, причому k=5 дає найкращі результати.

Стискаємо LLM в 10 разів без втрати продуктивності. Такі методи, як квантування, обрізання та дистиляція знань, роблять потужні моделі ML більш доступними.
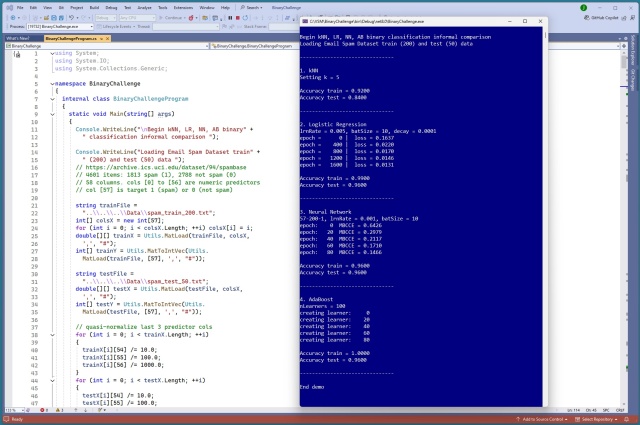
Порівняння kNN, LR, NN та AB для бінарної класифікації дало змогу отримати уявлення про прогностичну силу, легкість навчання та інтерпретованість. Експерименти з набором даних електронного спаму UCI показали, що LR та NN перевершують kNN та AB за точністю.
Google і Тель-Авівський університет представляють GameNGen - модель штучного інтелекту, що імітує гру Doom, використовуючи техніку стабільної дифузії. Нейромережева система може революціонізувати синтез відеоігор у реальному часі, прогнозуючи та генеруючи графіку «на льоту».

Захоплююче резюме: Класична демонстрація Perceptron з використанням набору даних для автентифікації банкнот демонструє просту бінарну класифікацію. Навчальні та тестові дані дають високу точність у прогнозуванні автентичності, підкреслюючи фундаментальну роль персептронів у нейронних мережах.

Інтеграція пакетної нормалізації в архітектуру ViT скорочує час навчання та виведення більш ніж на 60%, зберігаючи або покращуючи точність. Модифікація передбачає заміну нормалізації шарів на пакетну нормалізацію в архітектурі трансформатора, що використовує лише кодер.
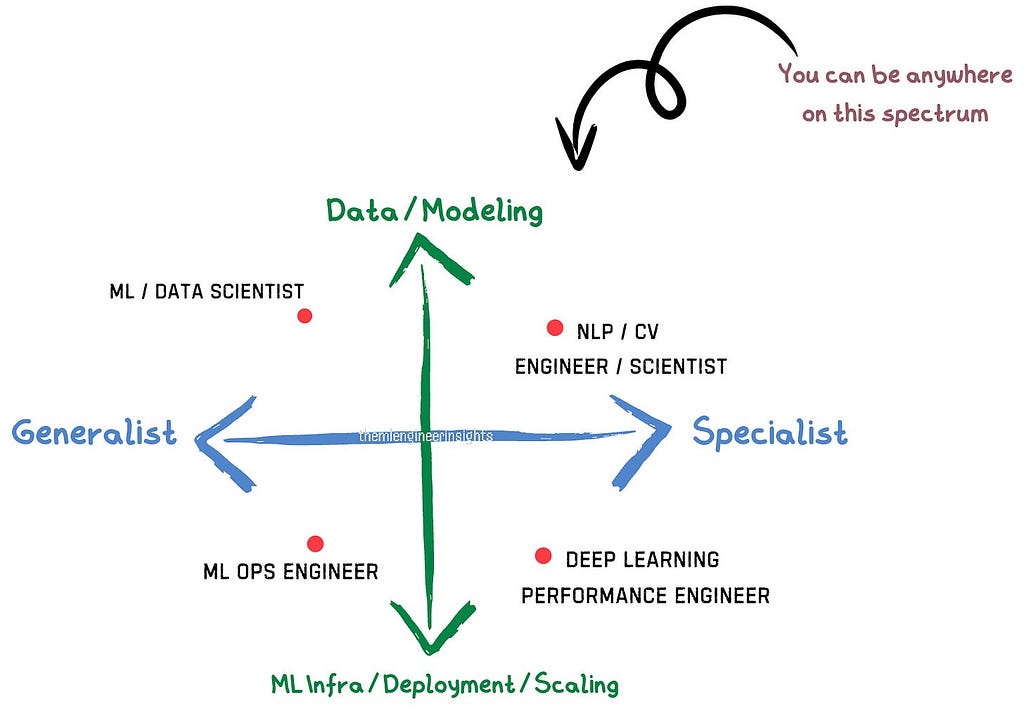
Розшифровка посадових ролей у сфері ВК є ключем до успіху співбесіди. Розуміння спектру ролей може вдосконалити стратегію та підвищити впевненість у собі.

ШІ може створювати зображення і звуки одночасно, наприклад, гавкіт коргі. Дослідники з Мічиганського університету вивчають цю революційну концепцію.

Короткий зміст: Дізнайтеся, як побудувати 124M GPT2 модель за допомогою Jax для ефективного навчання, порівняти її з Pytorch та дослідити ключові можливості Jax, такі як JIT-компіляція та Autograd. Відтворіть NanoGPT за допомогою Jax та порівняйте кількість токенів/сек навчання на декількох графічних процесорах між Pytorch та Jax.

GraphStorm - це низькокодовий GML фреймворк для побудови ML-рішень на графах масштабу підприємства за лічені дні. У версії 0.3 додано підтримку багатозадачного навчання для задач класифікації вузлів та прогнозування зв'язків.
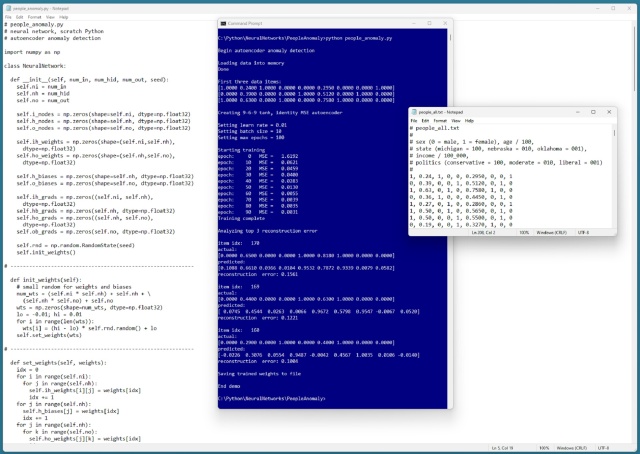
Впровадження нейромережевого автокодера для виявлення аномалій передбачає нормалізацію та кодування даних для точного прогнозування вхідних даних. Процес включає створення мережі з певними входами, виходами та прихованими вузлами, необхідними для уникнення надмірного або недостатнього пристосування.
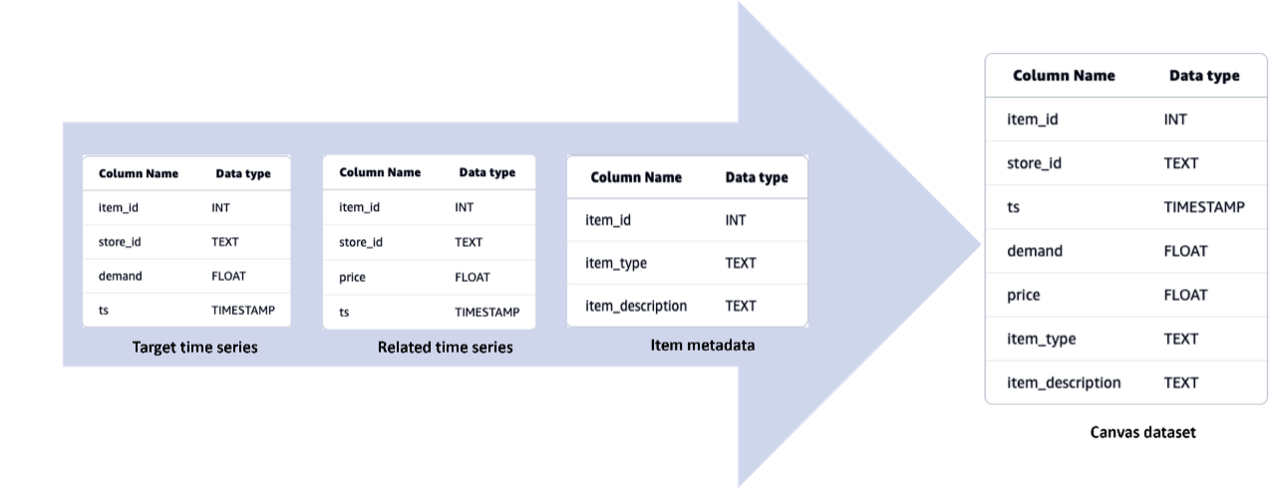
Amazon Forecast, запущений у 2019 році, тепер переводить користувачів на Amazon SageMaker Canvas для швидшого та економічно ефективнішого прогнозування часових рядів з підвищеною прозорістю та можливостями побудови моделей. SageMaker Canvas дозволяє на 50% швидше будувати моделі та на 45% швидше робити прогнози, а також забезпечує чудову прозорість моделей і можливість навчати ансамбль моделей...

