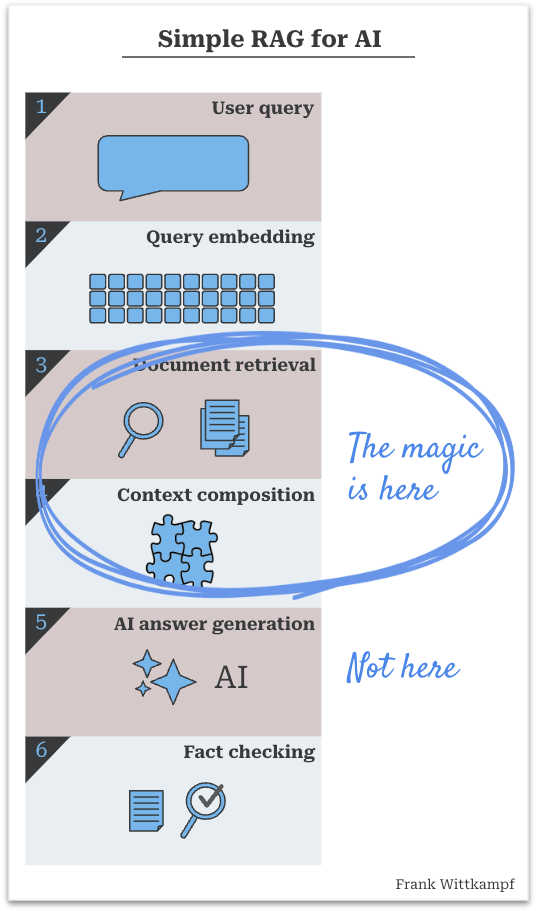
RAG systems rely on retrieval over generation for magical AI interactions. The key lies in providing AI with pre-processed answers for accurate responses.

Mathematics in modern machine learning is evolving. Shift towards scale broadens scope of applicable mathematical fields, impacting design choices.

