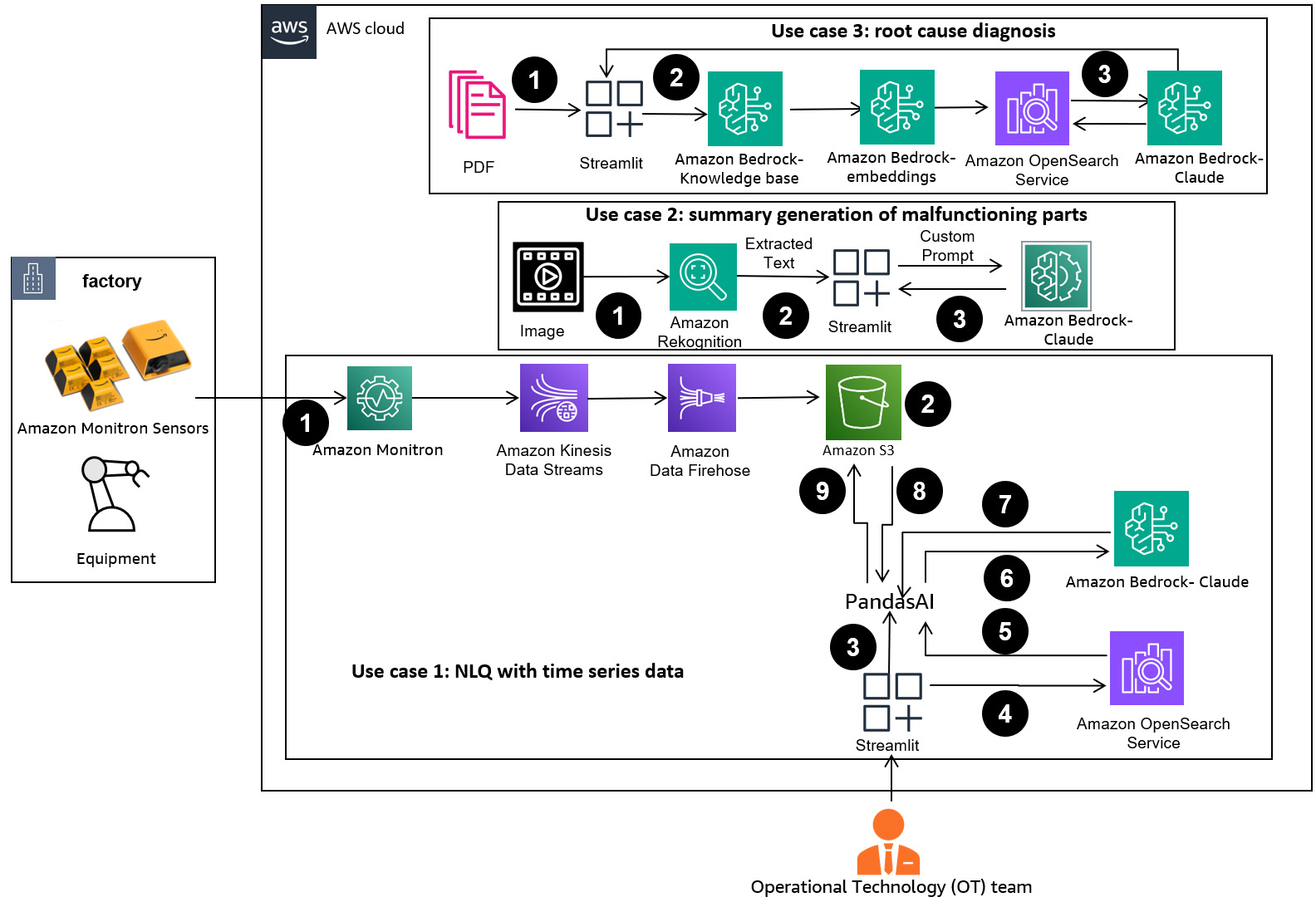
AI and ML revolutionize manufacturing, but challenges remain in handling vast unstructured data. Generative AI like Claude democratizes AI access for small manufacturers, enhancing productivity and decision-making. Multi-shot prompts improve code generation accuracy for complex NLQs, boosting FM capability in advanced data processing for industrial applications.

