
Себастьян Рашка, піонер в галузі навчання ШІ, ділиться 13 ключовими уроками для освоєння машинного навчання: починайте з простого, приймайте зміни та відповідально використовуйте великі мовні моделі. Його поради наголошують на терпінні, інтуїції та зосередженості, щоб побудувати міцний фундамент у цій галузі, яка стрімко розвивається.
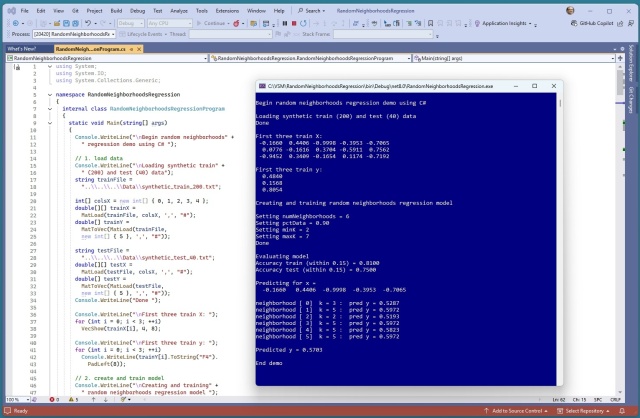
Ідея алгоритму регресії випадкових сусідів створює ансамбль регресорів k-найближчих сусідів для вирішення проблем перенастроювання та спроб і помилок у базовій регресії k-найближчих сусідів. Успішна демонстрація з використанням C# продемонструвала підвищення точності прогнозування за допомогою віртуальних колекцій регресорів.
NALA, заснована 22-річним Беньяміном Гулаком, змінює світ мистецтва, з'єднуючи художників безпосередньо з покупцями через цифрову платформу. Компанія прагне зруйнувати традиційні галерейні бар'єри, пропонуючи більший пул творів мистецтва та персоналізовані рекомендації.

Навчіться створювати LLM на курсі LLM Scientist and Engineer, що охоплює архітектуру, токенізацію, механізми уваги та методи вибірки. Моделі для попереднього навчання потребують великих наборів даних і ретельної курації для оптимальної продуктивності.

Маніш Рагхаван з Массачусетського технологічного інституту має на меті вдосконалити ШІ для суспільного блага, вирішуючи проблеми упередженості при прийомі на роботу та вдосконалюючи алгоритми прийняття рішень у медицині. Дослідження Рагхавана, зосереджені на соціальному впливі, спрямовані на вирішення давніх проблем за допомогою алгоритмічного прийняття рішень та ШІ.

Кейр Стармер прогнозує трансформацію економіки Великої Британії завдяки штучному інтелекту та заперечує плани щодо заміни голови Казначейства. Тиск на економіку зростає, оскільки зростання зупиняється, фунт знецінюється, а вартість боргу зростає.
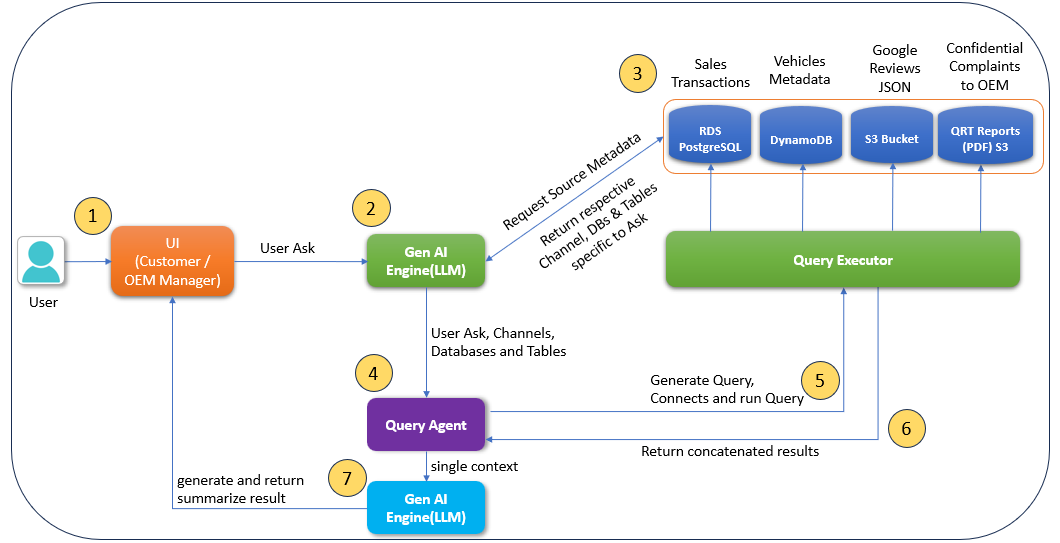
AutoWise Companion від HCLTech використовує штучний інтелект, щоб спростити рішення про купівлю автомобіля для клієнтів і покращити аналіз даних для виробників. Рішення витягує інформацію з різних джерел даних, надаючи персоналізовані рекомендації та підвищуючи рівень задоволеності клієнтів.

