
Sesame AI представляє модель Speech-to-Speech, що використовує джерела даних Moshi. Дізнайтеся про кодер Mimi та архітектуру з двома трансформаторами для генерації звуку.

nTop, заснована Бредлі Ротенбергом, пропонує дизайнерам швидкі інноваційні інструменти, використовуючи графічні процесори для паралельної обробки та штучного інтелекту. Компанія Ocado використала програмне забезпечення nTop для швидкого перепроектування своїх роботів, зменшивши їхню вагу на дві третини та заощадивши час і витрати.

Байєсівські методи пропонують надійне оцінювання параметрів, що виходить за рамки частотних інструментів. Розуміння надійності MCMC-самплерів має вирішальне значення для дослідників даних.
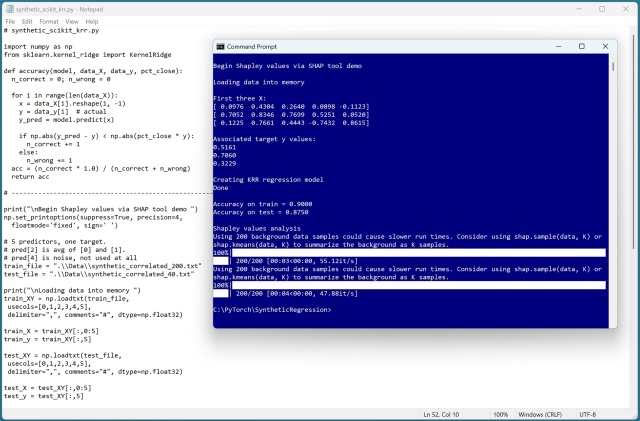
Значення Шейплі вимірюють важливість предиктора в ML-моделях, оцінюючи його за допомогою інструменту SHAP у Python. Синтетичний аналіз даних дає уявлення про точність моделі та значущість змінних.
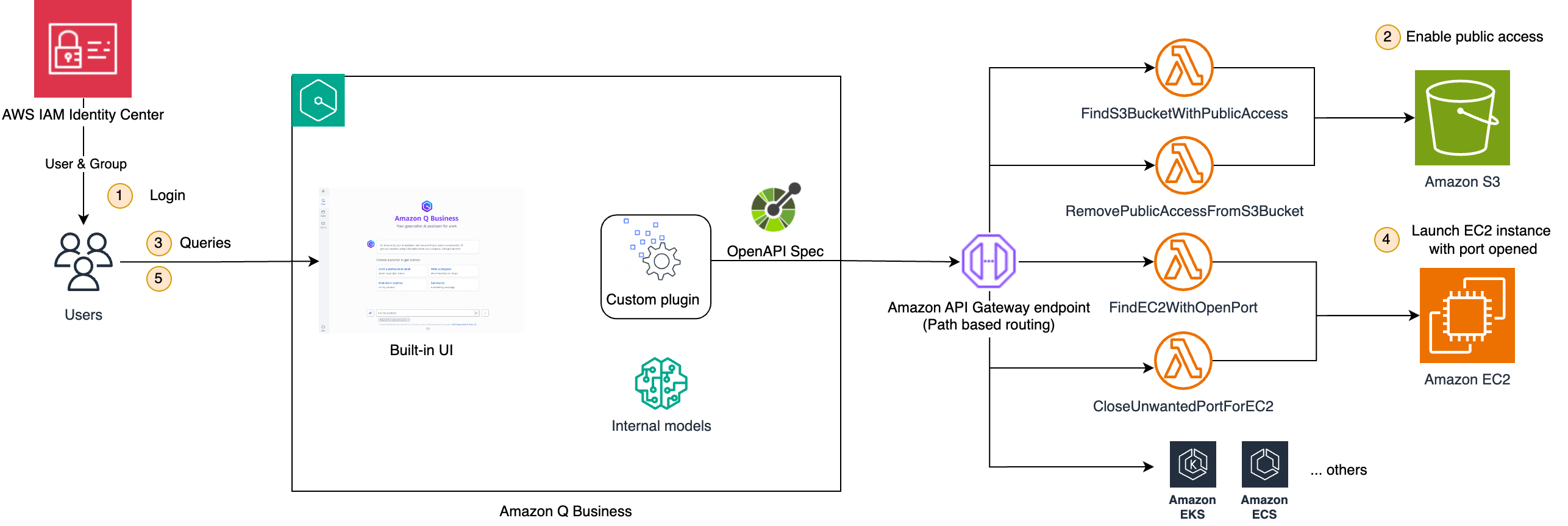
Організації стикаються з проблемами, пов'язаними з розрізненими сторонніми додатками, але плагіни Amazon Q Business пропонують рішення. Кастомні плагіни дозволяють чат-боту взаємодіяти з різними API за допомогою природної мови, спрощуючи складні хмарні операції та підвищуючи ефективність.
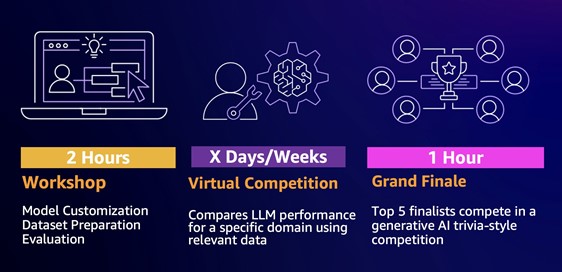
AWS DeepRacer League представляє автономні перегони, а AWS LLM League демократизує машинне навчання за допомогою гейміфікованих змагань. Учасники налаштовують LLM для вирішення реальних бізнес-завдань, демонструючи переваги менших моделей з точки зору ефективності та доступності.

