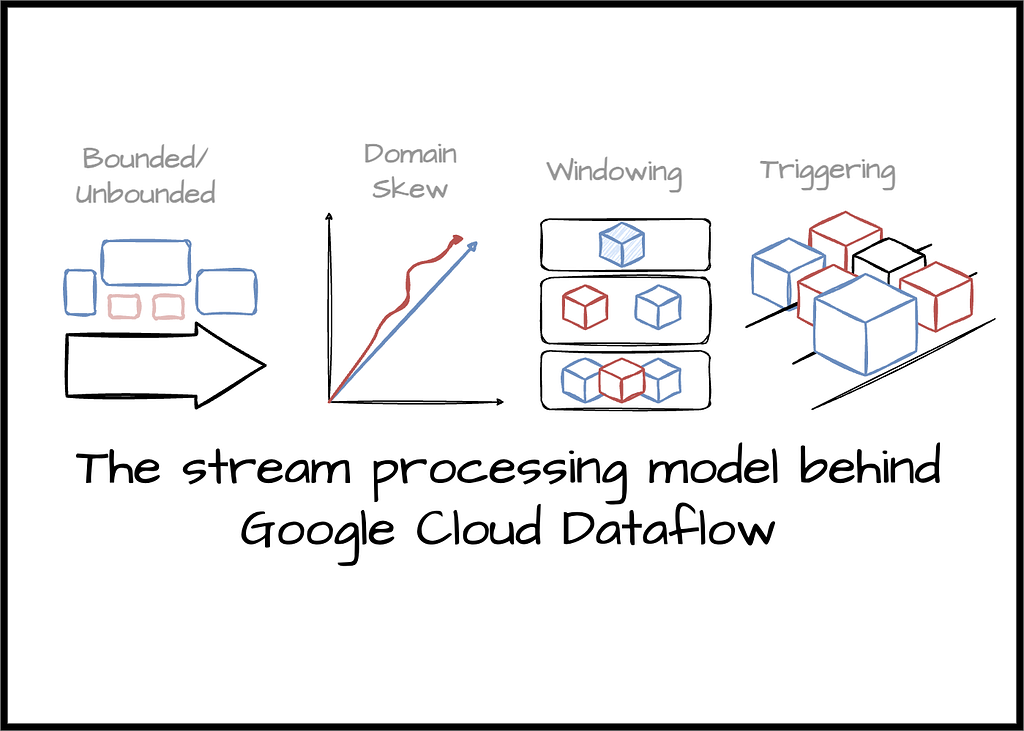
Google Dataflow, керований сервіс для потокової та пакетної обробки даних, забезпечує коректність і затримку. Модель Dataflow балансує між коректністю, затримкою та вартістю при обробці великих обсягів даних.

Amazon Transcribe Call Analytics представляє функцію генеративного підбиття підсумків дзвінків зі штучним інтелектом, щоб спростити роботу після дзвінків, підвищити продуктивність операторів і покращити якість обслуговування клієнтів. Директор з продуктів SuccessKPI високо оцінює можливість автоматизації підбиття підсумків дзвінків, зменшення ручної роботи та підвищення ефективності контакт-це...

Таємничий чат-бот під назвою "gpt2-chatbot" викликає спекуляції як потенційна тестова версія майбутньої великої мовної моделі OpenAI GPT-4.5 або GPT-5. Обмежений доступ та чутки в Інтернеті додають інтриги щодо присутності нової моделі на Арені чат-ботів.

SEA. AI у партнерстві з NVIDIA використовує штучний інтелект для підвищення безпеки на морі шляхом виявлення об'єктів у морі. Їхня технологія може виявляти небезпеки та людей у воді на відстані до 700 метрів, революціонізуючи безпеку на морі.

Дослідники Лабораторії Лінкольна Массачусетського технологічного інституту випустили відкритий набір даних TorNet, що містить радіолокаційні дані з тисяч торнадо. Моделі машинного навчання, навчені на TorNet, демонструють багатообіцяючу здатність виявляти торнадо, потенційно підвищуючи точність прогнозів і рятуючи життя людей.

Фестиваль навчання 2024 в Массачусетському технологічному інституті підкреслив важливість впровадження генеративного ШІ в освіту без заміни традиційних методів навчання. Викладачі та студенти переробляють завдання, щоб розвивати навички критичного мислення та покращувати лінгвістичні здібності, використовуючи такі інструменти, як ChatGPT.