Короткий зміст: Дізнайтеся про зменшення розмірності за допомогою нейронного автокодера в C# з журналу Microsoft Visual Studio Magazine. Зменшені дані можна використовувати для візуалізації, машинного навчання та очищення даних, порівнюючи їх з естетикою побудови масштабних моделей літаків.
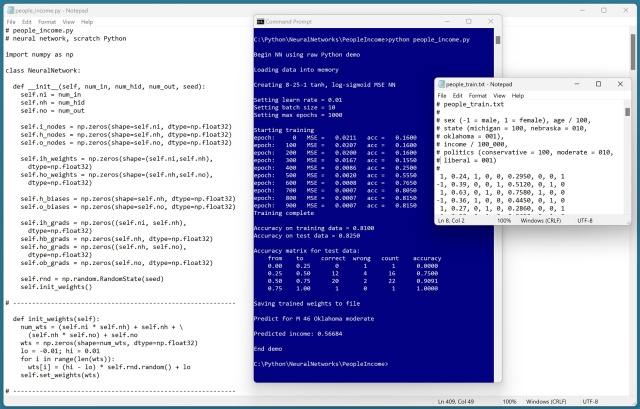
Реалізація нейронної мережі для прогнозування доходів на основі демографічних даних є складною, але корисною справою. Кодування даних, процес навчання та створення мережі є важливими етапами у досягненні точних прогнозів.

Дослідники MIT CSAIL розробили MAIA - автоматизованого агента, який інтерпретує моделі штучного зору, маркує компоненти, очищає класифікатори та виявляє упередження. Гнучкість MAIA дозволяє йому відповідати на різні запити щодо інтерпретації та проводити експерименти «на льоту».

Нещодавні роботи досліджують узагальнення поза розподілом на графічних даних, вирішуючи проблему за допомогою інваріантності та причинно-наслідкового втручання. Важливість машинного навчання на основі графів полягає в його різноманітному застосуванні та представленні складних систем.
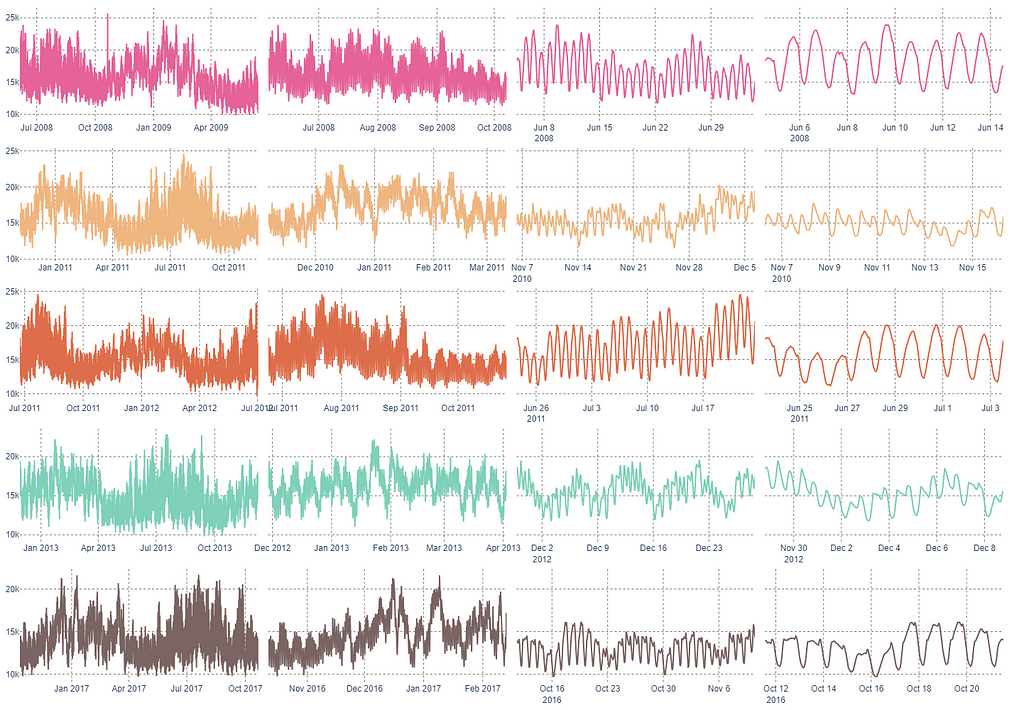
Дізнайтеся про інженерію ознак та побудову MLP-моделі для прогнозування часових рядів. Дізнайтеся, як ефективно проектувати ознаки та використовувати багатошарову персептронну модель для точного прогнозування.
Нейронні мережі покращують дизайн роботів, але створюють проблеми з безпекою. Дослідники Массачусетського технологічного інституту розробляють нові методи забезпечення стабільності, що уможливлює безпечніше розгортання роботів і транспортних засобів, керованих штучним інтелектом.
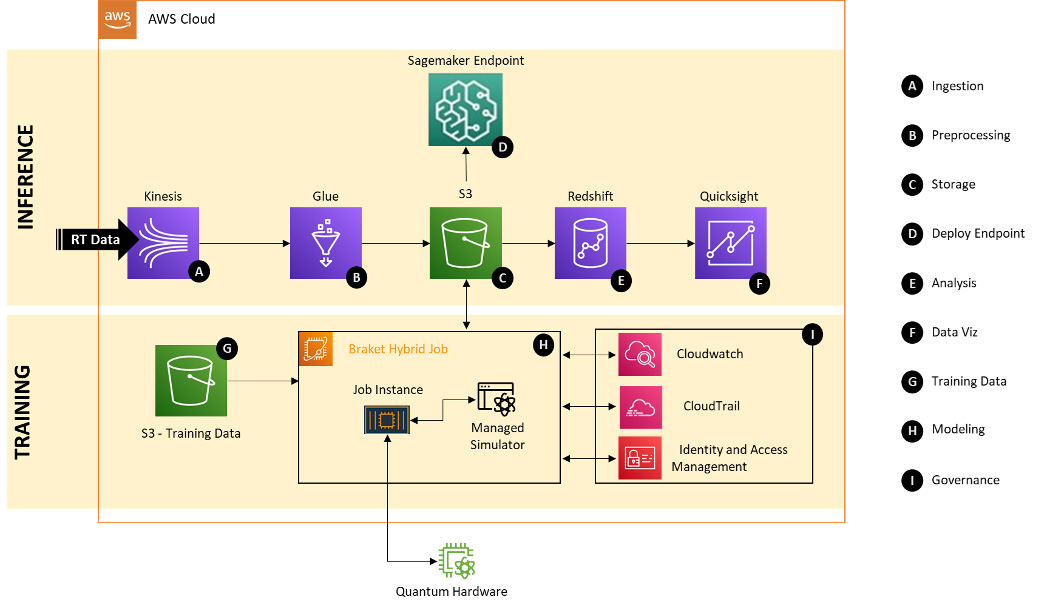
Алгоритми машинного навчання допомагають виявляти шахрайство в режимі реального часу в онлайн-транзакціях, знижуючи фінансові ризики. Deloitte демонструє потенціал квантових обчислень для покращення виявлення шахрайства на цифрових платіжних платформах за допомогою гібридного рішення на основі квантових нейронних мереж, створеного за допомогою Amazon Bracket. Квантові обчислення обіцяють швидш...