Джеррі Адамс розглядає можливість судового позову проти компанії Meta за використання його книг для навчання штучного інтелекту без дозволу. Мета включила щонайменше сім його книг до переліку авторських матеріалів.
Британський стартап Synthesia співпрацює з Shutterstock, щоб покращити аватарки зі штучним інтелектом, використовуючи стокові кадри. Угода вартістю $2 млрд спрямована на покращення виразу обличчя, тембру голосу та мови тіла аватарів для більш реалістичної взаємодії.

Графічні процесори NVIDIA GeForce RTX 50 серії та RTX PRO на архітектурі Blackwell покращують творчі робочі процеси за допомогою інструментів ШІ в DaVinci Resolve Studio 20. Нові функції ШІ, такі як шумозаглушення UltraNR і магічна маска, спрощують процеси редагування відео та постпродакшну, працюючи швидше на графічних процесорах RTX для підвищення ефективності та продуктивності.

Відкрийте для себе найкращі страви на основі сиру та хліба в Міжнародному валлійському центрі рідкісних страв. Лікар просить забрати плаценту додому, щоб прикрасити її трояндами, розпалюючи цікавість.
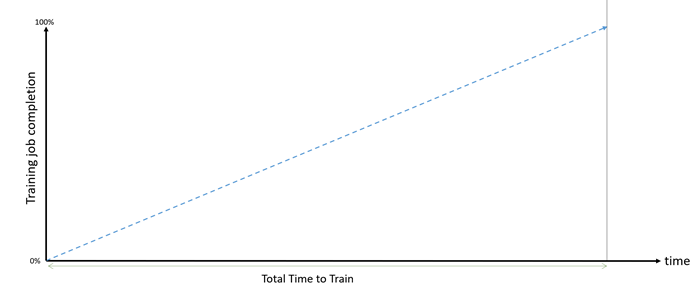
Масштабне навчання на прикордонних моделях вимагає значних обчислень, а збої в роботі обладнання заважають просуванню вперед. Amazon SageMaker HyperPod мінімізує збої, підвищує ефективність та зменшує витрати на навчання.

«Чорне дзеркало» переосмислює наукову фантастику за допомогою сучасних алегорій, що формують наш погляд на технології та майбутнє. Кожен епізод віддзеркалює наші колективні тривоги або вводить нові страхи через майстерну розповідь".

Стаття в журналі Microsoft Visual Studio Magazine за квітень 2025 року демонструє лінійну векторну регресію з використанням C# з еволюційним навчанням. Лінійна SVR карає викиди і зберігає значення моделі малими, але простіші методи, такі як L1 і L2 регресія, є більш популярними.
Модель Pixtral Large від Mistral AI тепер доступна на Amazon Bedrock, пропонуючи потужне мультимодальне ШІ-рішення зі 124 мільярдами параметрів. Ця модель відмінно справляється з багатомовним аналізом тексту, інтерпретацією графіків і загальним візуальним розумінням, революціонізуючи різні завдання, керовані даними.

Deb8flow використовує ШІ-агентів, таких як «За» і «Проти», для автономних дебатів, з перевіркою фактів і модерацією в режимі реального часу. Удосконалена архітектура використовує LangGraph та GPT-4o, гарантуючи, що дебати залишаються заснованими на правді.