Міністерство безпеки США створило Раду з безпеки та захисту штучного інтелекту для захисту від зловживань та іноземних загроз. Рада має на меті забезпечити безпечне впровадження та співпрацю між секторами.

Financial Times співпрацює з ChatGPT від OpenAI для навчання ШІ з використанням контенту FT. Угода передбачає виплати на користь FT від OpenAI.

Джулі Шах, керівник AeroAstro в Массачусетському технологічному інституті, відома своїми роботами зі штучного інтелекту та робототехніки, досліджує майбутнє співпраці людини та робота. Відзначена численними нагородами, вона очолює дослідження генеративного ШІ для більш якісної роботи.
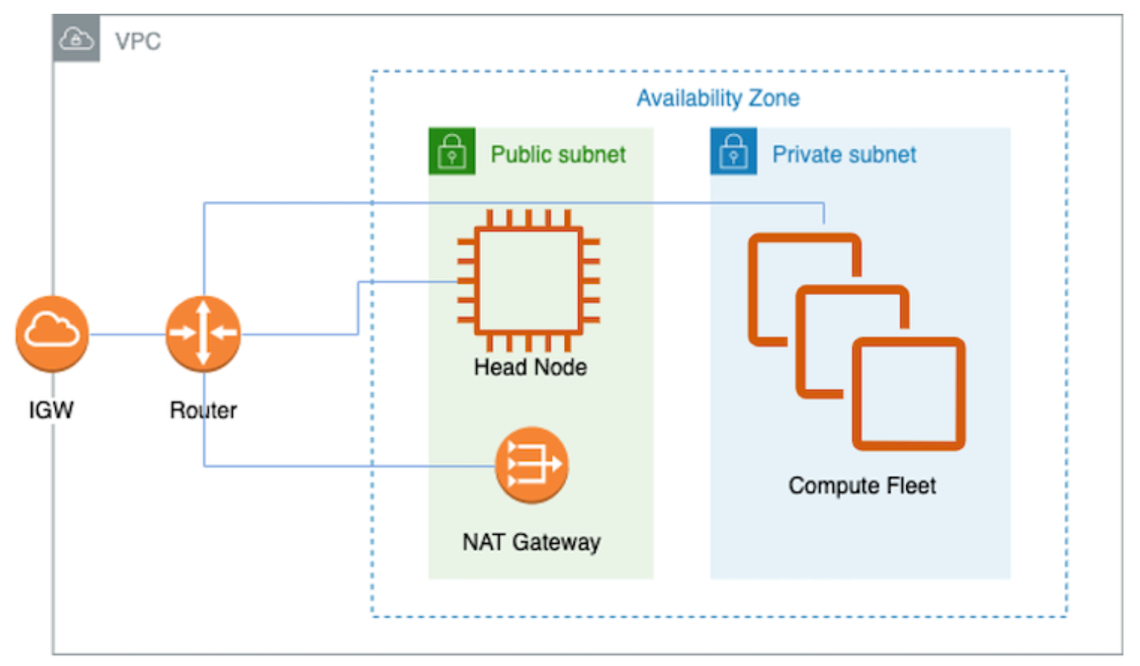
Arcee впроваджує інновації в ефективну підготовку LLM за допомогою безперервної попередньої підготовки та методів злиття моделей, співпрацюючи з AWS Trainium для досягнення високої продуктивності та зниження витрат. Їхній підхід демонструє значні досягнення в адаптації доменів для медичного, юридичного та фінансового секторів, використовуючи передові технології для трансформаційних ідей.
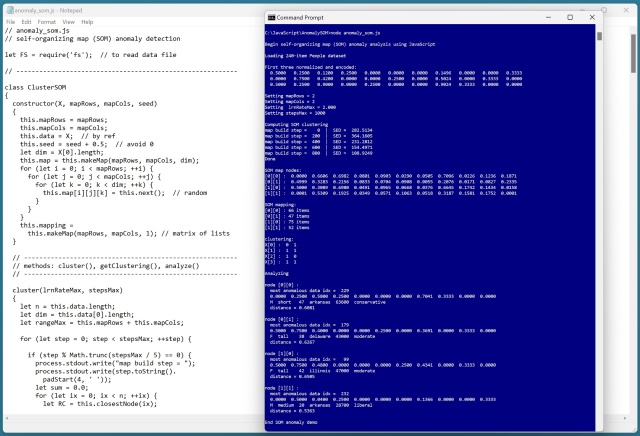
Демонстрація виявлення аномалій даних за допомогою карти, що самоорганізується (SOM), була рефакторингована з C# на Python та сирий JavaScript. SOM кластеризує дані на основі евклідової відстані, виявляючи аномалії для подальшого аналізу.

