
Трамп погрожує ввести 100% мита на китайські товари після введення Пекіном обмежень на експорт рідкісних земель на тлі зростаючих побоювань щодо бульбашки штучного інтелекту. Попередження глави МВФ Георгієвої про те, що «невизначеність є новою нормою», швидко підтверджується, оскільки ринки реагують на ескалацію торговельних напружень.

Користувачі додатку для знайомств Hinge, будьте обережні: комп'ютерно-генерований шарм набирає популярності, створюючи фальшиві особистості. Власниця бізнесу Рейчел закохалася в глибокі розмови зі своїм партнером, ставлячи під сумнів стилі прихильності.

Штучний інтелект проникає в смартфони, обслуговування клієнтів, охорону здоров'я та судові справи. Уникайте ШІ, використовуючи лайливі слова в пошуку Google або вимикаючи ШІ в певних додатках. Ігноруйте ChatGPT, фейкові відео з Дональдом Трампом та акторку-штучний інтелект Тіллі, щоб триматися подалі від програмного забезпечення на базі ШІ.

Недавнє дослідження, проведене компаніями Apple і Tesla, показує революційні досягнення в області технологій виробництва екологічних акумуляторів, що обіцяють більш довговічні та екологічні продукти. Співпраця двох гігантів індустрії демонструє потенціал більш екологічного майбутнього в галузі побутової електроніки.

Художниця-карикатуристка Фіона Катаускас викликає дискусії своїми ілюстраціями, що спонукають до роздумів. Ознайомтеся з її роботами, щоб побачити різні точки зору.

Генератор відео на базі штучного інтелекту Sora 2, розроблений Семом Альтманом, звинувачують у плагіаті. Марина Гайд критикує керівника OpenAI за відсутність турботи про згоду суб'єктів.

Рей Курцвейл прогнозує, що інтеграція штучного інтелекту та людини революціонізує медицину та довголіття. MIT вшановує Курцвейла за його новаторський внесок у розвиток технологій та інновацій.

Лінійна регресія з двосторонніми взаємодіями в JavaScript підвищує точність і інтерпретованість, пропонуючи більш складне рішення для обробки даних. Демонстраційна програма демонструє поліпшену якість моделі та легкість інтерпретації ваг, що робить її цінним інструментом для дослідження.