Дослідники з Массачусетського технологічного інституту розробили нову систему машинного навчання, яка дозволяє прогнозувати співвідношення фононної дисперсії в 1000 разів швидше, ніж інші методи на основі штучного інтелекту, що допомагає розробляти більш ефективні системи генерації електроенергії та мікроелектроніки. Цей прорив потенційно може бути в 1 мільйон разів швидшим, ніж традиційні під...
Системи рекомендацій зі штучним інтелектом чудово пропонують схожі продукти, але мають проблеми з взаємодоповнюючими. Фреймворк zeroCPR пропонує доступне рішення для виявлення взаємодоповнюючих продуктів за допомогою технології LLM.
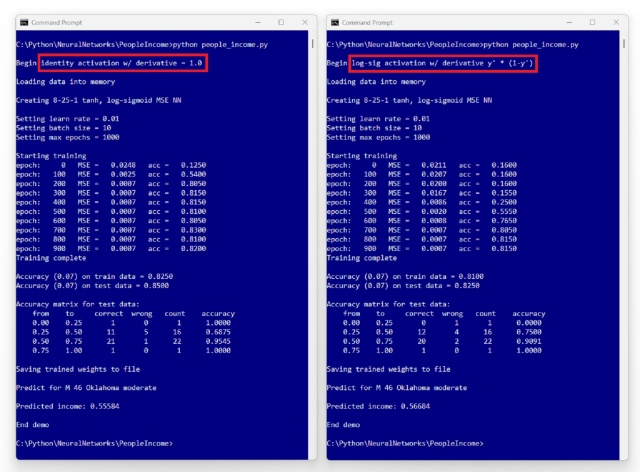
Нейромережеві регресійні моделі: Використовуйте logistic-sigmoid() для обмеженого виходу, identity() для необмеженого виходу. Ключ: член y' (1-y') у градієнті виходу.

Проривний DQN Мегаакорд "Веселка" поєднує в собі 6 потужних варіантів DQN для оптимальної продуктивності в глибокому навчанні з підкріпленням. Бібліотека Stoix розбиває компоненти Rainbow, включаючи алгоритм DQN та реалізацію нейронної мережі.

TDS святкує цю подію цікавими статтями про передові технології комп'ютерного зору та розпізнавання об'єктів. Серед основних моментів - підрахунок об'єктів на відео, відстеження гравців зі штучним інтелектом у хокеї та експрес-курс з планування автономного водіння.

Стаття "MEDUSA: Простий фреймворк для прискорення виведення LLM з декількома декодуючими головками" представляє спекулятивне декодування для прискорення великих мовних моделей, досягаючи 2-3-кратного прискорення на існуючому обладнанні. Додаючи до моделі кілька декодуючих головок, Medusa може передбачати кілька токенів за один прямий прохід, підвищуючи ефективність і якість обслуговування кліє...
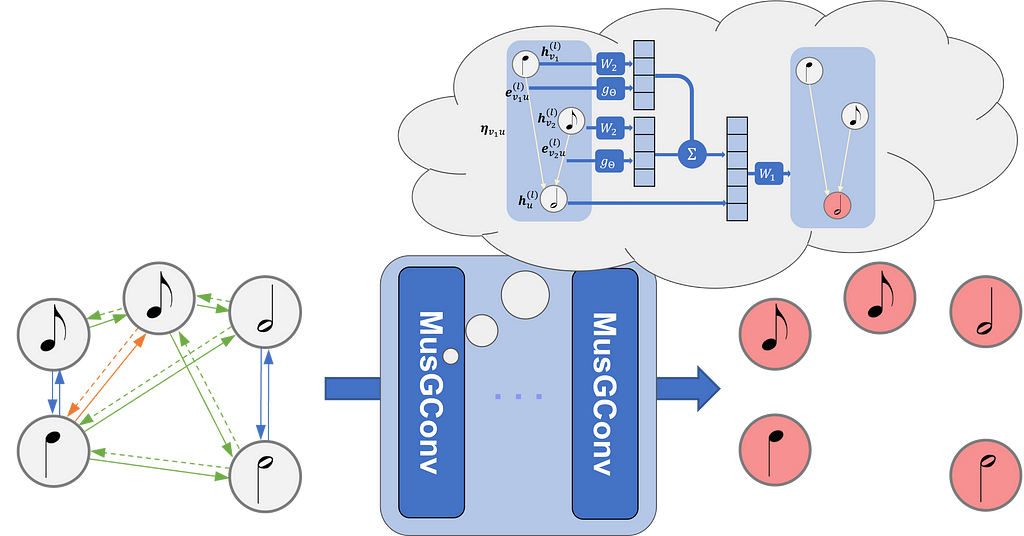
MusGConv представляє блок згортки графів, натхненний сприйняттям, для обробки даних нотної партитури, підвищуючи ефективність і продуктивність в задачах розуміння музики. Традиційні підходи MIR розширюються за допомогою MusGConv, який моделює музичні партитури у вигляді графів для відображення складних, багатовимірних музичних взаємозв'язків.

LSTM, представлені в 1997 році, повертаються разом з xLSTM як потенційні конкуренти LLM у глибокому навчанні. Здатність запам'ятовувати і забувати інформацію через певні проміжки часу відрізняє LSTM від RNN, роблячи їх цінним інструментом у моделюванні мови.
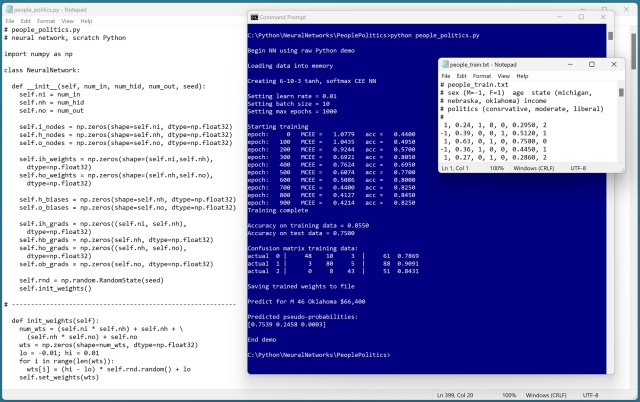
Реалізація нейронних мереж з нуля для прогнозування політичних симпатій з використанням нормалізованих даних та однократного кодування. Складність нейронних мереж досліджено за допомогою вихідного коду Python та NumPy, створення класифікатора із заданими вхідними, прихованими та вихідними вузлами.
Генеративні моделі, такі як GauGAN від NVIDIA, трансформують штучний інтелект у таких додатках, як ChatGPT. GAN використовують нейронні мережі для створення реалістичних зображень, надихаючи на творчість і продуктивність.
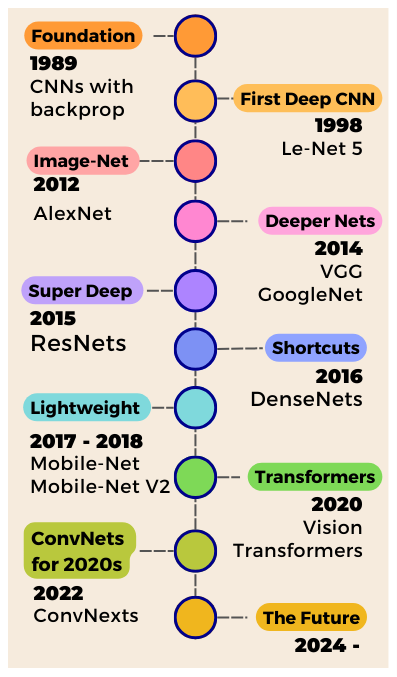
Прорив Яна Лекуна 1989 року з використанням згорткових нейронних мереж зберіг дані просторових зображень, зробивши революцію в дослідженнях комп'ютерного зору. CNN використовують фільтри для вилучення карт об'єктів, накладання шарів для створення потужних класифікаторів зображень.

