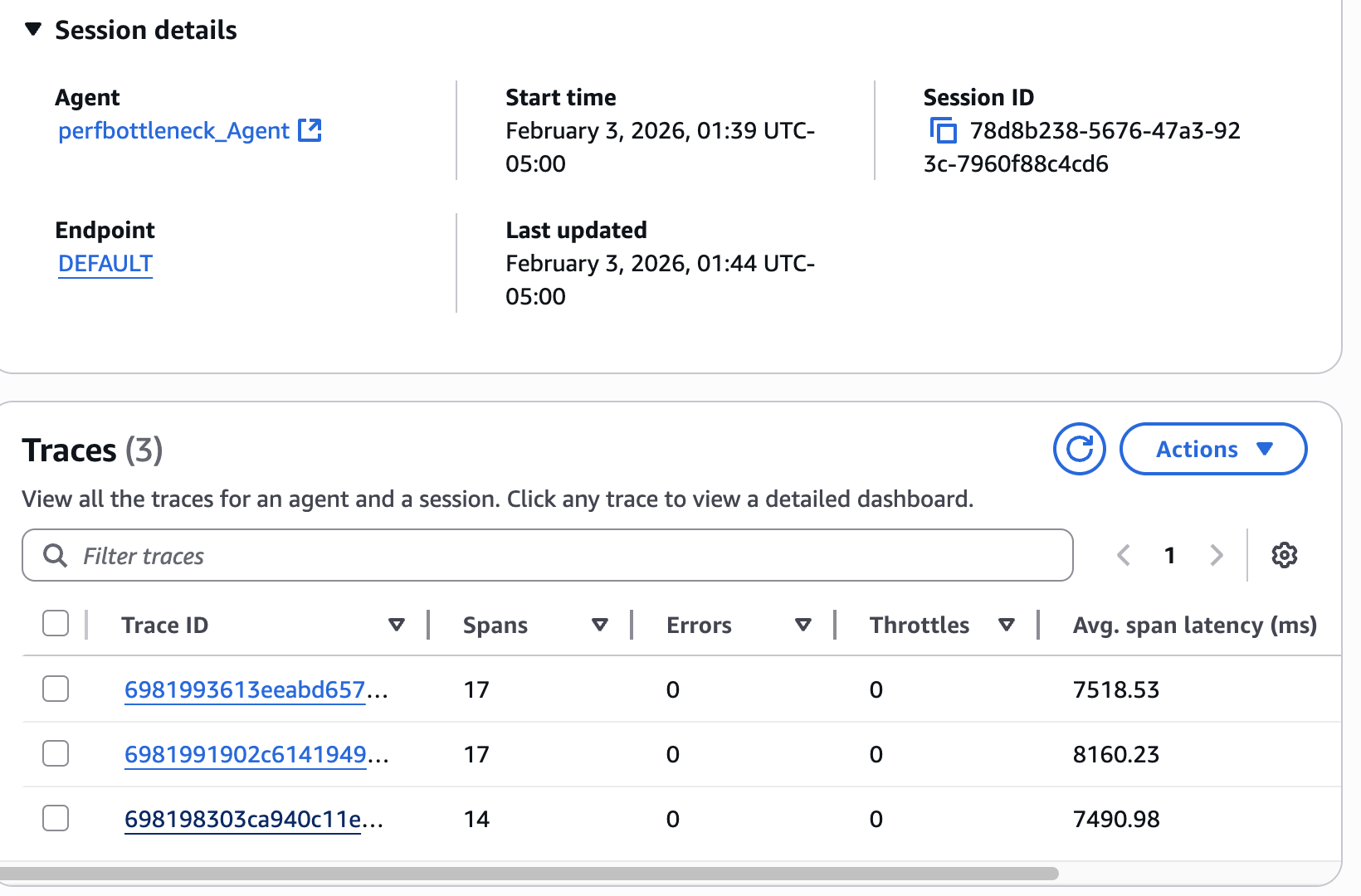
AI agents transitioning to production face challenges of slow performance and memory issues. Amazon Bedrock AgentCore and CloudWatch help diagnose bottlenecks and optimize agent architecture.

Organizations are integrating AI-powered analytics with natural language (Text2SQL) answers, emphasizing the importance of semantic richness flowing from data catalogs into AI products like Amazon Quick. The challenge lies in bridging the gap between rich metadata upstream and delivering curated, trustworthy AI answers and dashboards to end users.