Штучний інтелект становить загрозу для демократії, особливо з огляду на його довгостроковий вплив. Незважаючи на нещодавній досвід, занепокоєння щодо впливу контенту, створеного штучним інтелектом, на вибори залишається актуальним.
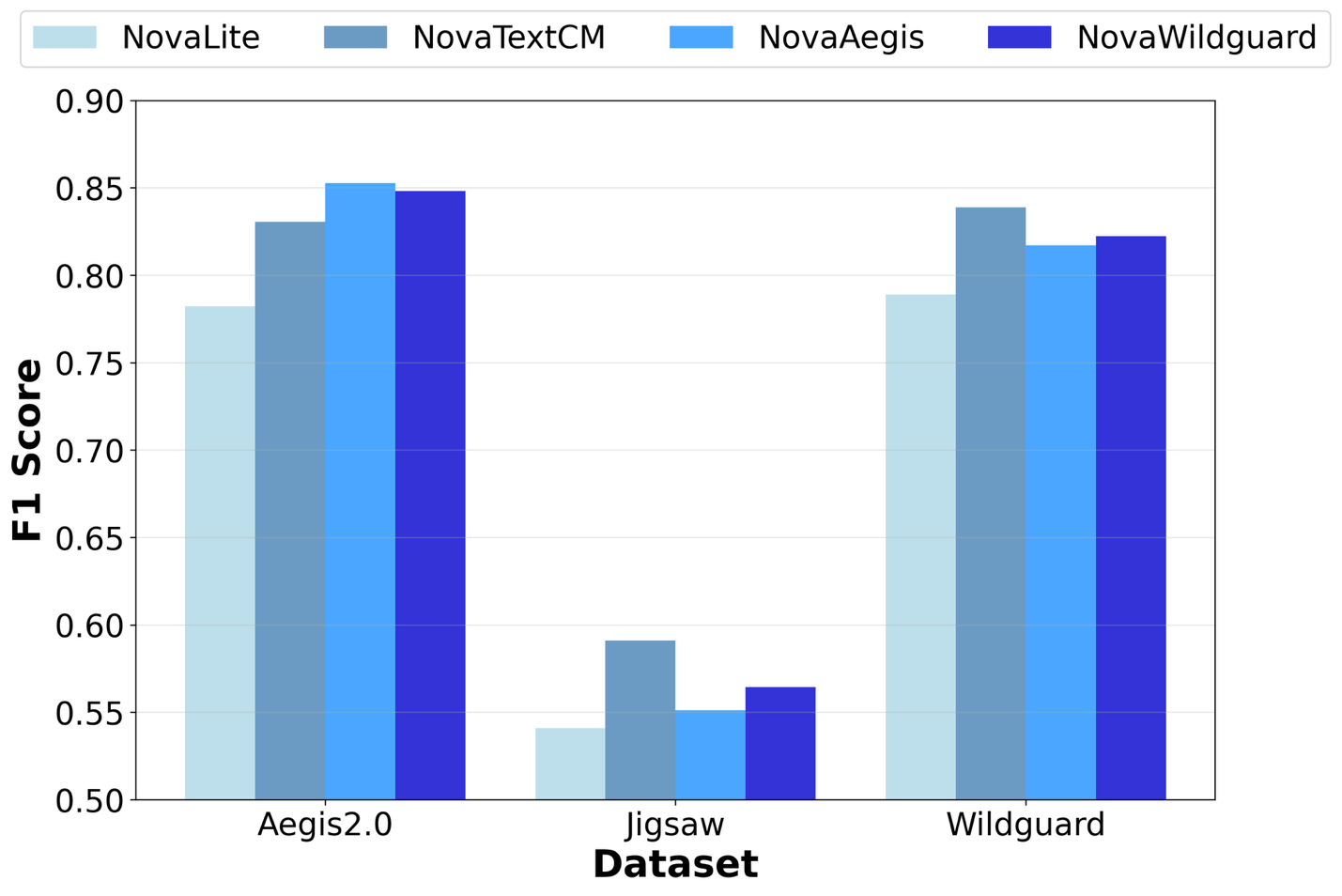
Соціальні медіа-платформи стикаються з проблемами модерації контенту за допомогою систем, що базуються на правилах та штучному інтелекті, що призводить до скарг користувачів та занепокоєння рекламодавців. Налаштування Amazon Nova на Amazon SageMaker AI забезпечує підвищену точність та відповідність політикам для завдань модерації контенту, досягаючи покращення F1-показників на 9,2%.

Battlefield 6 з потужністю GeForce RTX 5080 дебютує в хмарі, а також інтегрується з Discord для зручного пошуку ігор. NVIDIA та Discord об'єднуються для забезпечення безперебійного ігрового досвіду, починаючи з інтеграції Fortnite.

Ріші Сунак призначений старшим радником американських технологічних гігантів Microsoft і Anthropic, крім того, він обіймає посади в Goldman Sachs та інвестиційних компаніях. Згідно з інформацією наглядового органу за роботою колишніх міністрів, нові посади колишнього прем'єр-міністра Великої Британії не передбачають лобіювання чи впливу на політику Великої Британії.

Технології змінюють процес створення музики, піднімаючи питання про вплив штучного інтелекту на творчість. Відвідайте розкішні маєтки хакерів у Кремнієвій долині, де проживають засновники технологічних компаній та футурологи.
NVIDIA Blackwell домінує в тестах InferenceMAX v1 завдяки неперевершеній економічності штучного інтелекту, забезпечуючи 15-кратний прибуток на інвестиції. NVIDIA B200 досягає найнижчої вартості за токен, забезпечуючи 5-кратну економію всього за 2 місяці, встановлюючи нові стандарти ефективності штучного інтелекту.

Дослідження Британського інституту стандартів: 25% керівників розглядають можливість автоматизації завдань початкового рівня для скорочення витрат, що призведе до «апокаліпсису робочих місць» для молодих працівників, оскільки штучний інтелект стає пріоритетним порівняно з новими співробітниками. Бізнес-лідери обирають автоматизацію на основі штучного інтелекту для усунення дефіциту кваліфікова...