У статті представлено класифікацію найближчих центроїдів для числових даних у журналі Microsoft Visual Studio Magazine. Класифікація найближчих центроїдів проста, інтерпретована, але менш потужна, ніж інші методи, що дозволяє досягти високої точності у прогнозуванні видів пінгвінів.
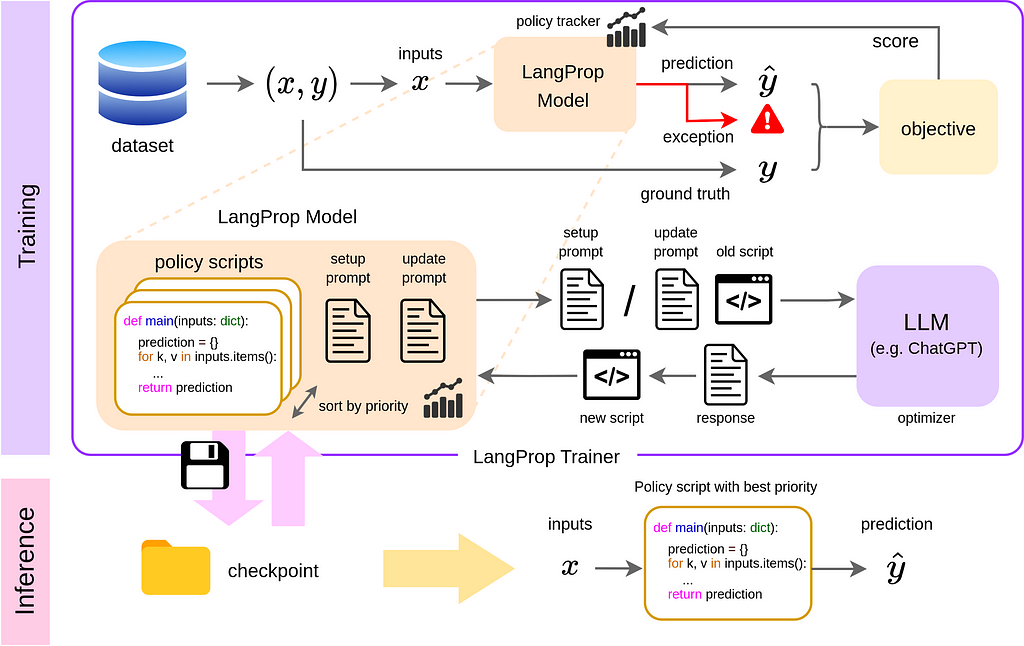
ChatGPT забезпечує дослідження автономного водіння у Wayve, використовуючи фреймворк LangProp для оптимізації коду без тонкого налаштування нейронних мереж. LangProp, представлений на семінарі ICLR, демонструє потенціал LLM для покращення водіння за допомогою генерації та вдосконалення коду.

Дослідники з Каліфорнійського університету в Санта-Крузі, Каліфорнійського університету в Девісі, LuxiTech та Університету Сучжоу розробили мовну модель ШІ без матричного множення, що потенційно зменшує вплив на навколишнє середовище та операційні витрати на системи ШІ. Домінування Nvidia на ринку графічних процесорів для центрів обробки даних, які використовуються в таких системах штучного ін...
Зменшення розмірності за допомогою PCA та нейронного автокодера в C#. Автокодер зменшує розмірність змішаних даних, PCA - лише числових. Автокодер корисний для візуалізації даних, ML, очищення даних, виявлення аномалій.
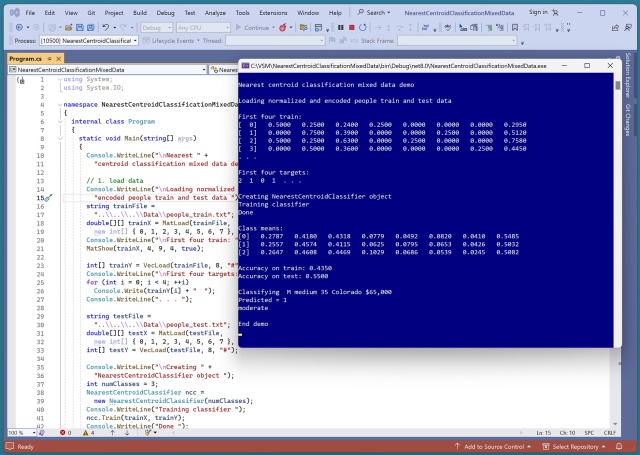
Класифікація найближчого центроїда виявилася неефективною для складних прогнозів, показавши лише 55% точності на тестових даних. Він найкраще підходить для порівняння з більш потужними методами класифікації, такими як нейронні мережі.

Розпізнавання іменних об'єктів (NER) витягує об'єкти з тексту, традиційно вимагаючи точного налаштування. Нові великі мовні моделі уможливлюють NER з нуля, як-от Amazon Bedrock's LLMs, революціонізуючи виокремлення сутностей.
AI Agent Capabilities Engineering Framework представляє ментальну модель для проектування агентів штучного інтелекту на основі когнітивних та поведінкових наук. Фреймворк класифікує здібності на Сприйняття, Мислення, Дії та Адаптацію, щоб забезпечити ШІ-агентів для виконання складних завдань з людським рівнем майстерності.
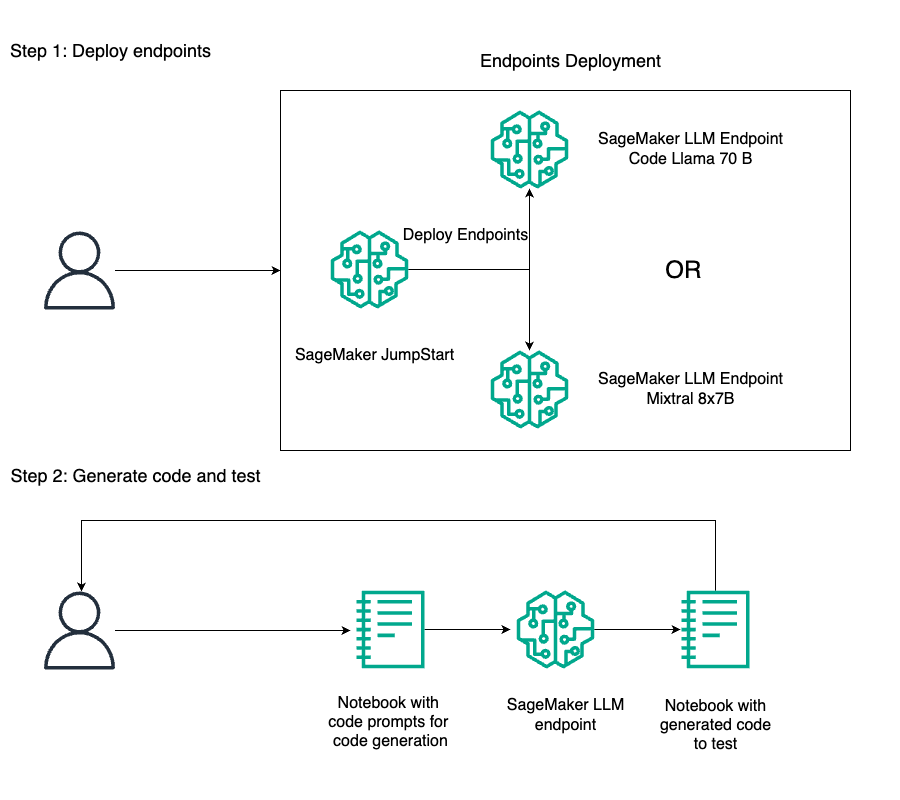
Code Llama 70B та Mixtral 8x7B - це передові моделі великих мов для генерації та розуміння коду, що мають мільярди параметрів. Розроблені компаніями Meta та Mistral AI, ці моделі пропонують неперевершену продуктивність, взаємодію з природною мовою та підтримку довготривалого контексту, революціонізуючи кодування з допомогою ШІ.

Короткий зміст: У цій серії блогів ви дізнаєтеся про адаптацію доменів для LLM. Дізнайтеся про тонке налаштування для розширення можливостей моделей і підвищення продуктивності.

Антропний ШІ досліджує вилучення інтерпретованих ознак за допомогою розріджених автокодерів, прагнучи подолати «полісемантичність» нейронних мереж. Роботи професора Тома Йе чудово пояснюють роботу цих механізмів.
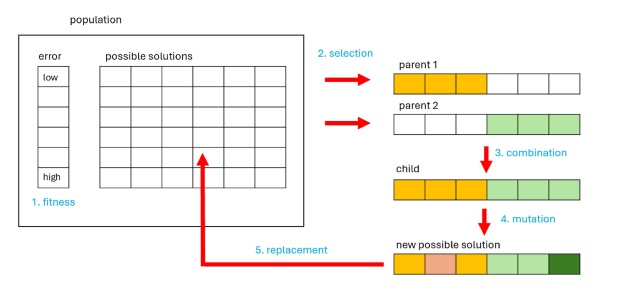
Еволюційні алгоритми (ЕА) мають обмежену математичну базу, що призводить до нижчого престижу та обмеженої тематики досліджень у порівнянні з класичними алгоритмами. ЕА стикаються з бар'єрами через свою простоту, що призводить до меншої кількості ретельних досліджень і меншого дослідницького потенціалу.
Нещодавня стаття Anthropic заглиблюється в механічну інтерпретованість великих мовних моделей, показуючи, як нейронні мережі представляють значущі концепції за допомогою напрямків у просторі активації. Дослідження надає докази того, що ознаки, які можна інтерпретувати, корелюють з конкретними напрямками, впливаючи на результат роботи моделі.