GeForce NOW transforms everyday laptops into powerful gaming setups, allowing seamless switching between schoolwork and gaming. The addition of Halo: Campaign Evolved to the library offers an exciting gaming experience for members, showcasing the platform's versatility and convenience.

MIT's Daniela Rus wins 2026 High-Tech Prize for groundbreaking work in robotics and AI, focusing on self-organizing robot collectives and soft robotics. Her research at CSAIL is shaping the future of physical AI, with applications ranging from healthcare to infrastructure.

MIT students and postdocs advocate for federal research funding in Washington. They meet with 62 congressional offices to discuss science policy. Co-organized by Audrey Parker and Ian Robertson, the program helps scientists engage in policy advocacy.
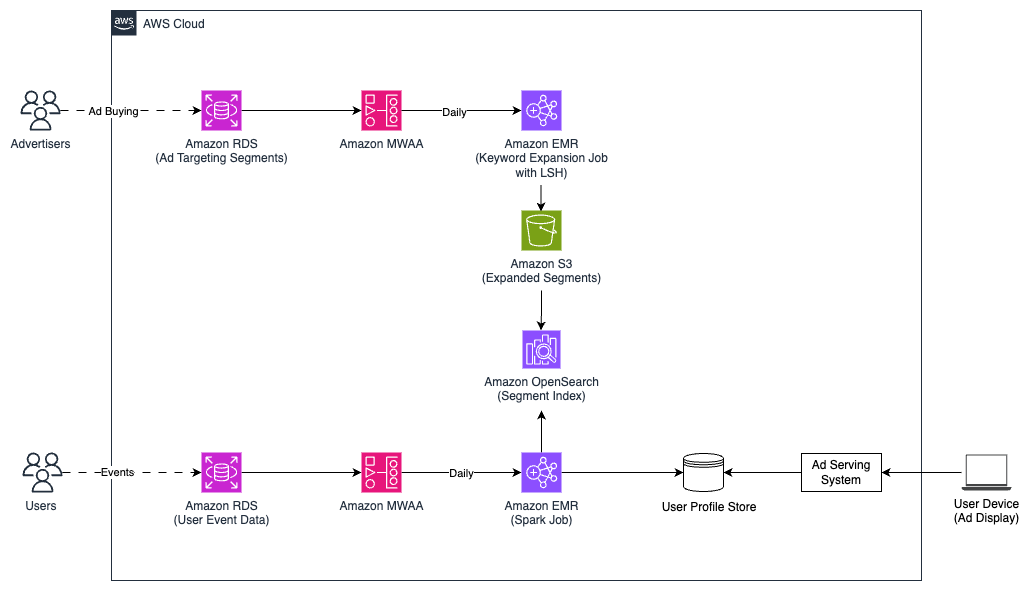
Yahoo's omnichannel Demand-Side Platform (DSP) tackles challenges in digital advertising with advanced technology and sophisticated audience targeting. By implementing Amazon Bedrock, Yahoo enhances Search Retargeting (SRT) capabilities, reaching users based on historical search behavior with generative AI-powered keyword expansion.

Amazon Bedrock introduces Advanced Prompt Optimization to streamline prompt migration and optimization for generative AI applications. The tool compares performance across multiple models, reducing manual effort and improving efficiency in the software development lifecycle.
Automating customer retention workflows in Amazon Quick reduces churn response time from days to minutes. A mid-size SaaS company lost 12% of at-risk accounts due to delayed customer contact. This post details building an automated retention pipeline in Amazon Quick, analyzing sentiment and prioritizing customers for tailored retention offers.

PhysioNet, founded in 1999, transformed medical research by pioneering global data-sharing of complex physiological signals. The platform now hosts hundreds of databases, cited in over 15,000 publications last year.
