
Організації інтегрують аналітику на основі штучного інтелекту з відповідями, що генеруються природною мовою (Text2SQL), підкреслюючи важливість семантичної інформації, яка передається з каталогів даних у продукти штучного інтелекту, такі як Amazon Quick. Проблема полягає в тому, щоб подолати розрив між великою кількістю метаданих на початковому етапі та забезпеченням користувачам надійні та пер...
Штучні інтелекти, що переходять до виробничого середовища, стикаються з новими викликами щодо швидкості та ефективності. Дізнайтеся, як Amazon Bedrock AgentCore допомагає виявляти та усувати вузькі місця продуктивності та проблеми з пам'яттю в процесах, що працюють тривалий час.

Студенти та постдокторанти Массачусетського технологічного інституту виступають за федеральне фінансування наукових досліджень у Вашингтоні. Вони зустрічаються з представниками 62 конгресменів, щоб обговорити питання наукової політики. Програма, яку спільно організували Одрі Паркер та Іен Робертсон, допомагає вченим брати участь у просуванні політичних ініціатив.

Даніела Рус з Массачусетського технологічного інституту отримала премію High-Tech Prize 2026 за новаторську роботу в галузі робототехніки та штучного інтелекту, зосереджену на самоорганізованих робототехнічних системах і м'якій робототехніці. Її дослідження в CSAIL визначають майбутнє фізичного ШІ, охоплюючи широкий спектр застосувань, від охорони здоров'я до інфраструктури.
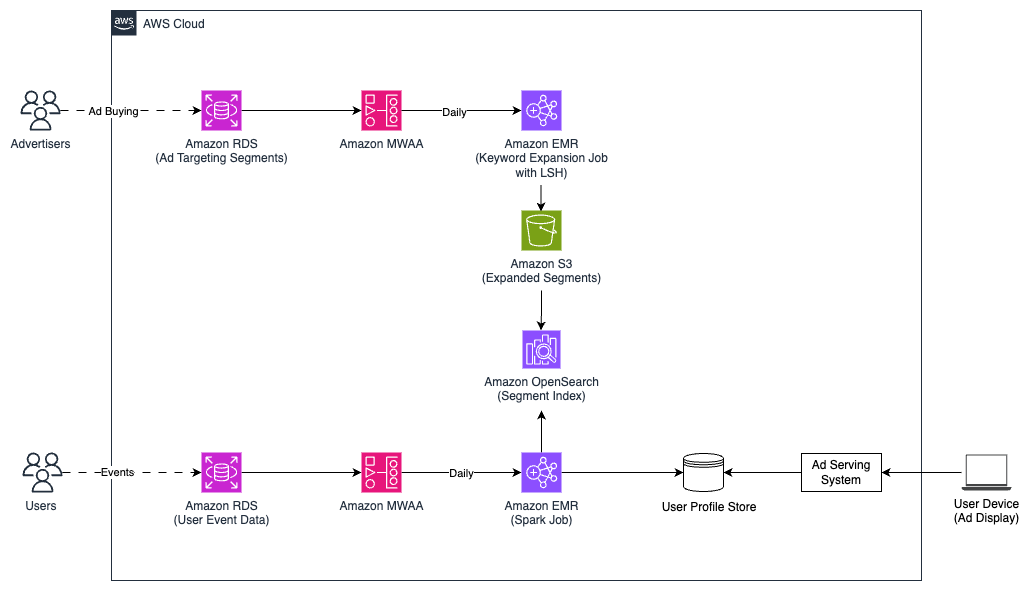
Платформа управління рекламними кампаніями (Demand-Side Platform, DSP) компанії Yahoo, що працює за принципом омніканальності, вирішує проблеми цифрової реклами завдяки передовій технології та складній системі таргетингу аудиторії. Завдяки впровадженню Amazon Bedrock, Yahoo покращує можливості ретаргетингу на основі пошуку (Search Retargeting, SRT), дозволяючи охоплювати користувачів, виходячи ...