Несподіваними науковими новинами 2024 року стали віспа в ДРК, ШІ на Нобелівських преміях та астронавти, що застрягли на мілині. Що принесе 2025 рік? Ієн Семпл та Ганна Девлін прогнозують майбутні великі історії.
Глобальна магістральна мережа AWS забезпечує надійне надання послуг у 34 регіонах, 600 точках доступу CloudFront тощо. AWS використовує GML фреймворк GraphStorm для прогнозування та пом'якшення ризиків перевантаження мережі, вирішуючи складні завдання управління мережею.
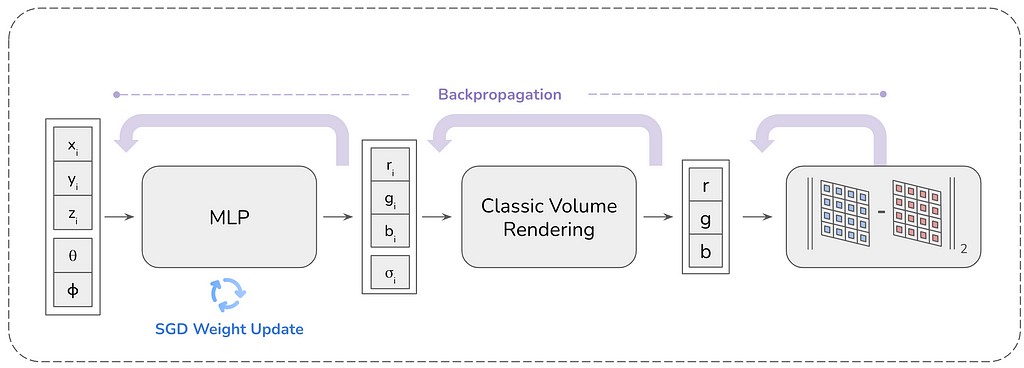
NeRF - це передовий метод рендерингу 2D-зображень з 3D-сцен, що використовує надбудований MLP для стиснення інформації про сцену. Це значно зменшує вимоги до пам'яті і дозволяє генерувати зображення з будь-якого напрямку перегляду.
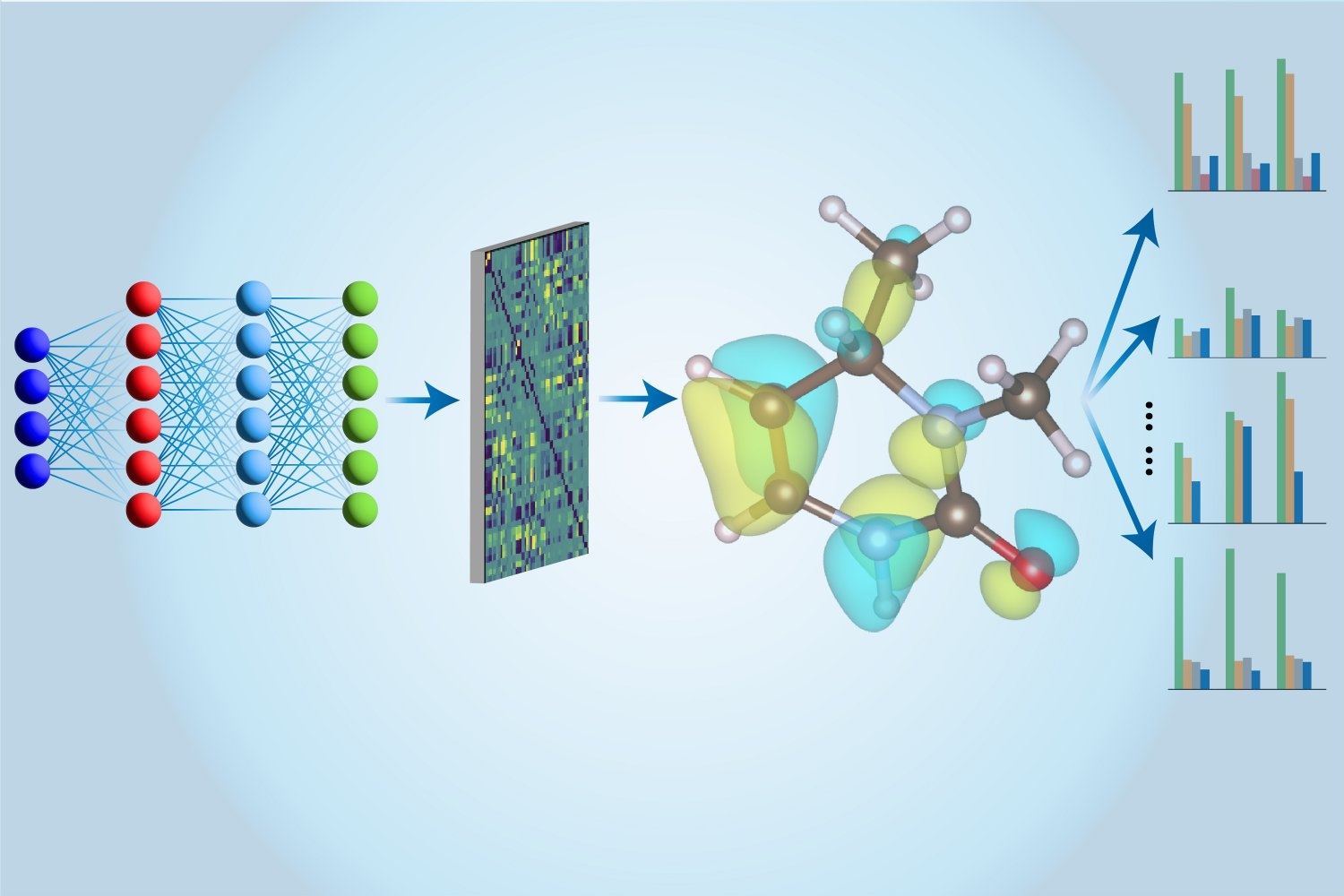
Дизайн матеріалів пройшов шлях від алхімії до машинного навчання. Дослідження під керівництвом Джу Лі представляє новий метод, що використовує теорію зв'язаних кластерів для підвищення точності та швидкості проектування матеріалів.