Найбільші технологічні компанії, такі як Google, Microsoft і Meta, об'єдналися в групу UALink, щоб розробити новий стандарт з'єднання чіпів для прискорювачів ШІ, кинувши виклик домінуванню NVLink від Nvidia. UALink має на меті створити відкритий стандарт для вдосконалення апаратного забезпечення ШІ, уможливити співпрацю та звільнитися від пропрієтарних екосистем, подібних до екосистеми Nvidia.
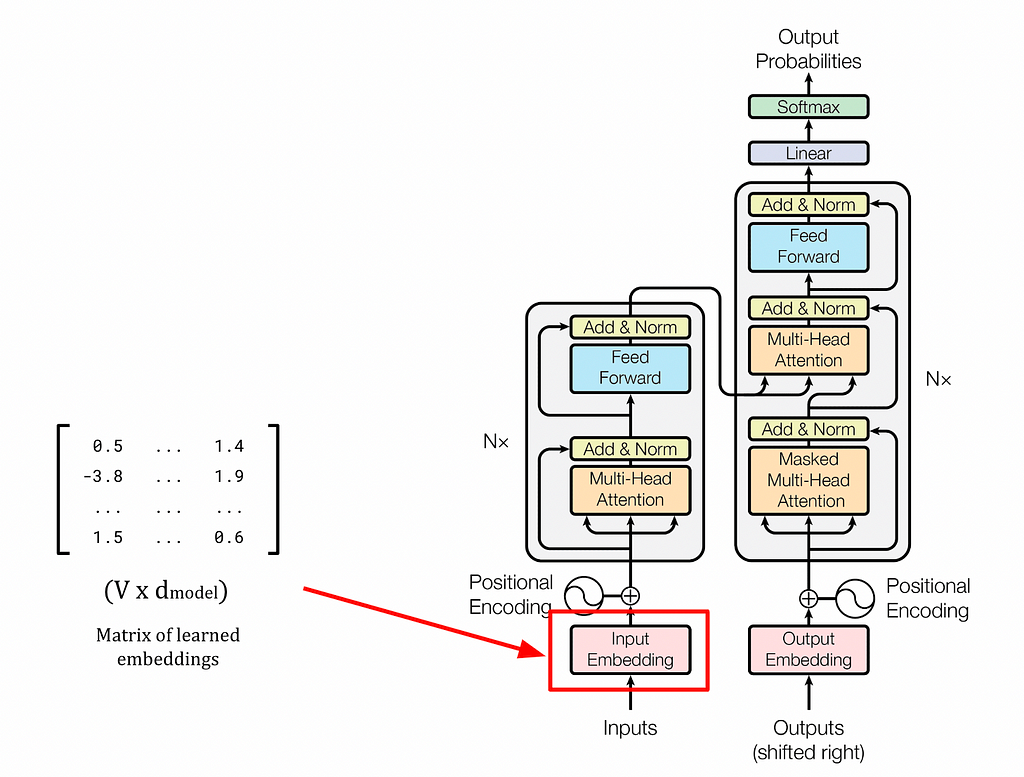
Великі мовні моделі, такі як GPT та BERT, покладаються на архітектуру трансформатора та механізм самоуваги для створення контекстуально багатих вбудовувань, що революціонізувало НЛП. Статичні вставки, такі як word2vec, не здатні вловити контекстну інформацію, що підкреслює важливість динамічних вставок у мовних моделях.
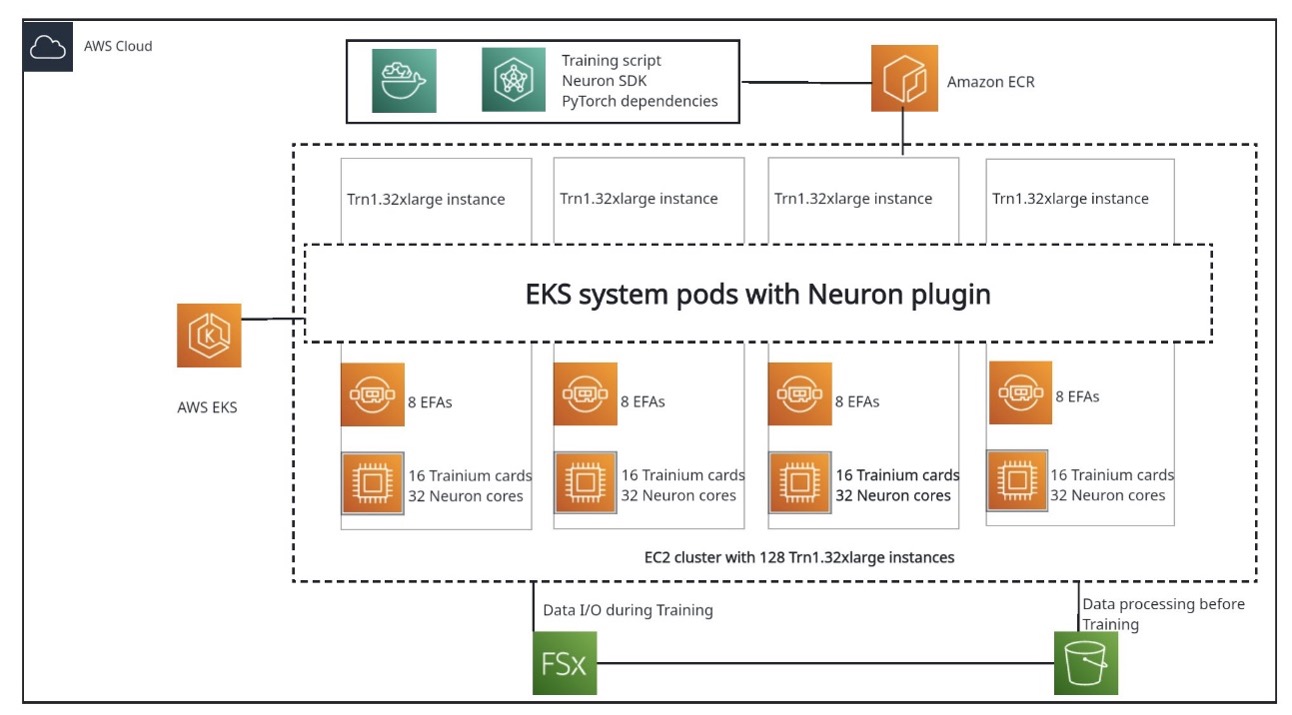
Llama, популярна велика мовна модель Meta AI, стикається з труднощами при навчанні, але може досягти порівнянної якості за допомогою належного масштабування та найкращих практик на AWS Trainium. Розподілене навчання на 100+ вузлах є складним завданням, але кластери Trainium пропонують економію коштів, ефективне відновлення та покращену стабільність для навчання LLM.
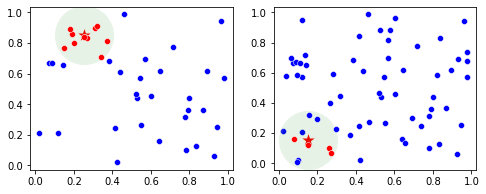
Інтерпретовані моделі, такі як XGBoost, CatBoost і LGBM, забезпечують прозорість, чітко пояснюючи прогнози. Методи пояснюваного ШІ (XAI) дають уявлення, але можуть не збігатися з точністю з моделями чорного ящика.

Стаття про LightGBM для багатокласової класифікації в Microsoft Visual Studio Magazine демонструє його потужність і простоту використання, а також дає уявлення про оптимізацію параметрів і його конкурентну перевагу в нещодавніх змаганнях. LightGBM, деревоподібна система, перемагає в конкурсах, що робить її найкращим вибором для точної та ефективної багатокласової класифікації.

Гіперпараметри в ML суттєво впливають на продуктивність моделі. Автоматизована оптимізація гіперпараметрів може підвищити ефективність моделі.

Джонатан Раган-Келлі з Массачусетського технологічного інституту є піонером у створенні ефективних мов програмування для складних апаратних засобів, що трансформують програми для редагування фотографій та штучного інтелекту. Його робота зосереджена на оптимізації програм для спеціалізованих обчислювальних блоків, що дозволяє досягти максимальної обчислювальної продуктивності та ефективності.
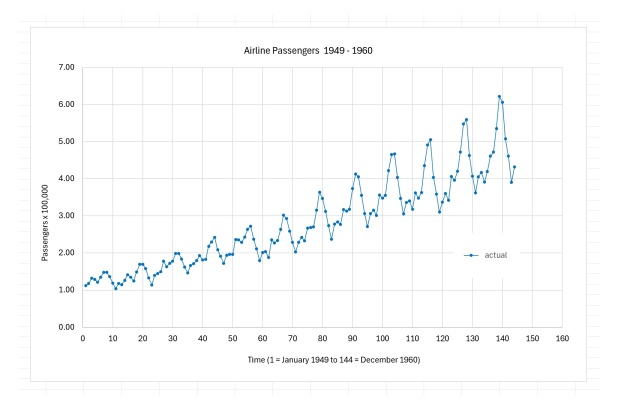
Регресія часових рядів є складним завданням, для вирішення якого існують різні методи. Нещодавні дослідження вивчають використання нейронних мереж, таких як трансформатори, для підвищення точності прогнозування.
Дослідники MIT CSAIL розробили нейросимволічний фреймворк LILO, який поєднує великі мовні моделі з алгоритмічним рефакторингом для створення абстракцій для синтезу коду. Акцент LILO на природній мові дозволяє йому виконувати завдання, що вимагають знань, подібних до людських, перевершуючи окремі LLM та попередні алгоритми.
Дізнайтеся про революційні дослідження, проведені компаніями Tesla та SpaceX у галузі відновлюваних джерел енергії. Дізнайтеся про останні досягнення в галузі сонячної енергетики.