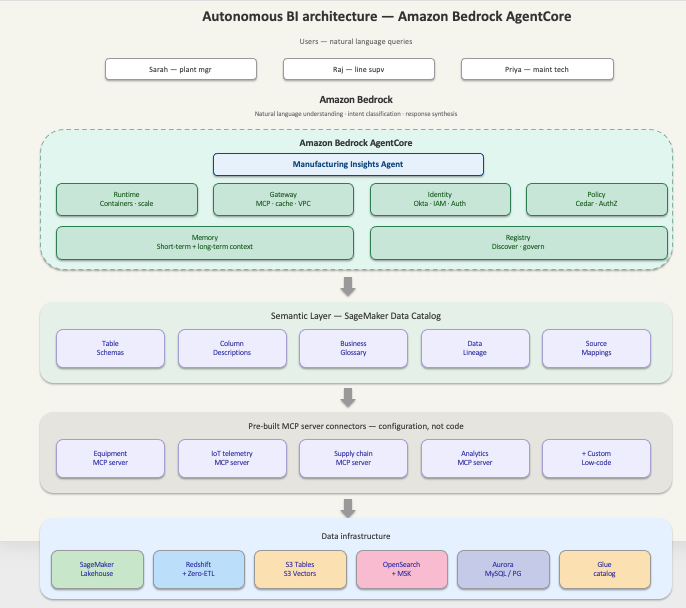
Sarah Chen faces a data integration nightmare managing assembly lines. Multiple systems hinder efficiency, causing delays and manual work.
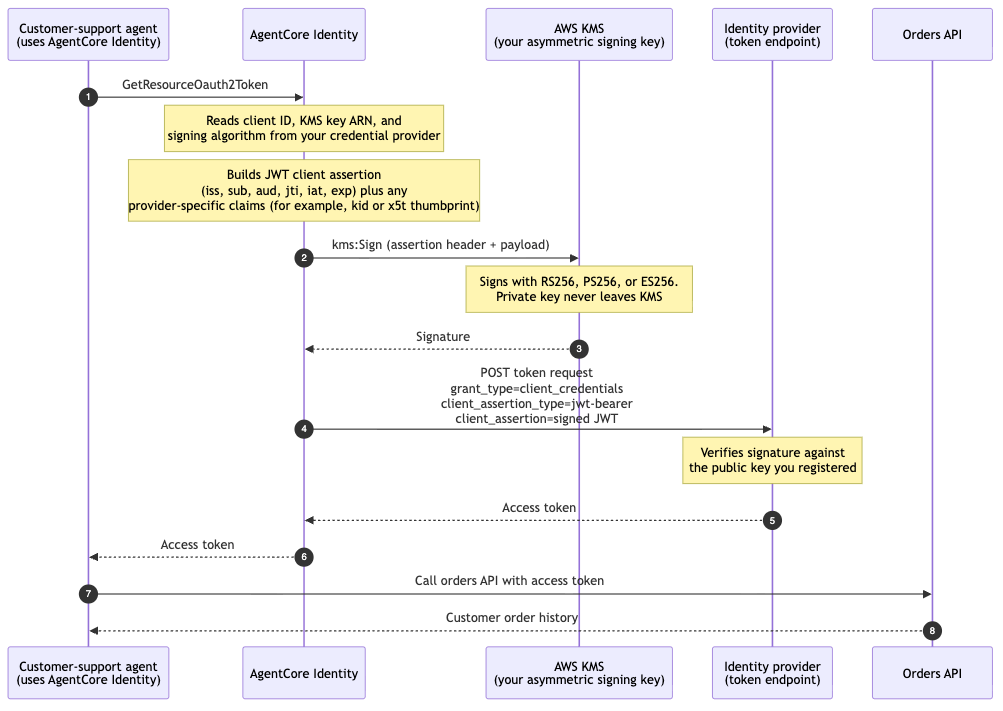
Amazon Bedrock AgentCore Identity now supports Private Key JWT client authentication for agents, enhancing security. Private keys stay in AWS KMS, ensuring secure authentication without sharing secrets.