Сервіс GeForce NOW перетворює звичайні ноутбуки на потужні ігрові системи, дозволяючи легко перемикатися між навчанням та іграми. Додавання гри Halo: Campaign Evolved до бібліотеки пропозицій сервісу відкриває захопливий ігровий досвід для користувачів, демонструючи універсальність та зручність цієї платформи.

Amazon Bedrock представляє функцію Advanced Prompt Optimization, яка спрощує процес перенесення та оптимізації промптів для застосунків генеративного штучного інтелекту. Цей інструмент автоматизує рутинні завдання, порівнює продуктивність різних моделей і усуває вузькі місця в життєвому циклі розробки програмного забезпечення.
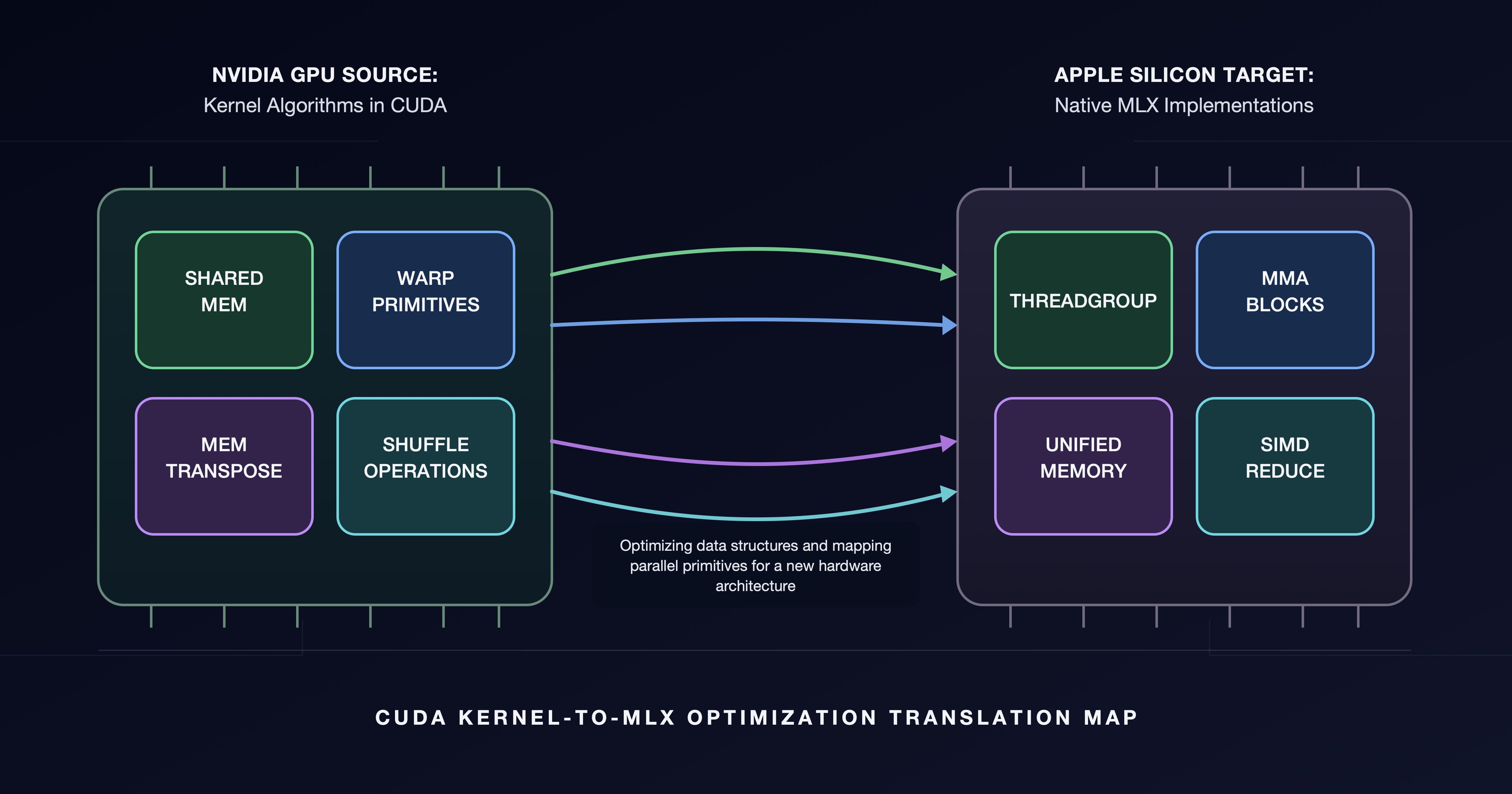
Нова оптимізація перекладу з CUDA на MLX підвищує продуктивність MLX на процесорах Apple Silicon, заповнюючи прогалини в критичних ядрах графічного процесора. Фреймворк MLX трансформує процес виведення результатів у системах штучного інтелекту на пристроях Apple, покращуючи продуктивність для моделей середнього розміру.