MIT students Yiming Chen ’24 and Wilhem Hector named 2025 Rhodes Scholars for pioneering work in AI safety and becoming first Haitian citizen to receive the prestigious scholarship. Supported by MIT faculty and committees, they will pursue postgraduate studies at Oxford University.
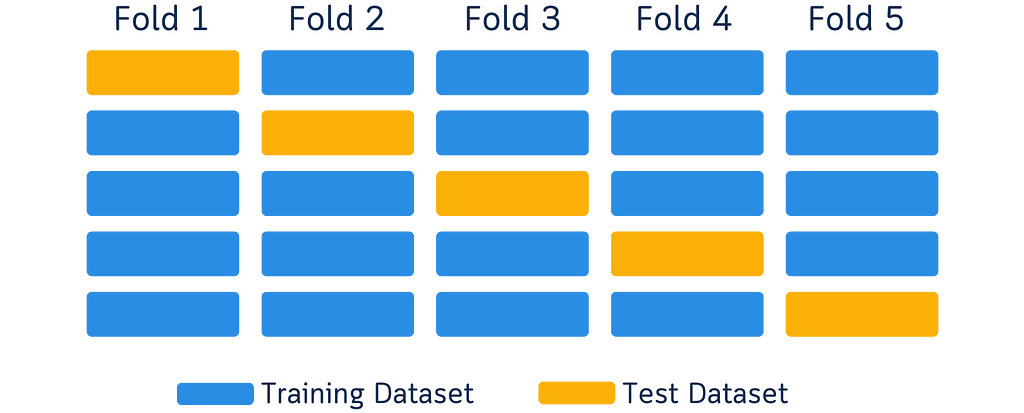
Current cross-validation diagrams using moving boxes can be misleading. A new approach is needed to better explain the concept.
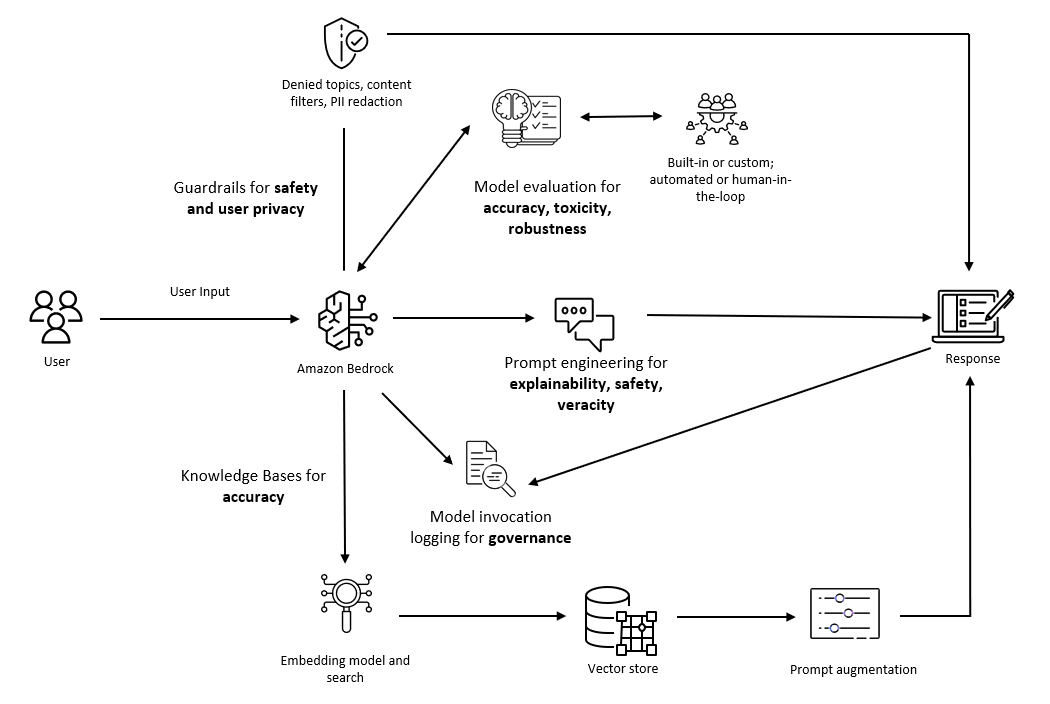
Generative AI advances offer transformative innovation but pose challenges. AWS emphasizes responsible AI development, focusing on dimensions like fairness and safety, with tools like Amazon Bedrock Guardrails to ensure secure and reliable AI applications.
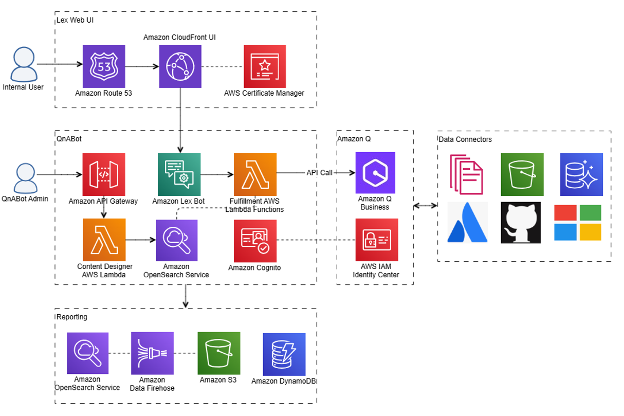
Principal leveraged QnABot on AWS to create an intelligent chatbot for real-time role-based answers, improving enterprise data access and productivity. By integrating with Amazon Q Business and Amazon Bedrock, Principal developed a secure internal chatbot for faster information retrieval, enhancing employee efficiency and creativity.