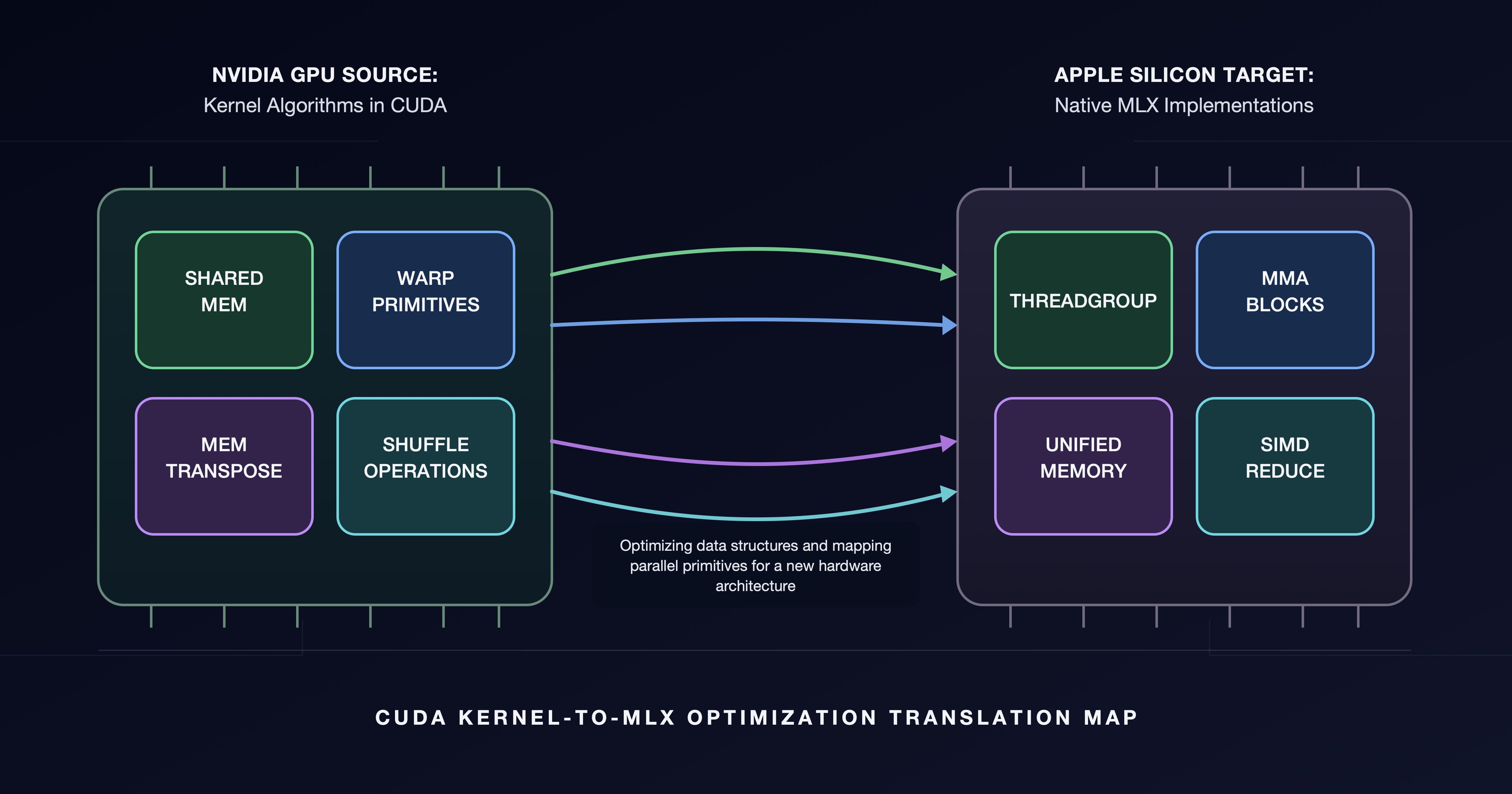
New CUDA-to-MLX translation boosts Apple Silicon GPU kernels. MLX framework fills performance gap for AI workloads, key for Apple's ML chips.

The Model Context Protocol (MCP) released a significant update, now stateless and scalable on HTTP infrastructure. The new version strengthens authorization, introduces a governed extensions system, and ensures backward compatibility for future updates.
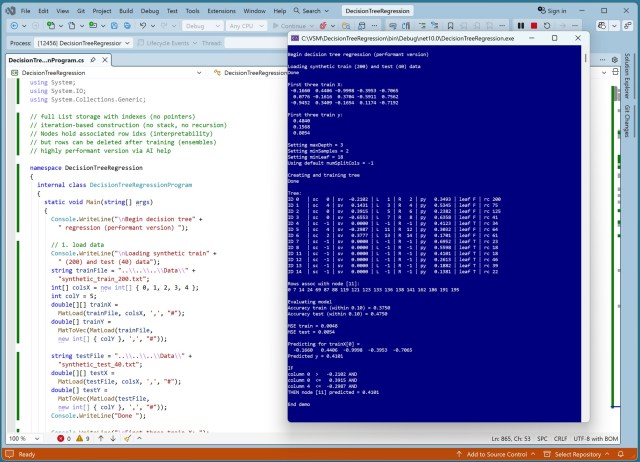
AI identified edge cases in decision tree regression code, improved performance, and increased training efficiency using a synthetic dataset. The revised demo showcased a performant version with enhanced accuracy and predictive capabilities.