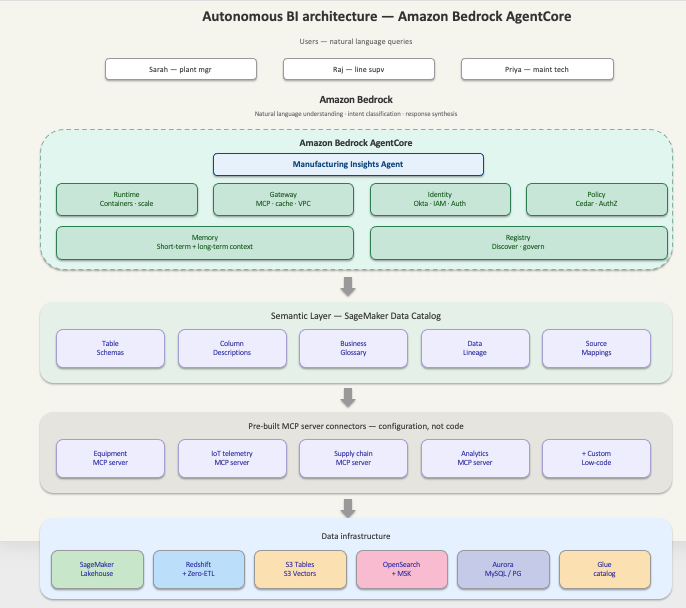
Сара Чен стикається з серйозними проблемами інтеграції даних при управлінні виробничими лініями. Різноманітні системи знижують ефективність, спричиняючи затримки та потребуючи ручної праці.
Автоматизація утримання клієнтів в Amazon Quick дозволяє скоротити час відповіді з днів до хвилин. Ця система аналізує настрої клієнтів, визначає пріоритетність утримання та ефективно генерує персоналізовані пропозиції.

PhysioNet, заснована у 1999 році, змінила підхід до медичних досліджень, запровадивши глобальний обмін складними фізіологічними даними. Наразі платформа містить сотні баз даних, які були згадані в понад 15 000 публікацій минулого року.