Кейр Стармер планує збільшити обчислювальну потужність ШІ в 20 разів до 2030 року. Але чи не суперечитимуть енергоємні дата-центри цілям Великобританії щодо чистої енергії?
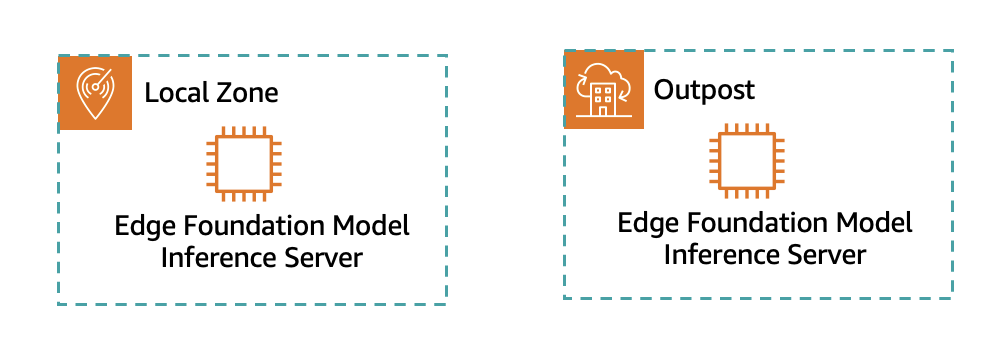
Агенти Amazon Bedrock Agents уможливлюють швидку розробку генеративних програм штучного інтелекту для корпоративних систем. Гібридні та периферійні сервіси, такі як AWS Outposts, покращують результати моделювання за допомогою локальних даних, вирішуючи проблеми резидентності даних та відповідності вимогам.
Дослідники Массачусетського технологічного інституту з Інституту досліджень мозку Макговерна виявили життєво важливу роль точного визначення часу в слухових нейронах для розпізнавання голосів і визначення місцезнаходження звуків. Використовуючи машинне навчання, моделі команди надають інформацію для вивчення порушень слуху та розробки інтервенцій.

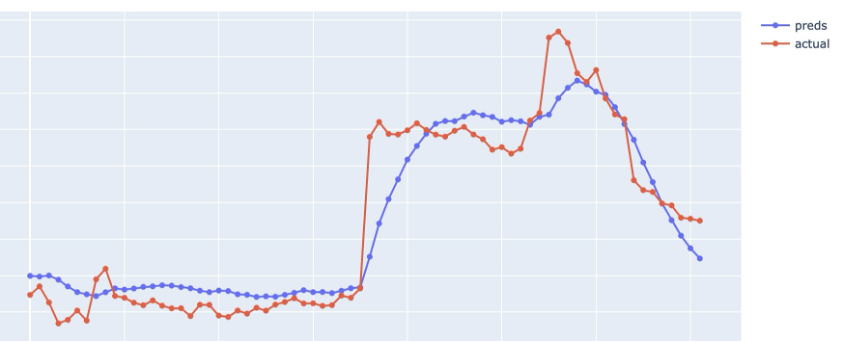
Лінійна регресія з двосторонніми взаємодіями може значно підвищити точність прогнозування. Модель була успішно реалізована за допомогою C# і досягла високого рівня точності.