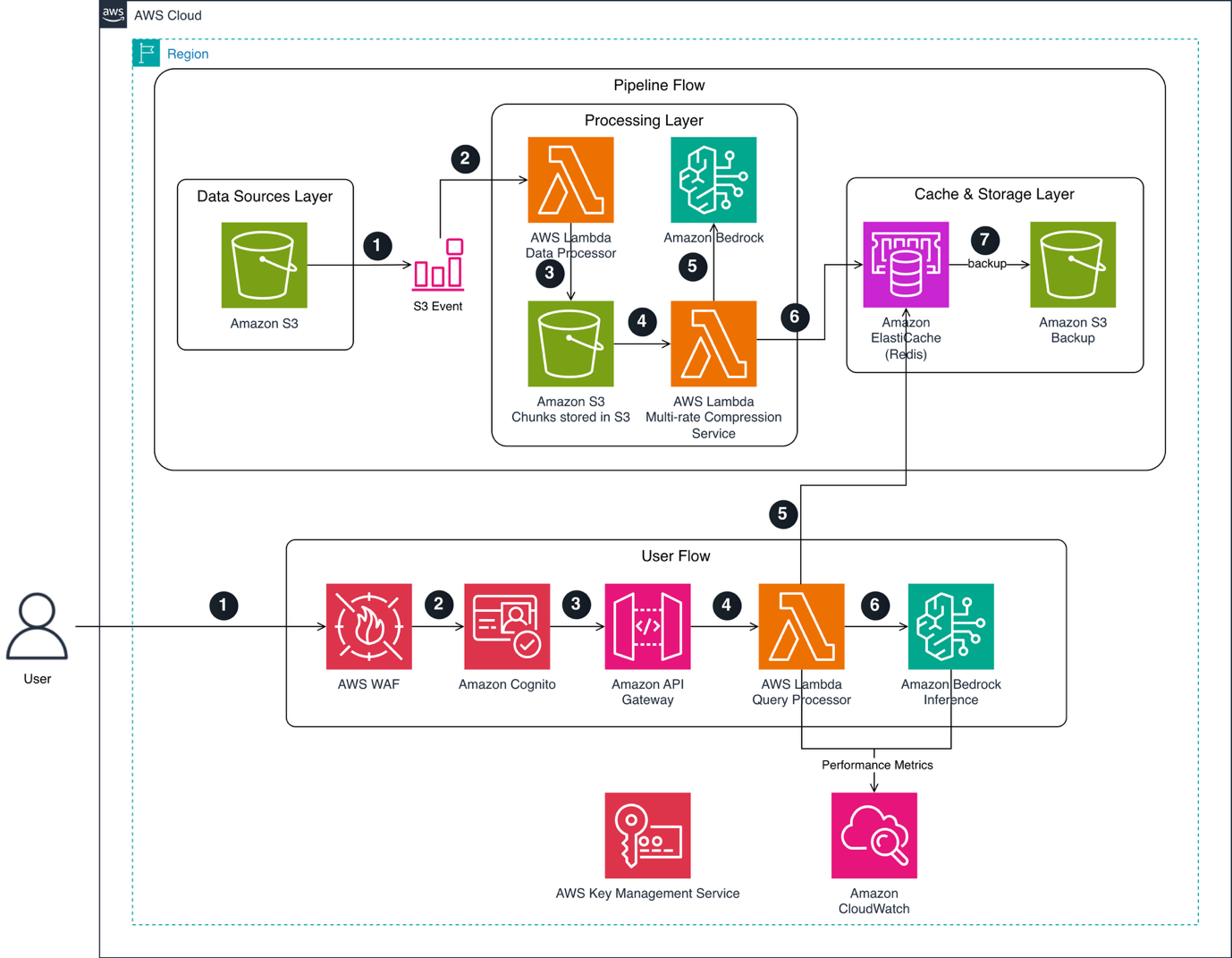
RAG hits a ceiling for complex tasks; TAKC pre-compresses knowledge bases for task-specific insights on AWS. TAKC provides detailed, task-focused document summaries for better analytical outcomes.