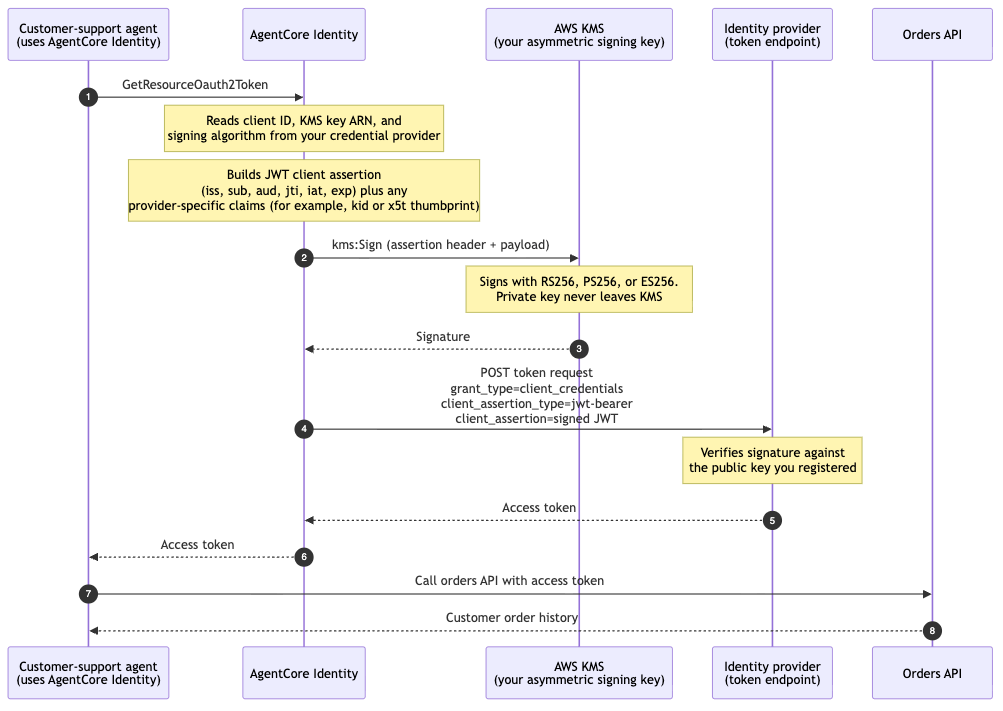
Функція Amazon Bedrock AgentCore Identity тепер підтримує аутентифікацію клієнтів за допомогою приватного ключа JWT для агентів, що підвищує рівень безпеки. Приватні ключі зберігаються в сервісі AWS KMS, забезпечуючи надійну автентифікацію без необхідності обміну секретними даними.
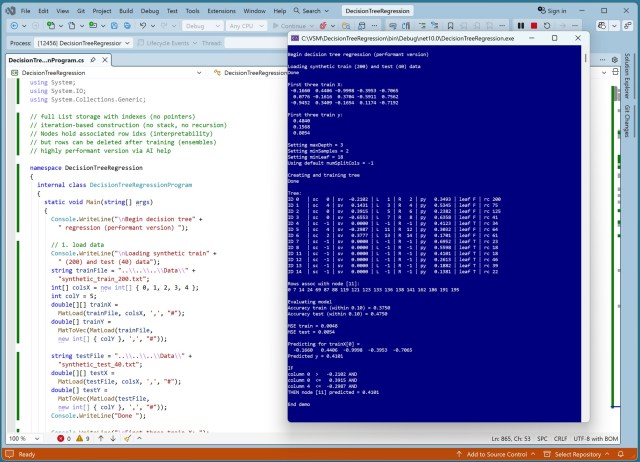
Штучний інтелект виявив нетипові випадки в коді регресії на основі дерев рішень, покращив продуктивність і підвищив ефективність навчання за допомогою синтетичного набору даних. Оновлена демонстрація показала версію з високою продуктивністю, покращеною точністю та можливостями прогнозування.

Протокол контексту моделі (Model Context Protocol, MCP) отримав велике оновлення, перейшовши до протоколу без стану, який масштабується на звичайній HTTP-інфраструктурі. Нова версія включає покращення в управлінні, посилює авторизацію та пропонує гарантії щодо життєвого циклу, не порушуючи роботу існуючих клієнтів.