Несподівано закрився Інститут майбутнього людства, заснований Ніком Бостромом у 2005 році за підтримки Кремнієвої долини. Центр попереджав про ризики, пов'язані зі штучним інтелектом, та пропагував культові ідеї на кшталт ефективного альтруїзму.

Постачальники послуг стикаються з проблемами в управлінні обурливими матеріалами в Інтернеті. Розділ 230 Закону про телекомунікації від 1996 року революціонізував відповідальність за інтернет-контент, що призвело до зростання користувацького контенту та модерації платформ.
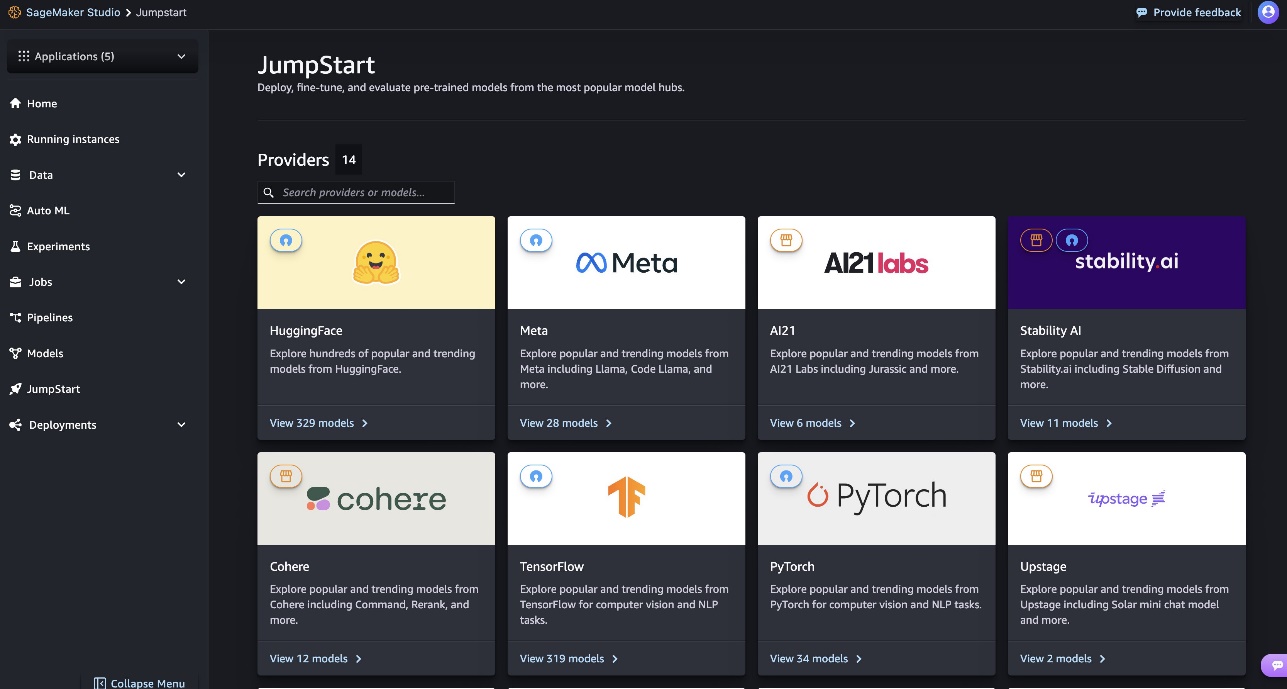
Модель DBRX, розроблена компанією Databricks, - це LLM з 132 мільярдами параметрів, попередньо навчений на 12 трильйонах токенів. SageMaker JumpStart пропонує легкий доступ до цієї моделі для різних завдань ML, прискорюючи розробку та розгортання.
AWS re:Invent 2023 представляє бази знань для Amazon Bedrock, що забезпечують безпечний чат з нульовим налаштуванням. Retrieval Augmented Generation розширює можливості FM-помічників зі штучним інтелектом, надаючи їм контекст у реальному часі з кураторських баз знань.