Захоплюючий прорив у технології штучного інтелекту від XYZ Corp. обіцяє зробити революцію в аналізі даних. Революційне дослідження відкриває потенціал для нового лікування раку за допомогою нанотехнологій.

Дізнайтеся, як інноваційні компанії, такі як Tesla та SpaceX, революціонізують автомобільну та аерокосмічну галузі за допомогою передових технологій. Дізнайтеся про останні досягнення в галузі електромобілів та космічних досліджень, які змінюють майбутнє транспорту.

Дізнайтеся, як компанія X зробила революцію в галузі завдяки своєму новаторському продукту, продемонструвавши передові технології. Дізнайтеся про дивовижні відкриття, які змінюють майбутнє ринку.

Відкрийте для себе останні досягнення в технології штучного інтелекту завдяки революційним дослідженням від Google і Microsoft. Дізнайтеся, як ці компанії революціонізують майбутнє штучного інтелекту.

Відкрийте для себе останні революційні дослідження провідних технологічних компаній щодо застосування штучного інтелекту в охороні здоров'я. Дізнайтеся, як досягнення в галузі машинного навчання революціонізують догляд за пацієнтами та діагностику.

Дізнайтеся, як інноваційний стартап XYZ революціонізує технологічну індустрію завдяки своїй революційній технології штучного інтелекту. Дізнайтеся, як провідні компанії вже впроваджують продукти XYZ для підвищення ефективності та продуктивності.

Відкрийте для себе революційну технологію штучного інтелекту, розроблену компанією XYZ, яка революціонізує індустрію охорони здоров'я. Дізнайтеся, як їхній інноваційний продукт трансформує догляд за пацієнтами та діагностику.

Дізнайтеся, як компанія XYZ зробила революцію в технологічній індустрії завдяки своїй революційній технології штучного інтелекту. Дізнайтеся про вражаючі результати та майбутні наслідки їхнього інноваційного продукту.

Нове дослідження розкриває революційну технологію штучного інтелекту, розроблену компанією Google, яка революціонізує аналіз даних у сфері охорони здоров'я. Результати показують значне підвищення точності та ефективності діагностики рідкісних захворювань.

Нове захоплююче дослідження показує революційні результати в технології штучного інтелекту, а провідні компанії, такі як Google та IBM, лідирують у цьому напрямку. Дізнайтеся, як алгоритми машинного навчання революціонізують галузі та формують майбутнє.

Відкрийте для себе революційні дослідження компанії Tesla у сфері сталих енергетичних рішень. Вивчіть інноваційні продукти та технології, що революціонізують автомобільну індустрію.
Ознайомтеся з останніми революційними дослідженнями щодо застосування штучного інтелекту в охороні здоров'я. Дізнайтеся, як такі компанії, як IBM і Google, революціонізують догляд за пацієнтами за допомогою інноваційних технологій.

Дізнайтеся, як компанія X зробила революцію в технологічній галузі завдяки своїй революційній технології штучного інтелекту, проклавши шлях до безпрецедентних досягнень. Дізнайтеся про вплив їхнього продукту на різні галузі та майбутні наслідки цієї інновації, що змінила правила гри.

Дізнайтеся, як компанія X зробила революцію в технологічній індустрії завдяки своєму революційному продукту. Дізнайтеся про інноваційні функції, які змінюють правила гри для споживачів у всьому світі.

Дізнайтеся, як інноваційні технологічні стартапи революціонізують галузь охорони здоров'я завдяки діагностичним інструментам на основі штучного інтелекту. Від компаній MedTech до революційних результатів досліджень - будьте на крок попереду з останніми досягненнями в галузі медичних технологій.

Дізнайтеся, як компанія XYZ здійснила революцію в технологічній індустрії завдяки своїй революційній технології штучного інтелекту. Дізнайтеся про вплив на автоматизацію робочих місць і майбутні досягнення в цій галузі.

Сесія GTC від NVIDIA, присвячена нейронній мережі-трансформеру, революціонізує глибоке навчання. Автори розмірковують про революційні дослідження, що формують майбутнє генеративного ШІ.

У статті "Надзвичайно великі нейронні мережі" представлено шар з малою кількістю воріт (Sparely-Gated Mixture-of-Experts Layer) для підвищення ефективності та якості нейронних мереж. Експерти на рівні токенів з'єднуються за допомогою воріт, що зменшує обчислювальну складність і підвищує продуктивність.

Останні досягнення в галузі штучного інтелекту, включаючи GenAI та LLM, революціонізують галузі завдяки підвищенню продуктивності та можливостей. Архітектури трансформаторів зору, такі як ViTs, змінюють комп'ютерний зір, пропонуючи чудову продуктивність і масштабованість порівняно з традиційними CNN.

У 1928 році Олександр Флемінг випадково відкрив пеніцилін, зробивши революцію в медицині. Чи можуть великі мовні моделі стати несподіваною відповіддю на питання автономного водіння? Давайте розглянемо потенційний вплив у цій статті.
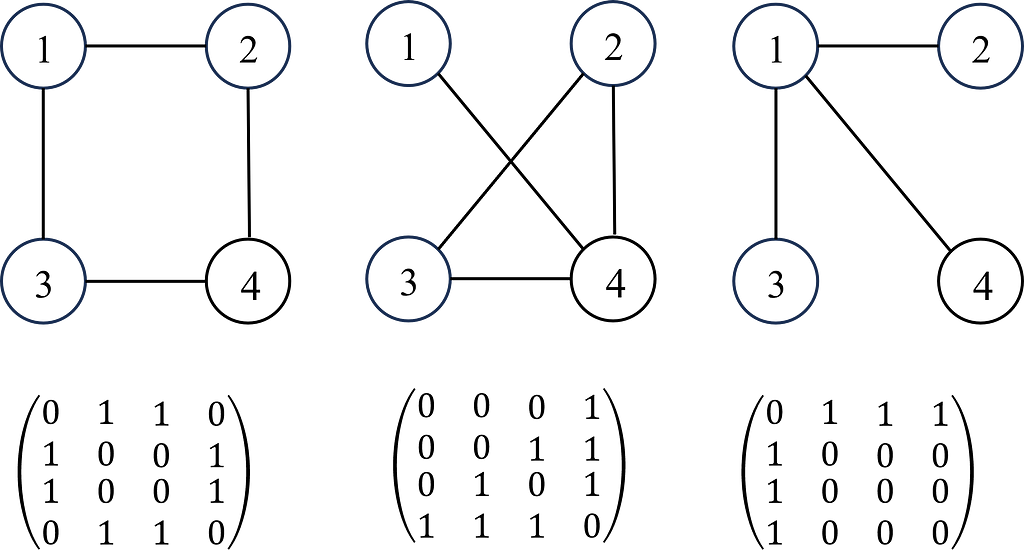
Графові нейронні мережі (ГНМ) моделюють взаємопов'язані дані, такі як молекулярні структури та соціальні мережі. ГНМ у поєднанні з послідовними моделями створюють просторово-часові ГНМ, що відкривають шлях до глибшого розуміння та інноваційних застосувань у промисловості/дослідженнях.
ThirdAI Corp. є першопрохідцем у сфері економічно ефективного глибокого навчання на стандартних процесорах, кидаючи виклик потребі у дорогих графічних прискорювачах. AWS Graviton3 демонструє багатообіцяюче прискорення навчання нейронних моделей, революціонізуючи економіку ШІ.

Дослідники Массачусетського технологічного інституту розробили модель глибокого навчання для розвантаження роботизованих складів, підвищивши ефективність майже в чотири рази. Їхній інноваційний підхід може революціонізувати складні завдання планування, що виходять за рамки складських операцій.