Companies are scraping personal data to train AI systems without consent. The tech industry is hungry for data to power advanced AI technologies.
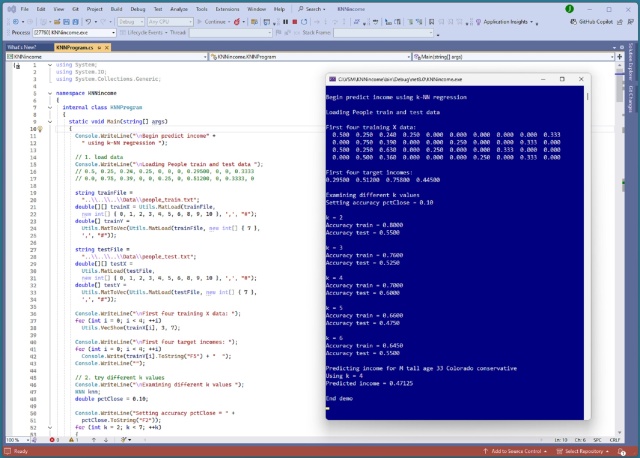
Implementing k-NN regression in C# for predicting income from demographic data. Encoding, normalizing, and testing accuracy with different k values.

At Web Summit, Digit by Agility Robotics showcased AI advancements by sorting laundry with Google's Gemini AI model. Raised concerns about jobs, safety, and climate impact.

Elon Musk accuses Microsoft and OpenAI of monopolizing AI market in lawsuit expansion. Allegations filed in federal court.

AI like ChatGPT is not just a toy, but an inflection point in human history, set to transform all aspects of our lives. While algorithms can create, they lack the human struggle and emotion that make true creativity unique.

MIT Energy Initiative director William H. Green emphasizes the urgent need for decarbonization amid global challenges. Conference highlights consensus-building, social barriers, and the critical role of universities in resolving conflicts for a durable energy transition.