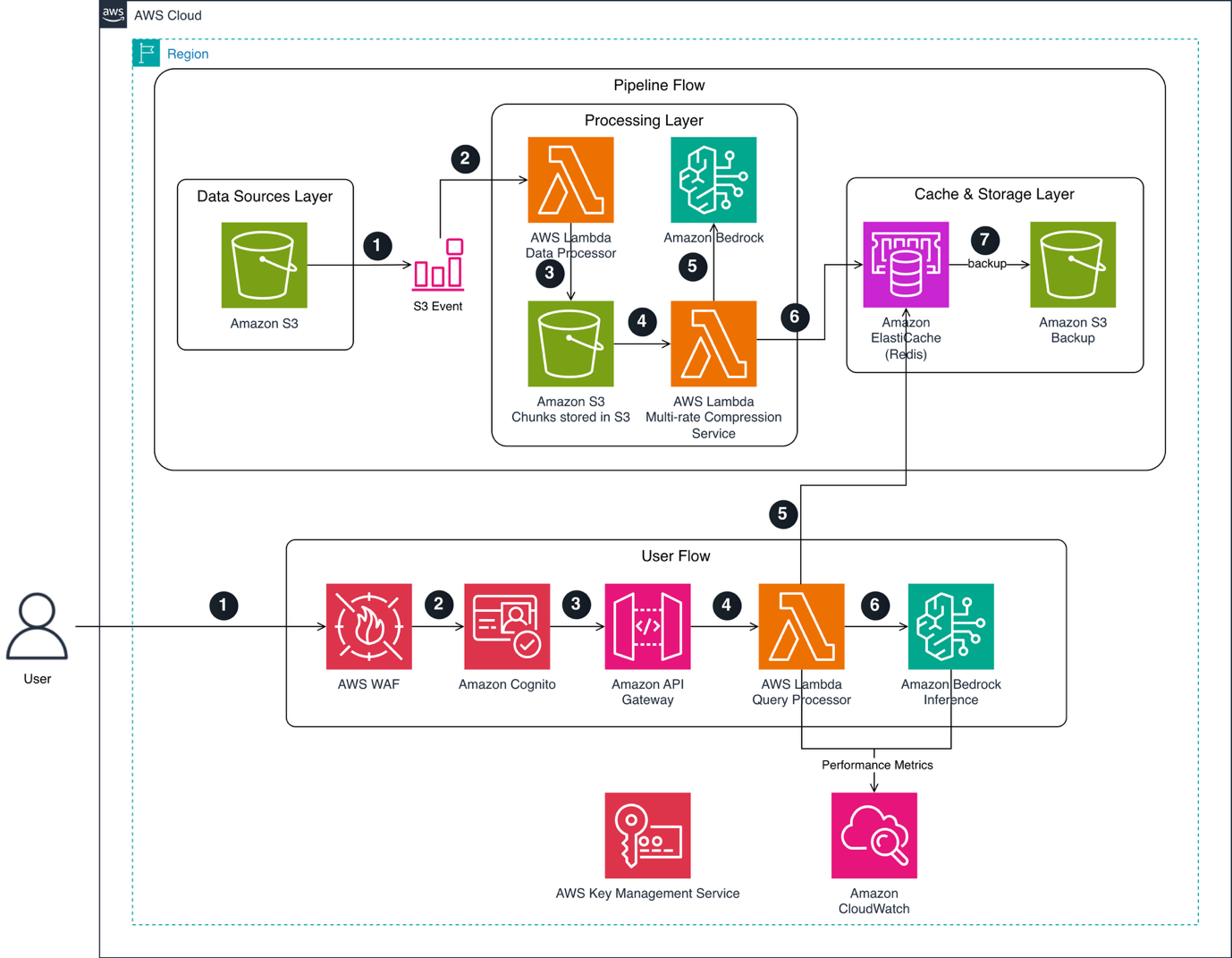
Система RAG досягає межі своїх можливостей при виконанні складних завдань. TAKC попередньо стискає бази знань для отримання специфічних відомостей, що стосуються конкретних задач, на платформі AWS. TAKC надає детальні резюме документів, орієнтовані на конкретні завдання, для досягнення кращих результатів аналізу.