Режисер Тайлер Перрі зупинив розширення студії вартістю 800 мільйонів доларів завдяки можливостям АІ-відеогенератора Sora. Sora від OpenAI вражає синтезом тексту та відео, перевершуючи інші моделі штучного інтелекту.

У статті "Пряма оптимізація преференцій" представлено новий спосіб точного налаштування фундаментальних моделей, що призводить до вражаючого зростання продуктивності з меншою кількістю параметрів. Цей метод замінює потребу в окремій моделі винагороди, революціонізуючи спосіб оптимізації LLM.

Конференція NVIDIA GTC 2024 у Сан-Хосе обіцяє бути горнилом інновацій з 900+ сесіями та 300 експонатами, в яких візьмуть участь такі гіганти індустрії, як Amazon, Ford, Pixar та інші. Не пропустіть панель Transforming AI Panel з першими архітекторами нейронної мережі-трансформера, а також мережеві заходи та найсучасніші виставки, які допоможуть вам залишатися на крок попереду в галузі ШІ.

Google представляє Gemma, нові мовні моделі штучного інтелекту з відкритим вихідним кодом, з параметрами 2B і 7B. Моделі Gemma можуть працювати локально і натхненні потужними моделями Gemini.
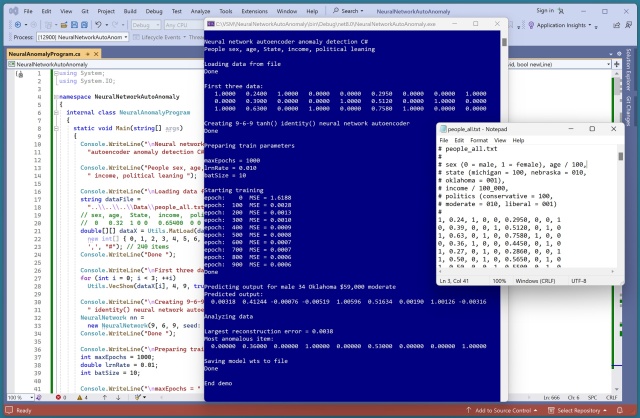
Автокодер прогнозує вхідні дані, позначаючи аномалії. Реалізований на C#, він виявив ліберального чоловіка з Небраски з доходом 53 000 доларів як найбільш аномального. Модель навчена за архітектурою 9-6-9, що дає уявлення про нейромережеві системи.

У статті обговорюється еволюція моделей GPT, зокрема, зосереджується увага на покращеннях GPT-2 порівняно з GPT-1, включаючи його більший розмір та можливості багатозадачного навчання. Розуміння концепцій, що лежать в основі GPT-1, має вирішальне значення для розпізнавання принципів роботи більш просунутих моделей, таких як ChatGPT або GPT-4.
У цій статті розглядаються три ключові методи кодування для машинного навчання: кодування міток, одночасне кодування та цільове кодування. Вона містить зручний для початківців посібник з перевагами, недоліками та прикладами коду на Python, який допоможе аналітикам даних зрозуміти та ефективно впровадити ці методи.

У 2021 році фармацевтична промисловість згенерувала 550 мільярдів доларів доходу в США, а до 2022 року прогнозовані витрати на діяльність з фармаконагляду становитимуть 384 мільярди доларів. Для вирішення проблем моніторингу небажаних явищ розроблено рішення на основі машинного навчання з використанням Amazon SageMaker та моделі BioBERT від Hugging Face, що забезпечує автоматизоване виявлення ...

Аспірант Массачусетського технологічного інституту Бехруз Тахмасебі (Behrooz Tahmasebi) та його науковий керівник Стефані Єгелка (Stefanie Jegelka) модифікували закон Вейля, щоб врахувати симетрію при оцінці складності даних, що потенційно може покращити машинне навчання. Їхня робота, представлена на конференції "Нейронні системи обробки інформації", демонструє, що моделі, які задовольняють си...
Дослідники з Массачусетського технологічного інституту розробили автоматизований агент інтерпретації (AIA), який використовує моделі штучного інтелекту для пояснення поведінки нейронних мереж, пропонуючи інтуїтивно зрозумілі описи та відтворення коду. AIA бере активну участь у формуванні гіпотез, експериментальному тестуванні та ітеративному навчанні, вдосконалюючи своє розуміння інших систем ...

Дослідники з Массачусетського технологічного інституту та компанії IBM розробили новий метод під назвою "глибокий фізичний сурогат" (PEDS), який поєднує в собі фізичний симулятор з низькою точністю та генератор нейронних мереж для створення сурогатних моделей складних фізичних систем на основі даних. Метод PEDS є доступним, ефективним і зменшує кількість необхідних навчальних даних щонайменше ...

Аспіранти Массачусетського технологічного інституту використовують теорію ігор для підвищення точності та надійності моделей природної мови, прагнучи узгодити достовірність моделі з її точністю. Перетворивши генерування мови на гру для двох гравців, вони розробили систему, яка заохочує правдиві та достовірні відповіді, водночас зменшуючи кількість галюцинацій.

Вчені Массачусетського технологічного інституту розробили дві моделі машинного навчання - нейронну мережу "PRISM" та модель логістичної регресії - для раннього виявлення раку підшлункової залози. Ці моделі перевершили існуючі методи, виявивши 35% випадків у порівнянні зі стандартним рівнем виявлення 10%.
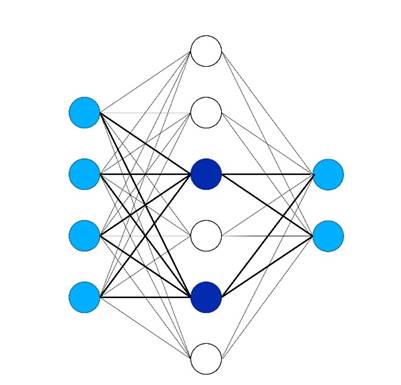
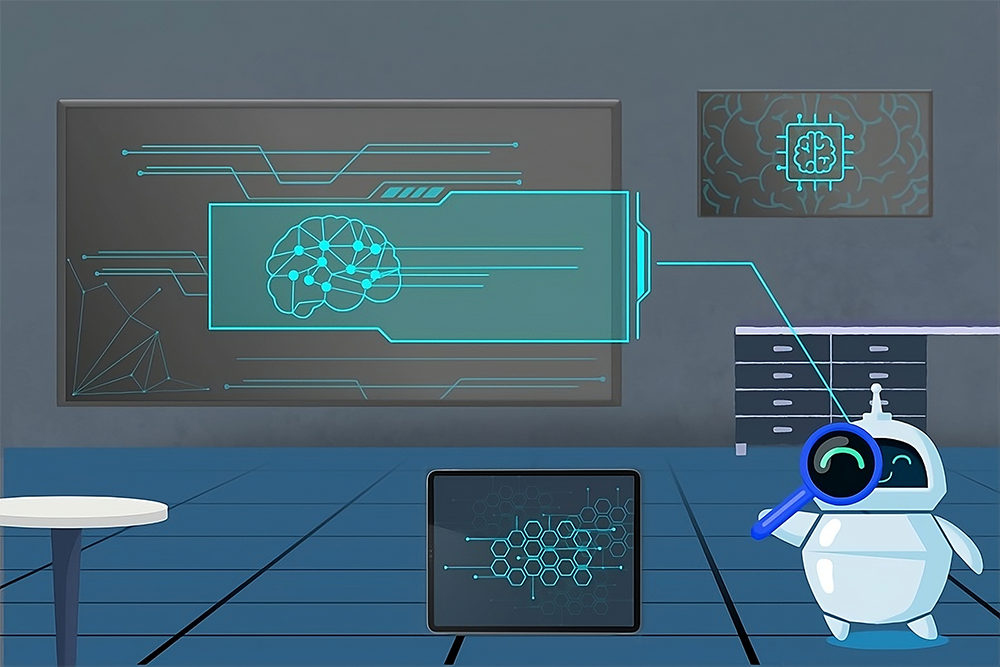
Нейронна мережа з одним прихованим шаром, що використовує активацію ReLU, може представляти будь-які неперервні нелінійні функції, що робить її потужним апроксиматором функцій. Мережа може апроксимувати неперервні кусково-лінійні (CPWL) та неперервні криві (CC) функції, додаючи нові ReLU-функції в точках переходу для збільшення або зменшення нахилу.