Google's rushed rollout of Gemini showcases the importance of thorough AI testing, as highlighted by Sergey Brin. The article delves into the unglamorous yet critical role of testing in AI product management, emphasizing the need for setting clear testing goals and avoiding issues like sexism and racism in image generation.
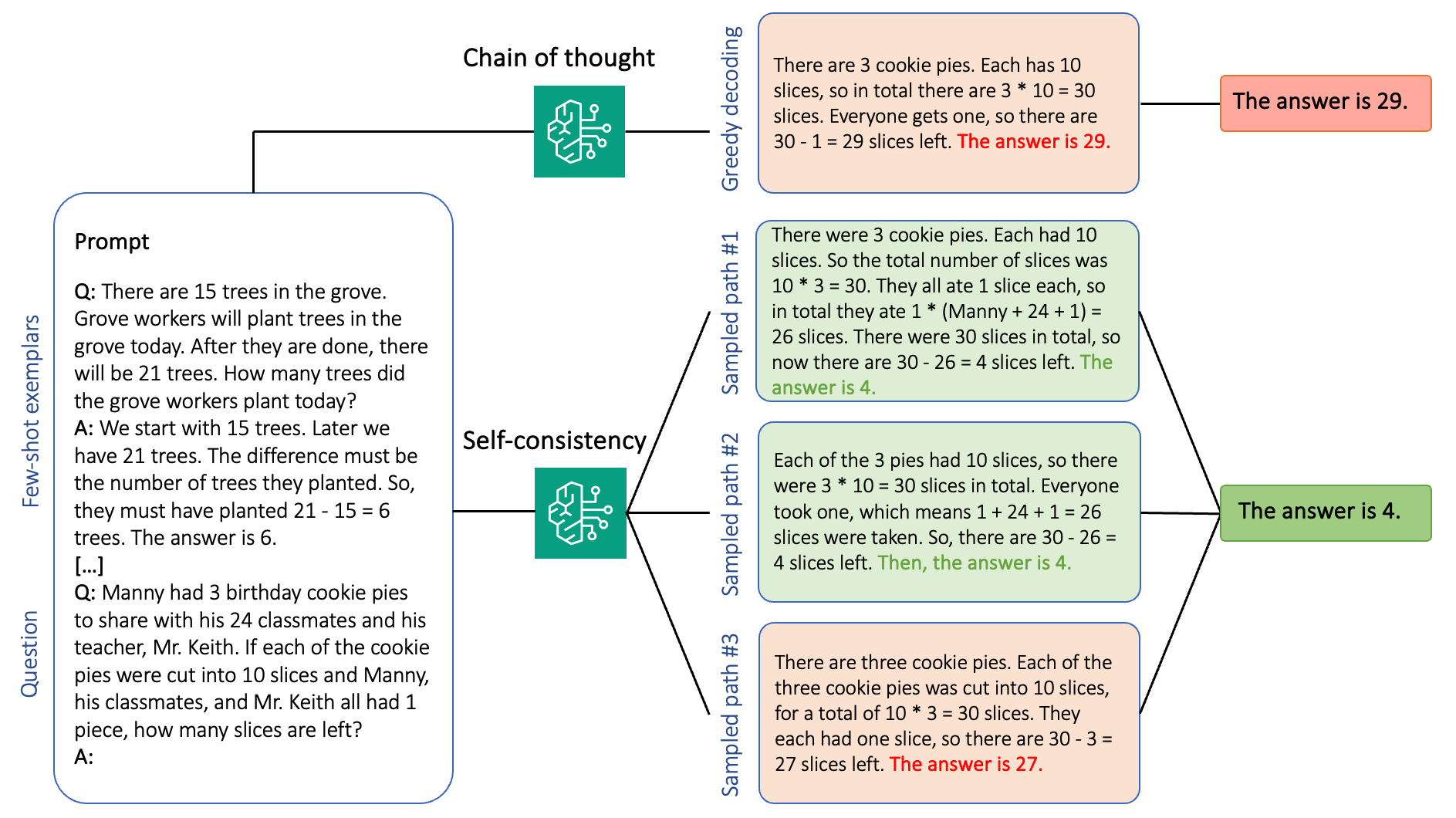
Generative language models excel in NLP tasks with prompt engineering. Amazon Bedrock offers high-performing models and batch inference for improved accuracy and efficiency in generative AI applications.

Labour thinktank proposes legal ban on nudification tools in AI development to combat deepfakes and 'cheapfakes'. Companies may face obligations to prevent harmful content production.

Nvidia unveils powerful Blackwell B200 chip, promising 25x cost reduction for AI inference. GB200 "superchip" combines two B200 chips for even more performance at GTC conference.

Discover how innovative startups are revolutionizing the tech industry with cutting-edge products. From AI-driven solutions to sustainable technologies, these companies are shaping the future.

Discover the groundbreaking collaboration between Tesla and SpaceX in developing sustainable energy solutions. Learn how their innovative technologies are revolutionizing the transportation and aerospace industries.

Discover the latest breakthrough in AI technology by leading companies like Google and IBM. Learn how these advancements are revolutionizing industries worldwide.

Discover the latest breakthrough in AI technology by Google, revolutionizing the way we interact with machines. Explore the potential impact on industries and daily life.

Discover how Company X revolutionized the tech industry with their groundbreaking product launch. Uncover the surprising results of their latest study on consumer behavior.

Discover how innovative startups are revolutionizing the tech industry with groundbreaking AI solutions. From autonomous vehicles to personalized medicine, these companies are reshaping the future.

Discover the latest groundbreaking research on AI technology by leading companies like Google and IBM. Learn about the potential impact on various industries and the future of artificial intelligence.

Discover the latest breakthrough in AI technology with the unveiling of Tesla's new self-driving car software. The revolutionary system promises to revolutionize the automotive industry.
New study reveals groundbreaking findings on the potential benefits of AI in healthcare. Companies like IBM and Google are leading the charge in developing innovative solutions for patient care.

Discover how tech giants like Apple and Google are revolutionizing the healthcare industry with cutting-edge wearables and health tracking apps. Learn about the latest advancements in remote patient monitoring and personalized healthcare solutions.