GeForce NOW introduces Farming Simulator 25 with new rice farming features and Asian-themed map. Members also get special rewards for Throne and Liberty game, enhancing their gaming experience.
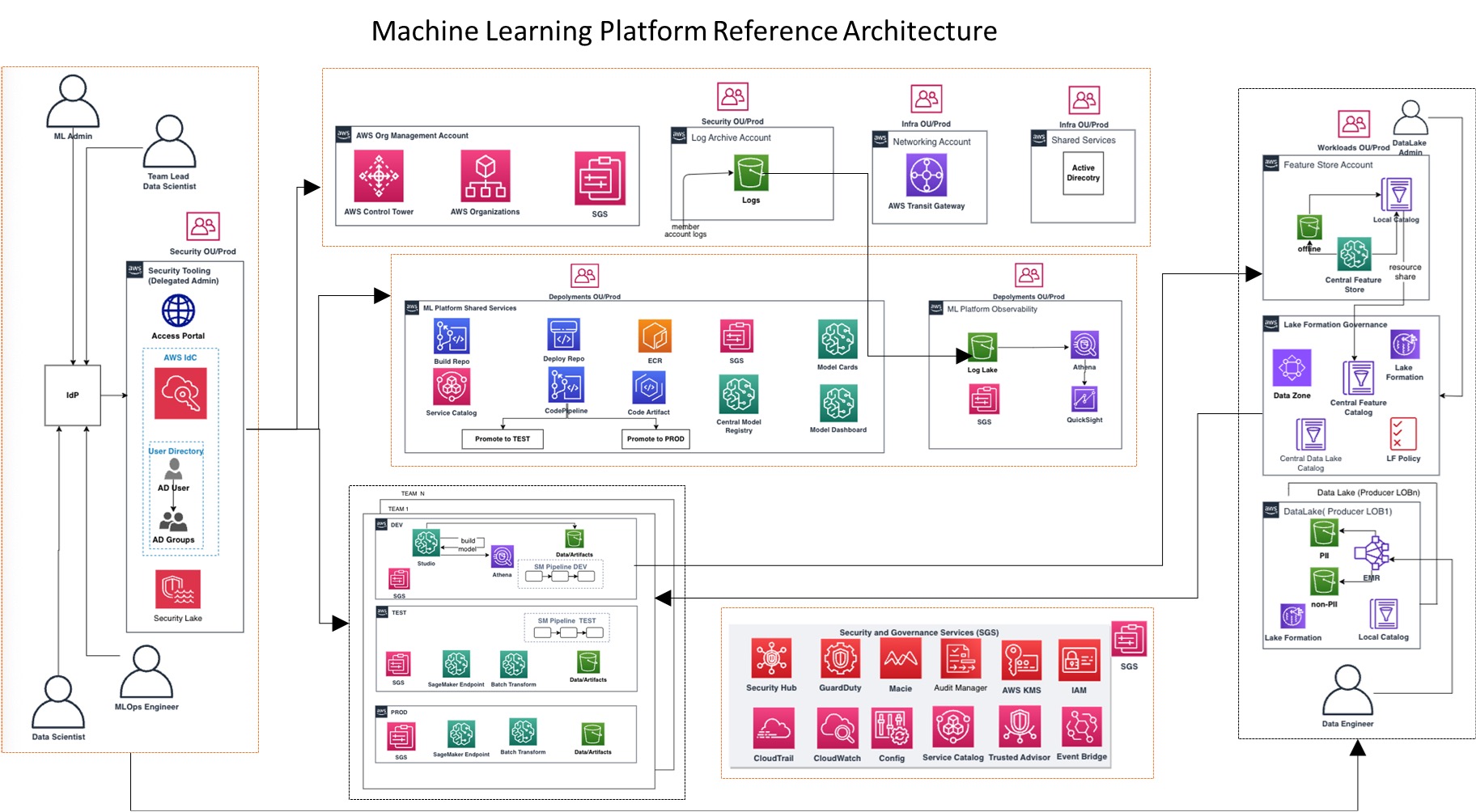
Cloud costs impact business operations. Real-time visibility and tagging strategy essential for cost-effective cloud utilization and optimization.
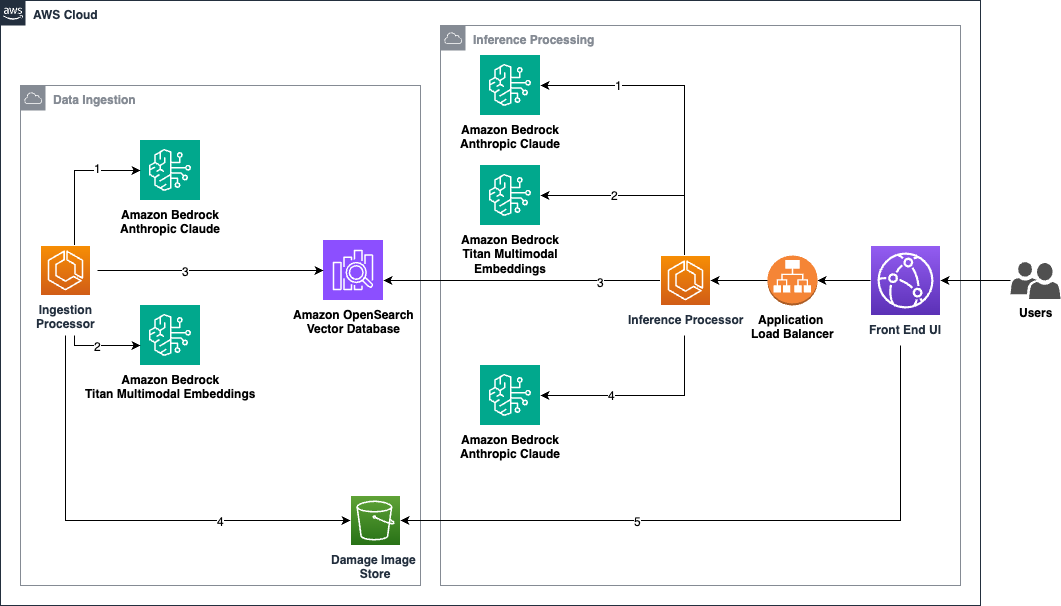
A solution using AWS generative AI like Amazon Bedrock and OpenSearch simplifies vehicle damage appraisals for insurers, repair shops, and fleet managers. By converting image and metadata to numerical vectors, this approach streamlines the process and provides valuable insights for informed decision-making in the automotive industry.