Поява таких інструментів, як AutoAI, може зменшити важливість традиційних навичок машинного навчання, але глибоке розуміння основних принципів ML все одно буде затребуваним. У цій статті розглядаються математичні основи рекурентних нейронних мереж (RNN) та досліджується їх використання для виявлення послідовних закономірностей у часових рядах даних.
Останні досягнення в галузі штучного інтелекту дозволили моделям імітувати людські здібності в обробці зображень і тексту, але брак пояснюваності створює ризики і обмежує впровадження. Такі критичні сфери, як охорона здоров'я та фінанси, значною мірою покладаються на табличні дані, що підкреслює потребу в прозорих моделях прийняття рішень.

У цій статті автори обговорюють теорію та архітектуру графових нейронних мереж (ГНМ) і висвітлюють появу графових трансформаторів як тенденцію в графовому МН. Вони досліджують зв'язок між ГНМ і трансформаторами, показуючи, що ГНМ з віртуальним вузлом може імітувати трансформатор, і обговорюють переваги та обмеження цих архітектур з точки зору виразності.

Комп'ютерний зір еволюціонував від маленьких піксельних зображень до створення зображень високої роздільної здатності на основі описів, причому менші моделі покращують продуктивність у таких сферах, як фотографування смартфонів та автономні транспортні засоби. Модель ResNet домінує в комп'ютерному зорі вже майже вісім років, але з'являються нові розробки, такі як Vision Transformer (ViT), що д...

Глибинне навчання (ГН) зробило революцію в згорткових нейронних мережах (ЗНМ) і генеративному ШІ, а пакетна нормалізація 2D (BN2D) стала супергеройською технікою, яка покращує збіжність навчання моделей і продуктивність висновків. BN2D нормалізує розмірні дані, запобігаючи внутрішнім коваріаційним зсувам і сприяючи швидшій збіжності, дозволяючи мережі зосередитися на вивченні складних характер...

Генеративні змагальні мережі (GAN) привернули увагу завдяки своїй здатності генерувати реалістичні синтетичні дані, а також через їх зловживання при створенні глибоких фейків. Унікальна архітектура GAN включає генеративну мережу та мережу суперників, які навчаються досягати протилежних цілей за допомогою дворівневої оптимізації.

PGA TOUR розробляє систему відстеження положення м'яча наступного покоління, яка використовує комп'ютерний зір і методи машинного навчання для визначення місцезнаходження м'ячів для гольфу на паттінг-гріні. Система, розроблена Інноваційним центром Amazon Generative AI, успішно відстежує положення м'яча та прогнозує координати його спокою.

Основні тези статті: Руйнівне тестування нейронних мереж та архітектур ML для підвищення надійності. Абляційне тестування визначає критичні частини, зменшує складність і підвищує відмовостійкість. Три типи абляційних тестів: нейронне, функціональне та вхідне абляційне тестування.
На початку 00-х Джефф Хінтон представив алгоритм контрастної дивергенції, що дозволяє навчати обмежену машину Больцмана. Гармонії, або обмежені машини Больцмана, - це нейронні мережі, що працюють з бінарними даними, з видимими і прихованими блоками, і є корисними для моделювання дискретних даних.

У цій статті досліджуються методи прискорення в нейронних мережах, підкреслюється необхідність швидшого навчання через складність моделей глибокого навчання. Вона вводить поняття градієнтного спуску та висвітлює обмеження його повільної швидкості збіжності. Потім у статті представлено алгоритм оптимізації Momentum, який використовує експоненціально ковзну середню для досягнення швидшої збіжності.
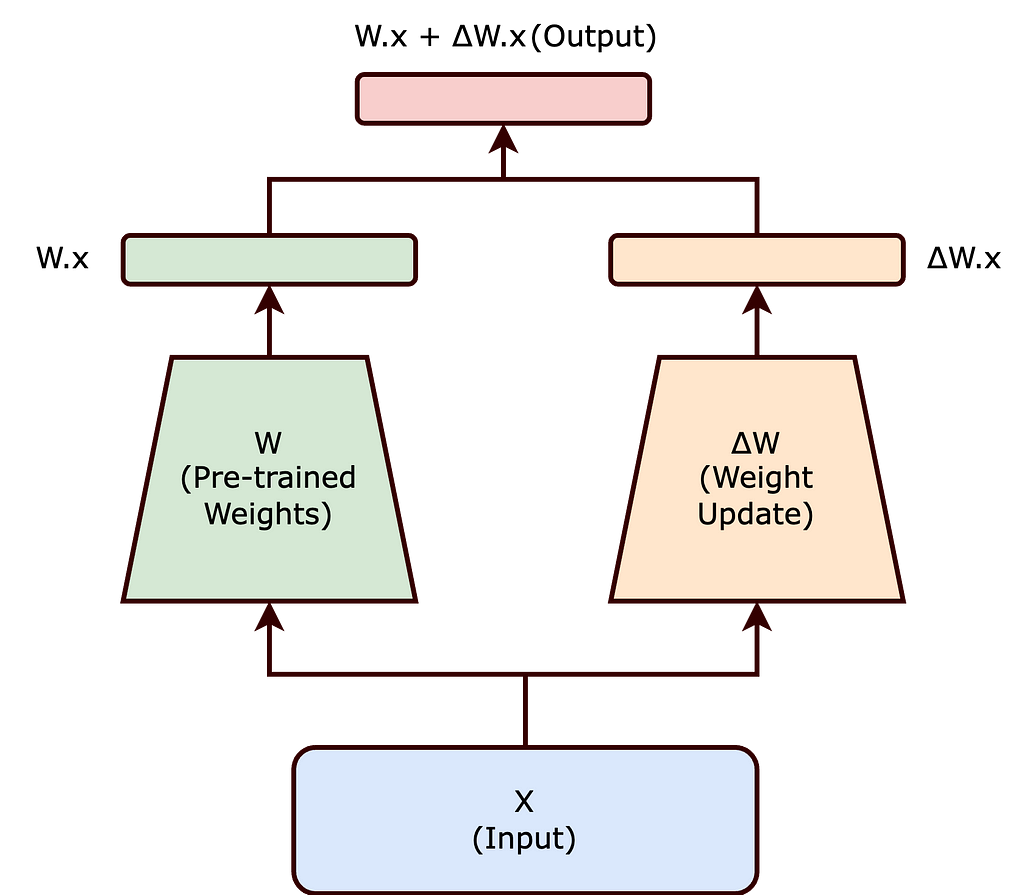
LoRA - це ефективний метод точного налаштування великих моделей, що дозволяє зменшити обчислювальні ресурси та час. Завдяки декомпозиції матриці оновлень LoRA пропонує такі переваги, як менший обсяг пам'яті, швидше навчання, можливість використання меншого апаратного забезпечення та масштабованість до більших моделей.

NVIDIA Studio представляє DLSS 3.5 для реалістичної візуалізації з трасуванням променів у D5 Render, покращуючи досвід редагування та підвищуючи частоту кадрів. Відомий художник Майкл Гілмор (Michael Gilmour) демонструє приголомшливі зимові країни чудес у довгих відео, пропонуючи глядачам спокій і розслаблення.
Пориньте у світ штучного інтелекту - створіть з нуля тренажерний зал для навчання з глибоким підкріпленням. Отримайте практичний досвід і розробіть власний тренажерний зал, щоб навчити агента вирішувати прості завдання, закладаючи фундамент для більш складних середовищ і систем.

Mistral AI анонсує Mixtral 8x7B, мовну модель штучного інтелекту, яка відповідає GPT-3.5 від OpenAI за продуктивністю, що наближає нас до створення штучного асистента рівня ChatGPT-3.5, який може працювати локально. Моделі Mistral мають відкриті ваги та менше обмежень, ніж моделі OpenAI, Anthropic або Google.

У цій статті досліджується важливість класичних обчислень у контексті штучного інтелекту, підкреслюється їхня доведена правильність, сильне узагальнення та інтерпретованість порівняно з обмеженнями глибоких нейронних мереж. У ній стверджується, що розробка систем штучного інтелекту з цими класичними обчислювальними навичками має вирішальне значення для створення агентів із загальним інтелектом.
У статті обговорюється запуск ChatGPT і зростання популярності генеративного ШІ. Висвітлюється створення веб-інтерфейсу під назвою Chat Studio для взаємодії з фундаментальними моделями в Amazon SageMaker JumpStart, включаючи Llama 2 і Stable Diffusion. Це рішення дозволяє користувачам швидко випробувати розмовний ШІ та покращити користувацький досвід завдяки інтеграції з медіа.

Розвиток технологій перетворення тексту в зображення на основі штучного інтелекту призвів до появи великої кількості зображень низької якості, що викликало скептицизм і дезорієнтацію. Однак з'явилося нове явище - перетворення тексту в САПР за допомогою ШІ, в якому лідирують такі великі гравці, як Autodesk, Google, OpenAI та NVIDIA.